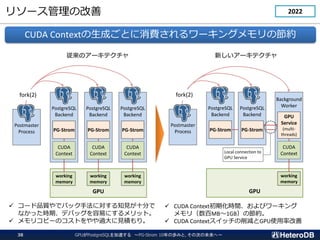
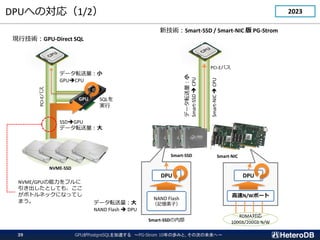
① Apache Arrowへの対応(1/3)
ETL
OLTPOLAP
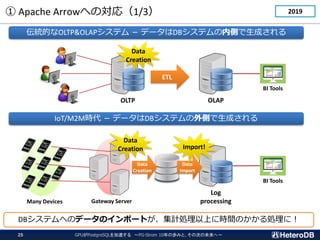
伝統的なOLTP&OLAPシステム - データはDBシステムの内側で生成される
Data
Creation
IoT/M2M時代 - データはDBシステムの外側で生成される
Log
processing
BI Tools
BI Tools
Gateway Server
Data
Creation
Data
Creation
Many Devices
GPUがPostgreSQLを加速する ~PG-Strom 10年の歩みと、その次の未来へ~
25
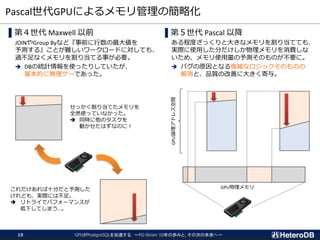
DBシステムへのデータのインポートが、集計処理以上に時間のかかる処理に!
Data
Import
Import!
2019






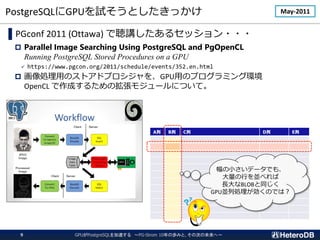
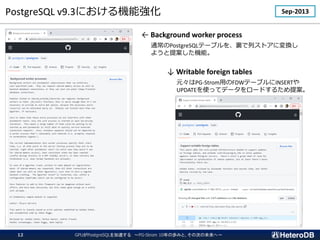
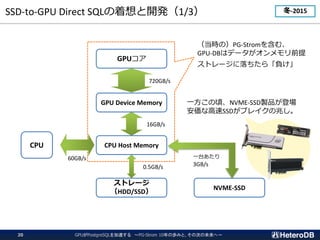
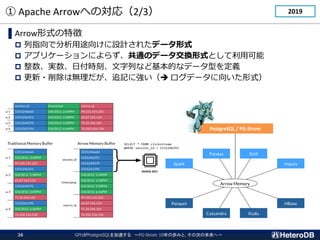
![GPUとはどんなプロセッサか?(1/2)
多数のコアと広帯域メモリによる強力な並列演算性能を有する。
CPU
Cache
CUDA Core
CUDA Core
CUDA Core
CUDA Core
CUDA Core
CUDA Core
CUDA Core
CUDA Core
広帯域メモリ
GPUがPostgreSQLを加速する ~PG-Strom 10年の歩みと、その次の未来へ~
7
Intel Xeon Platinum 8380
# of cores: 40
clock: 2.30GHz
3.40GHz (boost)
L1 cache: 64kB / core
L2 cache: 1MB / core
L3 cache: 60MB / proc
DRAM: DDR4-3200 x 8
(max 204.8GB/s)
NVIDIA A100 [80GB; PCI-E]
# of CUDA cores: 6,912 [32bit]
(108 SM)
clock: 1.065 GHz
1.410 GHz (boost)
L1 cache: 192kB / SM (*)
L2 cache: 40MB / proc
DRAM: HBM2e [80GB]
(max 1,935GB/s)](https://image.slidesharecdn.com/c-7heterodb20221102dbtspgstrom-221116093945-65368e84/85/20221116_DBTS_PGStrom_History-7-320.jpg)
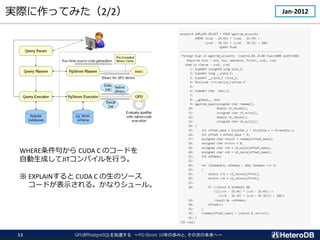
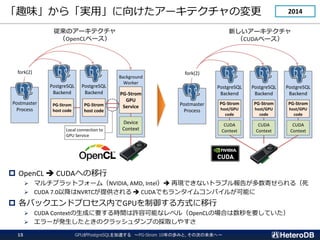
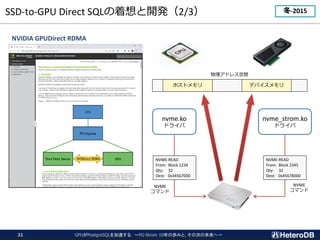
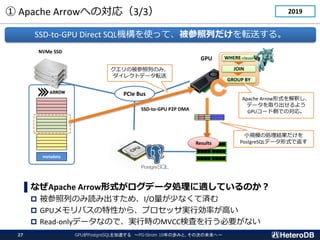
![GPUとはどんなプロセッサか?(2/2)
GPUがPostgreSQLを加速する ~PG-Strom 10年の歩みと、その次の未来へ~
8
スレッド同士での同期やデータ交換を低コストで実行できる
●
item[0]
step.1 step.2 step.4
step.3
GPUを用いた
Σi=0...N-1item[i]
配列総和の計算
◆
●
▲ ■ ★
● ◆
●
● ◆ ▲
●
● ◆
●
● ◆ ▲ ■
●
● ◆
●
● ◆ ▲
●
● ◆
●
item[1]
item[2]
item[3]
item[4]
item[5]
item[6]
item[7]
item[8]
item[9]
item[10]
item[11]
item[12]
item[13]
item[14]
item[15]
log2N ステップで
items[]の総和を計算
HW支援によるコア間の同期機構
SELECT count(X),
sum(Y),
avg(Z)
FROM my_table;
集約関数の計算で用いる仕組み](https://image.slidesharecdn.com/c-7heterodb20221102dbtspgstrom-221116093945-65368e84/85/20221116_DBTS_PGStrom_History-8-320.jpg)
















![GPUとSSDがPostgreSQLを加速する~クエリ処理スループット10GB/sへの挑戦~ [DB Tech Showcase Tokyo/2017]](https://cdn.slidesharecdn.com/ss_thumbnails/20170906dbtsgpussdacceleratespostgresqljp-170906073226-thumbnail.jpg?width=640&height=640&fit=bounds)








































