Download as PDF, PPTX








![SSD-to-GPU Direct SQL (3/4) – Benchmark results
PostgreSQL Webinar Series 2020 - Data processing more than billion rows per second18
Query Execution Throughput = (353GB; DB-size) / (Query response time [sec])
SSD-to-GPU Direct SQL runs the workloads close to the hardware limitation (8.5GB/s)
about x3 times faster than filesystem and CPU based mechanism
2343.7 2320.6 2315.8 2233.1 2223.9 2216.8 2167.8 2281.9 2277.6 2275.9 2172.0 2198.8 2233.3
7880.4 7924.7 7912.5
7725.8 7712.6 7827.2
7398.1 7258.0
7638.5 7750.4
7402.8 7419.6
7639.8
0
1,000
2,000
3,000
4,000
5,000
6,000
7,000
8,000
9,000
Q1_1 Q1_2 Q1_3 Q2_1 Q2_2 Q2_3 Q3_1 Q3_2 Q3_3 Q3_4 Q4_1 Q4_2 Q4_3
QueryExecutionThroughput[MB/s]
Star Schema Benchmark on 1xNVIDIA Tesla V100 + 3xIntel DC P4600
PostgreSQL 11.2 PG-Strom 2.2devel](https://image.slidesharecdn.com/20201006pgconfonlinekaigai-201006120509/75/20201006_PGconf_Online_Large_Data_Processing-18-2048.jpg)


![SSD-to-GPU Direct SQL on Arrow_Fdw (2/3) - Benchmark Results
Query Execution Throughput = (6.0B rows) / (Query Response Time [sec])
Combined usage of SSD-to-GPU Direct SQL and Columnar-store pulled out the extreme
performance; 130-500M rows per second
Server configuration is identical to what we show on p.17. (1U, 1CPU, 1GPU, 3SSD)
PostgreSQL Webinar Series 2020 - Data processing more than billion rows per second28
16.3 16.0 16.0 15.7 15.5 15.6 15.6 15.9 15.7 15.7 15.5 15.6 15.4
55.0 55.1 55.1 54.4 54.4 54.6 52.9 54.0 54.9 54.8 53.2 53.1 54.0
481.0
494.2 499.6
246.6
261.7
282.0
156.2
179.0 183.6 185.0
138.3 139.1
152.6
0
100
200
300
400
500
Q1_1 Q1_2 Q1_3 Q2_1 Q2_2 Q2_3 Q3_1 Q3_2 Q3_3 Q3_4 Q4_1 Q4_2 Q4_3
Numberofrowsprocessedpersecond
[millionrows/sec]
Star Schema Benchmark (s=1000, DBsize: 879GB) on Tesla V100 x1 + DC P4600 x3
PostgreSQL 11.5 PG-Strom 2.2 (Row data) PG-Strom 2.2 + Arrow_Fdw](https://image.slidesharecdn.com/20201006pgconfonlinekaigai-201006120509/75/20201006_PGconf_Online_Large_Data_Processing-28-2048.jpg)




![PCIe-bus level optimization (3/3)
PostgreSQL Webinar Series 2020 - Data processing more than billion rows per second40
$ pg_ctl restart
:
LOG: - PCIe[0000:80]
LOG: - PCIe(0000:80:02.0)
LOG: - PCIe(0000:83:00.0)
LOG: - PCIe(0000:84:00.0)
LOG: - PCIe(0000:85:00.0) nvme0 (INTEL SSDPEDKE020T7)
LOG: - PCIe(0000:84:01.0)
LOG: - PCIe(0000:86:00.0) GPU0 (Tesla P40)
LOG: - PCIe(0000:84:02.0)
LOG: - PCIe(0000:87:00.0) nvme1 (INTEL SSDPEDKE020T7)
LOG: - PCIe(0000:80:03.0)
LOG: - PCIe(0000:c0:00.0)
LOG: - PCIe(0000:c1:00.0)
LOG: - PCIe(0000:c2:00.0) nvme2 (INTEL SSDPEDKE020T7)
LOG: - PCIe(0000:c1:01.0)
LOG: - PCIe(0000:c3:00.0) GPU1 (Tesla P40)
LOG: - PCIe(0000:c1:02.0)
LOG: - PCIe(0000:c4:00.0) nvme3 (INTEL SSDPEDKE020T7)
LOG: - PCIe(0000:80:03.2)
LOG: - PCIe(0000:e0:00.0)
LOG: - PCIe(0000:e1:00.0)
LOG: - PCIe(0000:e2:00.0) nvme4 (INTEL SSDPEDKE020T7)
LOG: - PCIe(0000:e1:01.0)
LOG: - PCIe(0000:e3:00.0) GPU2 (Tesla P40)
LOG: - PCIe(0000:e1:02.0)
LOG: - PCIe(0000:e4:00.0) nvme5 (INTEL SSDPEDKE020T7)
LOG: GPU<->SSD Distance Matrix
LOG: GPU0 GPU1 GPU2
LOG: nvme0 ( 3) 7 7
LOG: nvme5 7 7 ( 3)
LOG: nvme4 7 7 ( 3)
LOG: nvme2 7 ( 3) 7
LOG: nvme1 ( 3) 7 7
LOG: nvme3 7 ( 3) 7
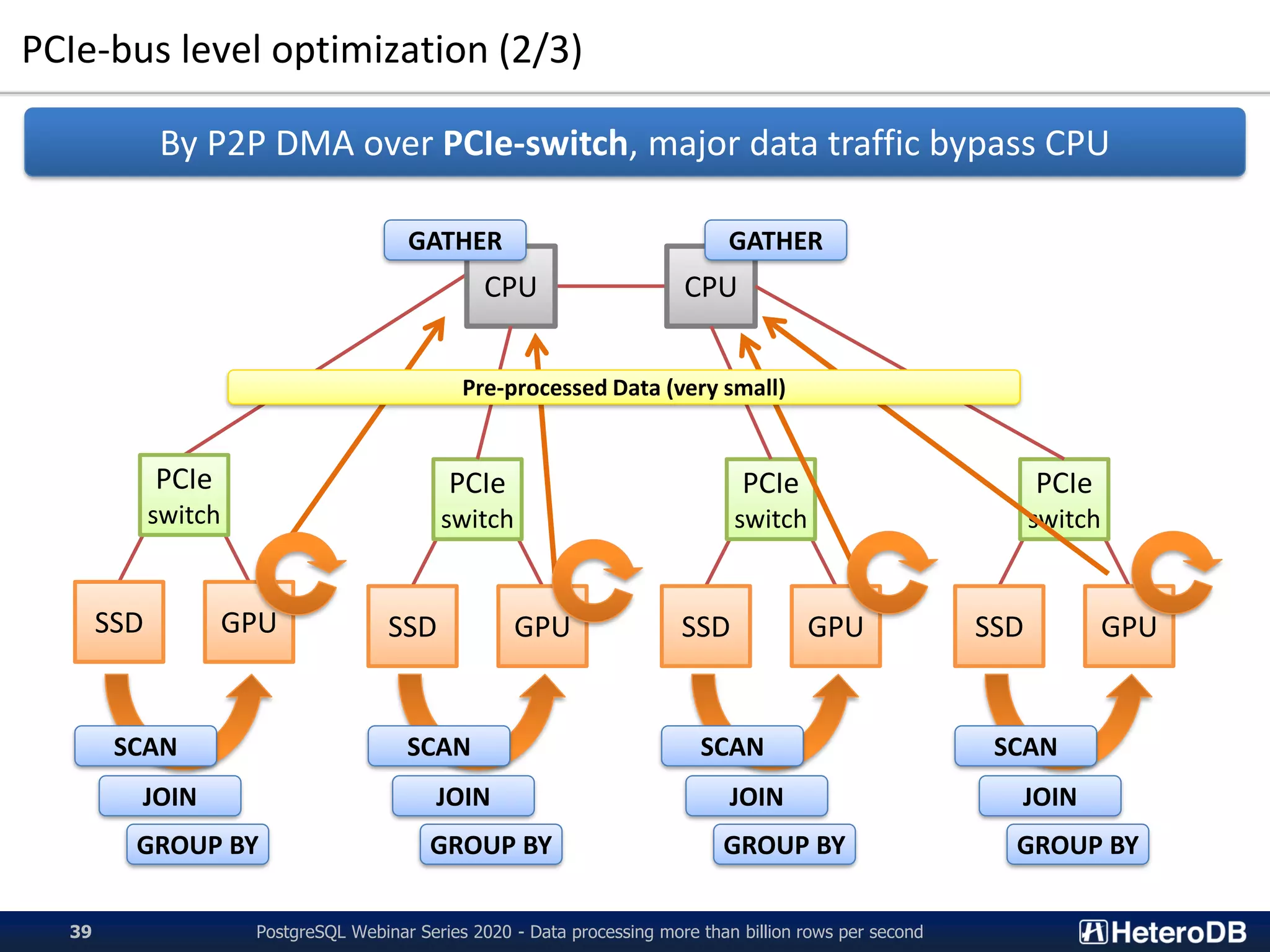
PG-Strom chooses the closest GPU
for the tables to be scanned,
according to the PCI-E device distance.](https://image.slidesharecdn.com/20201006pgconfonlinekaigai-201006120509/75/20201006_PGconf_Online_Large_Data_Processing-40-2048.jpg)



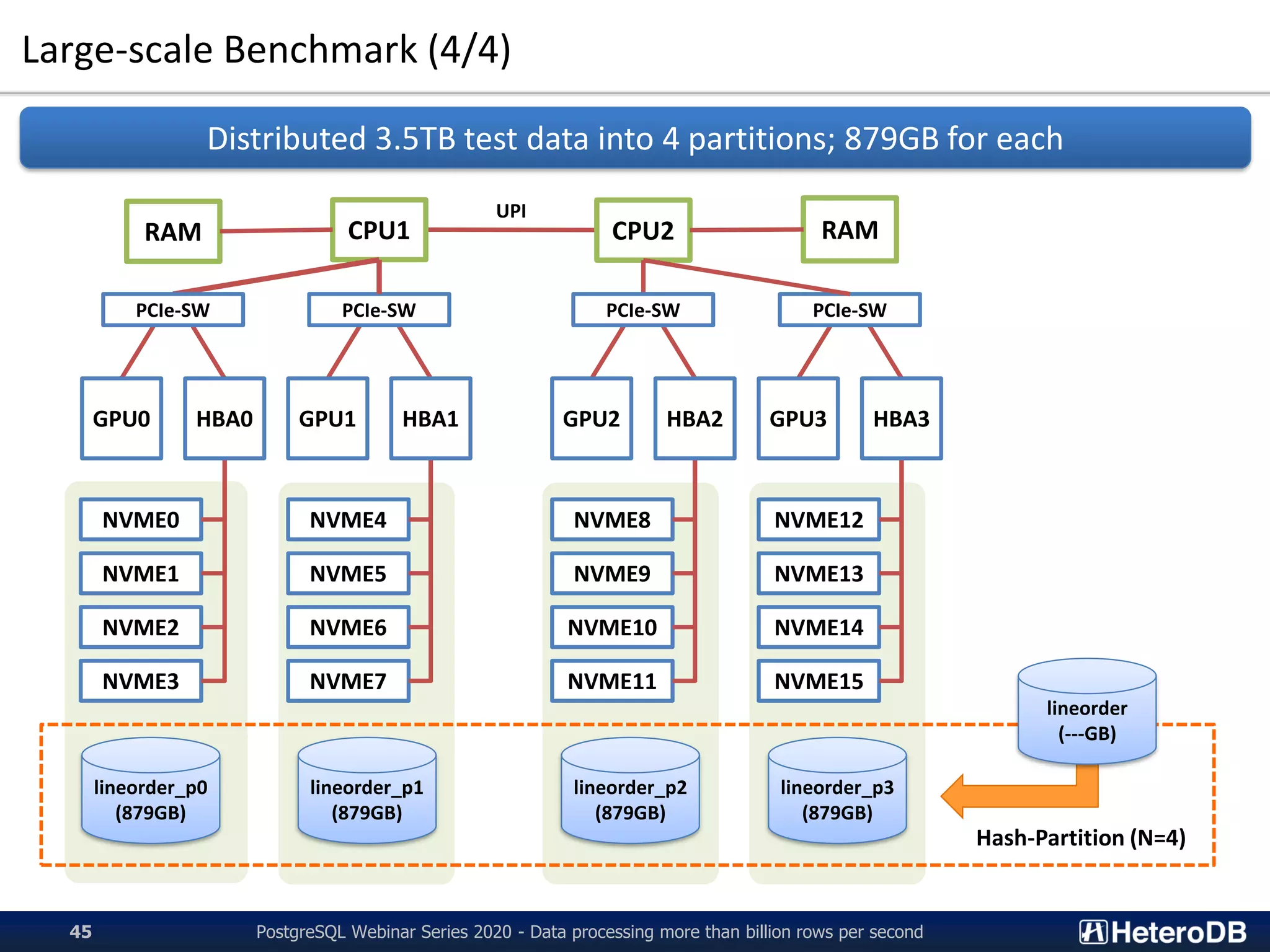
![Benchmark Results (1/2)
PostgreSQL Webinar Series 2020 - Data processing more than billion rows per second46
Billion rows per second at a single-node PostgreSQL!!
64.0 65.0 65.2 58.8 58.0 67.3 43.9 58.7 61.0 60.8 52.9 53.0 59.1
255.2 255.6 256.9 257.6 258.0 257.5 248.5 254.9 253.3 253.3 249.3 249.4 249.6
1,681
1,714 1,719
1,058
1,090
1,127
753
801 816 812
658 664 675
0
200
400
600
800
1,000
1,200
1,400
1,600
1,800
Q1_1 Q1_2 Q1_3 Q2_1 Q2_2 Q2_3 Q3_1 Q3_2 Q3_3 Q3_4 Q4_1 Q4_2 Q4_3
Numberofrowsprocessedpersecond
[millionrows/sec]
Results of Star Schema Benchmark
[SF=4,000 (3.5TB; 24B rows), 4xGPU, 16xNVME-SSD]
PostgreSQL 11.5 PG-Strom 2.2 PG-Strom 2.2 + Arrow_Fdw](https://image.slidesharecdn.com/20201006pgconfonlinekaigai-201006120509/75/20201006_PGconf_Online_Large_Data_Processing-46-2048.jpg)
![Benchmark Results (2/2)
PostgreSQL Webinar Series 2020 - Data processing more than billion rows per second47
40GB/s Read from NVME-SSDs during SQL execution (95% of H/W limit)
0
5,000
10,000
15,000
20,000
25,000
30,000
35,000
40,000
0 20 40 60 80 100 120 140 160 180 200 220 240 260 280 300 320 340
NVME-SSDReadThroughput[MB/s]
Elapsed Time [sec]
/dev/md0 (GPU0) /dev/md1 (GPU1) /dev/md2 (GPU2) /dev/md3 (GPU3)](https://image.slidesharecdn.com/20201006pgconfonlinekaigai-201006120509/75/20201006_PGconf_Online_Large_Data_Processing-47-2048.jpg)

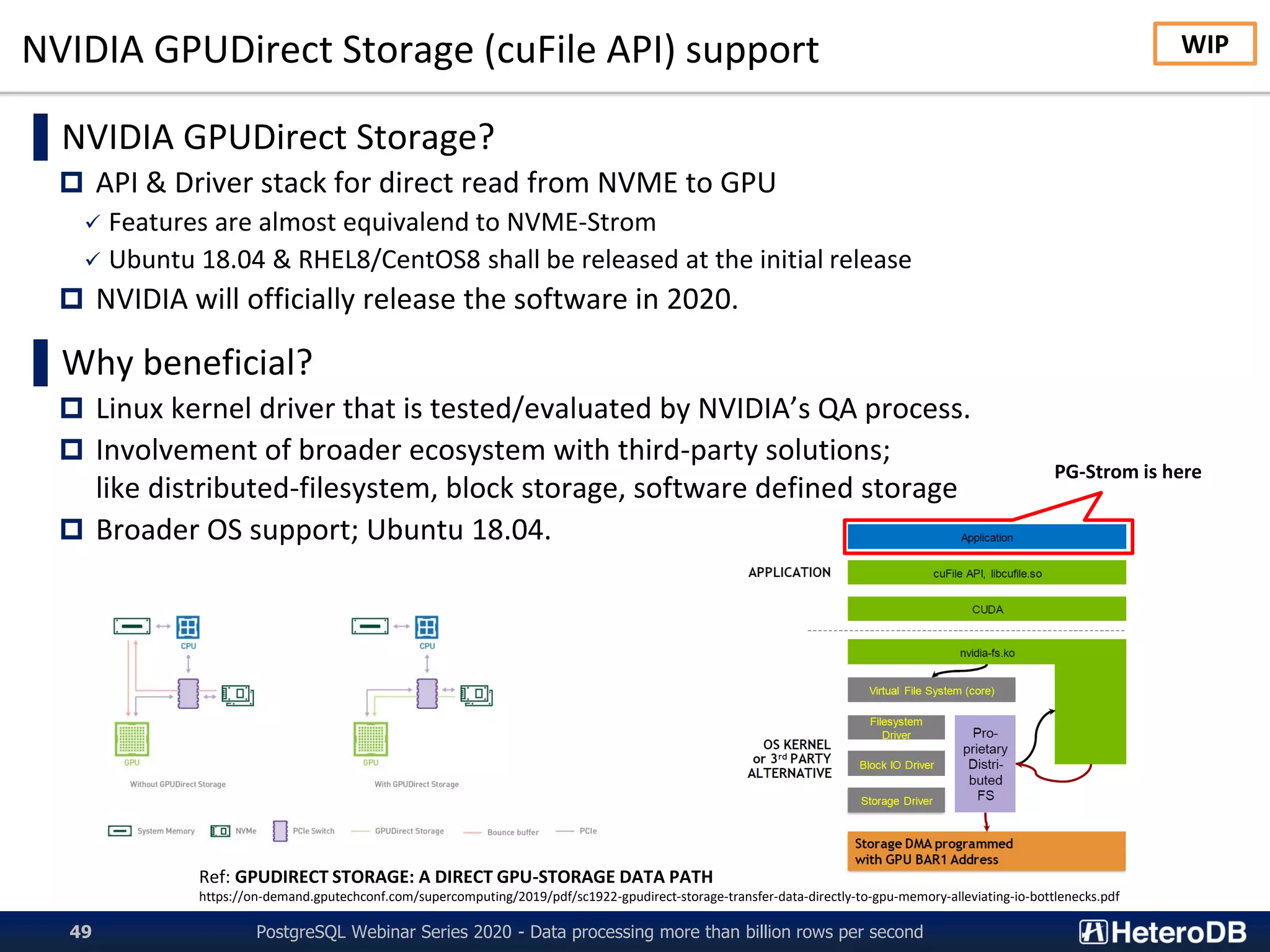
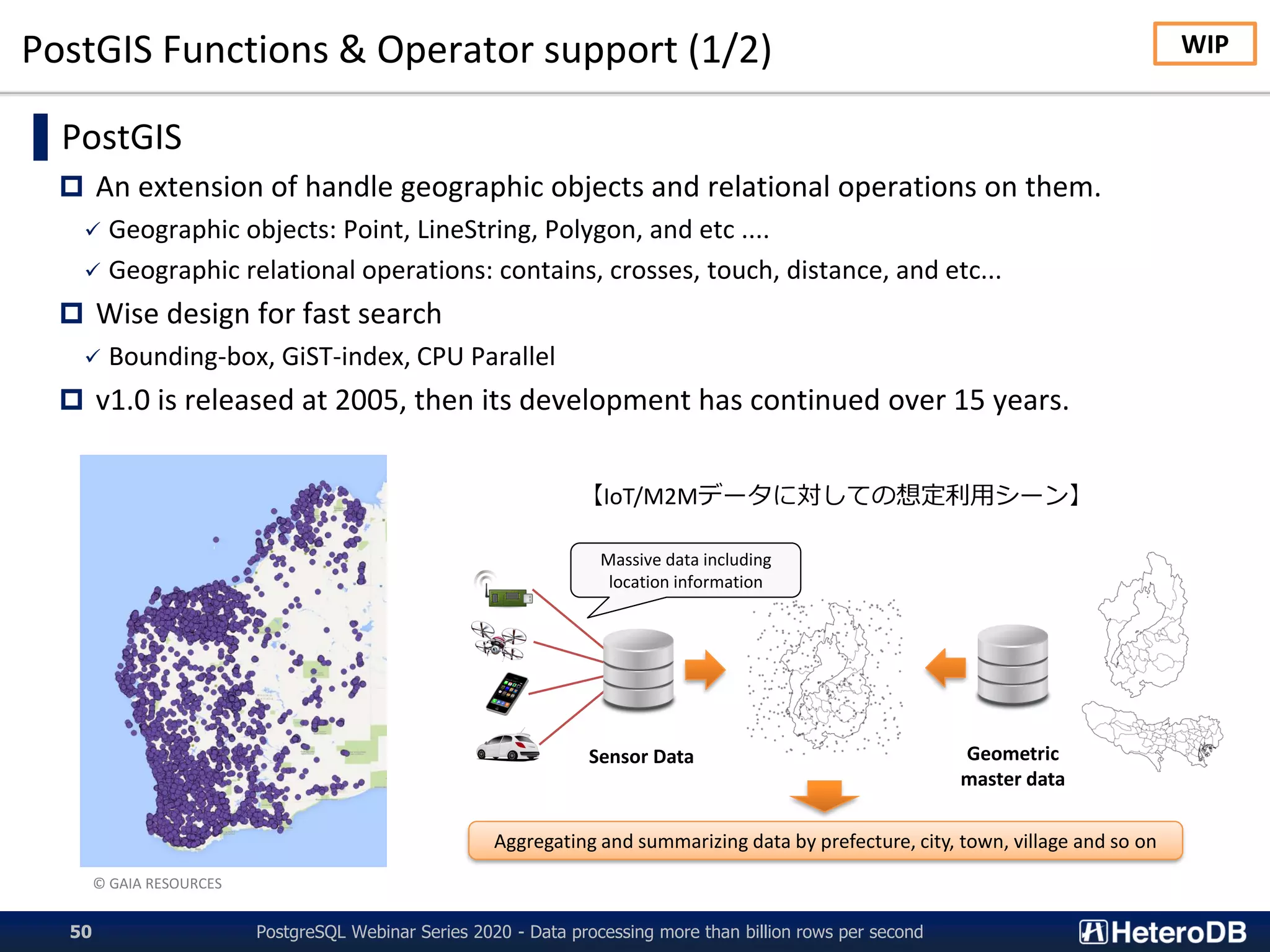




![Apache Arrow Internal (1/3)
▌Apache Arrow Internal
Header
• Fixed byte string: “ARROW1¥0¥0”
Schema Definition
• # of columns and columns definitions.
• Data type/precision, column name, column number, ...
Record Batch
• Internal data block that contains a certain # of rows.
• E.g, if N=1M rows with (Int32, Float64), this record-batch
begins from 1M of Int32 array, then 1M of Float64 array
follows.
Dictionary Batch
• Optional area for dictionary compression.
• E.g) 1 = “Tokyo”, 2 = “Osaka”, 3 = “Kyoto”
➔ Int32 representation for frequently appearing words
Footer
• Metadata - offset/length of RecordBatches and
DictionaryBatches
Header “ARROW1¥0¥0”
Schema Definition
DictionaryBatch-0
RecordBatch-0
RecordBatch-k
Footer
• DictionaryBatch[0] (offset, size)
• RecordBatch[0] (offset, size)
:
• RecordBatch[k] (offset, size)
Apache Arrow file
PostgreSQL Webinar Series 2020 - Data processing more than billion rows per second55](https://image.slidesharecdn.com/20201006pgconfonlinekaigai-201006120509/75/20201006_PGconf_Online_Large_Data_Processing-55-2048.jpg)
![Apache Arrow Internal (2/3) - writable Arrow_Fdw
Header “ARROW1¥0¥0”
Schema Definition
DictionaryBatch-0
RecordBatch-0
RecordBatch-k
Footer
• DictionaryBatch[0]
• RecordBatch[0]
:
• RecordBatch[k]
Arrow file (before writes)
Header “ARROW1¥0¥0”
Schema Definition
DictionaryBatch-0
RecordBatch-0
RecordBatch-k
Footer (new revision)
• DictionaryBatch[0]
• RecordBatch[0]
:
• RecordBatch[k]
• RecordBatch[k+1]
Arrow file (after writes)
RecordBatch-(k+1)
Overwrite of
the original
Footer area
Rows written by
a single INSERT
command
PostgreSQL Webinar Series 2020 - Data processing more than billion rows per second56](https://image.slidesharecdn.com/20201006pgconfonlinekaigai-201006120509/75/20201006_PGconf_Online_Large_Data_Processing-56-2048.jpg)
![Apache Arrow Internal (3/3) - writable Arrow_Fdw
Header “ARROW1¥0¥0”
Schema Definition
DictionaryBatch-0
RecordBatch-0
RecordBatch-k
Footer
• DictionaryBatch[0]
• RecordBatch[0]
:
• RecordBatch[k]
Arrow file (before writes)
Header “ARROW1¥0¥0”
Schema Definition
DictionaryBatch-0
RecordBatch-0
RecordBatch-k
Footer (new revision)
• DictionaryBatch[0]
• RecordBatch[0]
:
• RecordBatch[k]
• RecordBatch[k+1]
Arrow file (after writes)
RecordBatch-(k+1)
Overwrite of
the original
Footer area
Footer
• DictionaryBatch[0]
• RecordBatch[0]
:
• RecordBatch[k]
Arrow_Fdw keeps the original
Footer image until commit,
for support of rollback.
PostgreSQL Webinar Series 2020 - Data processing more than billion rows per second57](https://image.slidesharecdn.com/20201006pgconfonlinekaigai-201006120509/75/20201006_PGconf_Online_Large_Data_Processing-57-2048.jpg)
![Pg2Arrow / MySQL2Arrow
$ pg2arrow --help
Usage:
pg2arrow [OPTION] [database] [username]
General options:
-d, --dbname=DBNAME Database name to connect to
-c, --command=COMMAND SQL command to run
-t, --table=TABLENAME Table name to be dumped
(-c and -t are exclusive, either of them must be given)
-o, --output=FILENAME result file in Apache Arrow format
--append=FILENAME result Apache Arrow file to be appended
(--output and --append are exclusive. If neither of them
are given, it creates a temporary file.)
Arrow format options:
-s, --segment-size=SIZE size of record batch for each
Connection options:
-h, --host=HOSTNAME database server host
-p, --port=PORT database server port
-u, --user=USERNAME database user name
-w, --no-password never prompt for password
-W, --password force password prompt
Other options:
--dump=FILENAME dump information of arrow file
--progress shows progress of the job
--set=NAME:VALUE config option to set before SQL execution
--help shows this message
✓ mysql2arrow also has almost equivalent capability
Pg2Arrow / MySQL2Arrow enables to dump SQL results as Arrow file
Apache Arrow
Data Files
Arrow_Fdw
Pg2Arrow
PostgreSQL Webinar Series 2020 - Data processing more than billion rows per second58](https://image.slidesharecdn.com/20201006pgconfonlinekaigai-201006120509/75/20201006_PGconf_Online_Large_Data_Processing-58-2048.jpg)

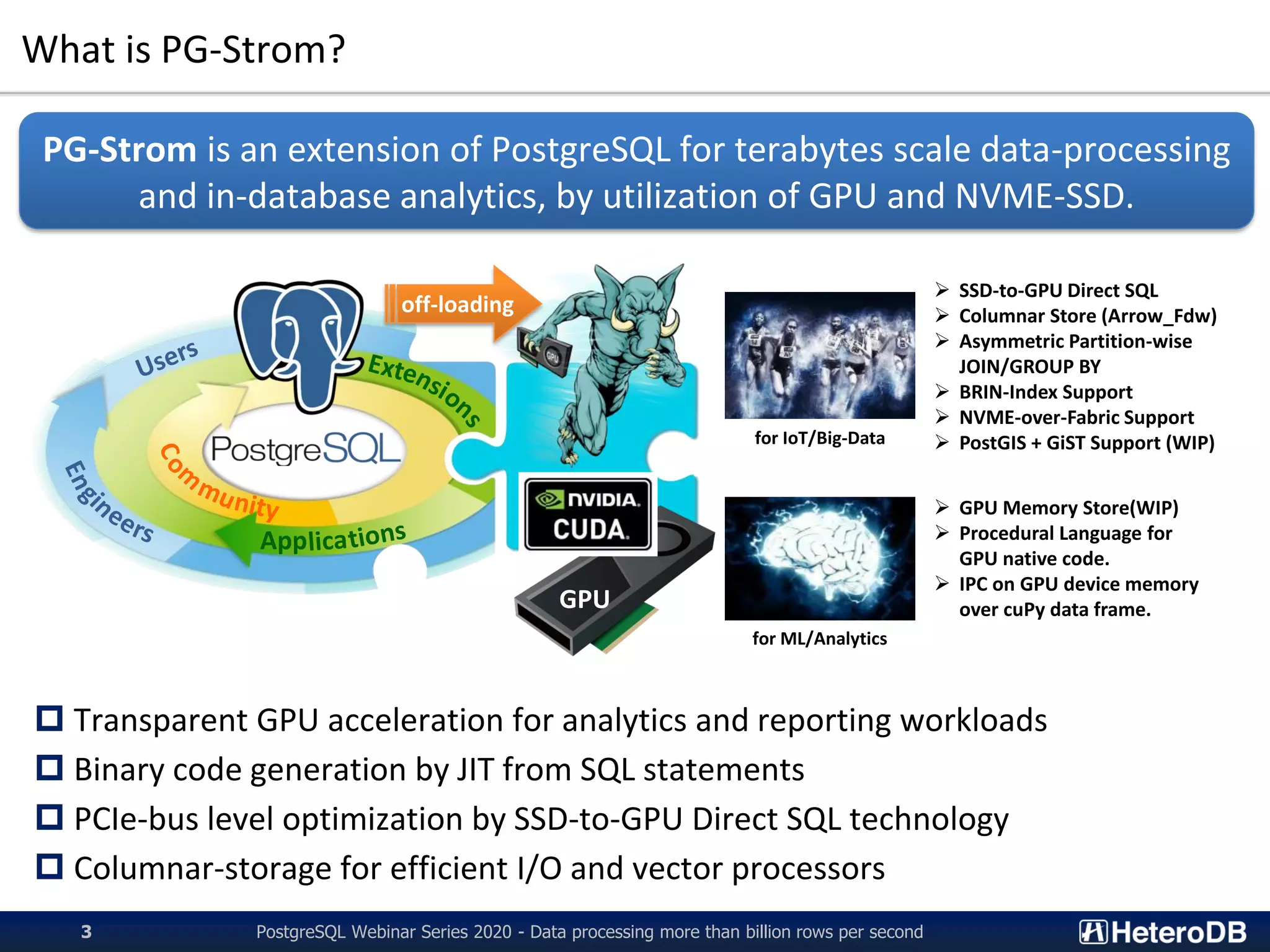
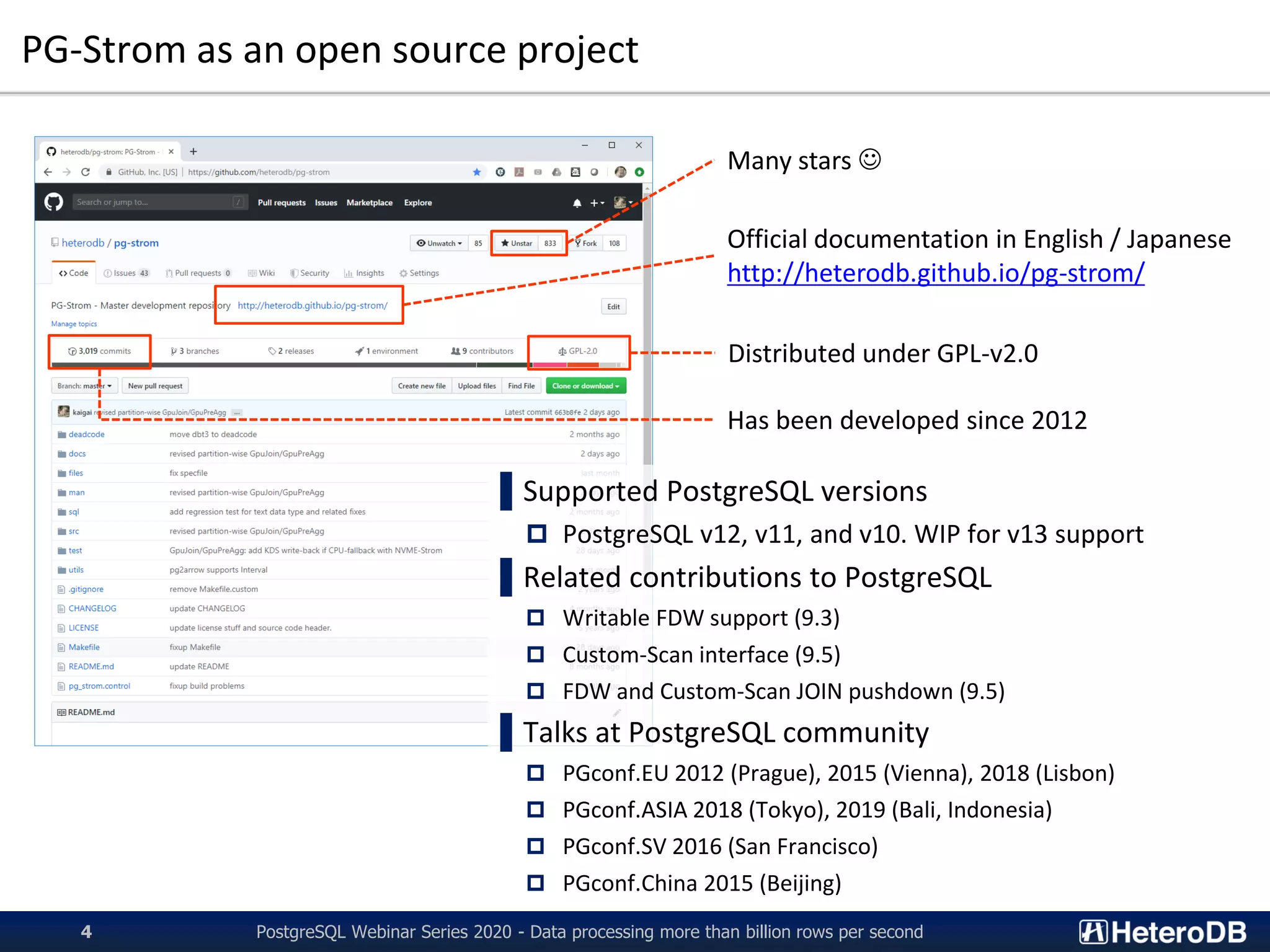
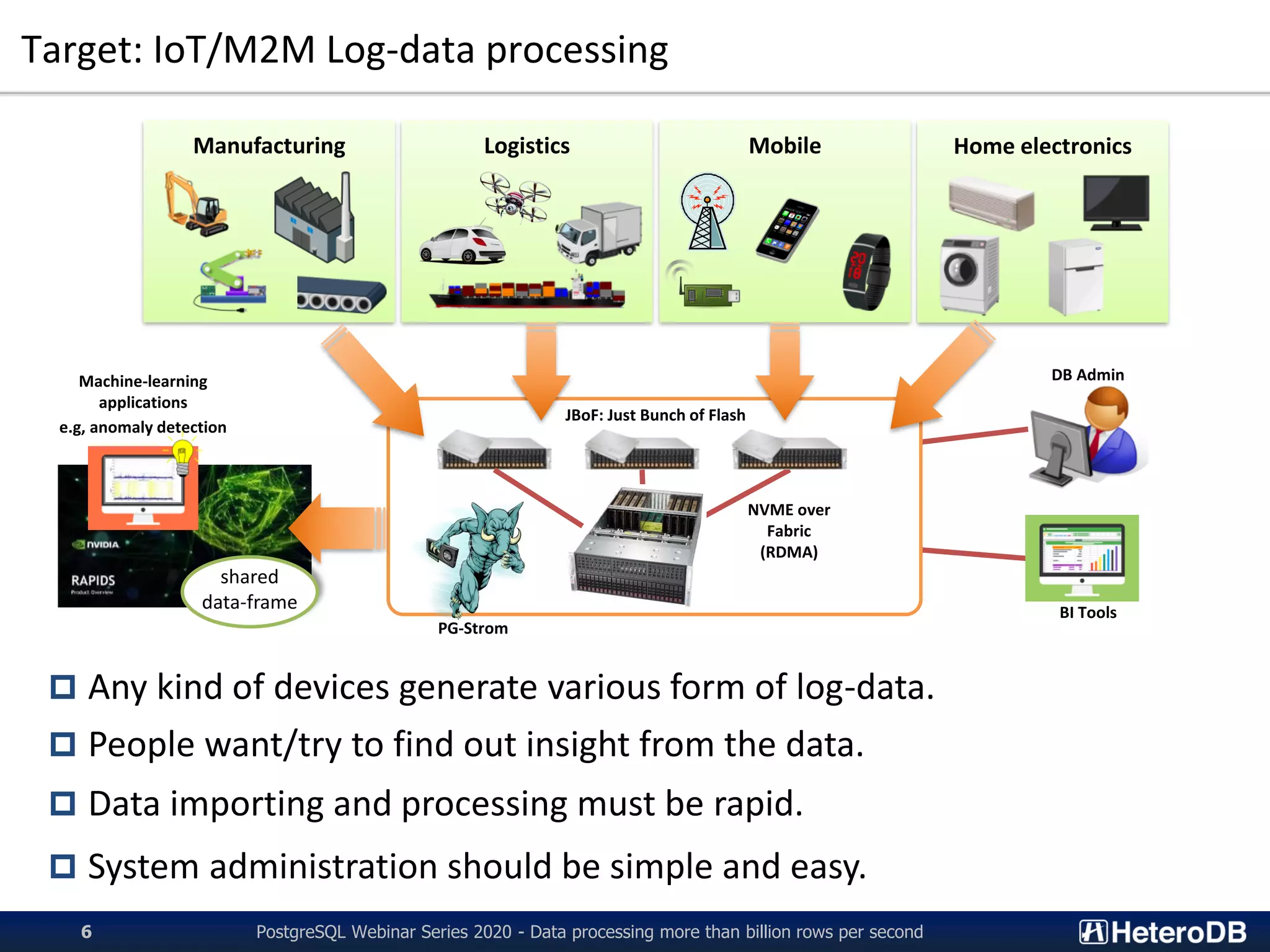
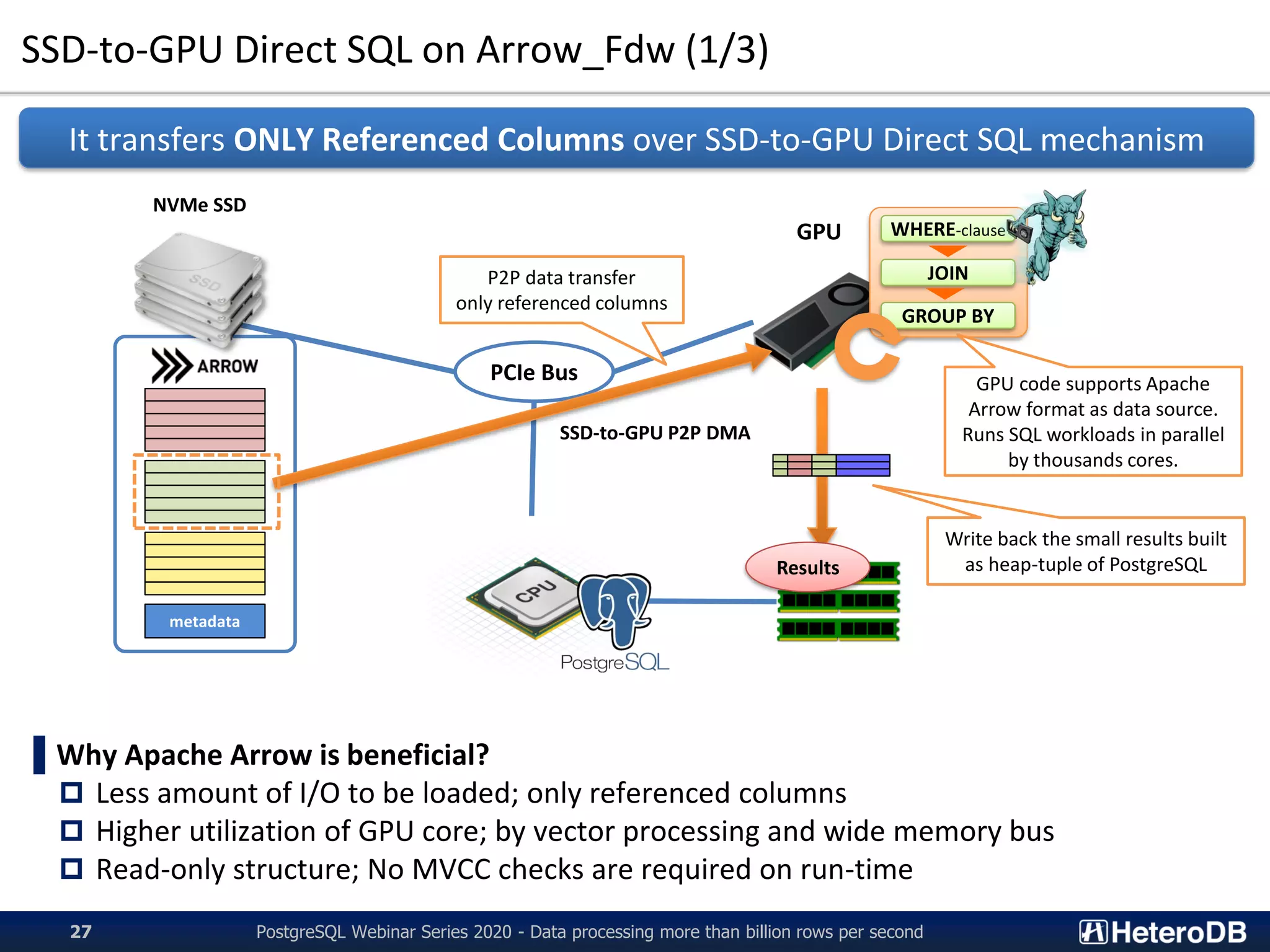
PG-Strom is an extension of PostgreSQL that utilizes GPUs and NVMe SSDs to enable terabyte-scale data processing and in-database analytics. It features SSD-to-GPU Direct SQL, which loads data directly from NVMe SSDs to GPUs using RDMA, bypassing CPU and RAM. This improves query performance by reducing I/O traffic over the PCIe bus. PG-Strom also uses Apache Arrow columnar storage format to further boost performance by transferring only referenced columns and enabling vector processing on GPUs. Benchmark results show PG-Strom can process over a billion rows per second on a simple 1U server configuration with an NVIDIA GPU and multiple NVMe SSDs.























































































