Download as PDF, PPTX
































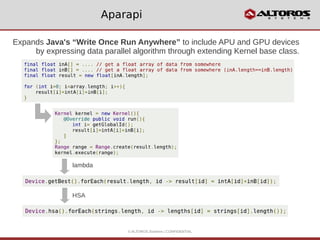
















The document discusses the emergence of data analytics on commodity clusters using technologies like Hadoop and GPU acceleration. It highlights the significant speed improvements possible with GPU-based computations, particularly in Java programming, showcasing examples and comparisons of performance. The document also introduces Aparapi, a tool that extends Java's capabilities to leverage GPU resources for data parallelism.























































































