Download as PDF, PPTX











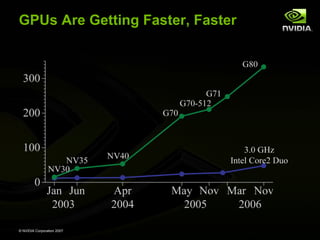










GPU computing provides a way to access the power of massively parallel graphics processing units (GPUs) for general purpose computing. GPUs contain over 100 processing cores and can achieve over 500 gigaflops of performance. The CUDA programming model allows programmers to leverage this parallelism by executing compute kernels on the GPU from their existing C/C++ applications. This approach democratizes parallel computing by making highly parallel systems accessible through inexpensive GPUs in personal computers and workstations. Researchers can now explore manycore architectures and parallel algorithms using GPUs as a platform.





































































































