Download as PDF, PPTX




















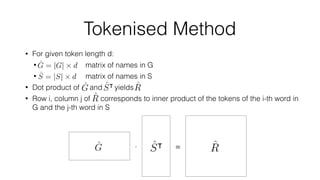
![Tokenised Method
Break name up into components (tokenising)
Many different types of tokens available: words, grams
Do this for all names in both G and S (this creates two matrices [names x tokens])
Example: Indicator function word tokeniser:
ABN RBS BANK Rabobank NV
ABN Amro
Bank
1 0 1 0 0
RBS Bank 0 1 1 0 0
Rabobank NV 0 0 0 1 1](https://image.slidesharecdn.com/pydataamsterdamnamematching-160804114738/85/PyData-Amsterdam-Name-Matching-at-Scale-22-320.jpg)




![Build ‘G’ TFIDF
matrix
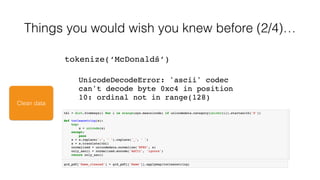
Things you would wish you knew before (3/4)…
Standard token_pattern (‘(?u)bww+b’) ignores single letters
Use token_pattern (‘(?u)bw+b’) for ‘full’ tokenization
(token_pattern = u’(?u)S', ngram_range=(3, 3)) gives 3-gram matching
‘Taxibedrijf M. van Seben’ —> [‘Taxibedrijf’, ‘van’, ‘ Seben’ ]](https://image.slidesharecdn.com/pydataamsterdamnamematching-160804114738/85/PyData-Amsterdam-Name-Matching-at-Scale-30-320.jpg)


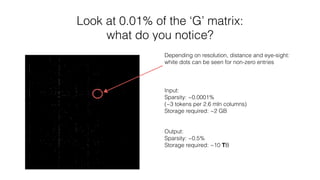




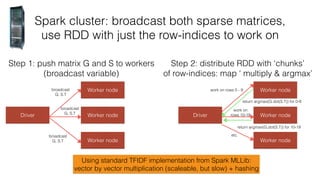



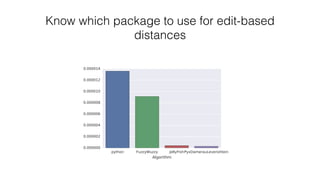
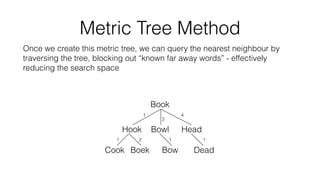
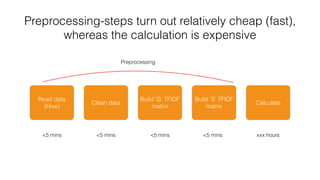
The document discusses the challenges of matching company names in large datasets due to variations in naming conventions, presenting three main approaches to solve the problem: brute force, metric tree, and tokenised methods. It highlights the inefficiencies of brute force due to high computational demands and introduces the tokenised method as a more efficient alternative by using matrix calculations and cosine similarity. The current status indicates ongoing optimization efforts using different computational resources like GPUs and Spark clusters for faster processing.


























![[Paper Reading] Steering Query Optimizers: A Practical Take on Big Data Workl...](https://cdn.slidesharecdn.com/ss_thumbnails/steersigmod21-210913065908-thumbnail.jpg?width=640&height=640&fit=bounds)
















































































