Download as PDF, PPTX




























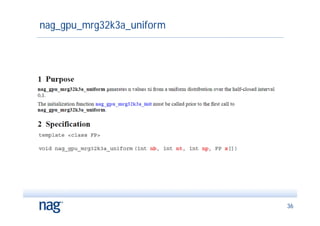




![Example program – kernel function
__global__ void mrg32k3a_kernel(int np, FP *d_P){
unsigned int v1[3], v2[3];
int n, i0;
FP x, x2 = nanf("");
// initialisation for first point
nag_gpu_mrg32k3a_stream_init(v1, v2, np);
// now do points
i0 = threadIdx.x + np*blockDim.x*blockIdx.x;
for (n=0; n<np; n++) {
nag_gpu_mrg32k3a_next_uniform(v1, v2, x);
}
d_P[i0] = x;
i0 += blockDim.x;
}
43](https://image.slidesharecdn.com/montecarlogpujan2010-100203065732-phpapp02/85/Monte-Carlo-G-P-U-Jan2010-43-320.jpg)


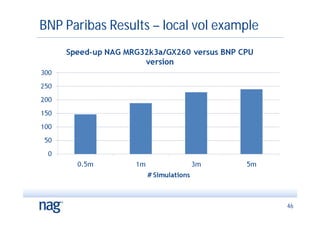







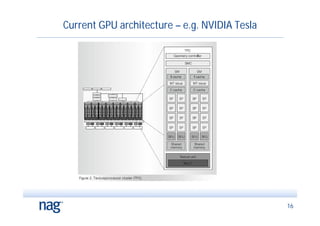
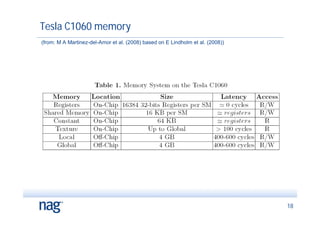
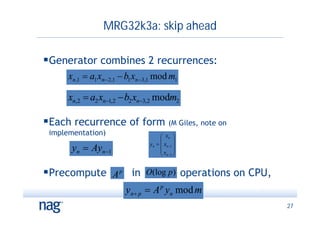
The document discusses the implementation of Monte Carlo simulation, emphasizing its importance for high-dimensional problems and applications with uncertainty, particularly in finance. It highlights advancements in GPU acceleration and higher order methods to improve performance on multi-core architectures. The text also covers numerical libraries that facilitate GPU use for Monte Carlo simulations and showcases examples of successful applications by financial institutions.


























































































