PG-Stromとは?
爆速Webinar#01 - 地理情報を爆速で処理するPG-Strom の新機能3
【機能】
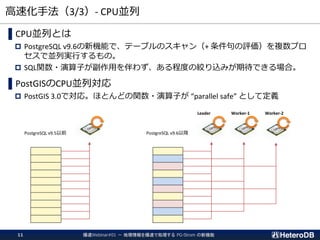
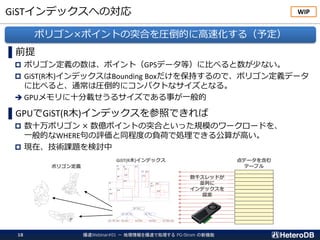
集計/解析ワークロードの透過的なGPU高速化
SQLからGPUプログラムを自動生成し並列実行
SSD-to-GPU Direct SQLによるPCIeバスレベルの最適化
GPUメモリにデータを常駐。OLTPワークロードとの共存
一部PostGIS関数のサポート。位置情報分析を高速化
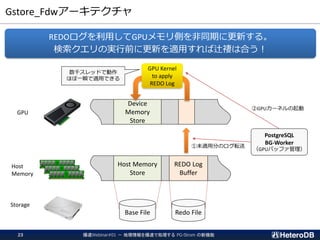
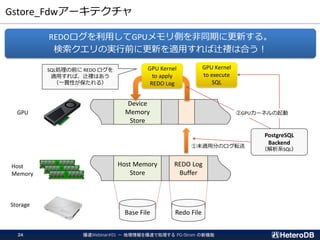
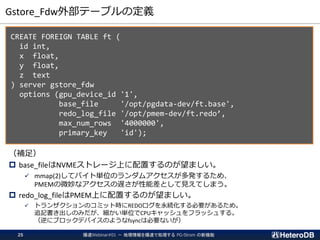
PG-Strom: GPUとNVME/PMEMの能力を最大限に引き出し、
テラバイト級のデータを高速処理するPostgreSQL向け拡張モジュール
App
GPU
off-loading
for IoT/Big-Data
for ML/Analytics
➢ SSD-to-GPU Direct SQL
➢ Columnar Store (Arrow_Fdw)
➢ GPU Memory Store (Gstore_Fdw)
➢ Asymmetric Partition-wise
JOIN/GROUP BY
➢ BRIN-Index Support
➢ NVME-over-Fabric Support
➢ Inter-process Data Frame
for Python scripts
➢ Procedural Language for
GPU native code (w/ cuPy)
➢ PostGIS Support
NEW
NEW
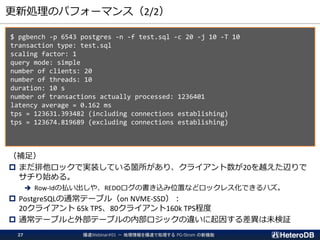
4.
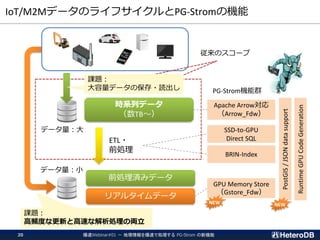
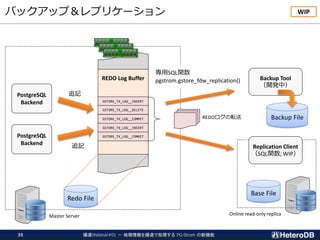
ログ収集デーモン:
ターゲット:IoT/M2Mログの集計・解析処理
爆速Webinar#01 - 地理情報を爆速で処理するPG-Strom の新機能4
Manufacturing Logistics Mobile Home electronics
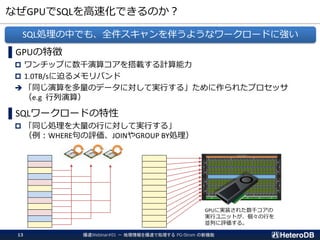
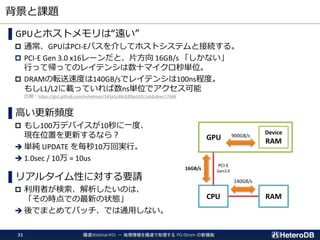
なぜPostgreSQLか?
シングルノードで処理できるならそっちの方が運用が楽
エンジニアが慣れ親しんが技術で、運用ノウハウの蓄積が豊富
JBoF: Just Bunch of Flash
NVME-over-Fabric
(RDMA)
DB管理者
BIツール(可視化)
機械学習アプリケーション
(E.g, 異常検知など)
共通データ
フレーム PG-Strom
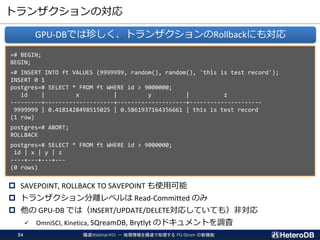
トランザクションの対応
SAVEPOINT, ROLLBACKTO SAVEPOINT も使用可能
トランザクション分離レベルは Read-Committed のみ
他の GPU-DB では(INSERT/UPDATE/DELETE対応していても)非対応
✓ OmniSCI, Kinetica, SQreamDB, Brytlyt のドキュメントを調査
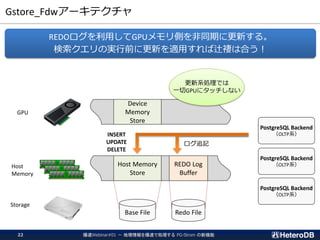
GPU-DBでは珍しく、トランザクションのRollbackにも対応
=# BEGIN;
BEGIN;
=# INSERT INTO ft VALUES (9999999, random(), random(), 'this is test record');
INSERT 0 1
postgres=# SELECT * FROM ft WHERE id > 9000000;
id | x | y | z
---------+--------------------+--------------------+---------------------
9999999 | 0.4181428498515025 | 0.5861937164356661 | this is test record
(1 row)
postgres=# ABORT;
ROLLBACK
postgres=# SELECT * FROM ft WHERE id > 9000000;
id | x | y | z
----+---+---+---
(0 rows)
爆速Webinar#01 - 地理情報を爆速で処理する PG-Strom の新機能34






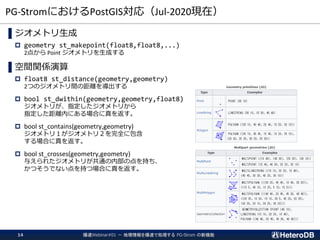
![PostGISって?(2/2)
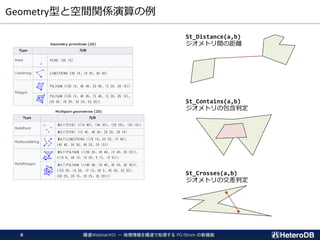
▌データ型
Geometry(投影座標系)、Geography(地理座標系)
▌ジオメトリ生成の例
geometry ST_MakePoint(float8 x, float8 y[, float8 z])
geometry ST_MakeLine(geometry point1, geometry point2)
…など
▌空間関係演算の例
float8 ST_Distance(geometry g1, geometry g2)
float8 ST_Distance(geography gg1, geography gg2)
bool ST_DWithin(geometry g1, geometry g2, float8 distance)
float8 ST_Area(geometry g1)
bool ST_Contains(geometry g1, geometry g2)
bool ST_Crosses(geometry g1, geometry g2)
…など
爆速Webinar#01 - 地理情報を爆速で処理する PG-Strom の新機能7](https://image.slidesharecdn.com/20200806pgstromnewfeatures-200806130812/85/20200806_PGStrom_PostGIS_GstoreFdw-7-320.jpg)


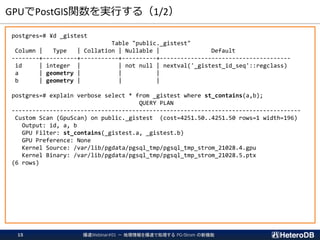



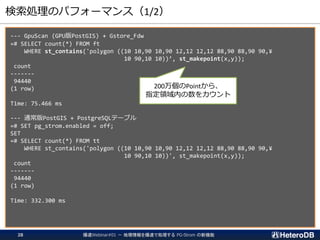
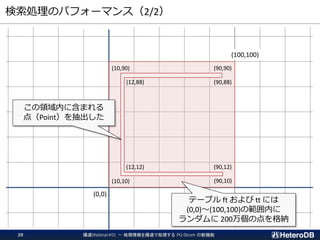
![検索+更新処理のパフォーマンス
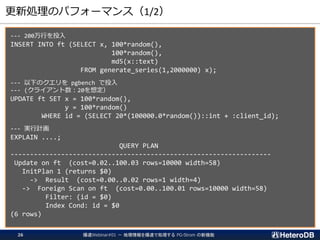
--- 裏で更新処理を実行
$ pgbench -p 6543 postgres -n -f test.sql -c 15 -T 60
:
duration: 60 s
number of transactions actually processed: 9188638
latency average = 0.098 ms
tps = 153143.595549 (including connections establishing)
tps = 153148.363454 (excluding connections establishing)
--- ヘビーな更新処理中に GPU での集計クエリを実行
=# SELECT count(*) FROM ft
WHERE st_contains('polygon ((10 10,90 10,90 12,12 12,12 88,90 88,90 90, ¥
10 90,10 10))', st_makepoint(x,y));
2020-07-26 17:26:12.283 JST [261916] LOG: gstore_fdw: Log applied (nitems=635787,
length=54396576, pos 750323824 => 787623328)
count
-------
94629
(1 row)
Time: 136.456 ms
ヘビーな更新処理中であっても、若干の処理速度低下で応答
集計処理の開始時点で、GPU側ストアを
最新の状態にリフレッシュするため、
未適用のREDOログを 63.5 万件適用している
爆速Webinar#01 - 地理情報を爆速で処理する PG-Strom の新機能30](https://image.slidesharecdn.com/20200806pgstromnewfeatures-200806130812/85/20200806_PGStrom_PostGIS_GstoreFdw-30-320.jpg)

















![[20170922 Sapporo Tech Bar] 地図用データを高速処理!オープンソースGPUデータベースMapDってどんなもの?? by 株式会社...](https://cdn.slidesharecdn.com/ss_thumbnails/20170922mapd-170926064811-thumbnail.jpg?width=640&height=640&fit=bounds)






















![GPUとSSDがPostgreSQLを加速する~クエリ処理スループット10GB/sへの挑戦~ [DB Tech Showcase Tokyo/2017]](https://cdn.slidesharecdn.com/ss_thumbnails/20170906dbtsgpussdacceleratespostgresqljp-170906073226-thumbnail.jpg?width=640&height=640&fit=bounds)
























