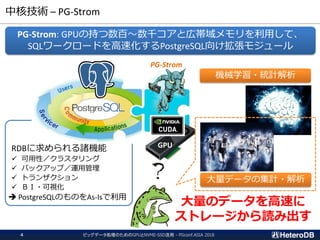
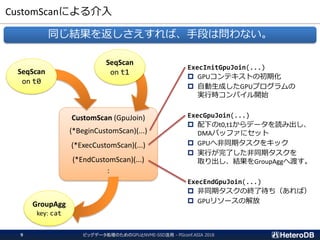
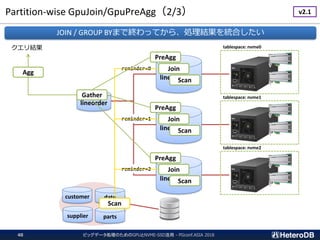
GpuScan + GpuJoin+ GpuPreAgg Combined Kernel (1/3)
Aggregation
GROUP BY
JOIN
SCAN
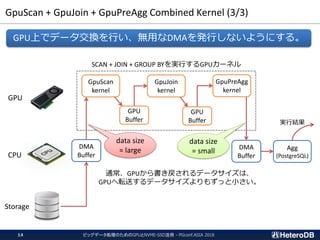
SELECT cat, count(*), avg(x)
FROM t0 JOIN t1 ON t0.id = t1.id
WHERE y like ‘%abc%’
GROUP BY cat;
count(*), avg(x)
GROUP BY cat
t0 JOIN t1
ON t0.id = t1.id
WHERE y like ‘%abc%’
実行結果
ビッグデータ処理のためのGPUとNVME-SSD活用 - PGconf.ASIA 201812
GpuScan
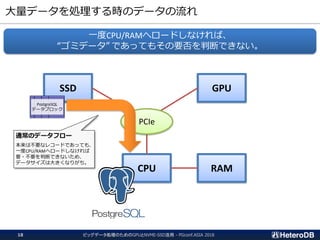
GpuJoin
Agg
+
GpuPreAgg
SeqScan
HashJoin
Agg
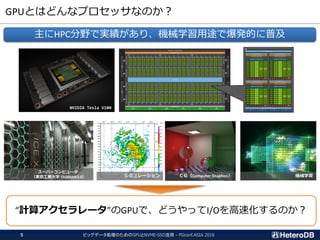
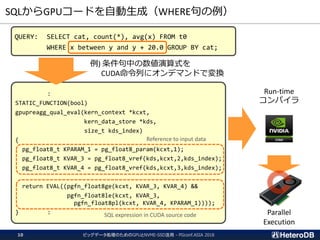
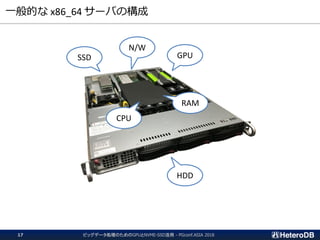
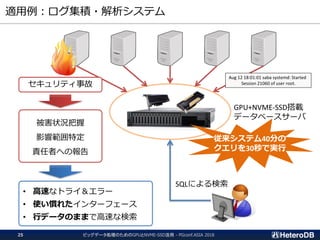
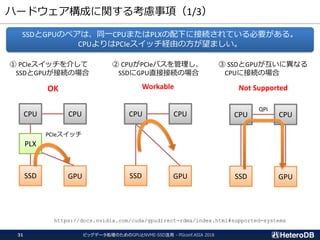
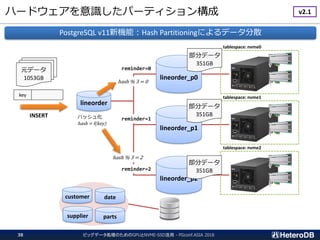
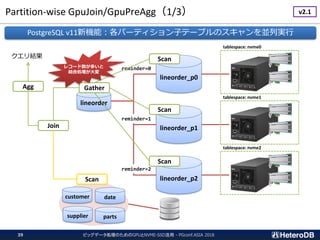
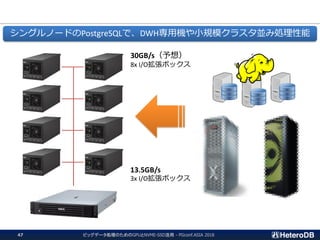
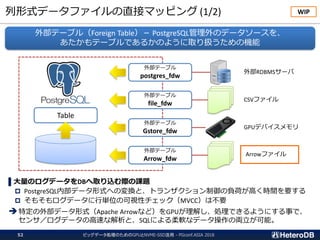
ハードウェア構成に関する考慮事項(1/3)
ビッグデータ処理のためのGPUとNVME-SSD活用 - PGconf.ASIA201831
① PCIeスイッチを介して
SSDとGPUが接続の場合
OK
② CPUがPCIeバスを管理し、
SSDにGPU直接接続の場合
Workable
③ SSDとGPUが互いに異なる
CPUに接続の場合
Not Supported
CPU CPU
PLX
SSD GPU
PCIeスイッチ
CPU CPU
SSD GPU
CPU CPU
SSD GPU
QPI
SSDとGPUのペアは、同一CPUまたはPLXの配下に接続されている必要がある。
CPUよりはPCIeスイッチ経由の方が望ましい。
https://docs.nvidia.com/cuda/gpudirect-rdma/index.html#supported-systems
32.
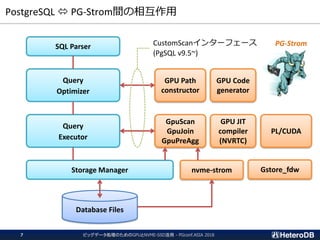
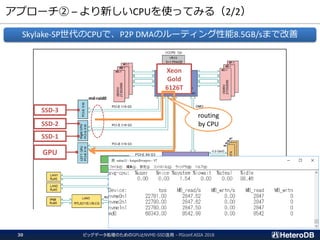
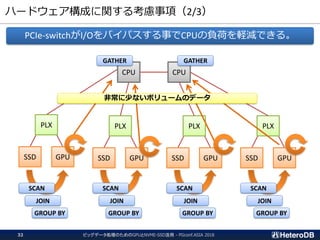
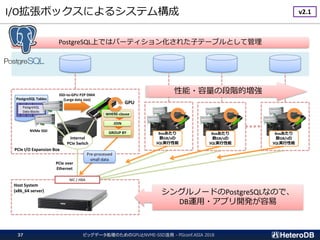
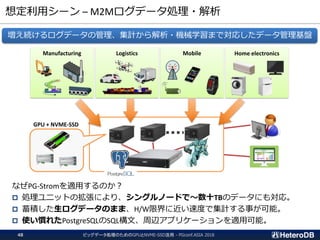
ハードウェア構成に関する考慮事項(2/3)
ビッグデータ処理のためのGPUとNVME-SSD活用 - PGconf.ASIA201832
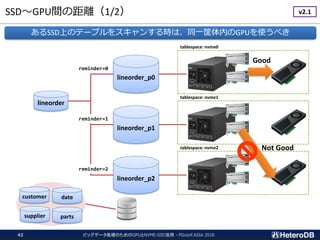
PCIe-switchがI/Oをバイパスする事でCPUの負荷を軽減できる。
CPU CPU
PLX
SSD GPU
PLX
SSD GPU
PLX
SSD GPU
PLX
SSD GPU
SCAN SCAN SCAN SCAN
JOIN JOIN JOIN JOIN
GROUP BY GROUP BY GROUP BY GROUP BY
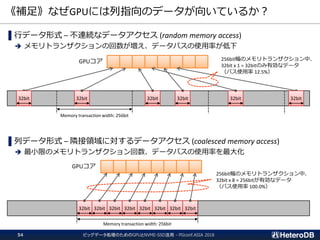
非常に少ないボリュームのデータ
GATHER GATHER
33.
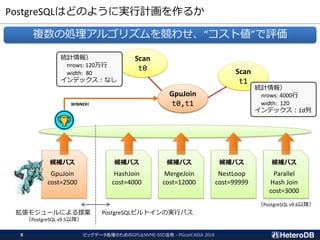
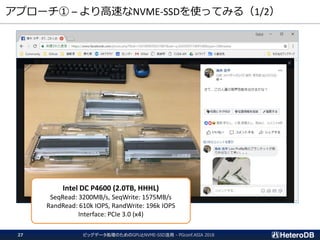
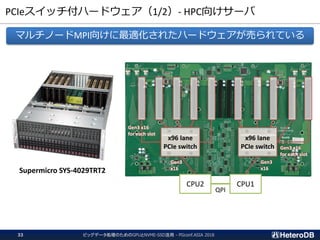
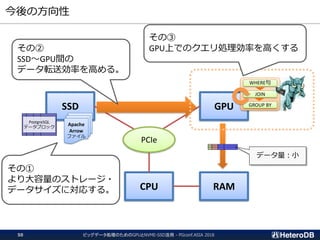
PCIeスイッチ付ハードウェア(1/2)- HPC向けサーバ
ビッグデータ処理のためのGPUとNVME-SSD活用 -PGconf.ASIA 201833
Supermicro SYS-4029TRT2
x96 lane
PCIe switch
x96 lane
PCIe switch
CPU2 CPU1
QPI
Gen3
x16
Gen3 x16
for each slot
Gen3 x16
for each slot
Gen3
x16
マルチノードMPI向けに最適化されたハードウェアが売られている
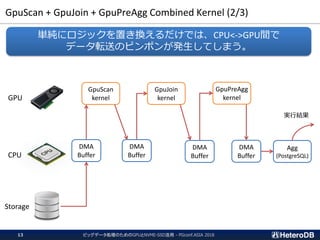
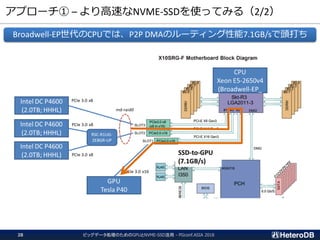
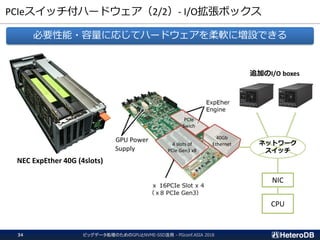
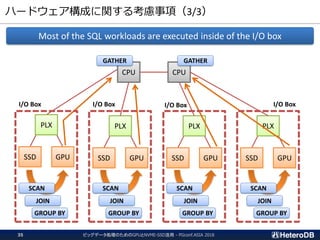
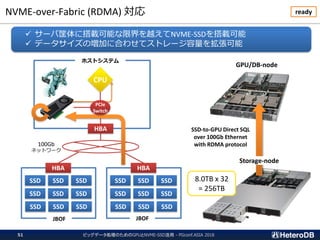
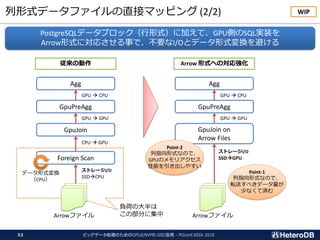
ハードウェア構成に関する考慮事項(3/3)
ビッグデータ処理のためのGPUとNVME-SSD活用 - PGconf.ASIA201835
Most of the SQL workloads are executed inside of the I/O box
CPU CPU
PLX
SSD GPU
PLX
SSD GPU
PLX
SSD GPU
PLX
SSD GPU
SCAN SCAN SCAN SCAN
JOIN JOIN JOIN JOIN
GROUP BY GROUP BY GROUP BY GROUP BY
GATHER GATHER
I/O BoxI/O BoxI/O BoxI/O Box

![テーマ:どのようにしてこのベンチマーク結果を実現したのか
ビッグデータ処理のためのGPUとNVME-SSD活用 - PGconf.ASIA 20182
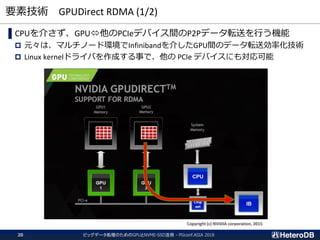
ベンチマーク条件
シングルノード環境でのPostgreSQL v11beta3とPG-Strom v2.1develによる結果。
1.05TBのデータベースに対して13種類のStar Schema Benchmark クエリを実行。
➔全件スキャンを含む集計系クエリを80秒弱で実行 ≒ 13.5GB/s
0
2,000
4,000
6,000
8,000
10,000
12,000
14,000
Q1_1 Q1_2 Q1_3 Q2_1 Q2_2 Q2_3 Q3_1 Q3_2 Q3_3 Q3_4 Q4_1 Q4_2 Q4_3
QueryExecutionThroughput[MB/s]
Star Schema Benchmark for PostgreSQL 11beta3 + PG-Strom v2.1devel
PG-Strom v2.1devel
max 13.5GB/sのクエリ処理速度をシングルノードで実現](https://image.slidesharecdn.com/20181211pgconfasiamultissd2gpu-181211065349/85/20181211-PGconf-ASIA-NVMESSD-GPU-for-BigData-2-320.jpg)





![ベンチマーク結果(シングルノード)
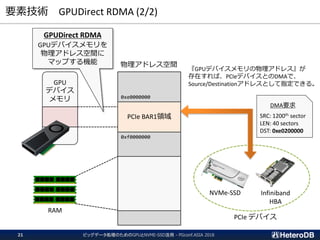
NVME and GPU accelerates PostgreSQL beyond the limitation -PGconf.EU 2018-22
2172.3 2159.6 2158.9 2086.0 2127.2 2104.3
1920.3
2023.4 2101.1 2126.9
1900.0 1960.3
2072.1
6149.4 6279.3 6282.5
5985.6 6055.3 6152.5
5479.3
6051.2 6061.5 6074.2
5813.7 5871.8 5800.1
0
1000
2000
3000
4000
5000
6000
7000
Q1_1 Q1_2 Q1_3 Q2_1 Q2_2 Q2_3 Q3_1 Q3_2 Q3_3 Q3_4 Q4_1 Q4_2 Q4_3
QueryProcessingThroughput[MB/sec]
Star Schema Benchmark on NVMe-SSD + md-raid0
PgSQL9.6(SSDx3) PGStrom2.0(SSDx3) H/W Spec (3xSSD)
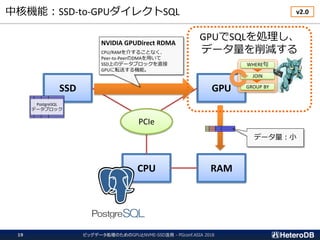
SSD-to-GPU Direct SQLでハードウェアの限界に近いSQL処理速度を実現
DBサイズ 353GB (sf: 401) の Star Schema Benchmark を用いてクエリ処理時間を計測
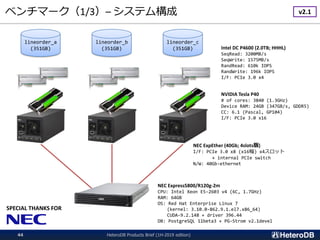
CPU: Intel Xeon E5-2650v4, RAM: 128GB, GPU: NVIDIA Tesla P40, SSD: Intel 750 (400GB; SeqRead 2.2GB/s)x3
NVME-SSDの理論限界は 2.2GB/s x 3 = 6.6GB/s。SQL処理スループットもそれに近い 6.2GB/s まで出ている。](https://image.slidesharecdn.com/20181211pgconfasiamultissd2gpu-181211065349/85/20181211-PGconf-ASIA-NVMESSD-GPU-for-BigData-22-320.jpg)
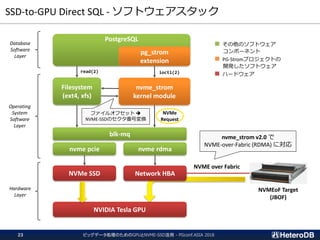




![SSD~GPU間の距離(2/2)
ビッグデータ処理のためのGPUとNVME-SSD活用 - PGconf.ASIA 201843
$ pg_ctl restart
:
LOG: - PCIe[0000:80]
LOG: - PCIe(0000:80:02.0)
LOG: - PCIe(0000:83:00.0)
LOG: - PCIe(0000:84:00.0)
LOG: - PCIe(0000:85:00.0) nvme0 (INTEL SSDPEDKE020T7)
LOG: - PCIe(0000:84:01.0)
LOG: - PCIe(0000:86:00.0) GPU0 (Tesla P40)
LOG: - PCIe(0000:84:02.0)
LOG: - PCIe(0000:87:00.0) nvme1 (INTEL SSDPEDKE020T7)
LOG: - PCIe(0000:80:03.0)
LOG: - PCIe(0000:c0:00.0)
LOG: - PCIe(0000:c1:00.0)
LOG: - PCIe(0000:c2:00.0) nvme2 (INTEL SSDPEDKE020T7)
LOG: - PCIe(0000:c1:01.0)
LOG: - PCIe(0000:c3:00.0) GPU1 (Tesla P40)
LOG: - PCIe(0000:c1:02.0)
LOG: - PCIe(0000:c4:00.0) nvme3 (INTEL SSDPEDKE020T7)
LOG: - PCIe(0000:80:03.2)
LOG: - PCIe(0000:e0:00.0)
LOG: - PCIe(0000:e1:00.0)
LOG: - PCIe(0000:e2:00.0) nvme4 (INTEL SSDPEDKE020T7)
LOG: - PCIe(0000:e1:01.0)
LOG: - PCIe(0000:e3:00.0) GPU2 (Tesla P40)
LOG: - PCIe(0000:e1:02.0)
LOG: - PCIe(0000:e4:00.0) nvme5 (INTEL SSDPEDKE020T7)
LOG: GPU<->SSD Distance Matrix
LOG: GPU0 GPU1 GPU2
LOG: nvme0 ( 3) 7 7
LOG: nvme5 7 7 ( 3)
LOG: nvme4 7 7 ( 3)
LOG: nvme2 7 ( 3) 7
LOG: nvme1 ( 3) 7 7
LOG: nvme3 7 ( 3) 7
PCIeデバイス間の距離に基づいて、
最適なGPUを自動的に選択する
v2.1](https://image.slidesharecdn.com/20181211pgconfasiamultissd2gpu-181211065349/85/20181211-PGconf-ASIA-NVMESSD-GPU-for-BigData-43-320.jpg)
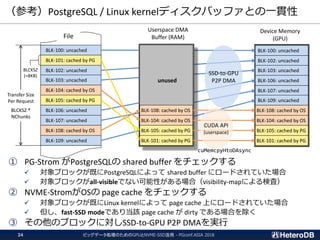
![ベンチマーク(2/3) – 測定結果
ビッグデータ処理のためのGPUとNVME-SSD活用 - PGconf.ASIA 201845
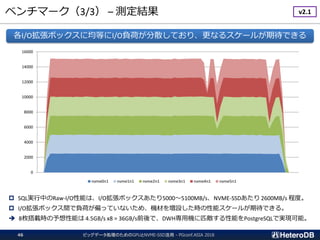
I/O拡張ボックス毎に351GB、計1055GBのデータベースを構築し、13種類のSSBMクエリを実行
SQL実行を伴わない SSD→Host への Raw-I/O データ転送は 9GB/s 弱が限界。
つまり、Raw-I/Oのストレージ読出しよりも、SQLを高速に実行てきている。
2,388 2,477 2,493 2,502 2,739 2,831
1,865
2,268 2,442 2,418
1,789 1,848
2,202
13,401 13,534 13,536 13,330
12,696
12,965
12,533
11,498
12,312 12,419 12,414 12,622 12,594
0
2,000
4,000
6,000
8,000
10,000
12,000
14,000
Q1_1 Q1_2 Q1_3 Q2_1 Q2_2 Q2_3 Q3_1 Q3_2 Q3_3 Q3_4 Q4_1 Q4_2 Q4_3
QueryExecutionThroughput[MB/s]
Star Schema Benchmark for PgSQL v11beta3 / PG-Strom v2.1devel on NEC ExpEther x3
PostgreSQL v11beta3 PG-Strom v2.1devel Raw-I/O限界値
I/O拡張ボックス3台構成で、max 13.5GB/s のクエリ処理速度を実現!
v2.1](https://image.slidesharecdn.com/20181211pgconfasiamultissd2gpu-181211065349/85/20181211-PGconf-ASIA-NVMESSD-GPU-for-BigData-45-320.jpg)
















![[20170922 Sapporo Tech Bar] 地図用データを高速処理!オープンソースGPUデータベースMapDってどんなもの?? by 株式会社...](https://cdn.slidesharecdn.com/ss_thumbnails/20170922mapd-170926064811-thumbnail.jpg?width=640&height=640&fit=bounds)










![[db tech showcase Tokyo 2017] B35: 地図用データを高速処理!オープンソースGPUデータベースMapDの魅力に迫る!!by...](https://cdn.slidesharecdn.com/ss_thumbnails/b35-170912021017-thumbnail.jpg?width=640&height=640&fit=bounds)












![GPUとSSDがPostgreSQLを加速する~クエリ処理スループット10GB/sへの挑戦~ [DB Tech Showcase Tokyo/2017]](https://cdn.slidesharecdn.com/ss_thumbnails/20170906dbtsgpussdacceleratespostgresqljp-170906073226-thumbnail.jpg?width=640&height=640&fit=bounds)












![[db analytics showcase Sapporo 2018] B25 Hadoop上で動く世界最速のAnalytic DBをSparkと一緒に...](https://cdn.slidesharecdn.com/ss_thumbnails/dbassapporo2018b25-180628051851-thumbnail.jpg?width=640&height=640&fit=bounds)















