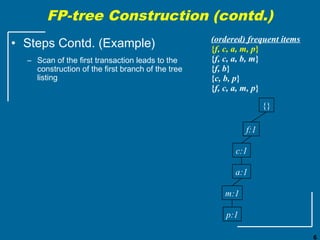
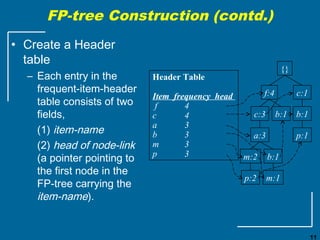
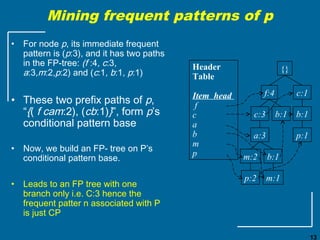
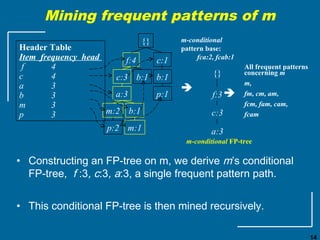
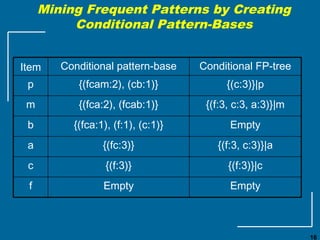
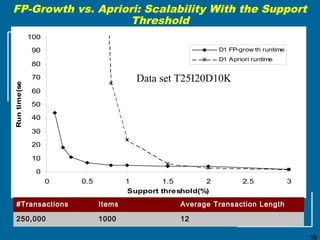
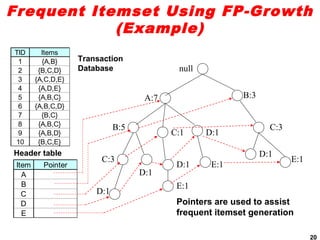
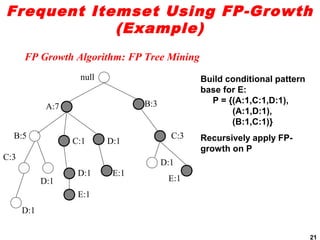
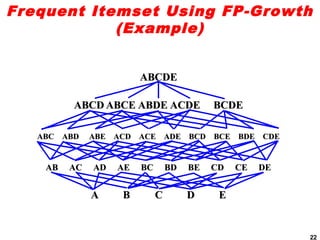
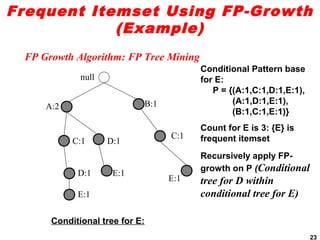
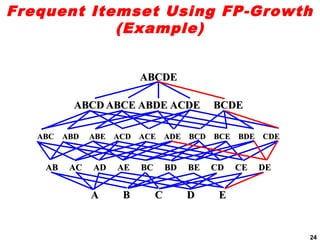
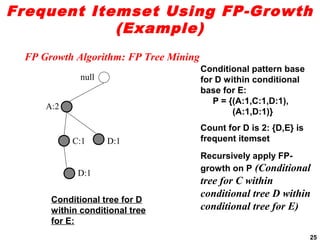
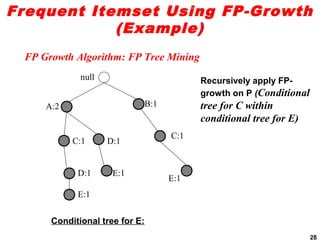
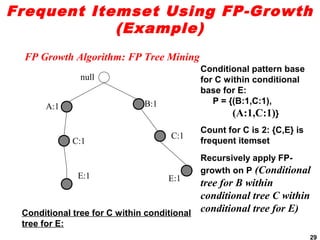
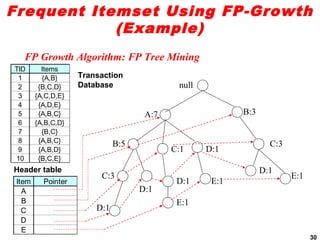
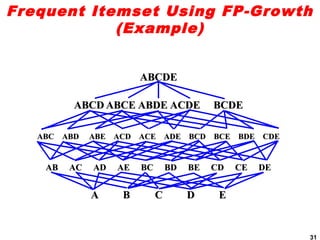
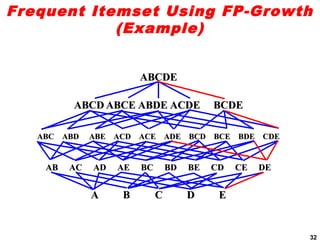
The document discusses the FP-growth algorithm for mining frequent patterns without candidate generation. It begins with an overview of the performance bottlenecks of the Apriori algorithm and introduces the FP-growth approach. The key steps of FP-growth include compressing the transaction database into a frequent-pattern tree (FP-tree) structure, and then mining the FP-tree to find all frequent patterns. The mining process recursively constructs conditional FP-trees to decompose the problem into smaller sub-problems without candidate generation. Examples are provided to illustrate the FP-tree construction and pattern mining.