Download to read offline


![International Journal of Advanced Research in Engineering and Technology (IJARET), ISSN 0976 –
6480(Print), ISSN 0976 – 6499(Online) Volume 5, Issue 2, February (2014), pp. 52-60, © IAEME
(Knowledge Discovery from Data) [10]. Data mining is to find valid, novel, potentially useful and
ultimately understandable patterns in data. In general there are many kinds of patterns that can
be discovered from data . For example, association rules can be mined for market basket analysis,
classification rules can be found for accurate classifiers, clusters and outliers can be identified
for customer relationship management [10]. There are mainly two types in ARM first is frequent
pattern generation and another one is to generate rules from frequent patterns. A well known
algorithm for frequent pattern mining is Apriori. Apriori is a classical algorithm that requires
candidate generation and multiple database scans to find frequent patterns [1] [2] [3]. To overcome
the limitations of Apriori Han et al. propose a data structure, frequent pattern tree or FP-Tree, and an
algorithm called FP-growth that allows mining of frequent item sets without generating candidate
item sets. Still there are some limitations that FP-growth requires two database scan and does not
support iterative and incremental mining [4] [5]. CATS-tree requires only one database scan and also
supports iterative mining but merging and splitting of nodes create bottlenecks [6]. To overcome this
limitation researchers have proposed CAN tree [8] [9]. It uses some canonical order to construct the
tree. It enables incremental mining. Proposed algorithms enable frequent pattern mining with
different supports without rebuilding the tree structure. It also allows mining with a single pass over
the database as well as efficient insertion or deletion of transactions at any time.
This paper is organized as follows. Section II discusses about related background of the frequent
pattern mining. Section III discusses our proposed Tree method. Section IV shows the comparison of
existing algorithm. Section V shows the experimental results, and Conclusion is discussed in section
VI.
II. RELATED BACKGROUNDS
A. Apriori Algorithm
Apriori is a well known algorithm for frequent pattern mining. It uses generate and test
approach. First step is to generate candidates item sets from the given database then to test whether it
is frequent or not if any item set does not support minimum threshold value then remove that item.
Important property of Apriori is its anti monotone approach that all nonempty subsets of a super set
must also be frequent. Drawbacks of Apriori are candidate generation and multiple database scan [1]
[2] [3] [10].
B. FP-growth Algorithm
It overcomes the limitations of Apriori like huge no. of candidate generation and need to scan
database again and again. It uses Divide and conquers approach. It compresses the database
representing frequent patterns into a FP-Tree which contain the item sets association information.
Construction of FP-tree uses two pass. In first pass Take Database D Scan and generate 1-itemsets by
sorted frequent items in order of descending support count and in second pass Construction of FPtree. Create root nod as “null”. Use linked list concept and start construction of FP-tree using support
count. For mining the frequent patterns take initial suffix pattern from FP-tree then Construct
conditional pattern base that is “Sub-database which contains set of prefix paths in FP-tree cooccurring with the suffix pattern”. Perform mining recursively on the tree. Drawbacks are FP-Tree
may not fit in memory, FP-Tree is expensive to build, does not support incremental mining [4] [5]
[10].
C. ECLAT Algorithm
It uses TID (transactional id). It uses vertical data format (horizontal transactional can be
transformed into the vertical data format) [10].
53](https://image.slidesharecdn.com/20120140502006-140227233043-phpapp02/85/20120140502006-2-320.jpg)
![International Journal of Advanced Research in Engineering and Technology (IJARET), ISSN 0976 –
6480(Print), ISSN 0976 – 6499(Online) Volume 5, Issue 2, February (2014), pp. 52-60, © IAEME
D. CATS-tree and FELINE Algorithm
CATS tree is compressed and Arranged Transaction Sequences tree algorithm. It is an
extension of FP-tree. Use only single data scan. It contains all elements of FP-tree. It supports
Interactive mining. But Tree construction is expensive to build. Swapping and/or merging of nodes
require extra cost. The algorithm needs to traverse both upward and downward to include frequent
items [4] [6].
E. CAN tree
To overcome the limitation of existing algorithms like extra cost for swapping and/or
merging of nodes researchers have proposed CAN tree. In the Can Tree, items are arranged
according to some canonical order, which is unaffected by frequency changes. The frequency of a
node in the Can Tree is at least as high as the sum of frequencies of all its children. Use only single
data scan. Support Iterative mining and Incremental Mining. But still tree construction requires more
memory [8] [9].
F. Variant of CAN-tree
A variant of Can Tree is called CANTries. It reduces the size of node. Use only single data
scan. The structure of a Can Tries is quite similar to that of the Can Tree, except that nodes along the
same path are combining into a mega-node if they have the same frequency. It overcomes the
memory problem of CAN Tree [8] [9].
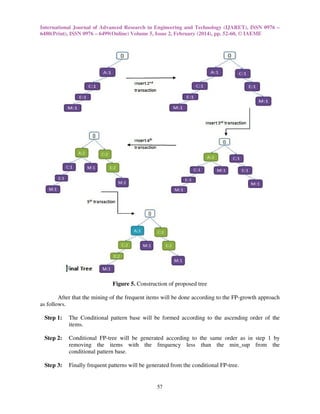
III. PROPOSED ALGORITHM
In FP-growth algorithm it works on two pass first is to Take Database D. Scan and generate
1-itemsets by sorted frequent items in order of descending support count shown in figure 1 then in
second pass Construction of FP-tree. Create root nod as “null”. Use linked list concept and start
construction of FP-tree using support count which is shown in figure 2. Finally mine patterns by
using conditional pattern base and conditional FP-tree.
Figure 1. First pass of FP-growth
54](https://image.slidesharecdn.com/20120140502006-140227233043-phpapp02/85/20120140502006-3-320.jpg)


![International Journal of Advanced Research in Engineering and Technology (IJARET), ISSN 0976 –
6480(Print), ISSN 0976 – 6499(Online) Volume 5, Issue 2, February (2014), pp. 52-60, © IAEME
IV. COMPARISON
Figure shows comparison between existing algorithms of frequent pattern mining by various
parameters.
Figure 6. Comparison
V. EXPERIMENTAL RESULTS
In these experiments, transaction databases generated by IBM [11] are used in computer
system having core 2 duo 2.0 GHz processor, 160 GB hard disk and 2 GB RAM.
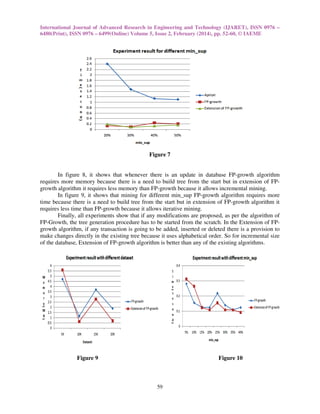
The goal of experiment is to find out the performance of proposed algorithm over existing
algorithms. In figure 7, it shows comparison between Apriori, FP-growth and Extension of FPgrowth by requiring time for different min_sup value. Results show that Extension of FP-growth
requires minimum time as compared to Apriori and FP-growth. The Apriori algorithm works on the
principle of candidate generate and test, so it requires the maximum execution time.
58](https://image.slidesharecdn.com/20120140502006-140227233043-phpapp02/85/20120140502006-7-320.jpg)
![International Journal of Advanced Research in Engineering and Technology (IJARET), ISSN 0976 –
6480(Print), ISSN 0976 – 6499(Online) Volume 5, Issue 2, February (2014), pp. 52-60, © IAEME
VI. CONCLUSION
A Novel approach has been implemented to provide the efficient and powerful tree support
for incremental mining. The extension of FP-growth algorithm captures transactions of database and
arranges nodes according to alphabetical order that is unaffected by changes in item frequency. By
exploiting its nice properties, the extension of FP-growth algorithm can be easily maintained when
there is an update in database transactions. Extension of FP-growth does not require merging and/or
splitting of tree nodes. It avoids the rescan of the entire updated database or the construction of a tree
from the scratch for incremental updating.
REFERENCES
[1]
[2]
[3]
[4]
[5]
[6]
[7]
[8]
[9]
[10]
[11]
[12]
[13]
[14]
[15]
Agrawal R, Imielinski T, Swami AN. "Mining Association Rules between Sets of Items in
Large Databases." SIGMOD. June 1993.
R. Agrawal and R. Srikant, “Fast algorithms for mining association rules”, Proceeding of
the 20th VLDB Conference Santiago, Chile 1994.
R Agrawal, Mannila H, Toivonen H, Verkamo AI. “Fast Discovery of Association Rules." at
Quest Project at IBM Almaden Research Centre and research at the university of
Helsinki 1994.
Cheung W., ”Frequent Pattern mining without candidate generation or support
constraint.” Master’s thesis, University of Alberta, 2002.
Jiawei Han, Jian Pei, and Yiwen Yin,” Mining Frequent Patterns without Candidate
Generation “, Simon Fraser University, 2002.
William Cheung and Osmar R. Zaiane, “Incremental Mining of Frequent Patterns without
candidate Generation or Support Constraint”, IDEAS’03.
Christian Borgelt, “An Implementation of the FP-growth Algorithm” OSDM’05.
Q. I. Khan, T. Hoque and C. K. Leung, “CANTree: A Tree structure for Efficient
Incremental mining of frequent patterns”, ICDM ’05.
Sanjay Patel and Dr. Ketan Kotecha, “Incremental Frequent Pattern Mining using Graph
based approach”, International Journal of Computers & Technology, March-April 2013.
Jiawei Han and Micheline Kamber, Book.”Data Mining, Concept and Techniques”.
http://www.almaden.ibm.com/cs/quest//syndata.html#assocSynData
M. Karthikeyan, M. Suriya Kumar and Dr. S. Karthikeyan, “A Literature Review on the Data
Mining and Information Security”, International Journal of Computer Engineering &
Technology (IJCET), Volume 3, Issue 1, 2012, pp. 141 - 146, ISSN Print: 0976 – 6367,
ISSN Online: 0976 – 6375.
R. Manickam, D. Boominath and V. Bhuvaneswari, “An Analysis of Data Mining: Past,
Present and Future”, International Journal of Computer Engineering & Technology (IJCET),
Volume 3, Issue 1, 2012, pp. 1 - 9, ISSN Print: 0976 – 6367, ISSN Online: 0976 – 6375.
R. Lakshman Naik, D. Ramesh and B. Manjula, “Instances Selection Using Advance Data
Mining Techniques”, International Journal of Computer Engineering & Technology (IJCET),
Volume 3, Issue 2, 2012, pp. 47 - 53, ISSN Print: 0976 – 6367, ISSN Online: 0976 – 6375.
Rinal H. Doshi, Dr. Harshad B. Bhadka and Richa Mehta, “Development of Pattern
Knowledge Discovery Framework Using Clustering Data Mining Algorithm”, International
Journal of Computer Engineering & Technology (IJCET), Volume 4, Issue 3, 2013,
pp. 101 - 112, ISSN Print: 0976 – 6367, ISSN Online: 0976 – 6375.
60](https://image.slidesharecdn.com/20120140502006-140227233043-phpapp02/85/20120140502006-9-320.jpg)

The document describes a novel approach for frequent pattern mining from large databases. It proposes constructing a tree structure based on a canonical (lexicographic) order of items rather than support count. This allows mining frequent patterns with a single pass over the database and supports incremental and iterative mining as transactions are added, deleted or modified. The algorithm is compared to existing methods like Apriori, FP-Growth, CATS-tree and CAN-tree which have limitations around candidate generation, multiple database scans or not supporting iterative/incremental mining. Experimental results demonstrate the advantages of the proposed approach.
































![[4]](https://cdn.slidesharecdn.com/ss_thumbnails/4-110623204652-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)















![3.[18 22]hybrid association rule mining using ac tree](https://cdn.slidesharecdn.com/ss_thumbnails/3-18-22hybridassociationruleminingusingactree-111125091146-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)
![3.[18 22]hybrid association rule mining using ac tree](https://cdn.slidesharecdn.com/ss_thumbnails/3-18-22hybridassociationruleminingusingactree-111203185002-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)















































