Download to read offline

![Frequent patterns play an essential role in association Rule
An association rule is an implication of the form[2] :
X → Y, where X, Y ⊂ I, and X ∩Y = ∅
A transaction t contains X, a set of items in I, if X ⊆ t.
Each rule has two quality measurements:
“A → Β [support s, confidence c]”.
Support: usefulness of discovered rules
Confidence: certainty of the detected association
Rules that satisfy both min_sup and min_conf are called strong.
3
n
countYX
support
).( ∪
=
countX
countYX
confidence
.
).( ∪
=](https://image.slidesharecdn.com/fp-growthtreeimproveitsefficiencyandscalability-170319034335/75/Fp-growth-tree-improve-its-efficiency-and-scalability-3-2048.jpg)









![[1] JIAWEI HAN “Technologies for Mining Frequent Patterns in Large Databases”, Simon Fraser University, canada.
[2] R. Agrawal and R. Srikant. “Fast algorithms for mining association rules”. In Proc. VLDB’94, Chile, September 1994
[3] Akshita Bhandari, Ashutosh Gupta, Debasis Das “Improvised apriori algorithm using frequent pattern tree for real time
applications in data mining” in Elsevier2014.
[4] O.Jamsheela, Raju.G: “An Adaptive Method for Mining Frequent Itemsets Efficiently: An Improved Header Tree Method” In
IEEE2015.
[5] Wei-Tee Lin and Chih-Ping Chu “Using Appropriate Number of Computing Nodes for Parallel Mining of Frequent Patterns”
in IEEE2014.
[6] Dang Nguyen , Bay Vo , Bac Le “Efficient strategies for parallel mining class association rules” in Elsevier 2014.
[7] Sheetal Rathi , Dr.Chandrashekhar.A.Dhote “Using Parallel Approach in Pre-processing to Improve Frequent Pattern Growth
Algorithm” in IEEE2014.
17](https://image.slidesharecdn.com/fp-growthtreeimproveitsefficiencyandscalability-170319034335/75/Fp-growth-tree-improve-its-efficiency-and-scalability-17-2048.jpg)


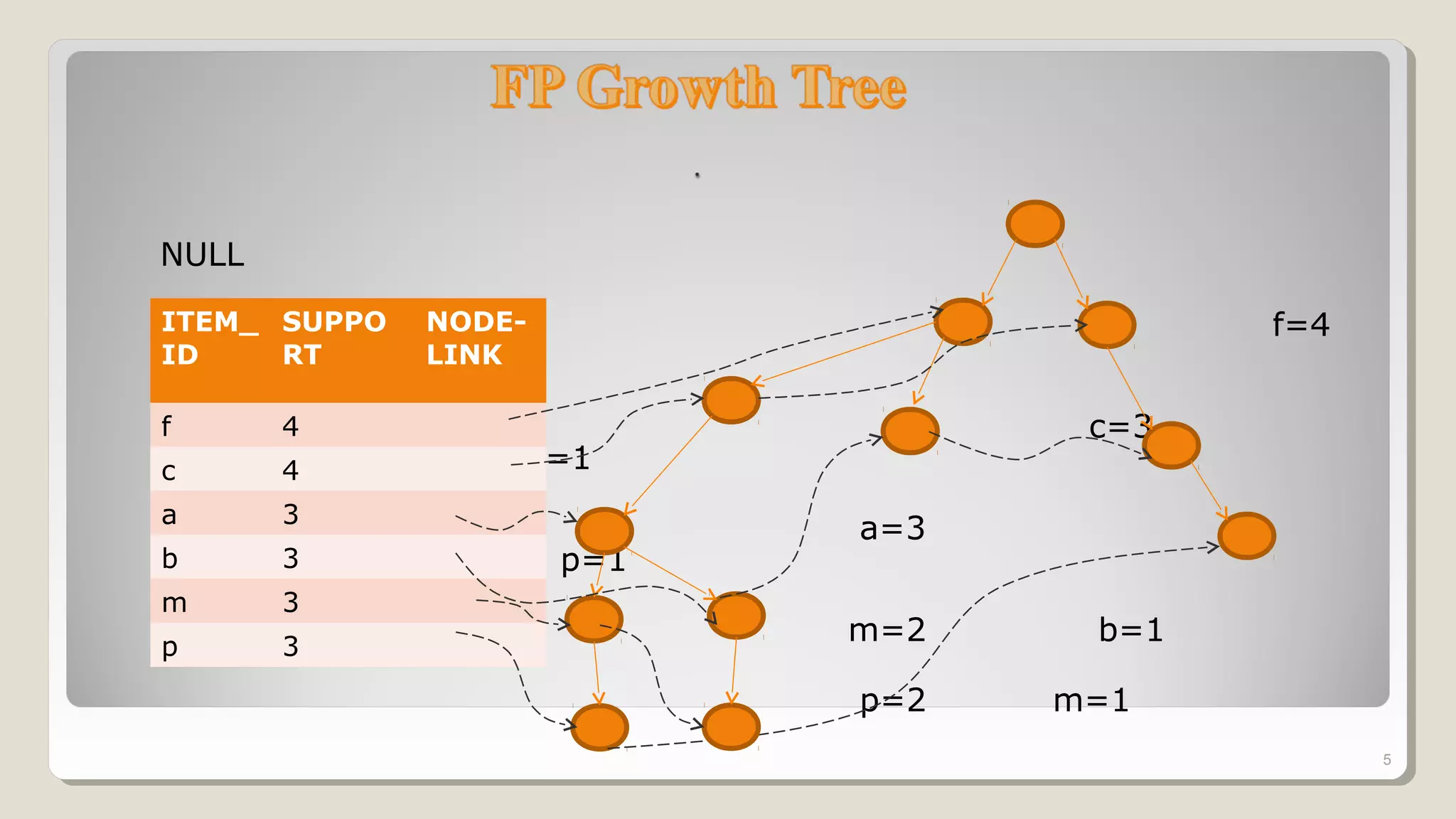
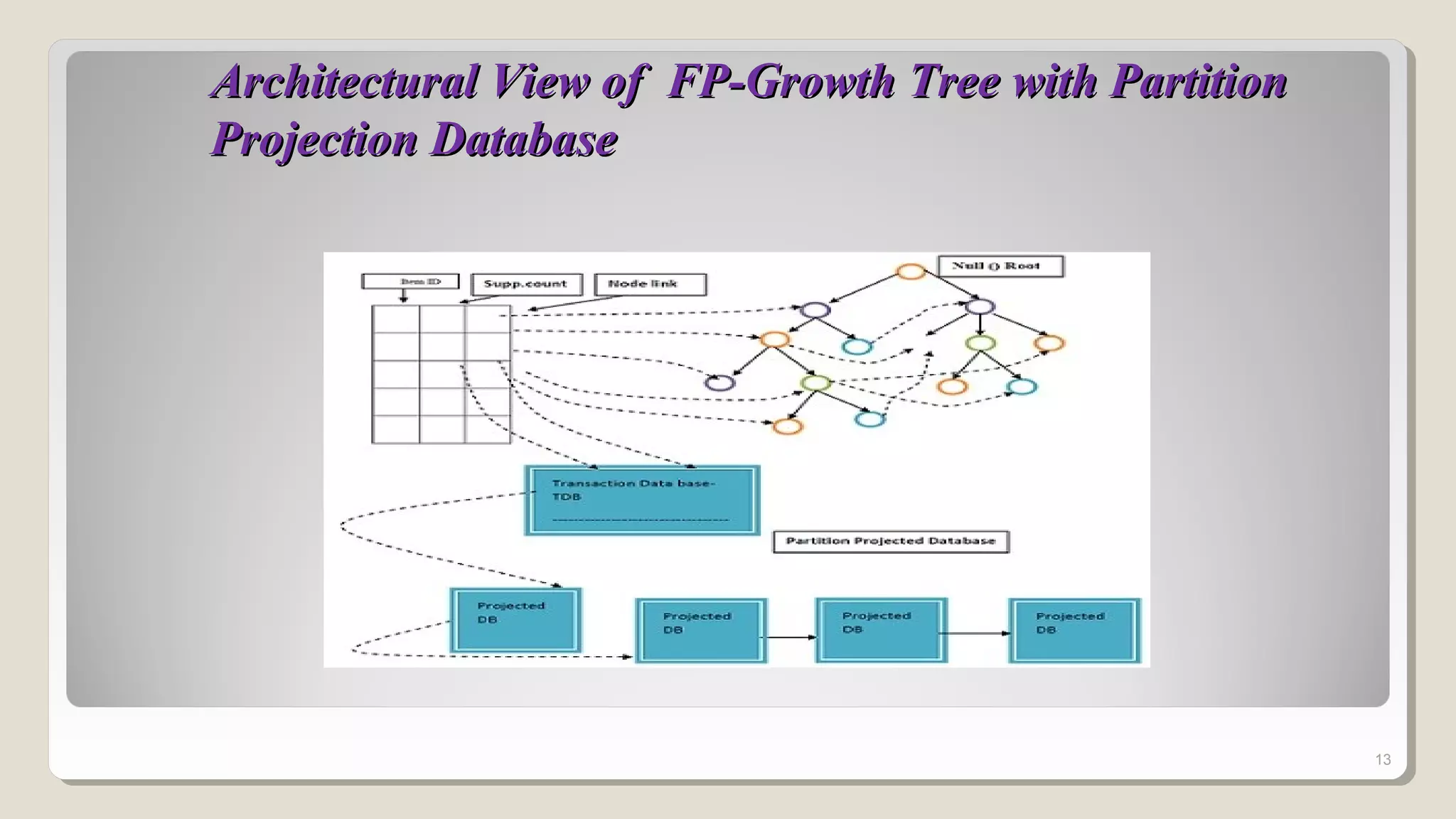
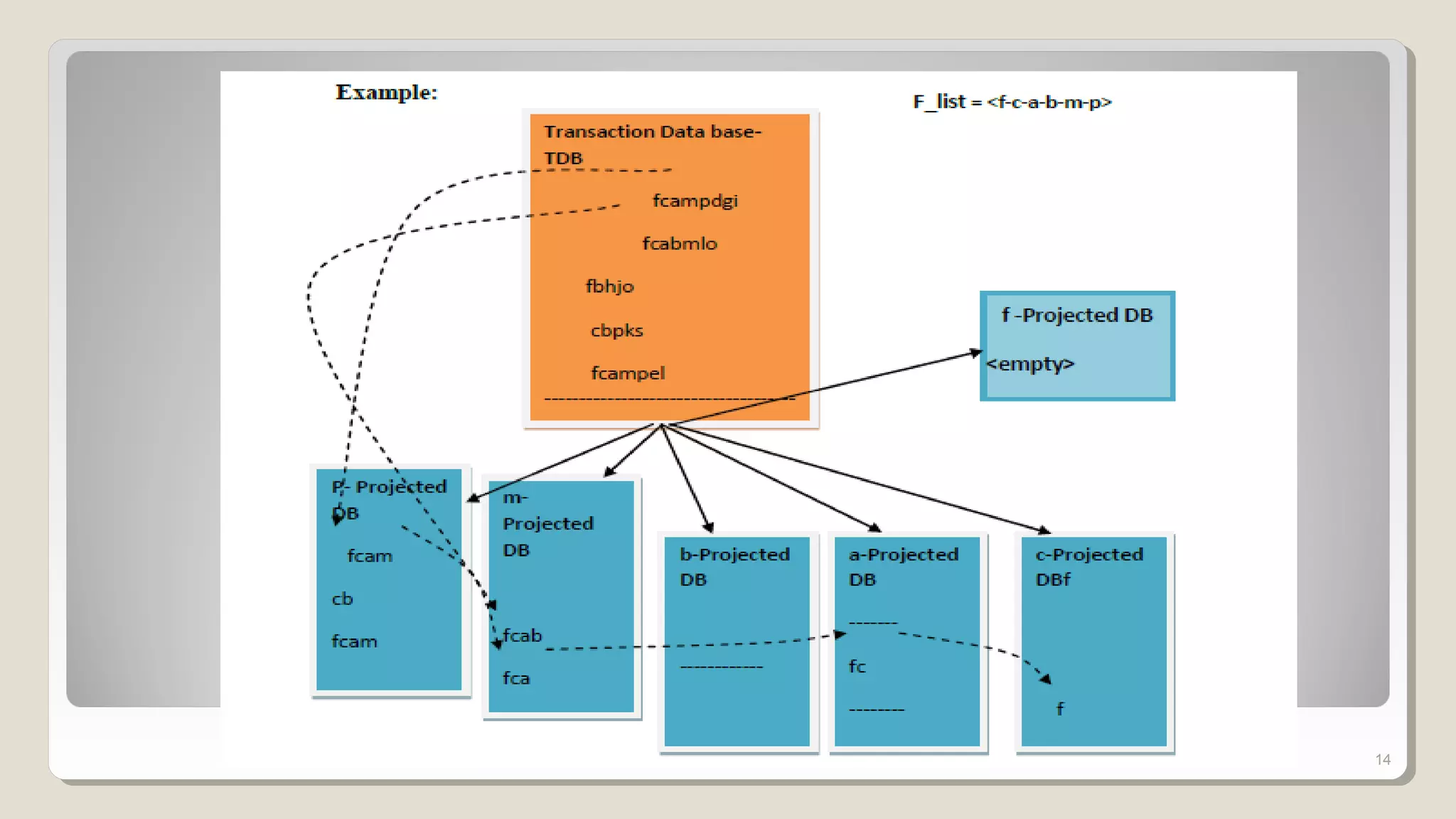
The document discusses frequent patterns in databases, particularly in the context of association rule mining and the FP-growth algorithm. It highlights the challenges of traditional methods like the apriori algorithm and presents the FP-tree and projection methods as efficient alternatives for mining. Additionally, it describes two projection strategies: parallel and partition projection, which help reduce the computational cost and memory usage during data mining processes.











































![[테크앤로] 세계소비자의날 토론 개인정보보호 패러다임의 변화 170315_구태언](https://cdn.slidesharecdn.com/ss_thumbnails/tek170315-170319034301-thumbnail.jpg?width=640&height=640&fit=bounds)











































