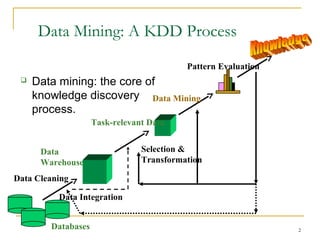
Data mining involves multiple steps in the knowledge discovery process including data cleaning, integration, selection, transformation, mining, and pattern evaluation. It has various functionalities including descriptive mining to characterize data, predictive mining for inference, and different mining techniques like classification, association analysis, clustering, and outlier analysis.