Downloaded 28 times




![The association rule mining algorithm is given as below:
» Input: D, ,
» Output: R(D, , )
» 1: Compute F(D, )
» 2: R := {}
» 3: for all I 2 F do
» 4: R := R [ I ) {}
» 5: C1 := {{i} | i 2 I};
» 6: k := 1;
» 7: while Ck 6= {} do
» 8: // Extract all heads of confident association rules
» 9: Hk := {X 2 Ck | confidence(I X ) X,D) }
» 10: // Generate new candidate heads
» 11: for all X, Y 2 Hk,X[i] = Y [i] for 1 i k−1, and X[k] < Y [k] do
» 12: I = X [ {Y [k]}
» 13: if 8J I, |J| = k : J 2 Hk then
» 14: Ck+1 := Ck+1 [ I
» 15: end if
» 16: end for
» 17: k++
» 18: end while
» 19: // Cumulate all association rules
» 20: R := R [ {I X ) X | X 2 H1 [ · · · [ Hk}
» 21: end](https://image.slidesharecdn.com/efficientfrequentpatternminingindistributedsystem-130918043234-phpapp02/85/Efficient-frequent-pattern-mining-in-distributed-system-5-320.jpg)




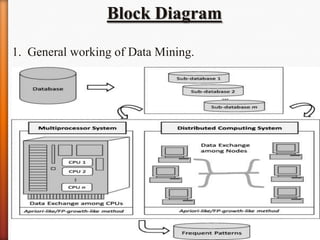





The document discusses efficient frequent pattern mining within distributed systems, focusing on association rule mining as a method for extracting actionable knowledge from large data sets. It outlines the importance of data mining in managing the challenges of massive databases and reviews existing literature in the field, highlighting significant research and algorithms developed over the years. Additionally, it identifies future work that could enhance system efficiency through improvements in the distributed setup and processing of large data inputs.























































































