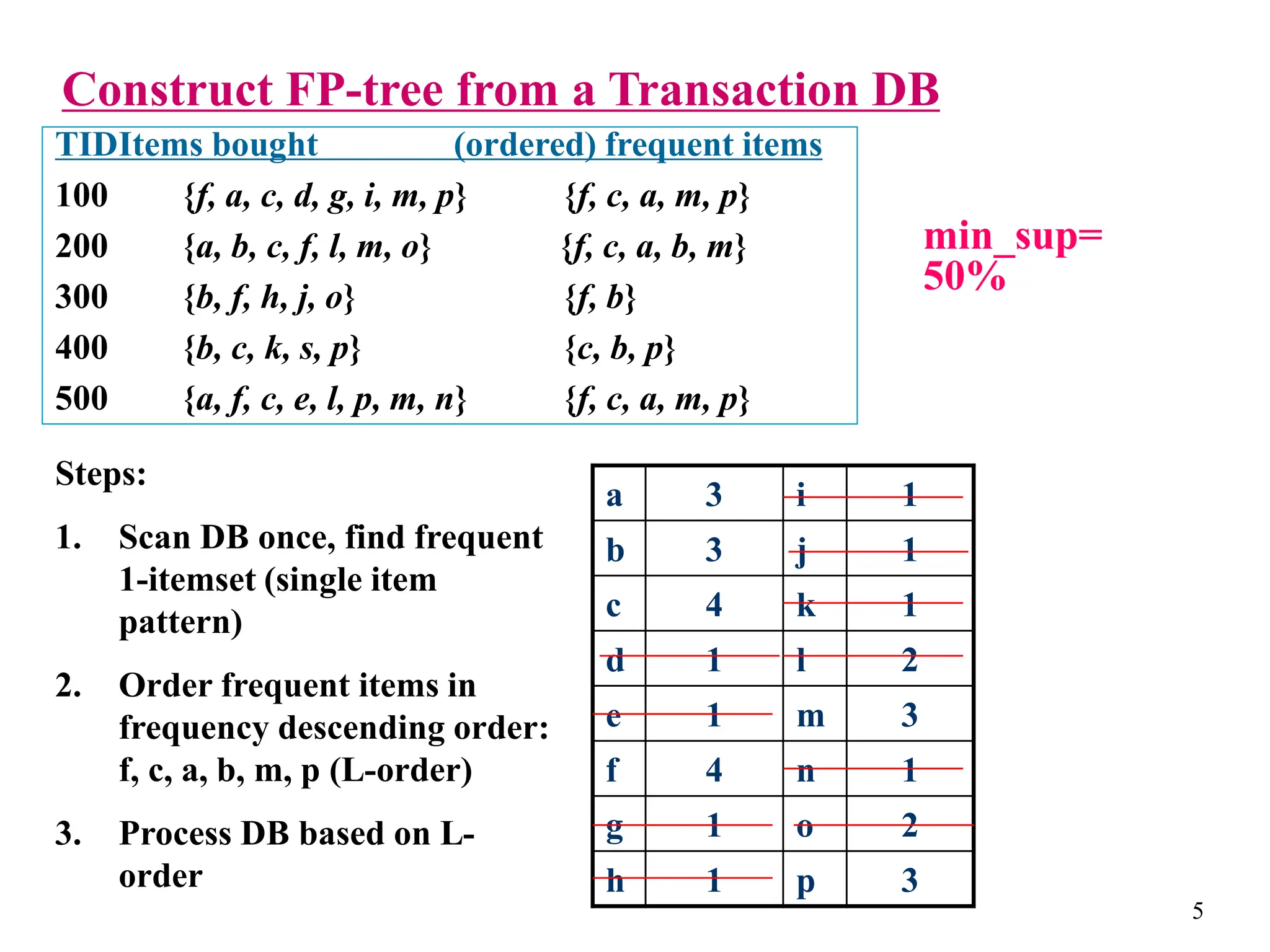
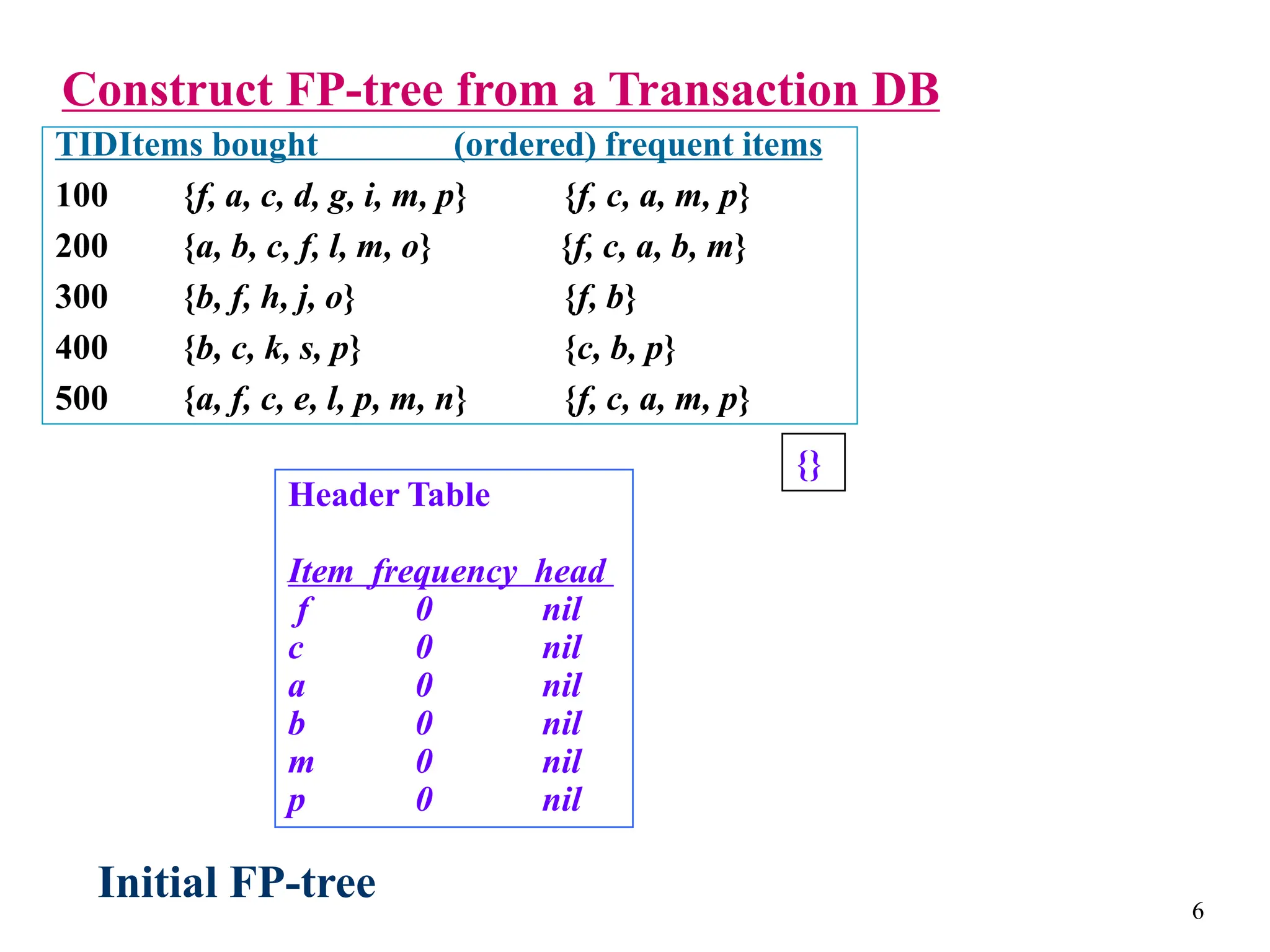
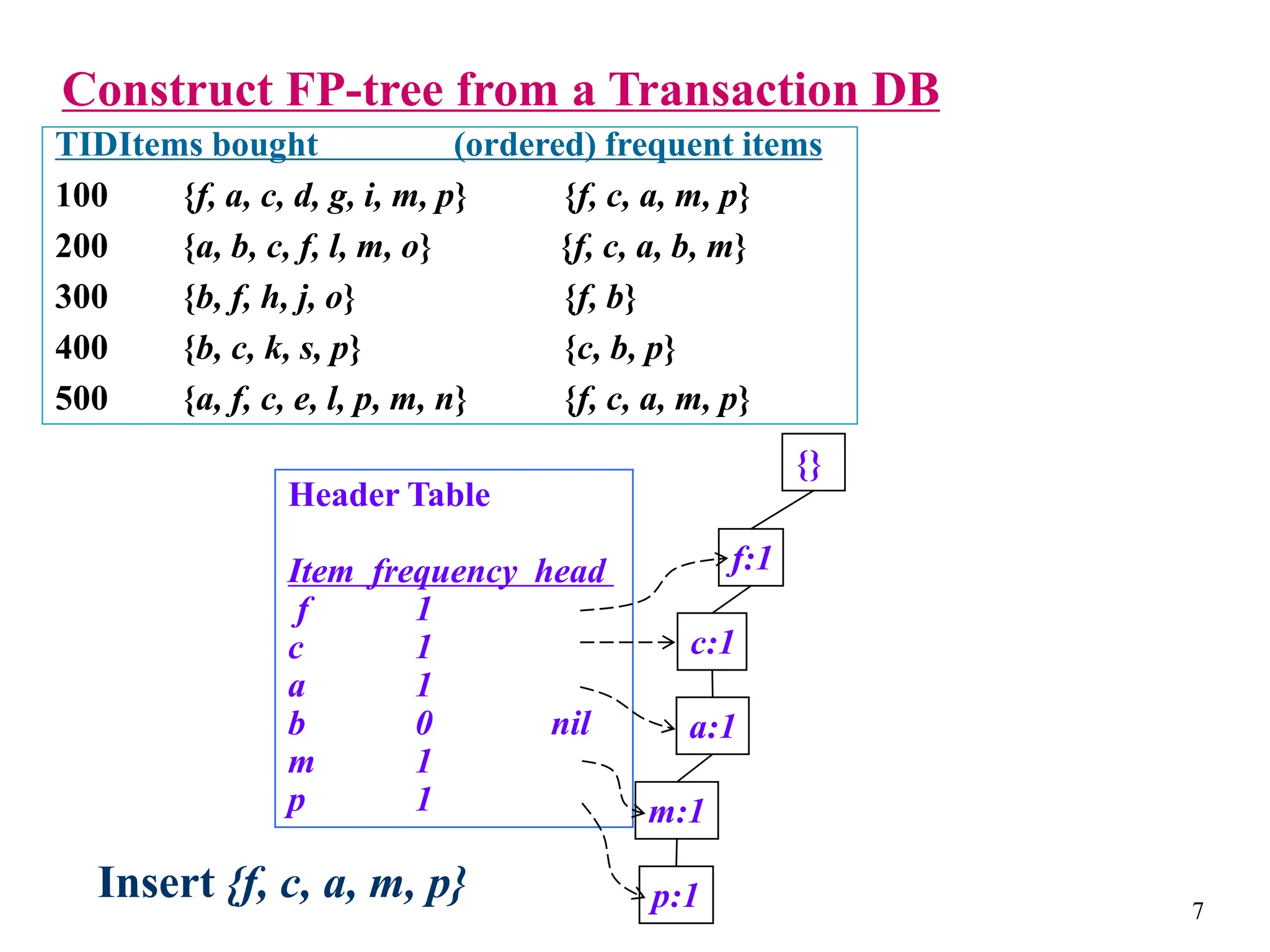
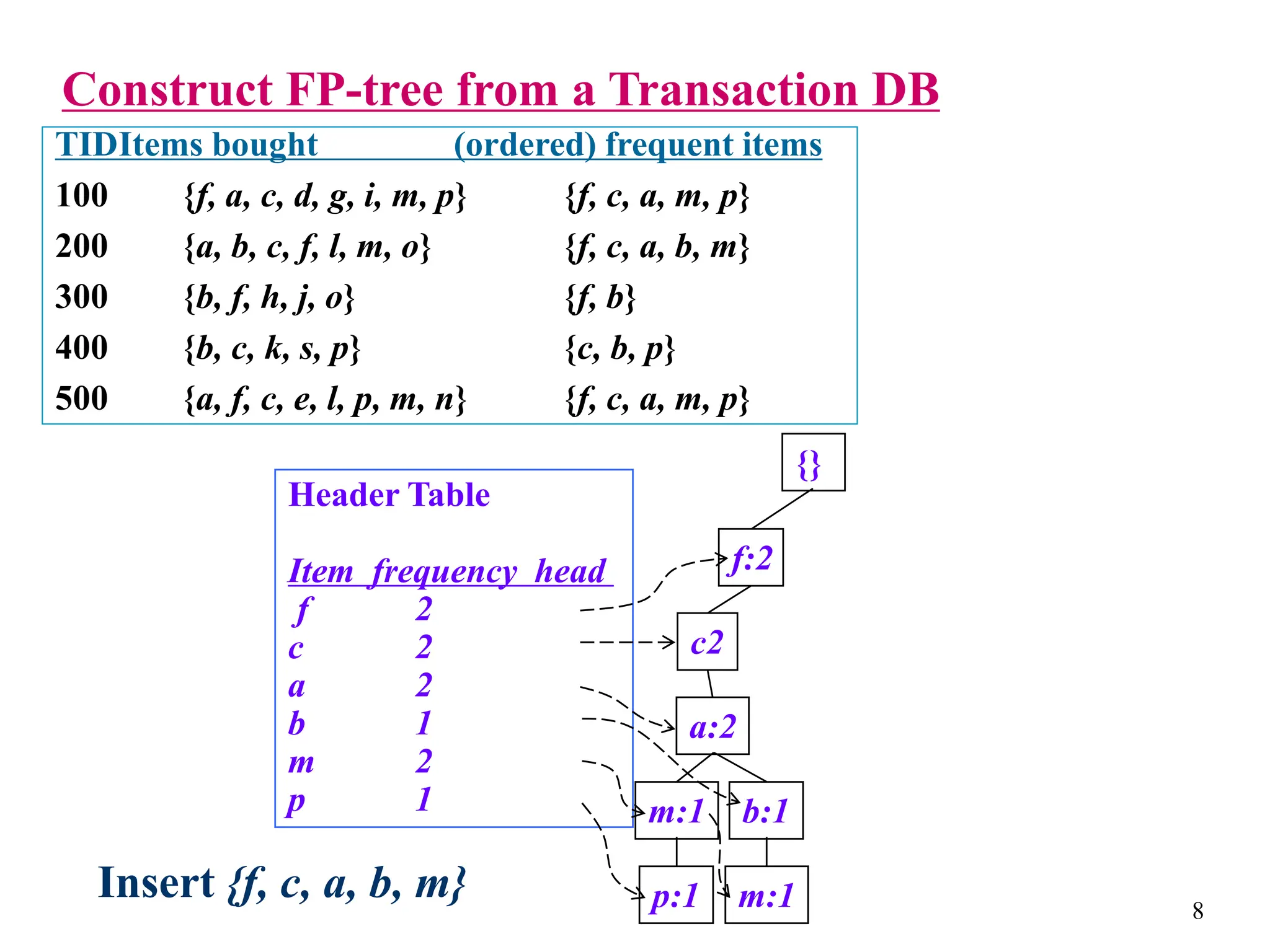
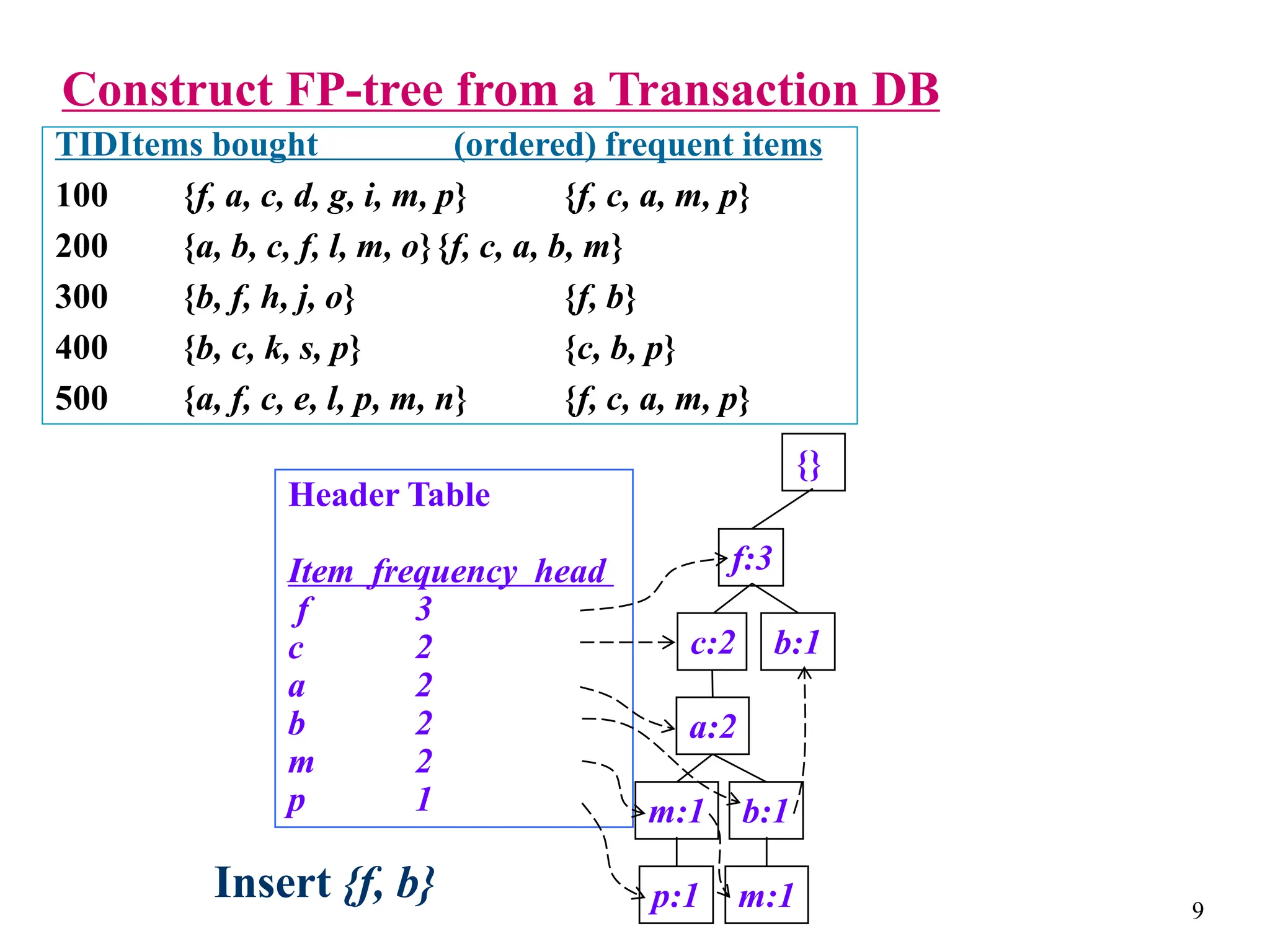
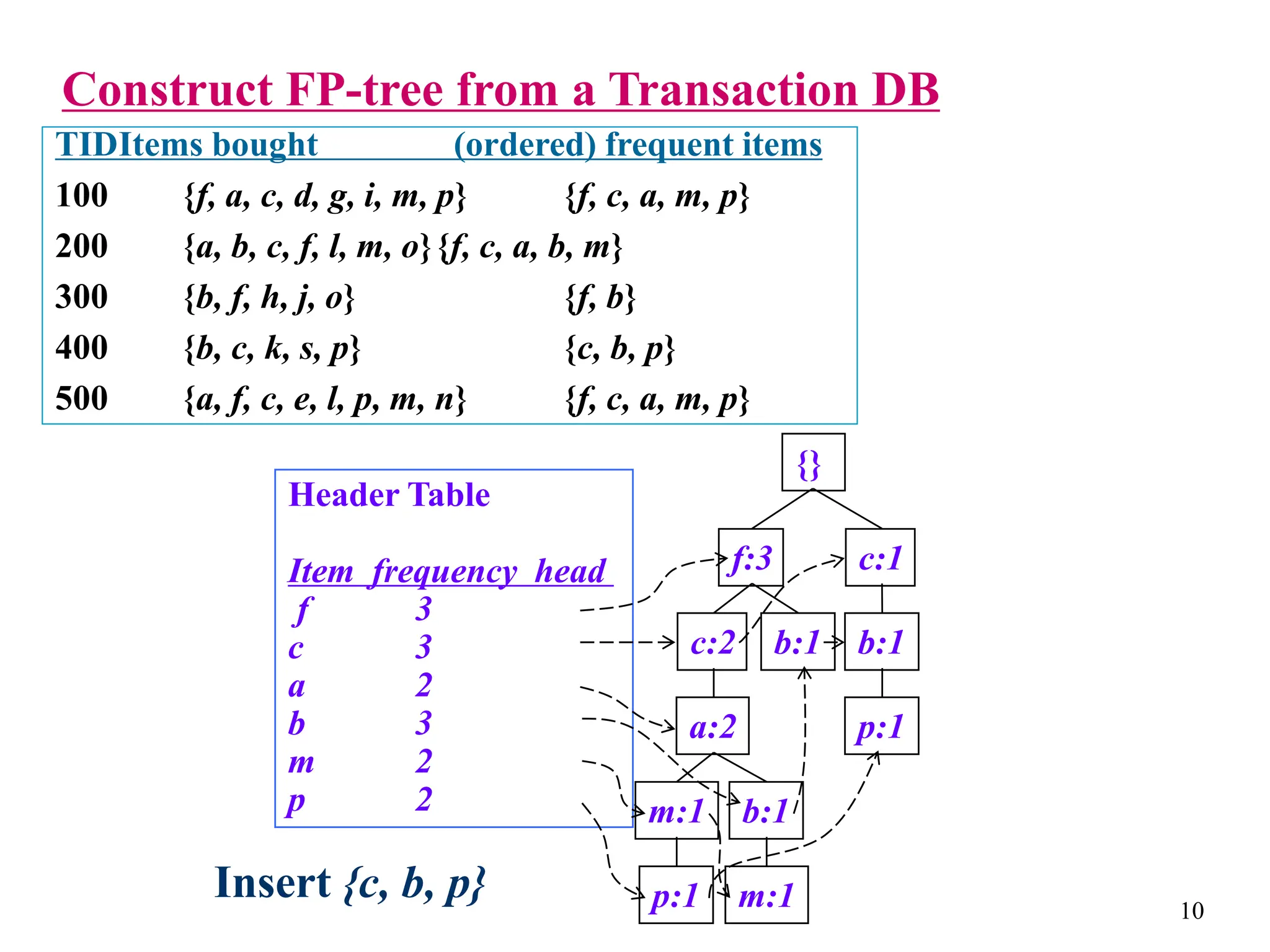
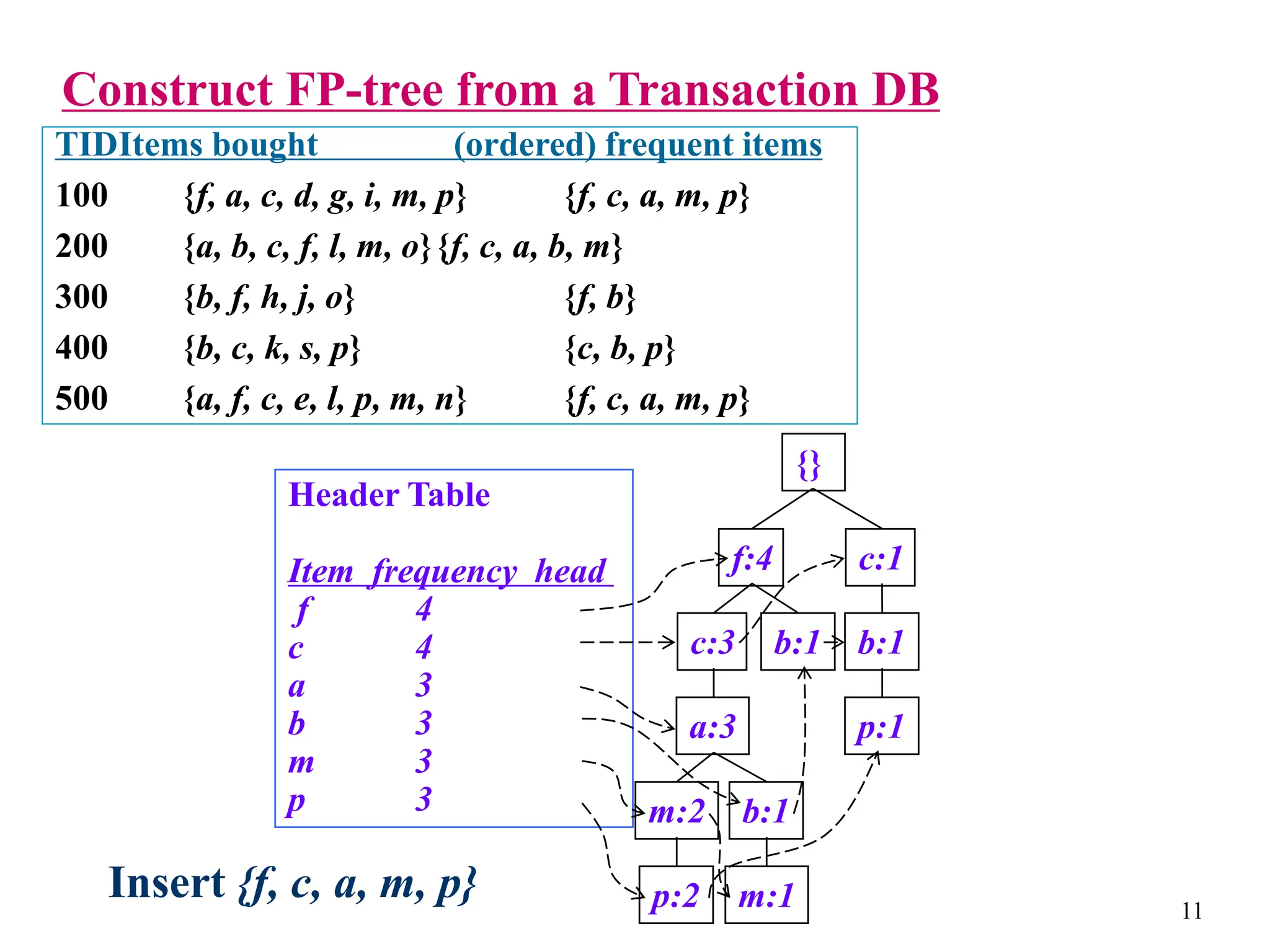
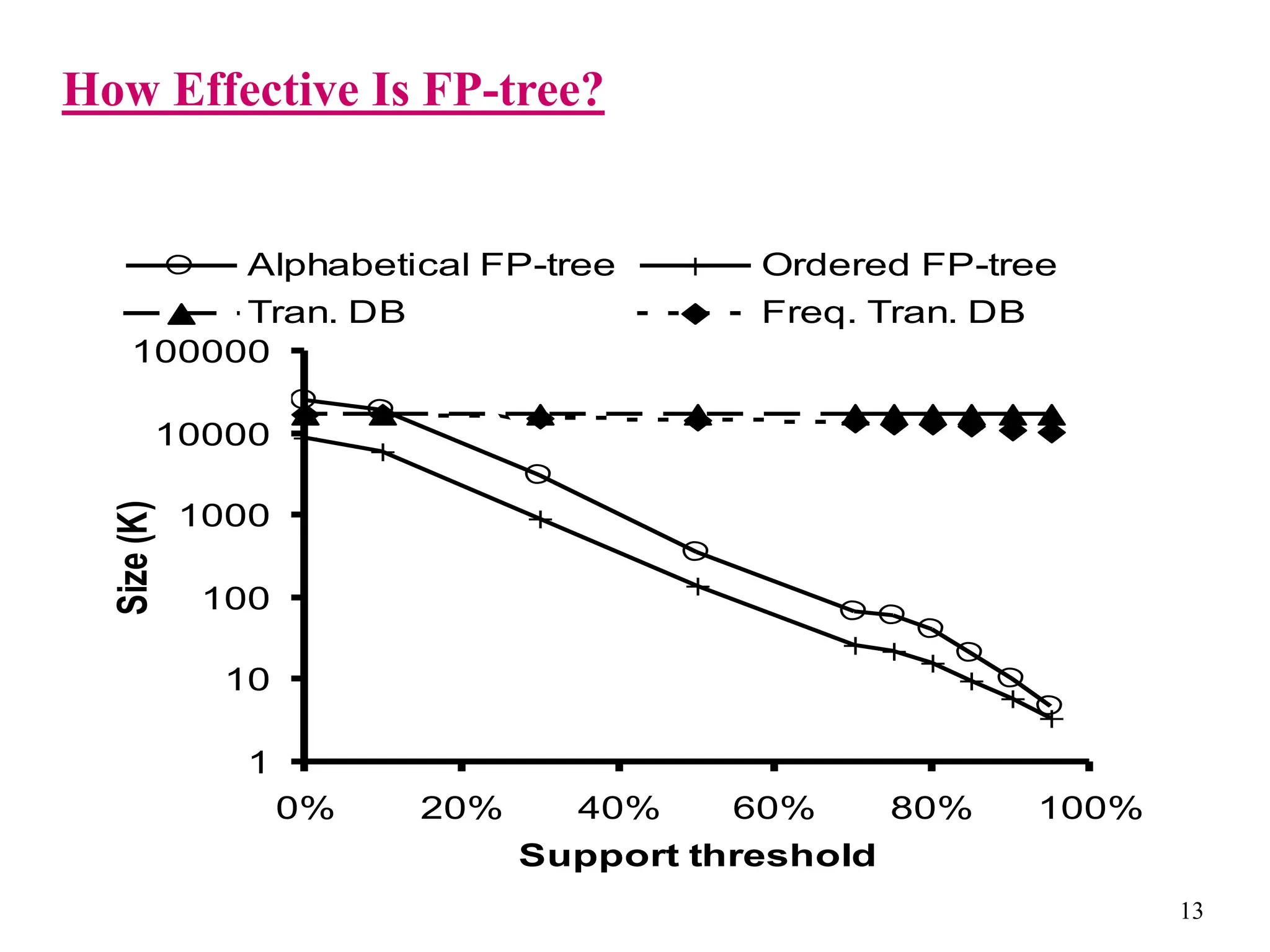
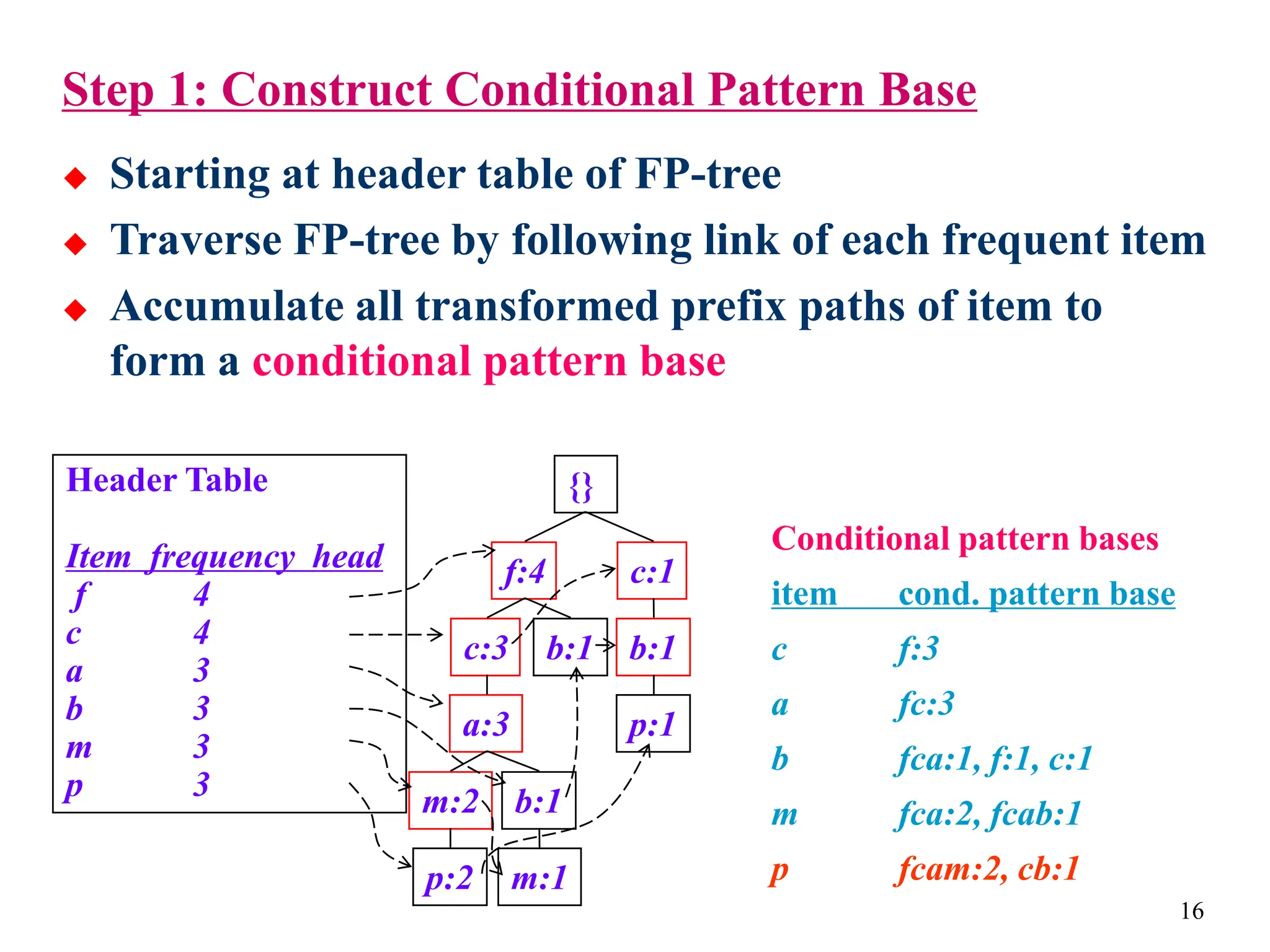
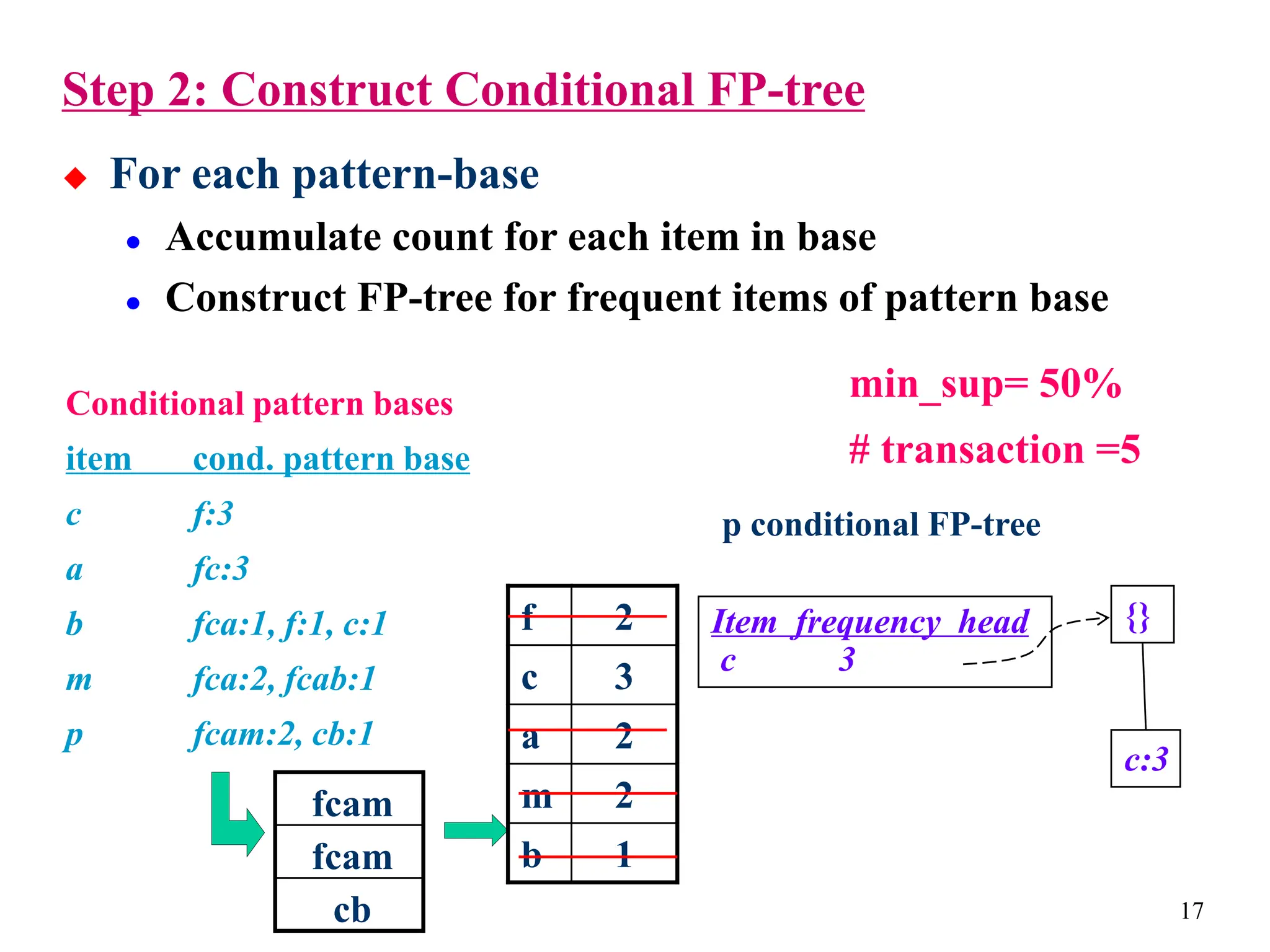
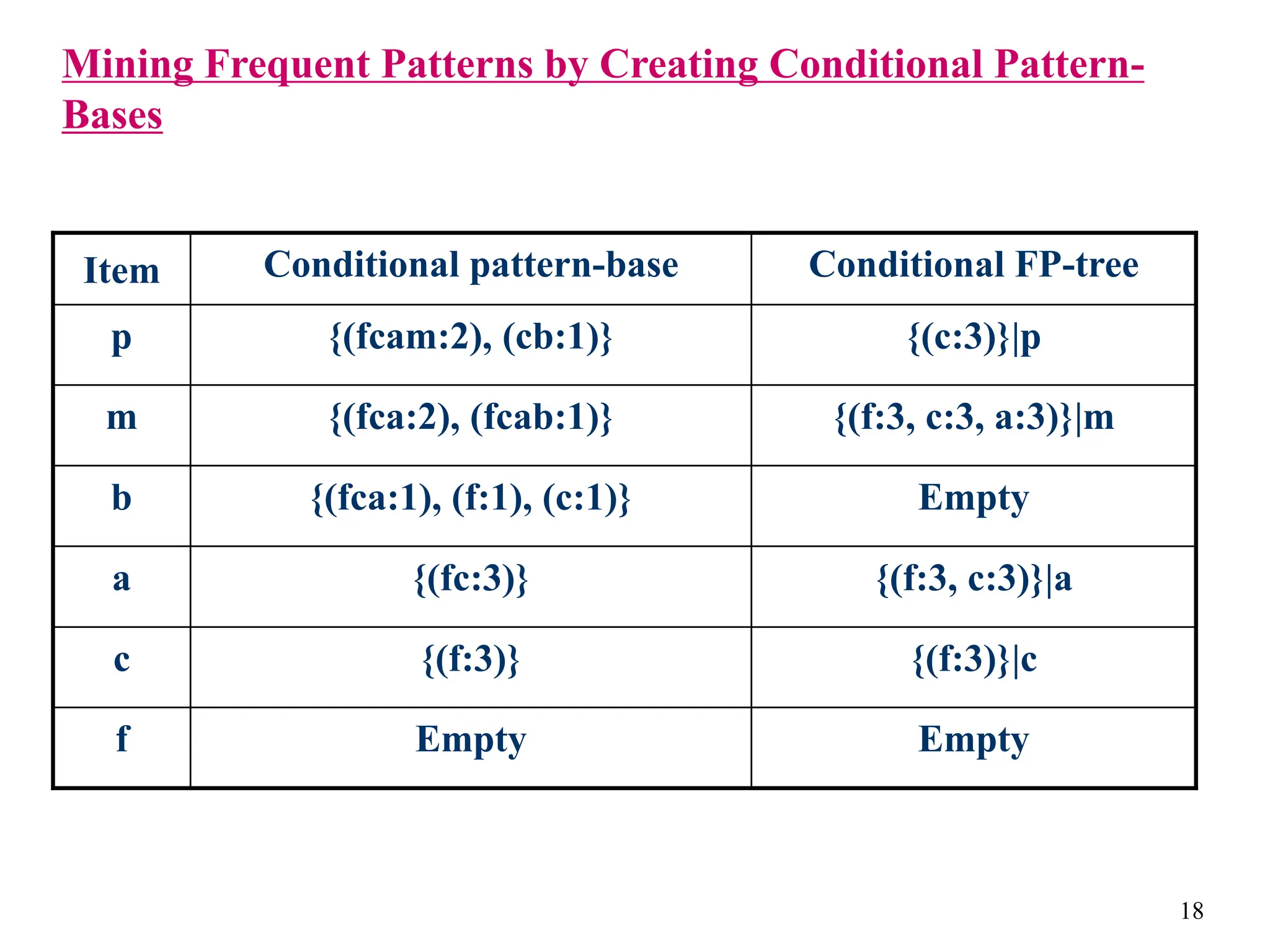
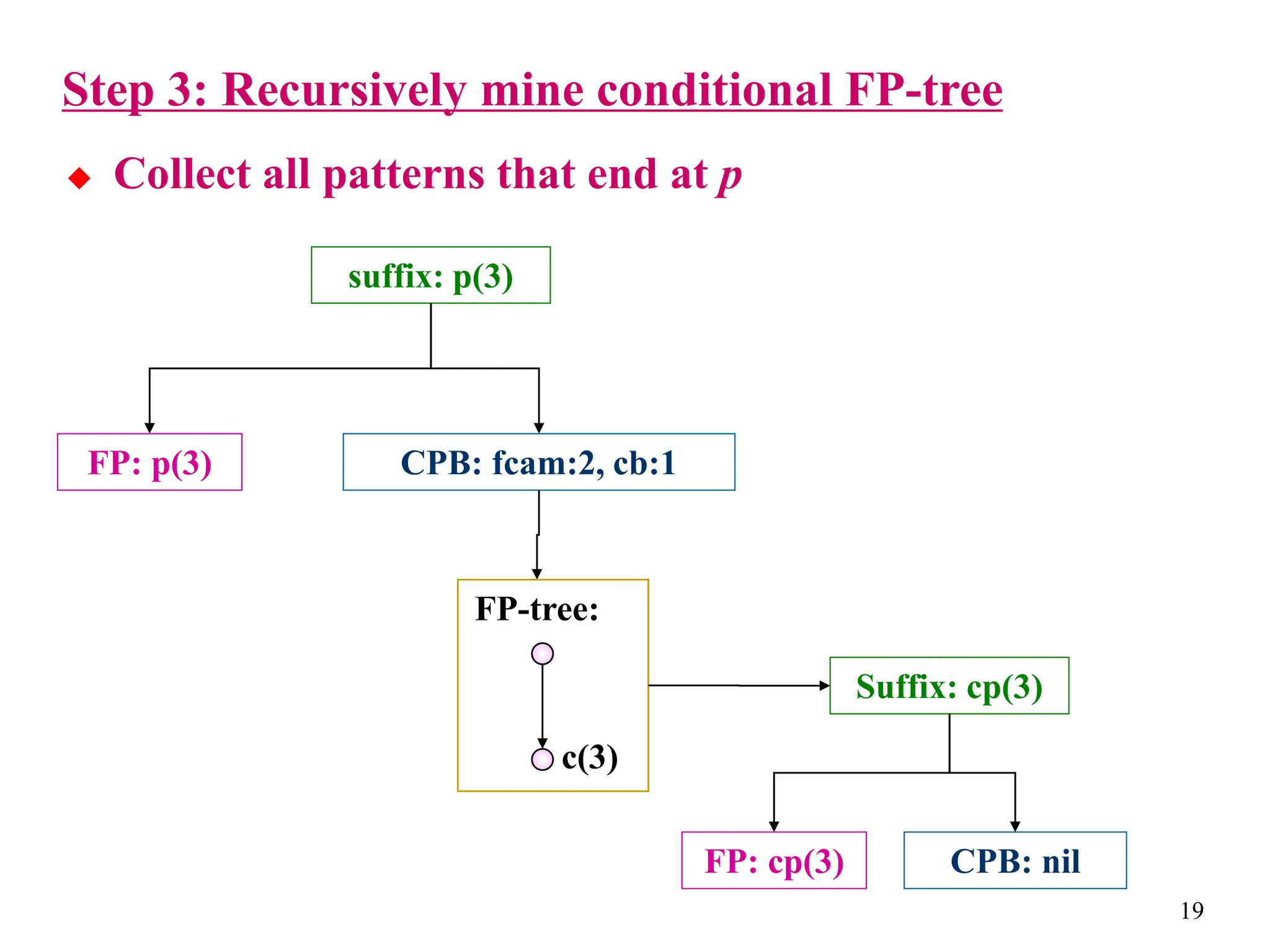
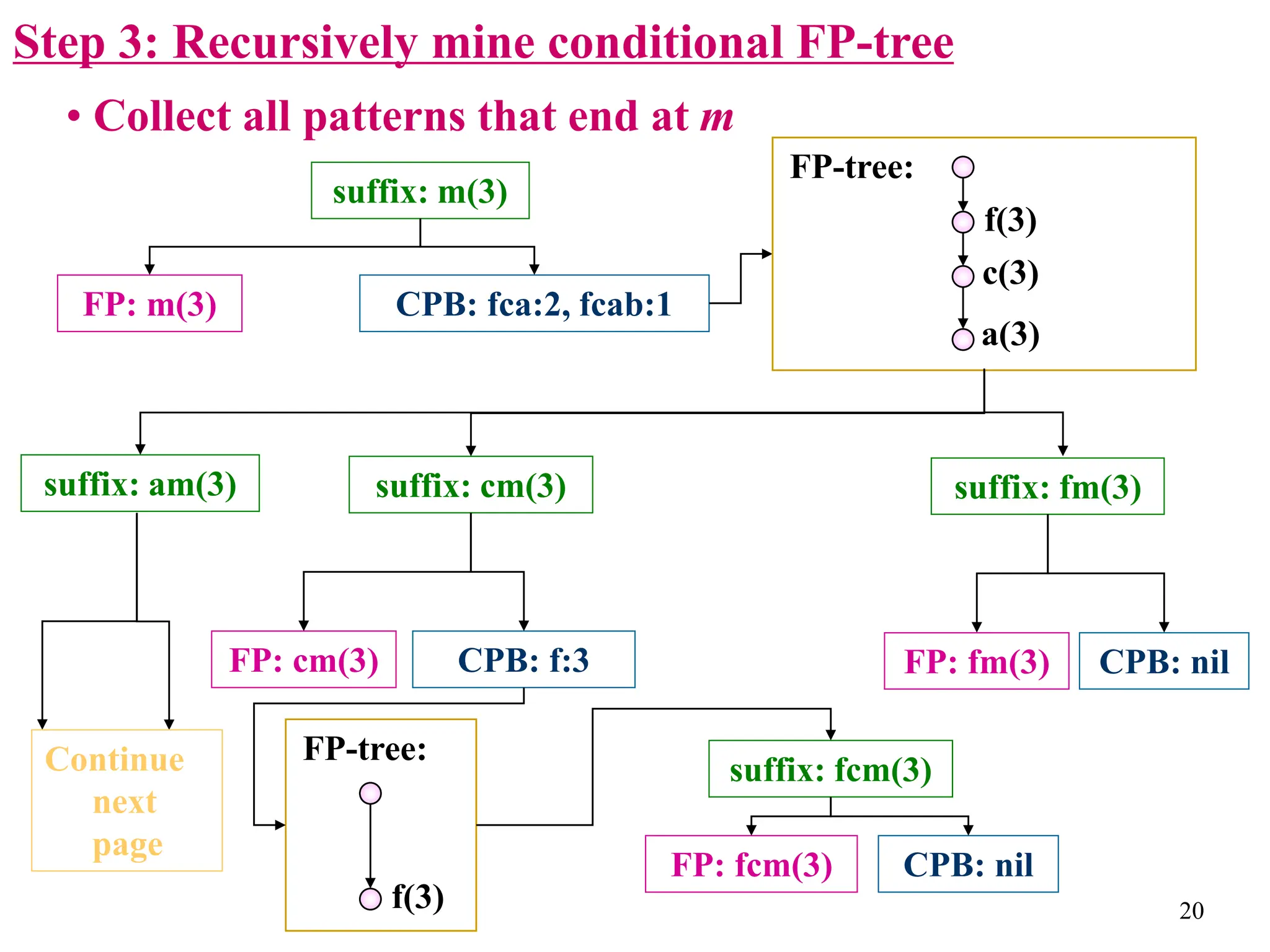
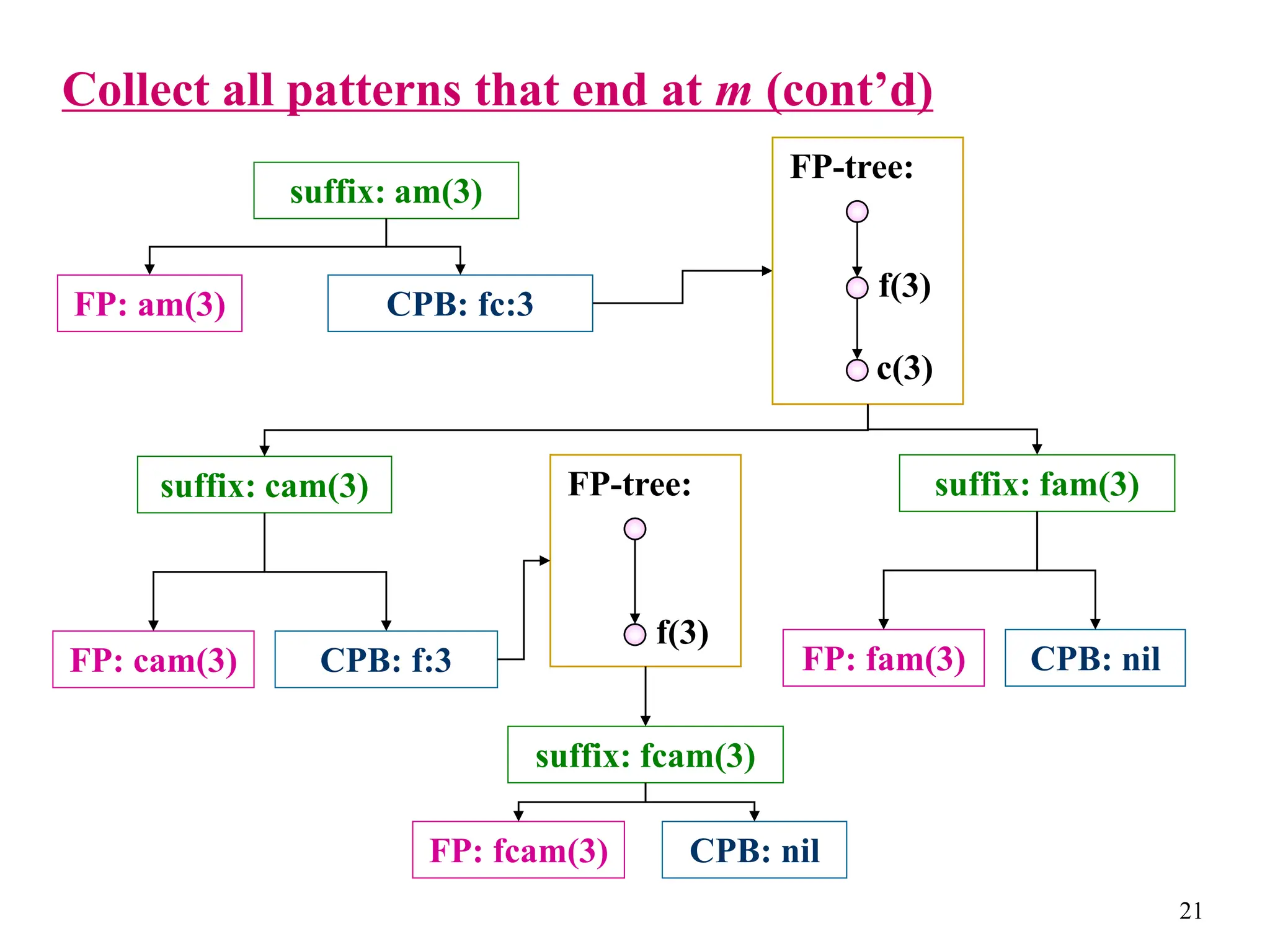
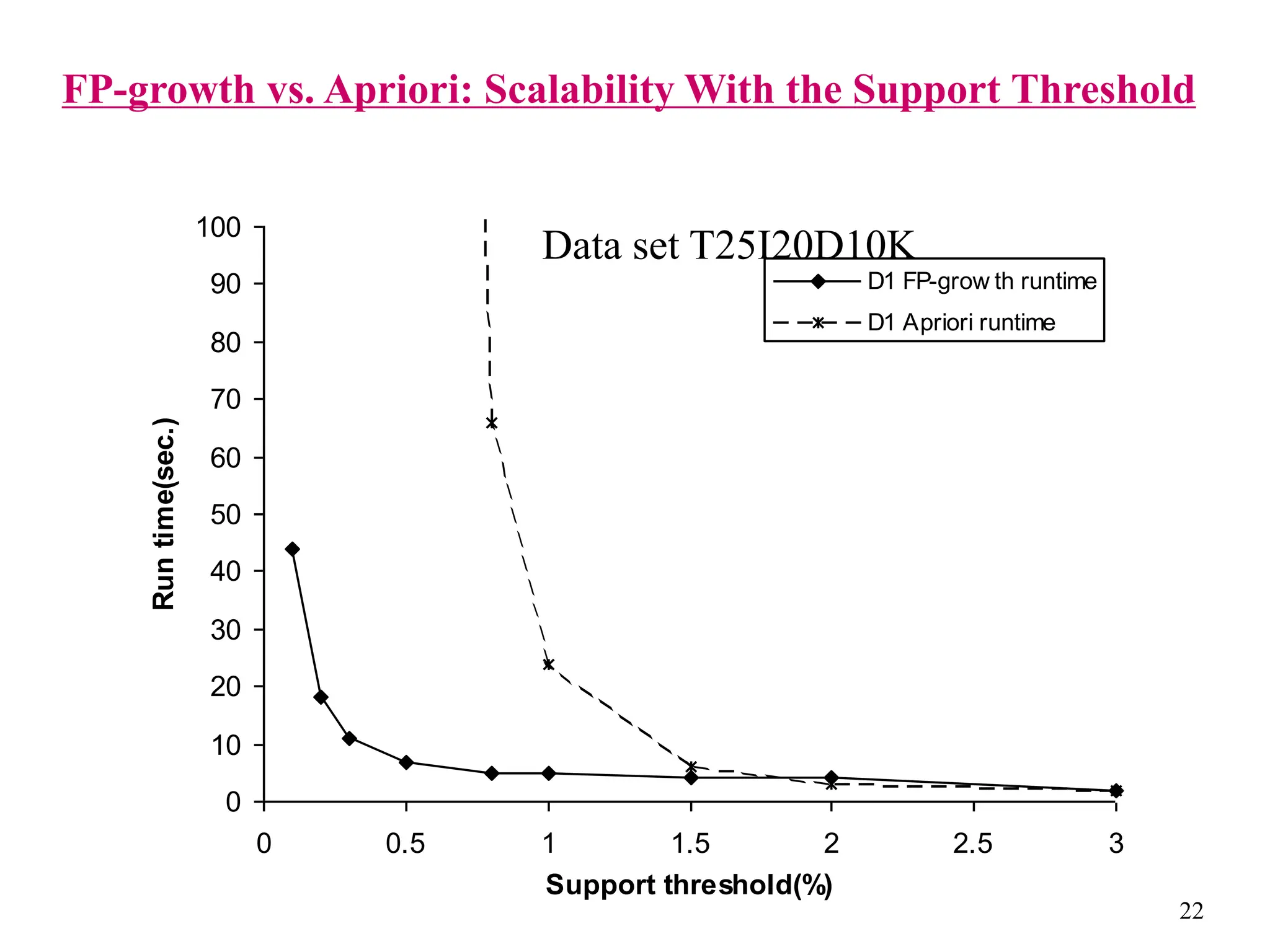
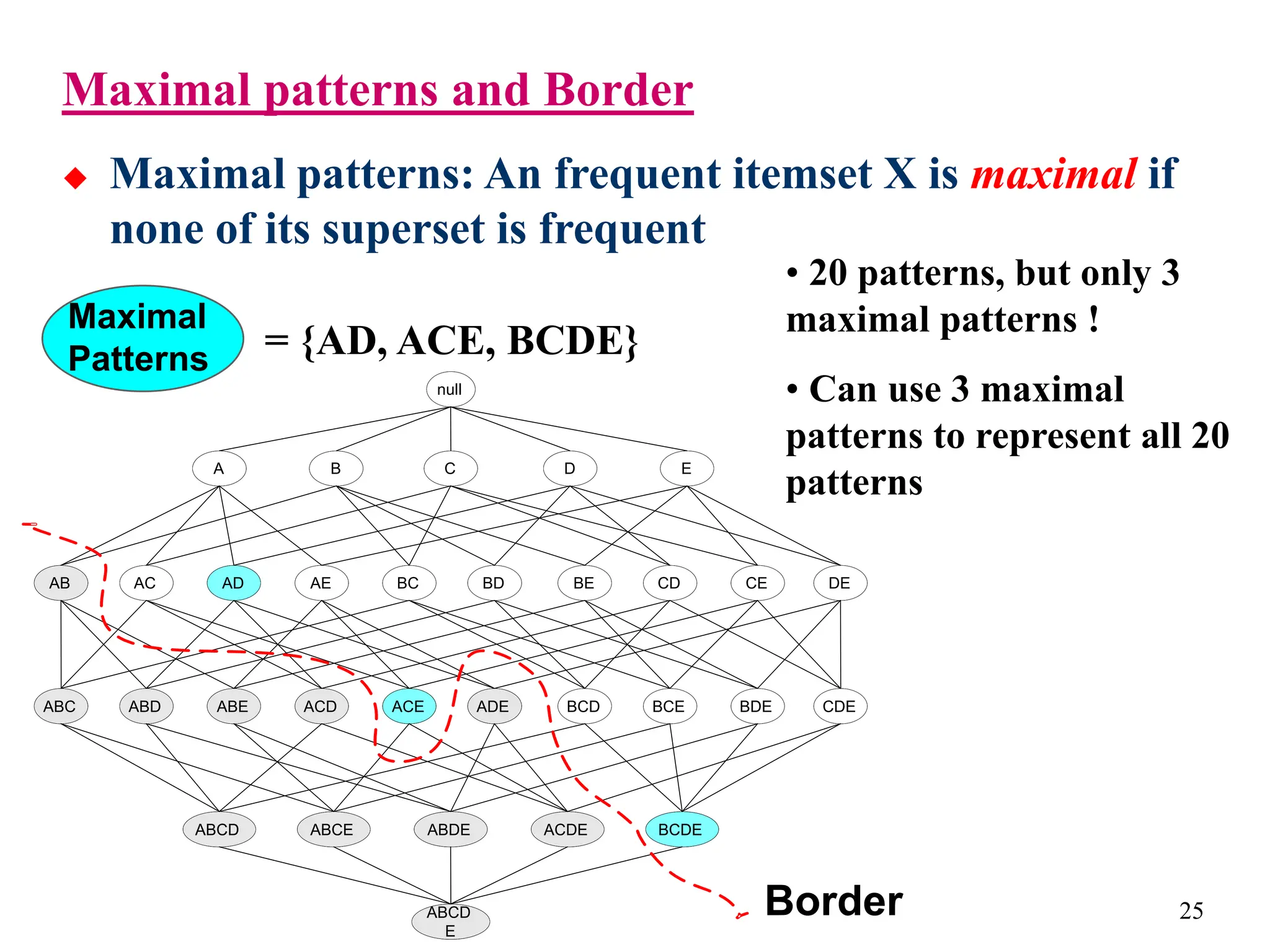
The document discusses the frequent pattern tree (FP-tree) structure for efficiently mining frequent patterns without candidate generation. It describes how an FP-tree compresses a transaction database into a tree structure that preserves all frequent itemsets. The FP-growth algorithm recursively mines the FP-tree to discover all frequent patterns by creating conditional pattern bases and conditional FP-trees. FP-growth avoids multiple database scans and candidate generation, making it faster than the Apriori algorithm. However, it is dependent on support threshold and cannot handle incremental updates.