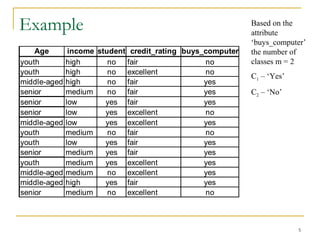
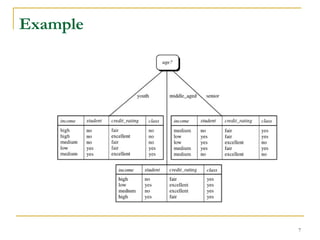
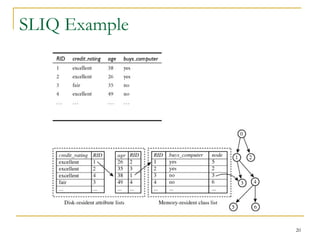
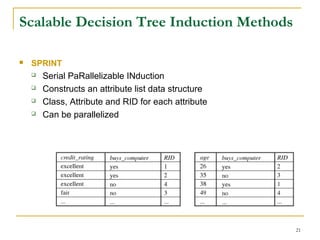
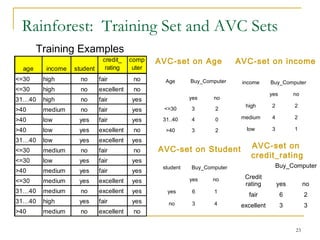
This document discusses decision tree induction and attribute selection measures. It describes common measures like information gain, gain ratio, and Gini index that are used to select the best splitting attribute at each node in decision tree construction. It provides examples to illustrate information gain calculation for both discrete and continuous attributes. The document also discusses techniques for handling large datasets like SLIQ and SPRINT that build decision trees in a scalable manner by maintaining attribute value lists.