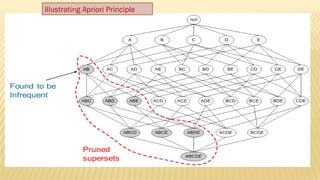
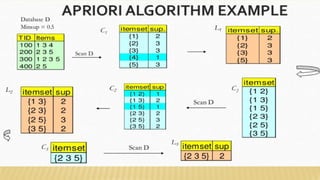
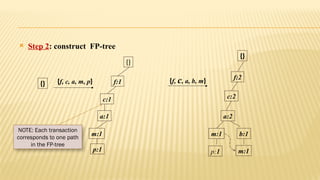
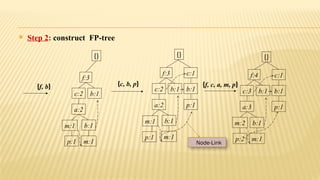
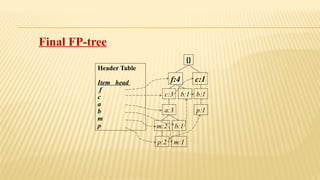
The document presents an improvised apriori algorithm utilizing a frequent pattern tree for association rule mining, focusing on identifying rules that can predict item occurrences within market-basket transactions. It explains key concepts such as itemsets, support count, and the apriori principle, detailing how the algorithm minimizes candidate itemsets through pruning. Additionally, it describes the FP-growth method for efficiently mining frequent patterns from a database, highlighting its two-scan process to build a compact FP-tree structure.


















































![7.__Developing_a_Research_Proposal[1].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/7-260131073037-df92dd7d-thumbnail.jpg?width=640&height=640&fit=bounds)





![Hacking-Uncovered-How-People-Get-Hacked-and-How-to-Stay-Safe[1].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/hacking-uncovered-how-people-get-hacked-and-how-to-stay-safe1-260130170011-4883a9c7-thumbnail.jpg?width=640&height=640&fit=bounds)










