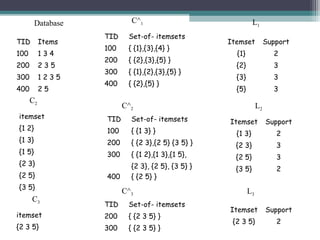
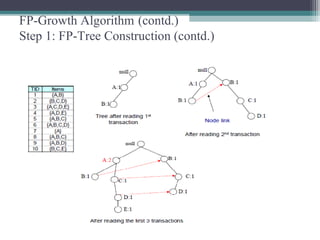
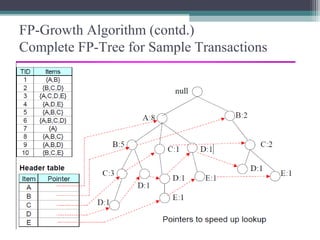
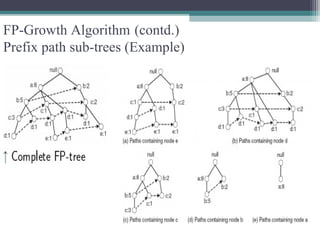
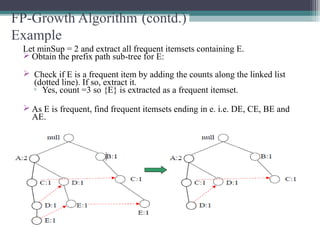
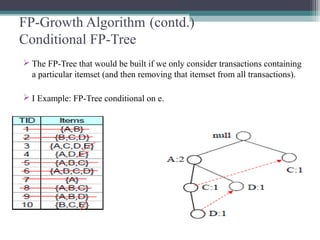
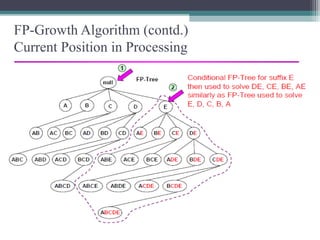
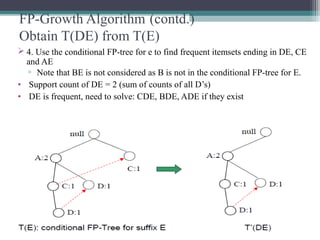
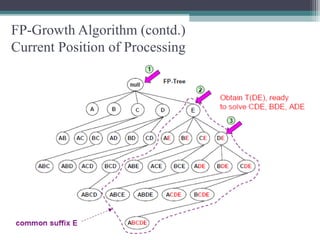
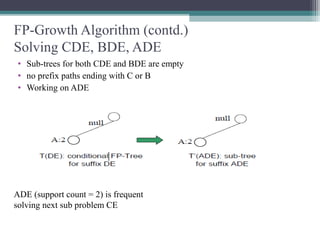
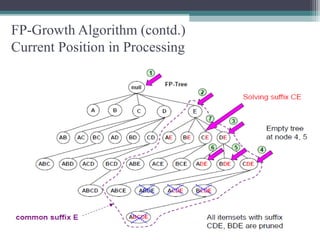
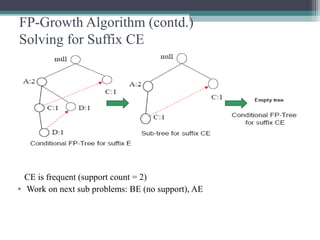
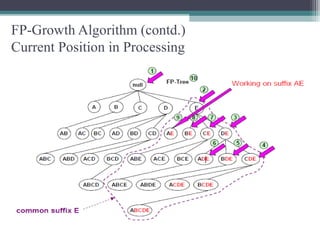
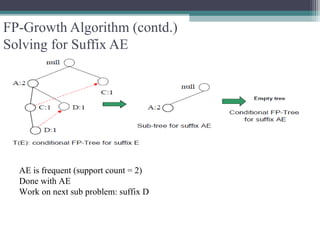
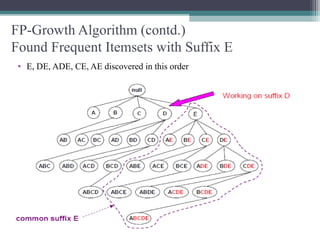
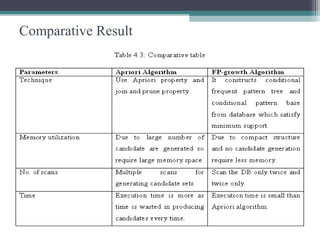
This document summarizes a seminar presentation comparing the Apriori and FP-Growth algorithms for association rule mining. The document introduces association rule mining and frequent itemset mining. It then describes the Apriori algorithm, including its generate-and-test approach and bottlenecks. Next, it explains the FP-Growth algorithm, including how it builds an FP-tree to efficiently extract frequent itemsets without candidate generation. Finally, it provides results comparing the performance of the two algorithms and concludes that FP-Growth is more efficient for mining long patterns.