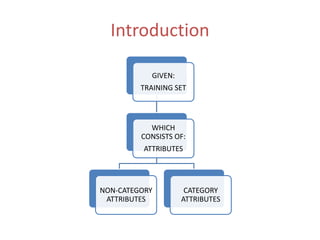
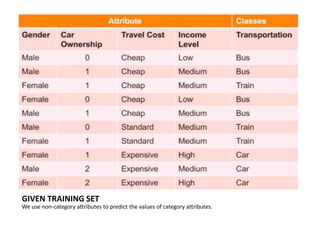
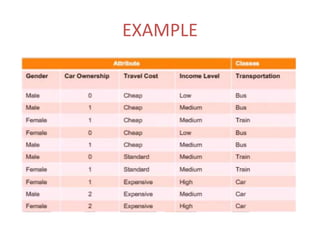
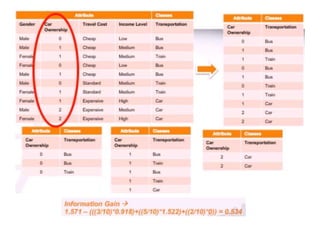
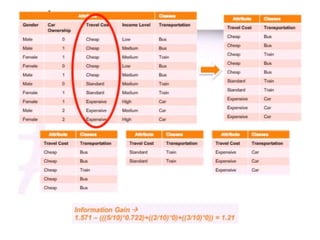
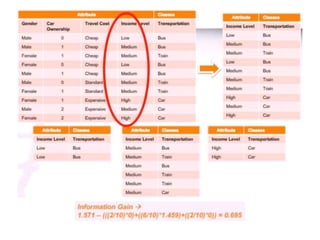
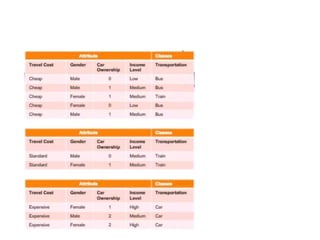
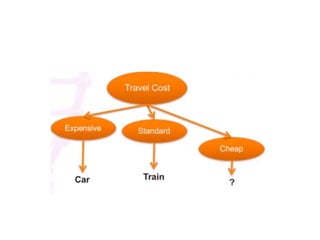
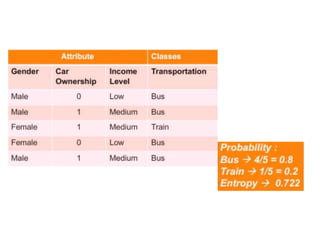
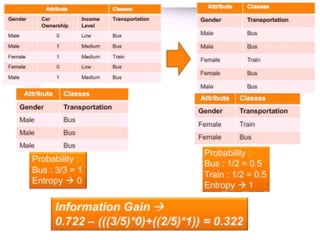
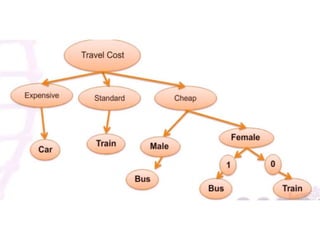
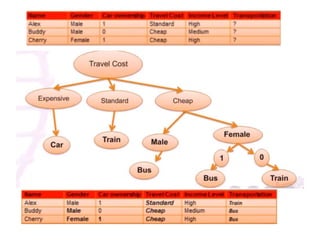
The ID3 algorithm generates a decision tree from training data using a top-down, greedy search. It calculates the entropy of attributes in the training data to determine which attribute best splits the data into pure subsets with maximum information gain. It then recursively builds the decision tree, using the selected attributes to split the data at each node until reaching leaf nodes containing only one class. The resulting decision tree can then classify new samples not in the training data.