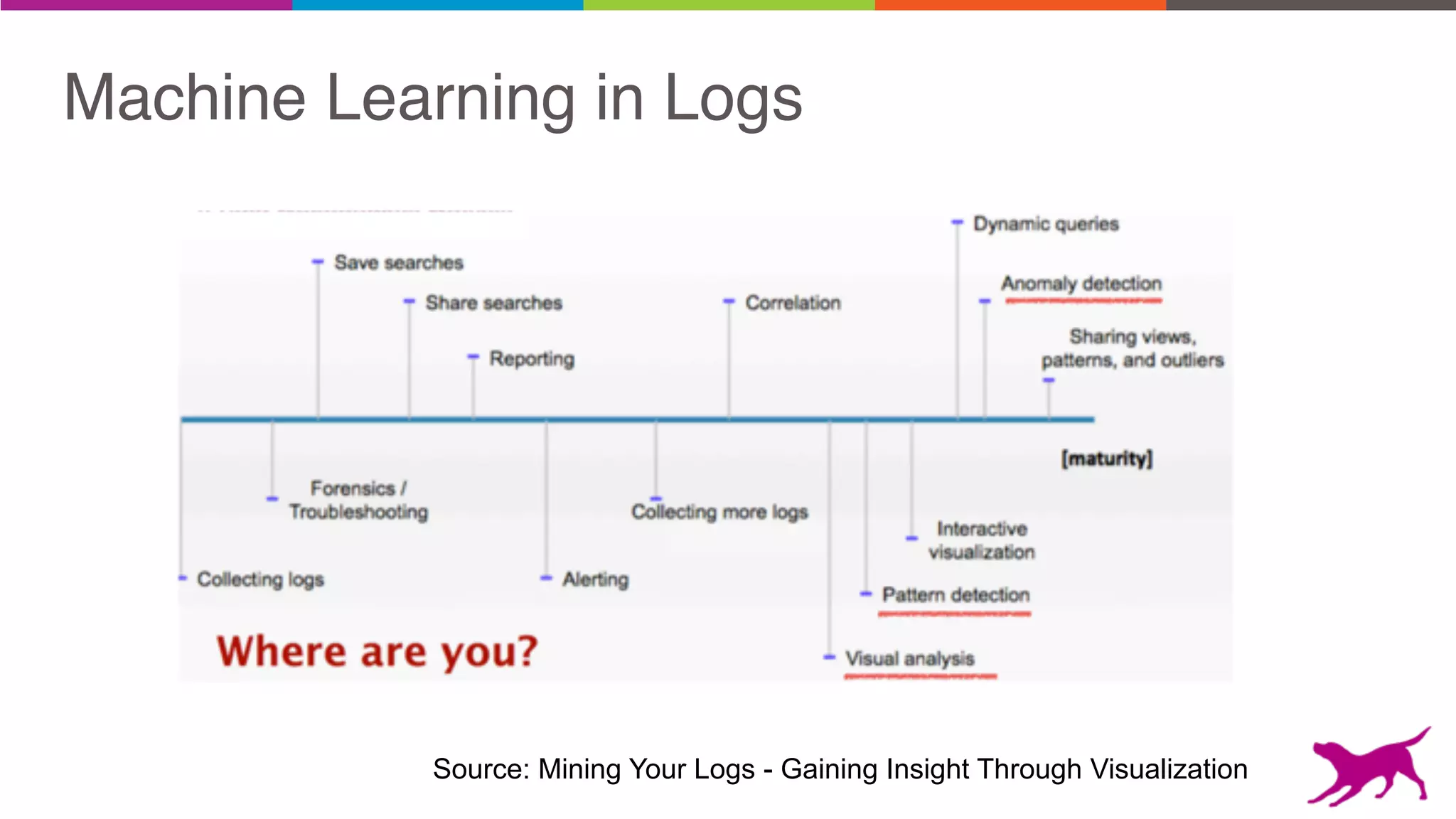
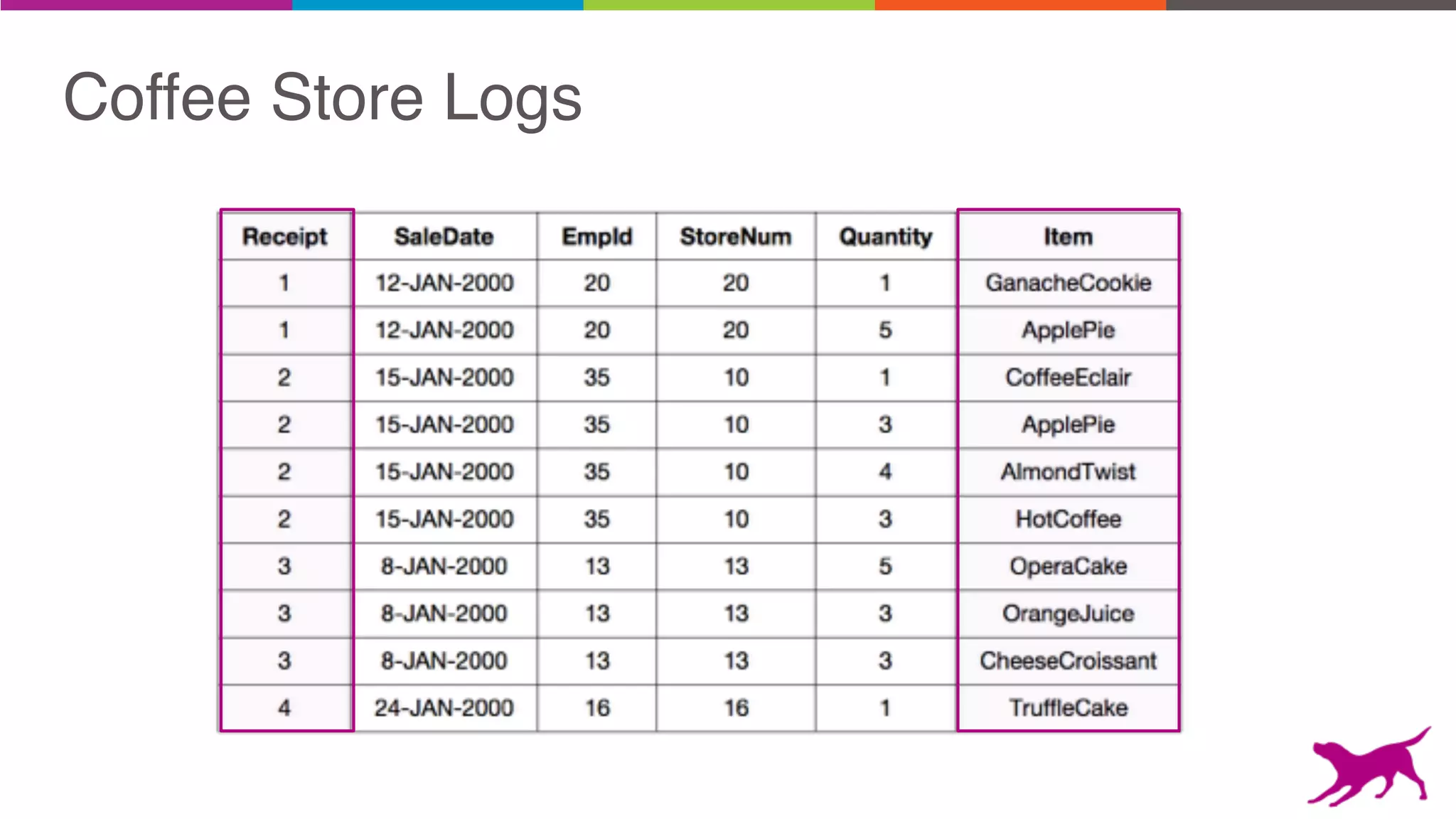
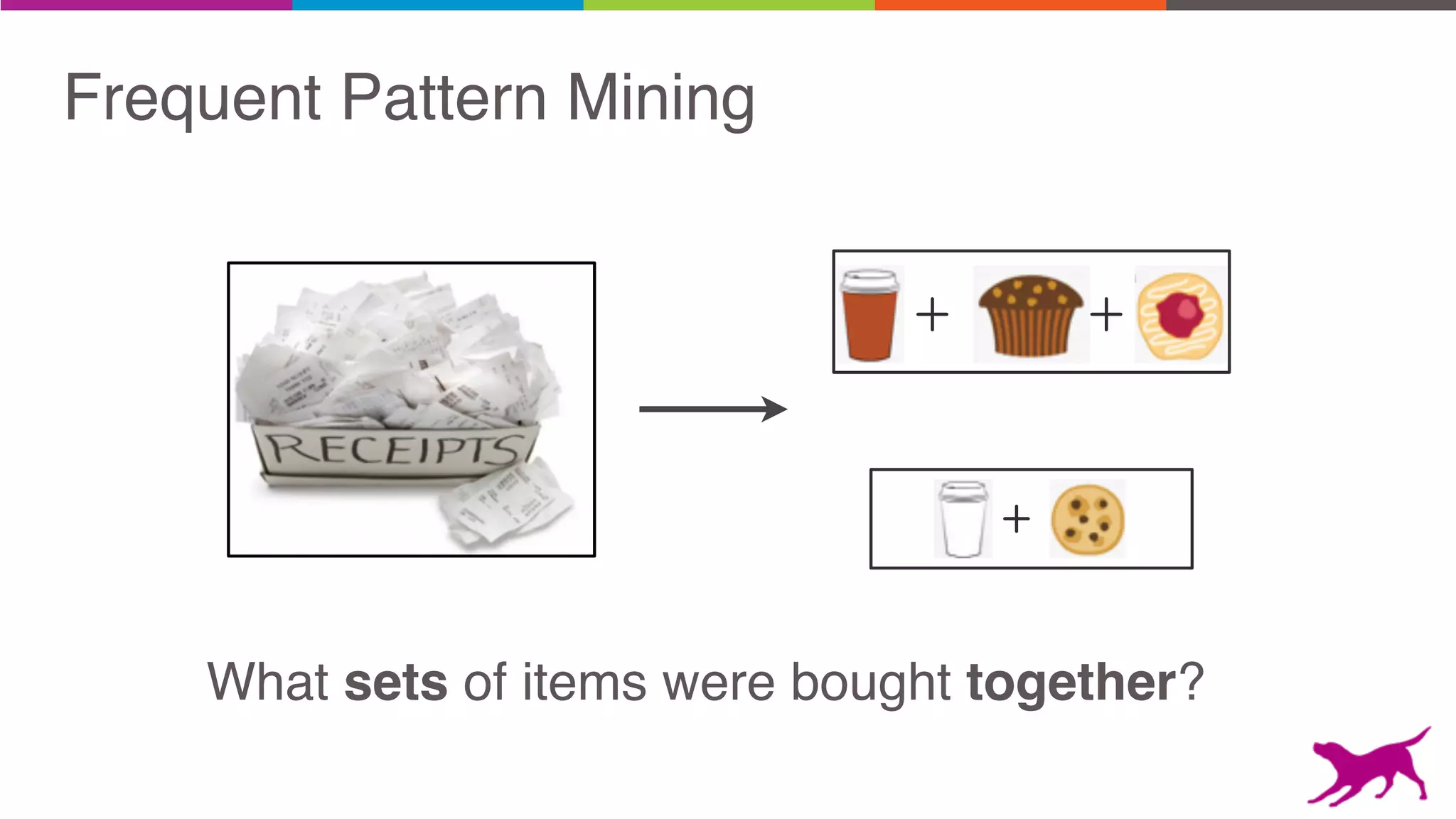
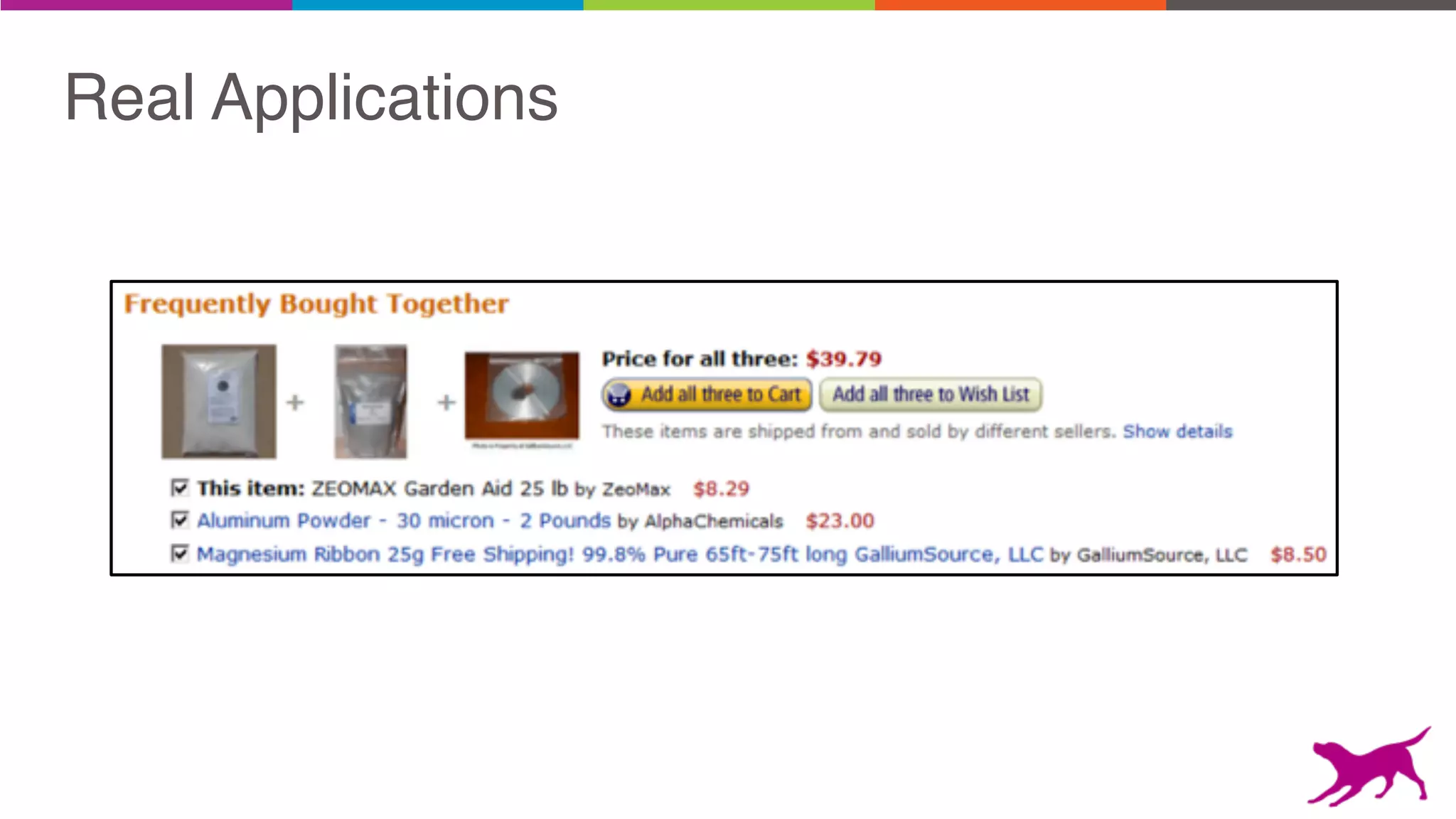
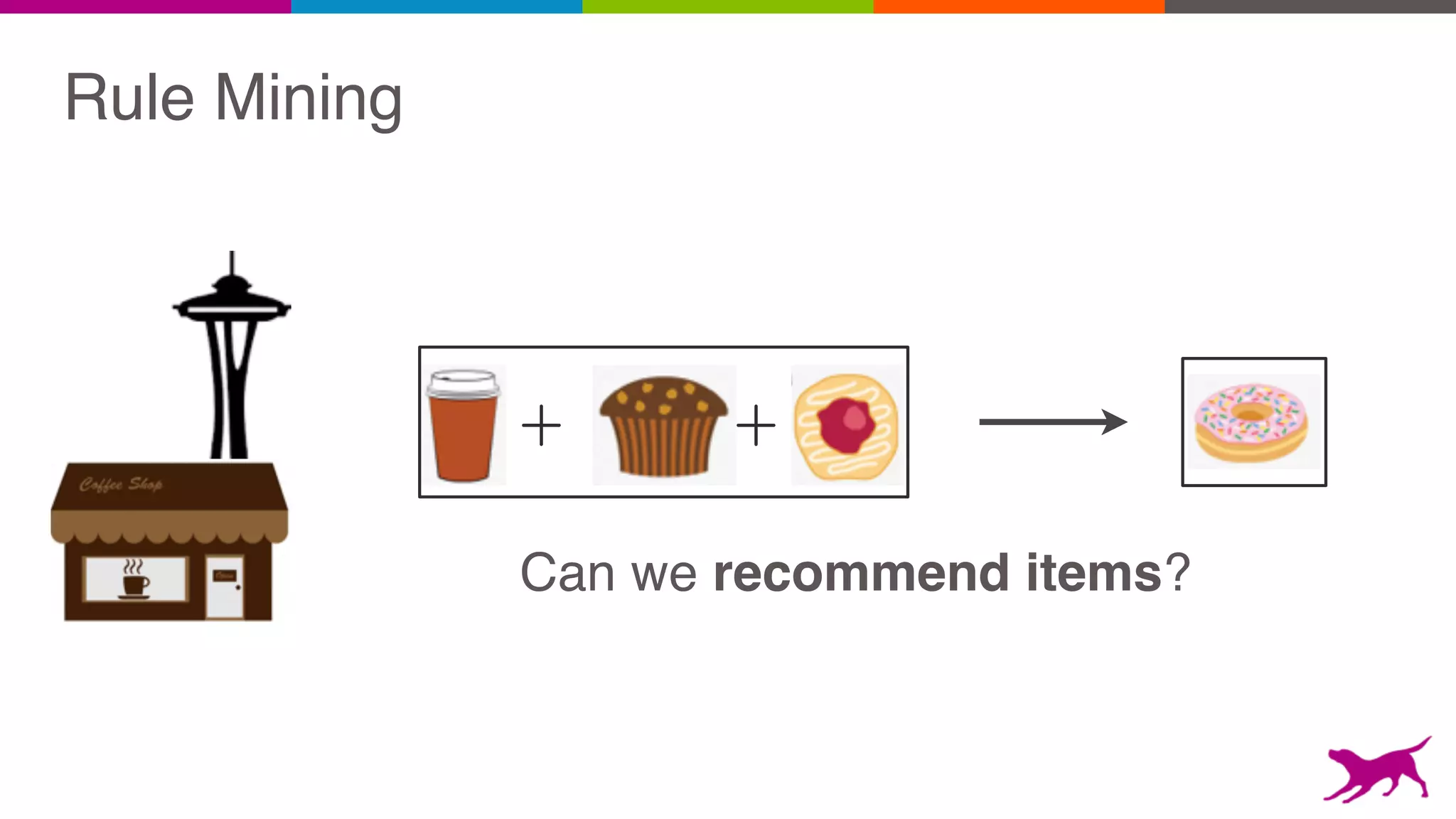
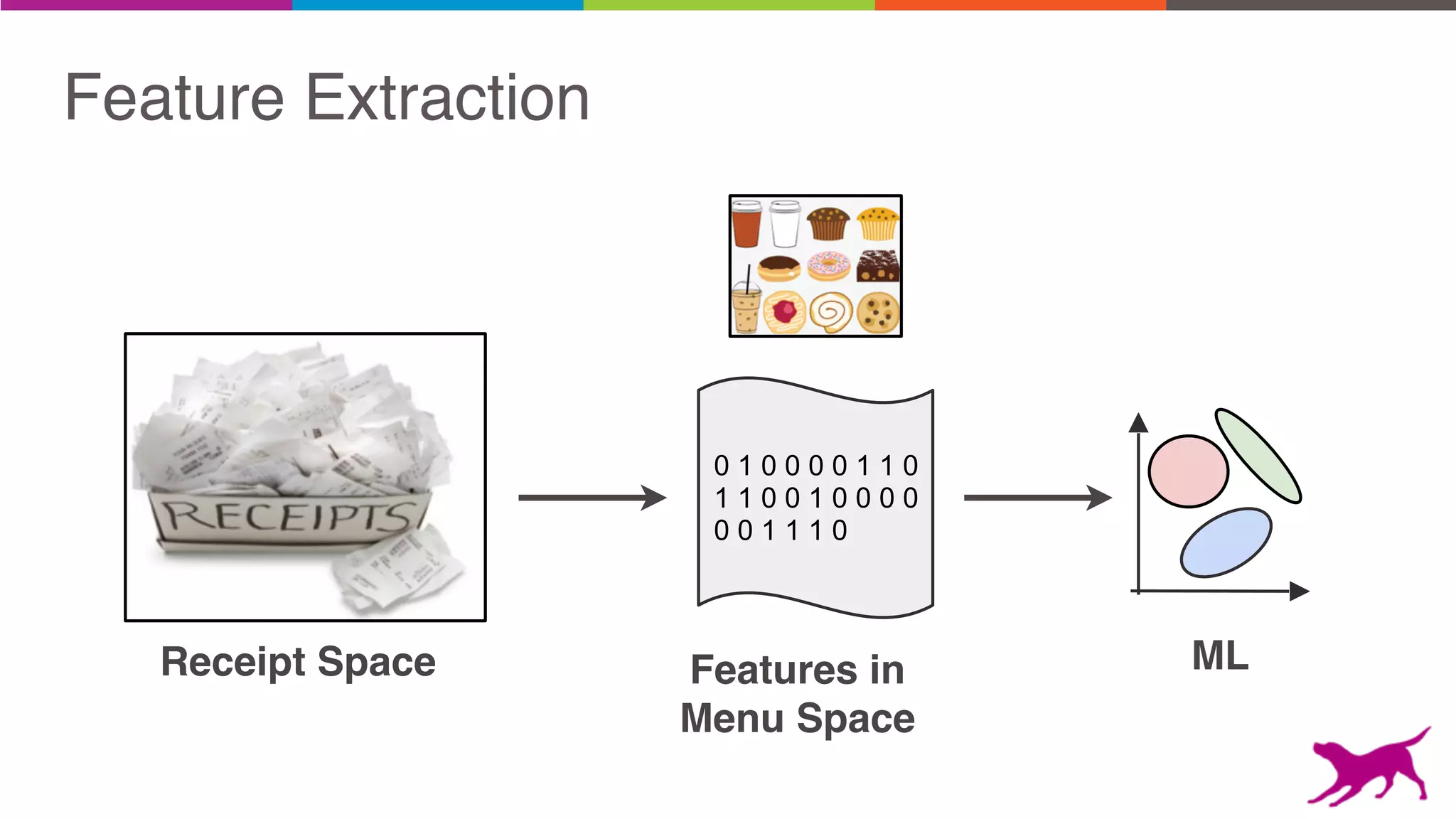
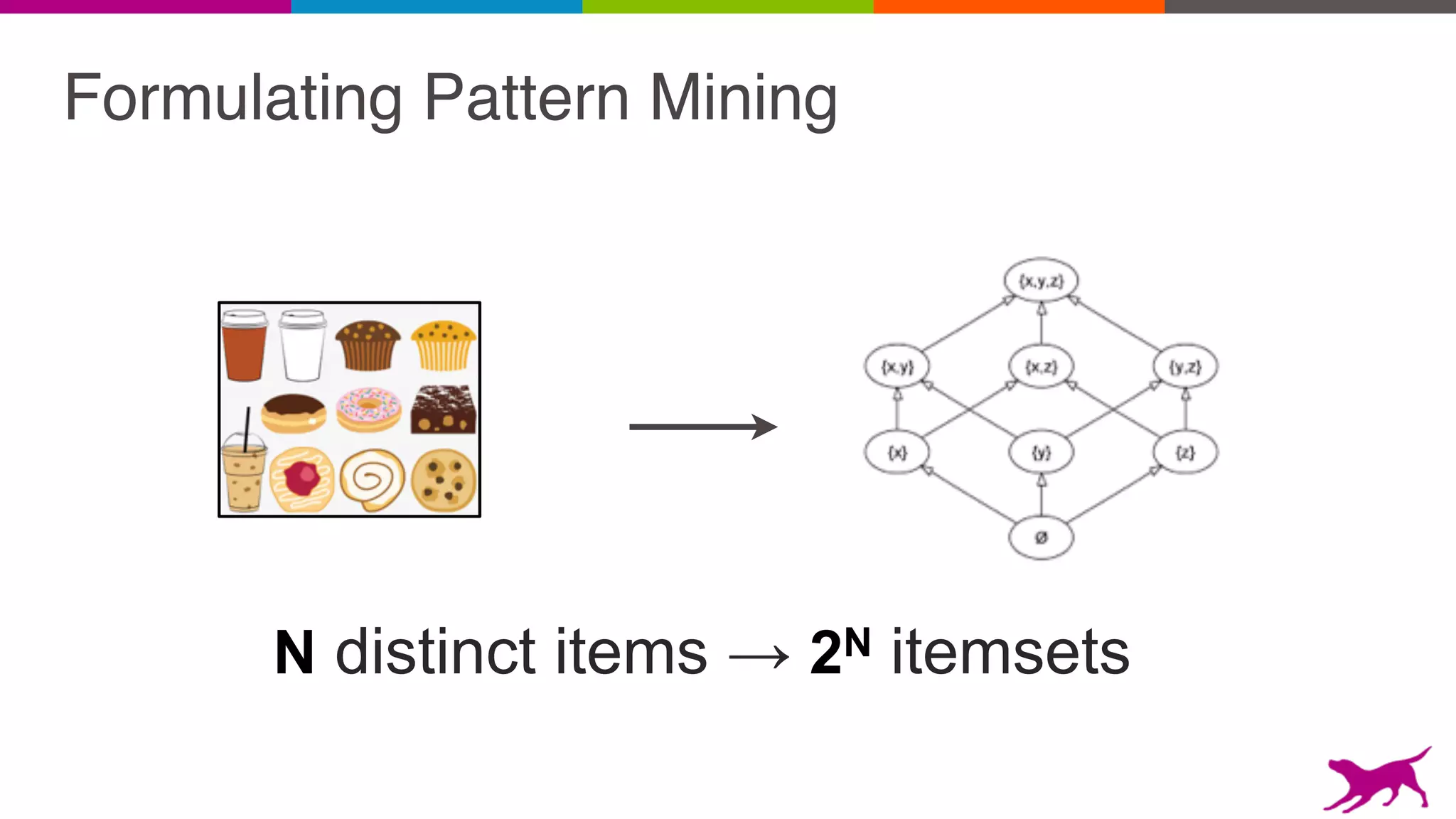
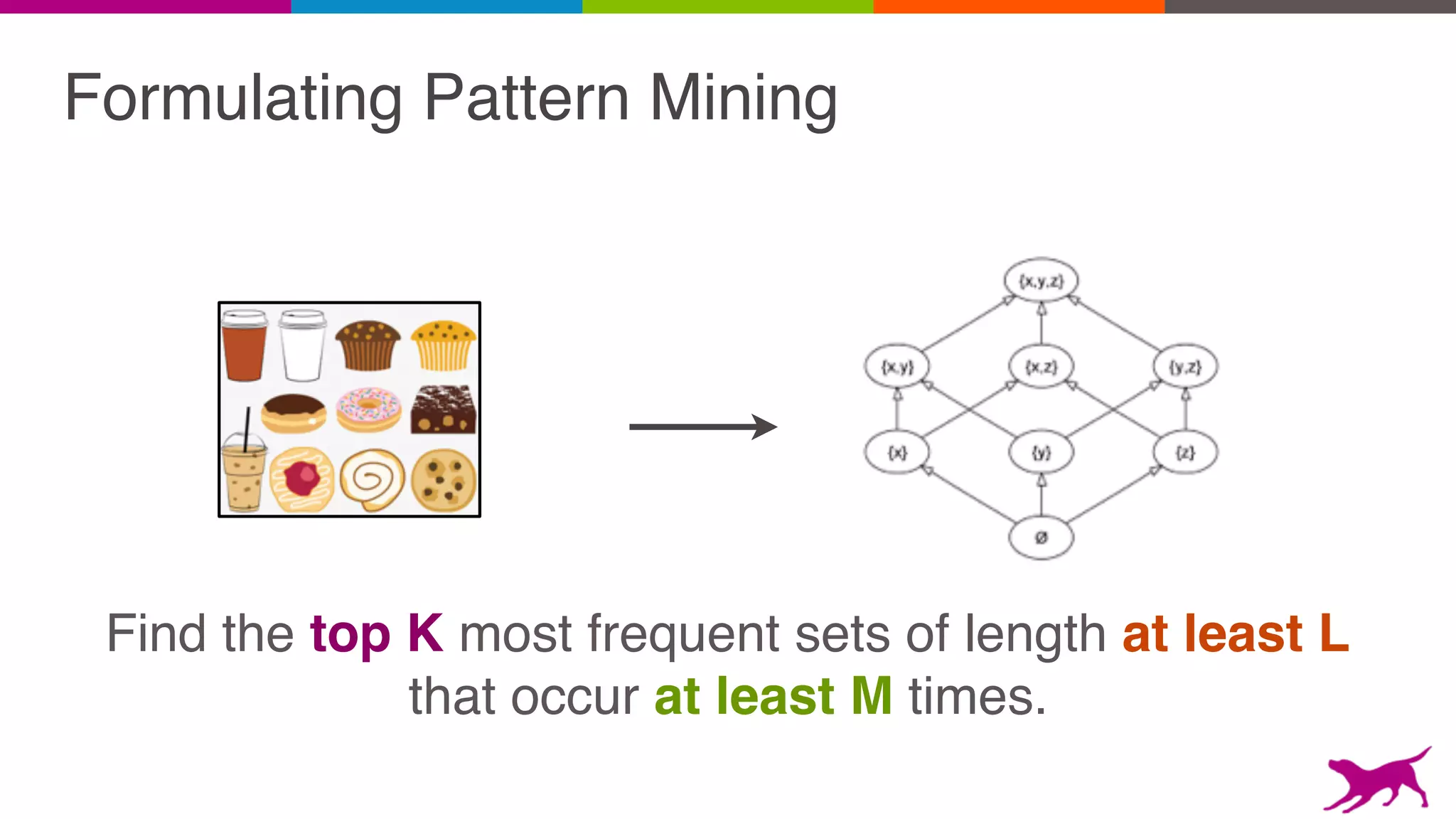
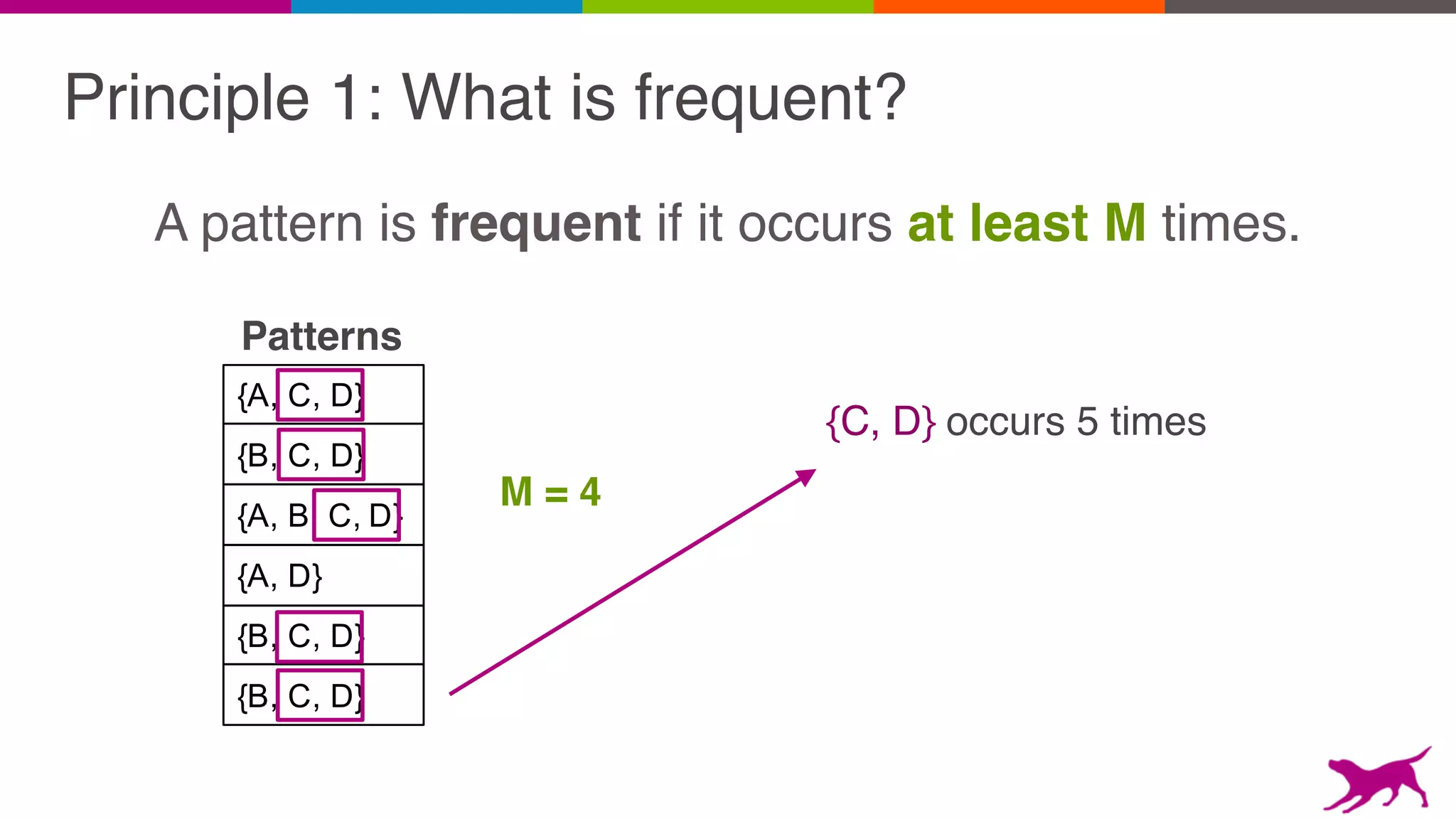
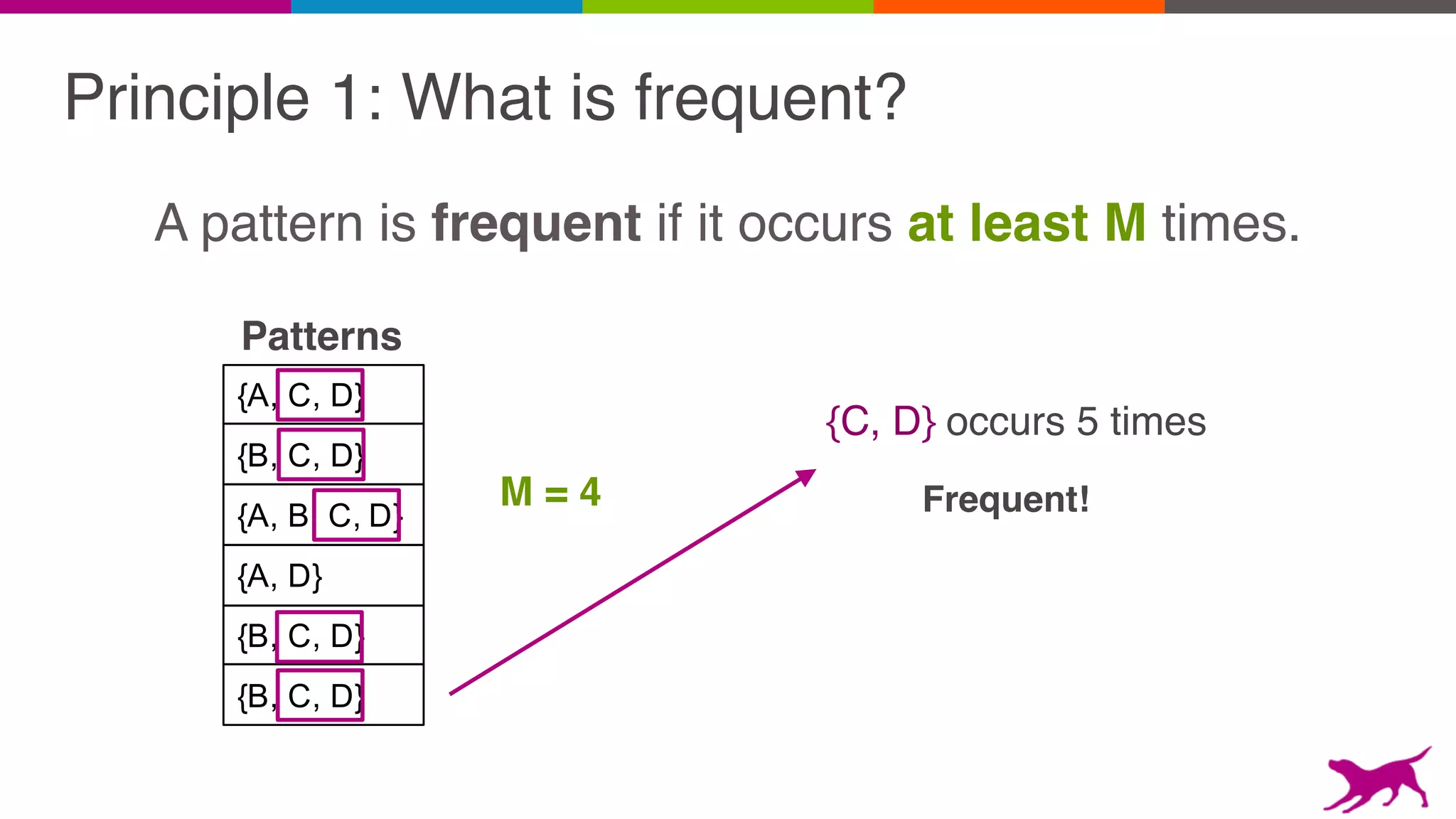
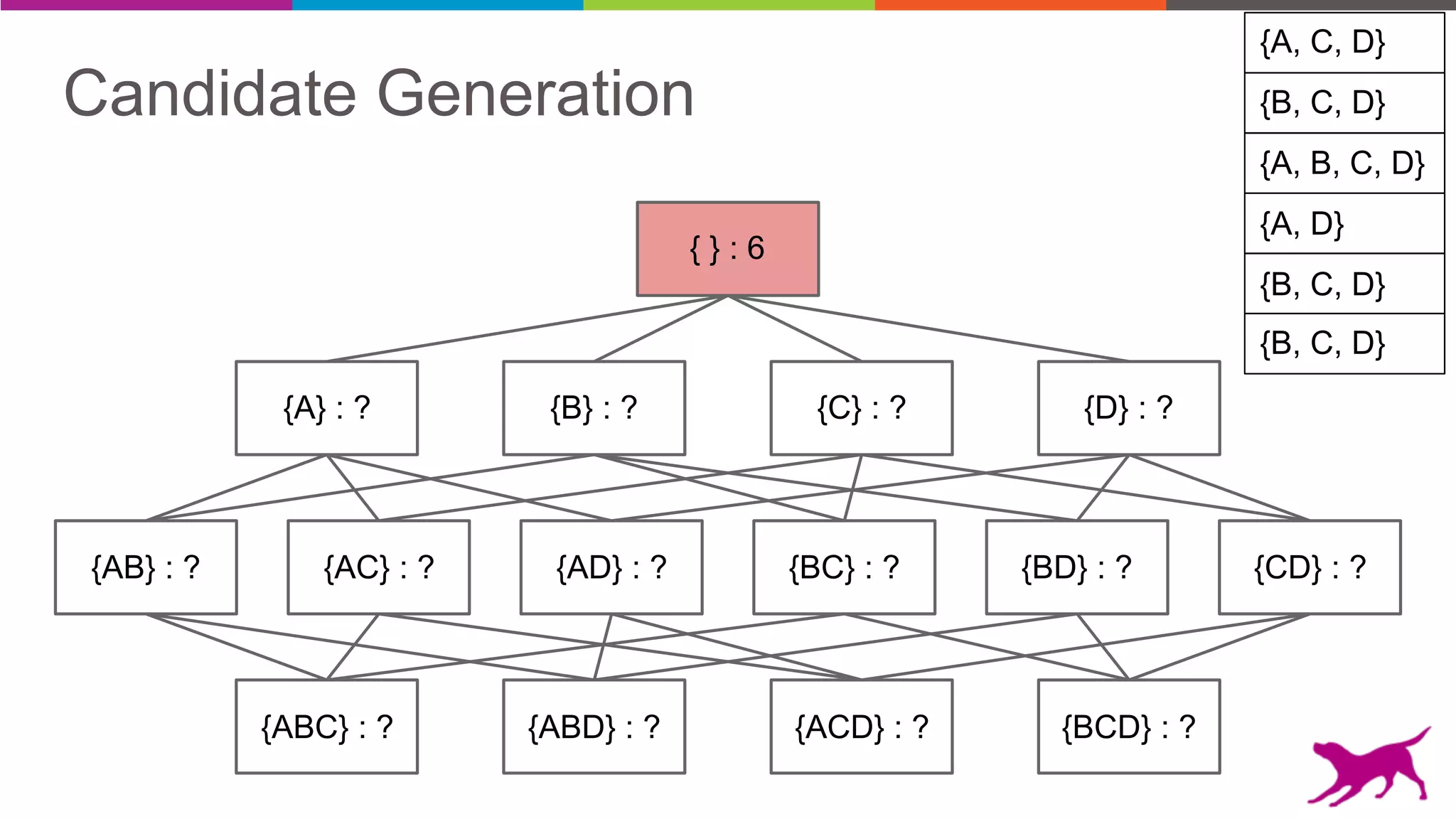
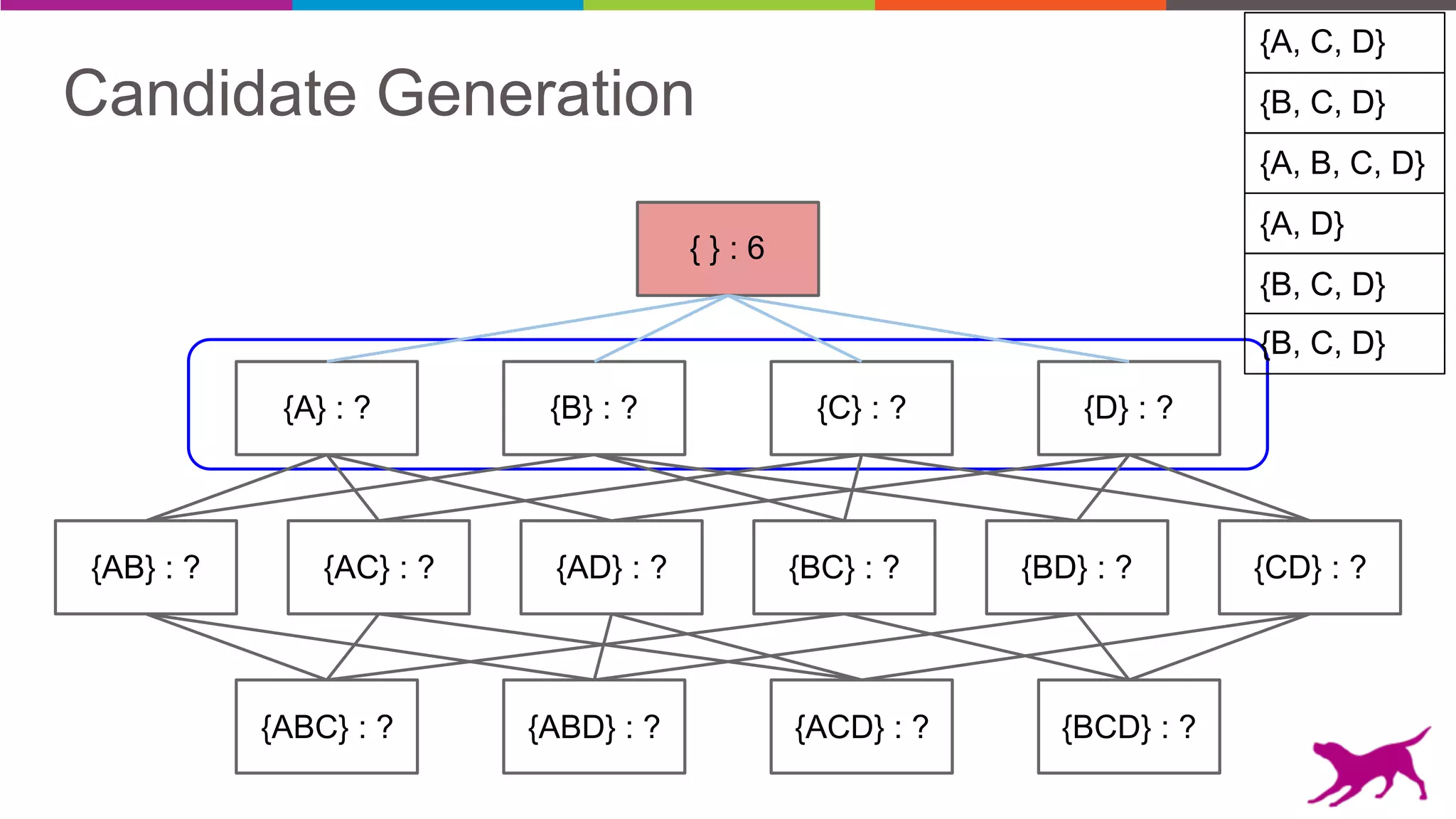
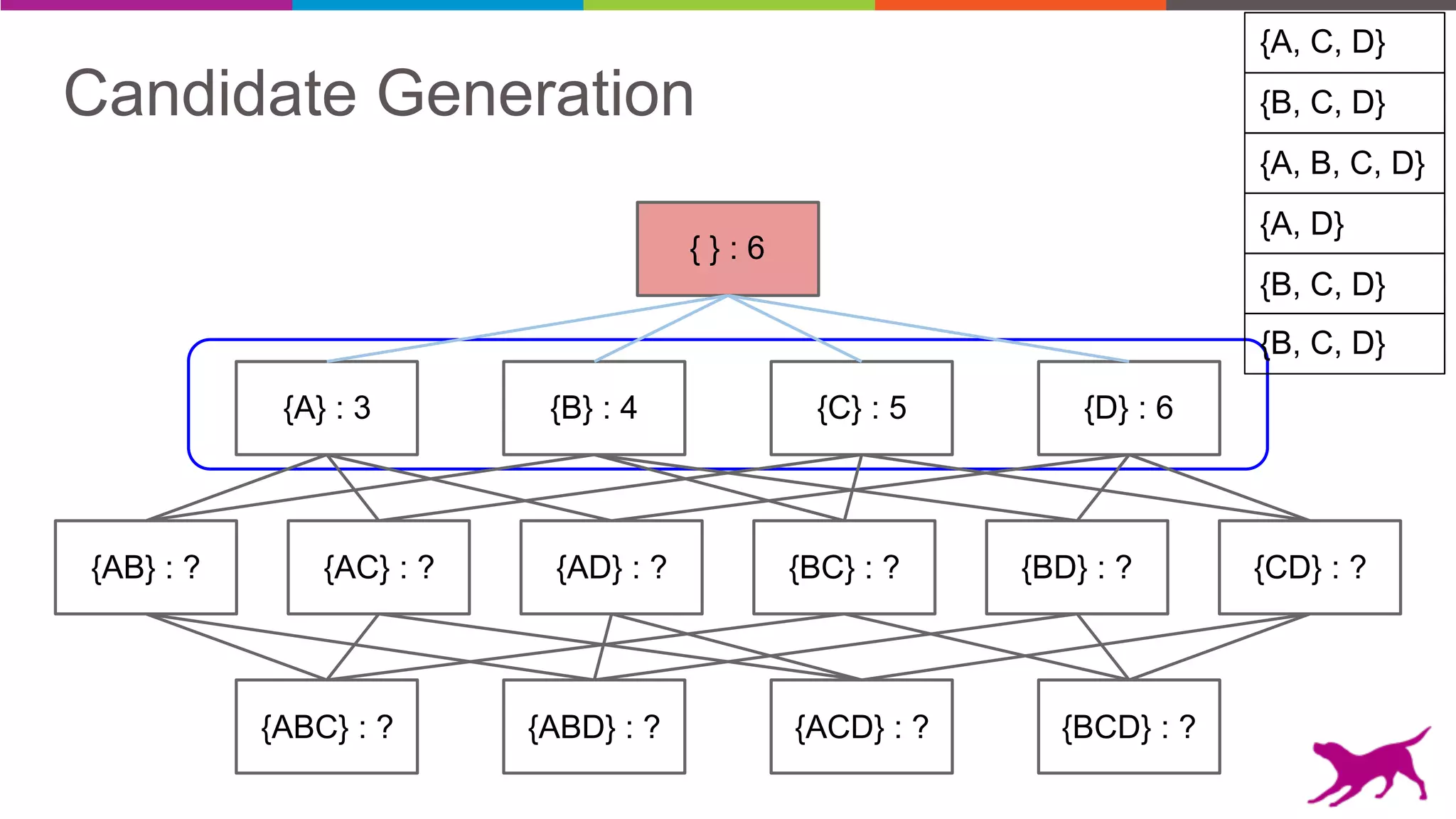
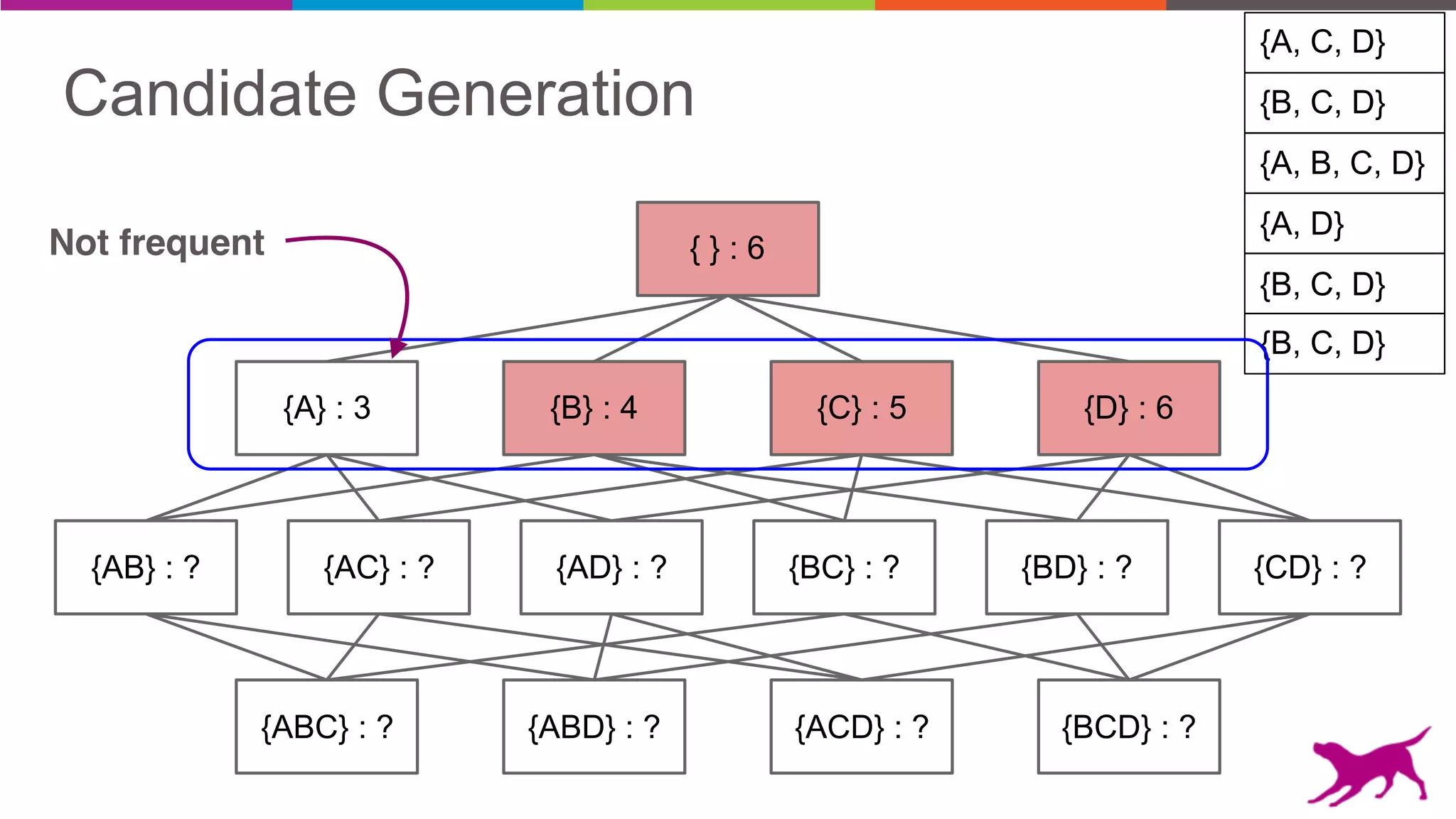
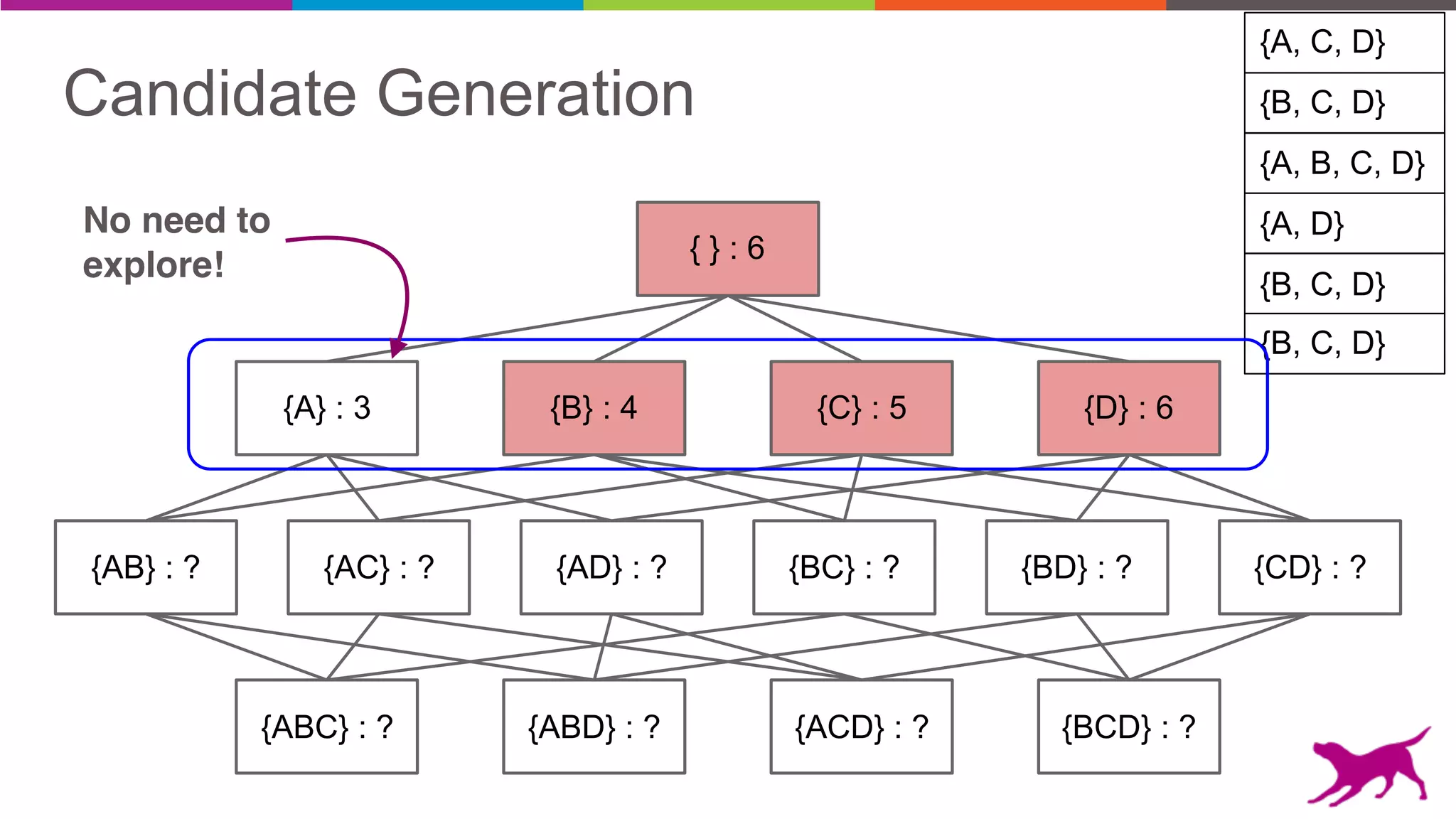
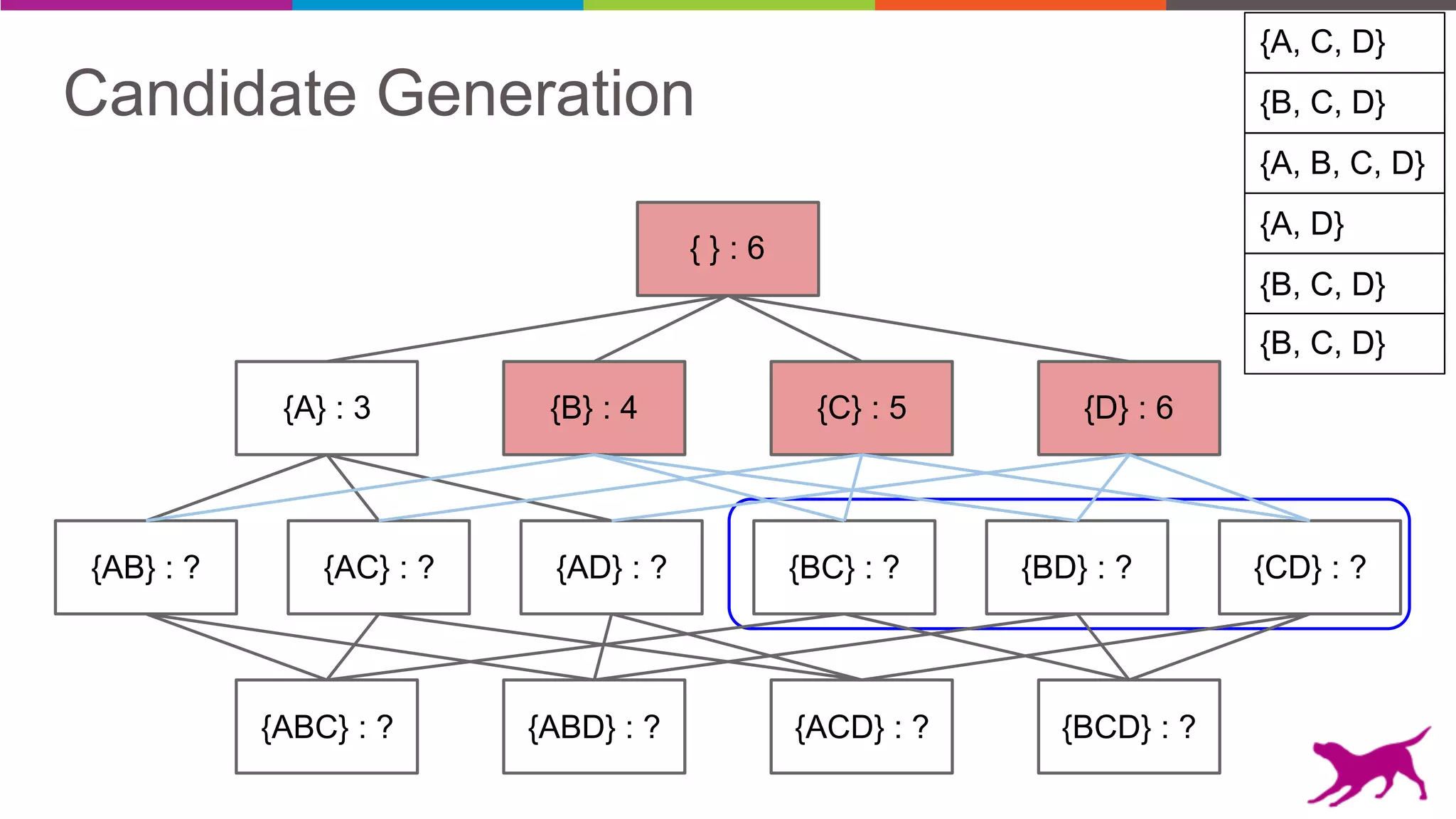
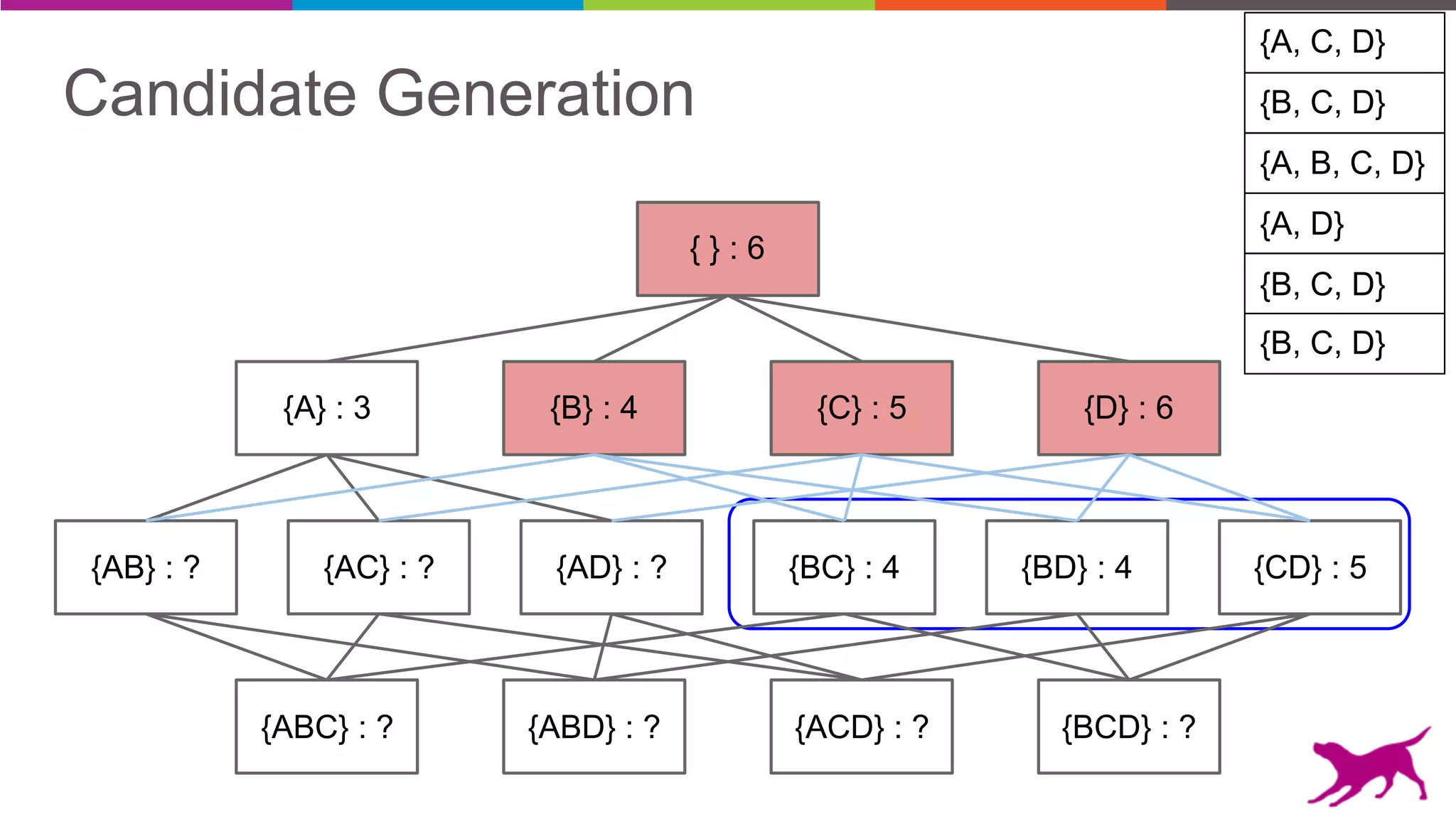
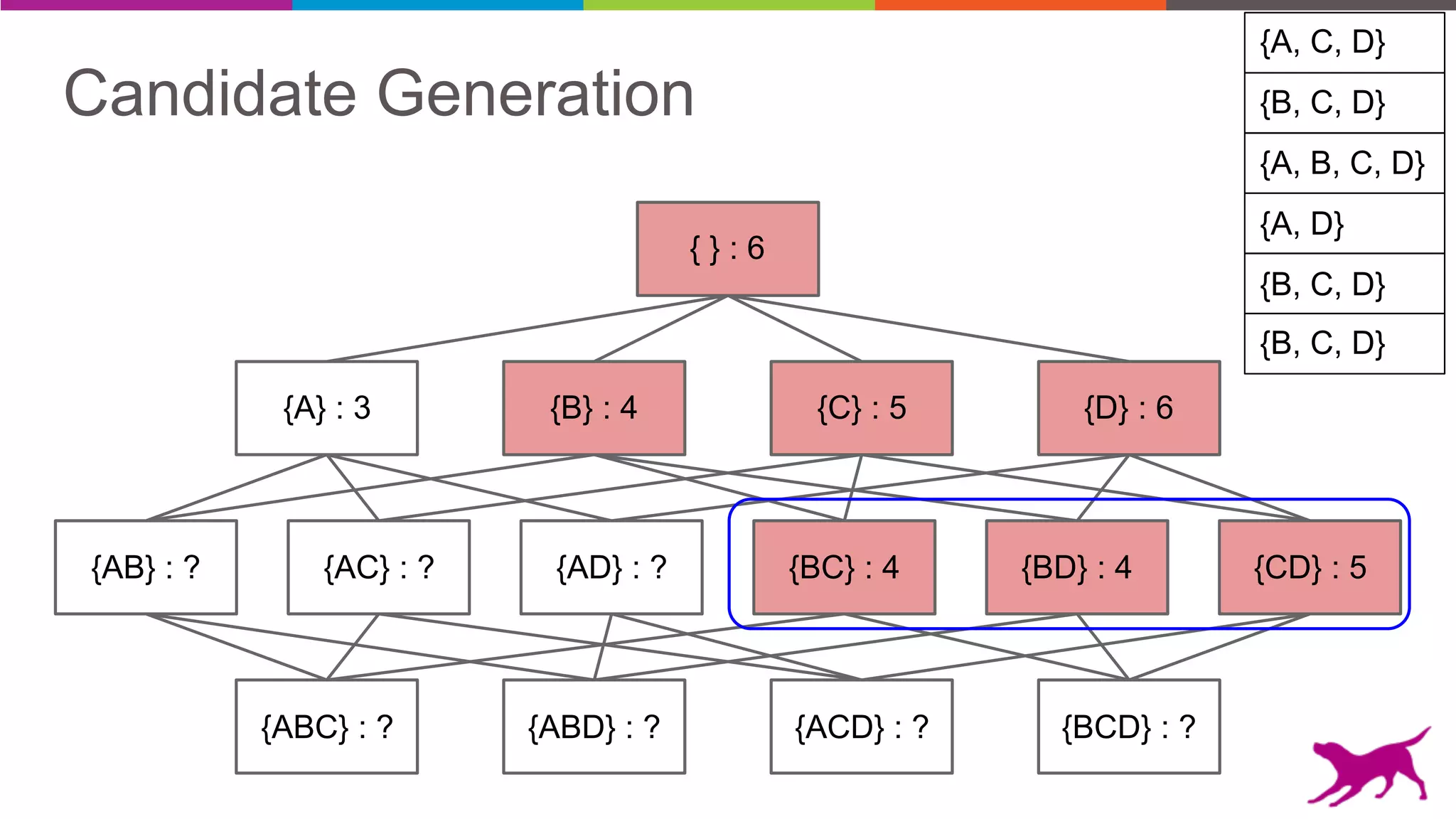
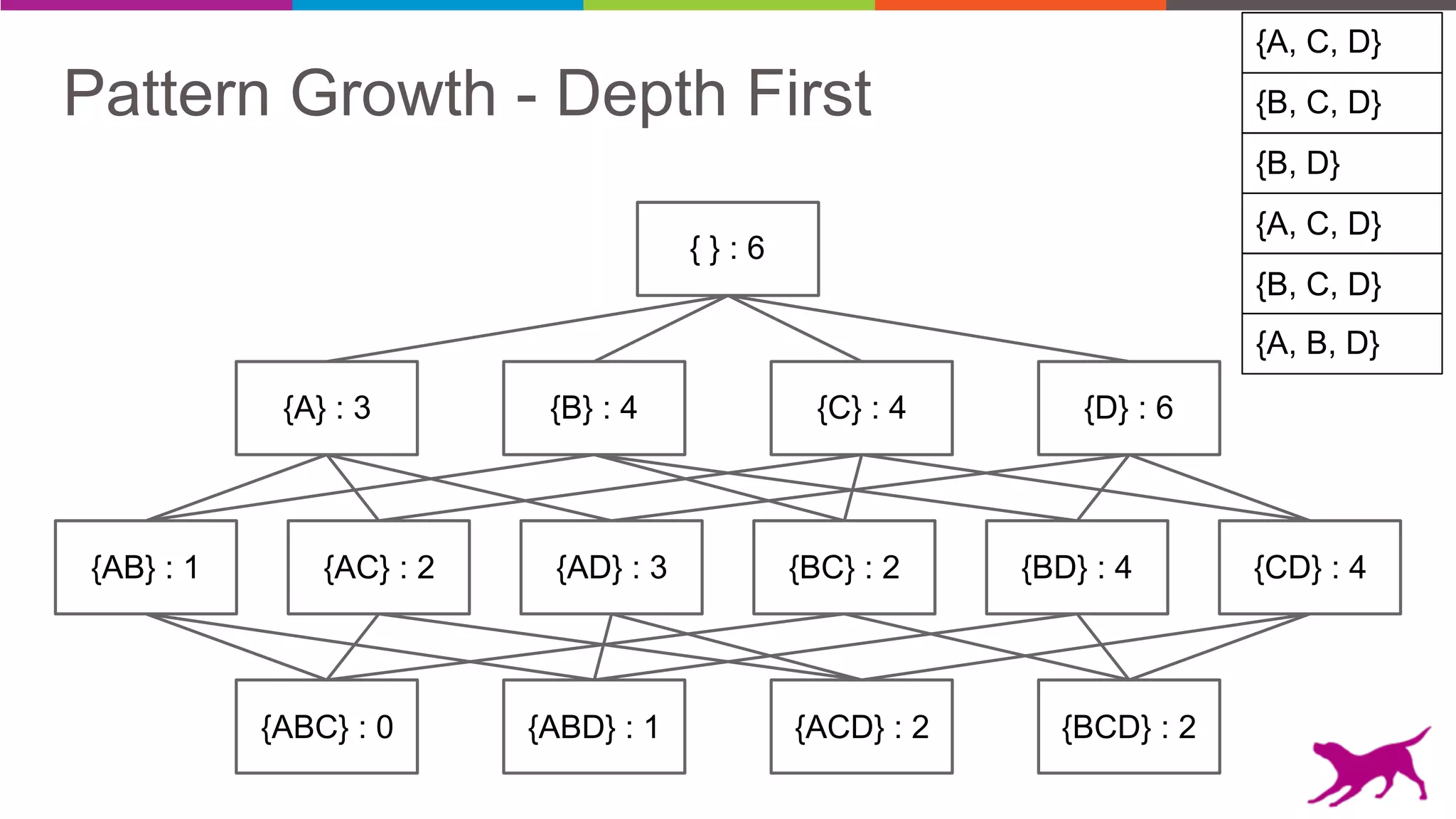
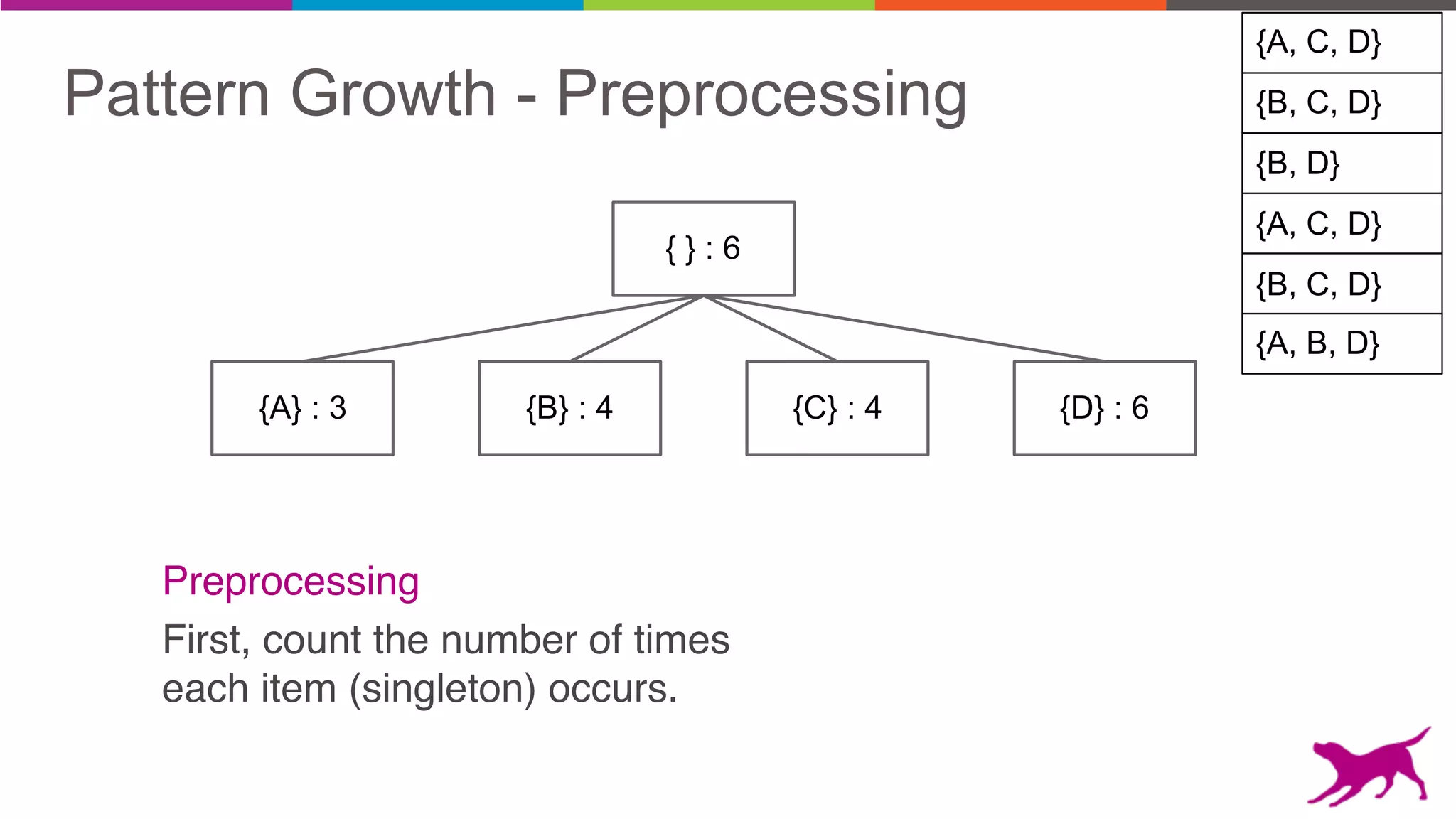
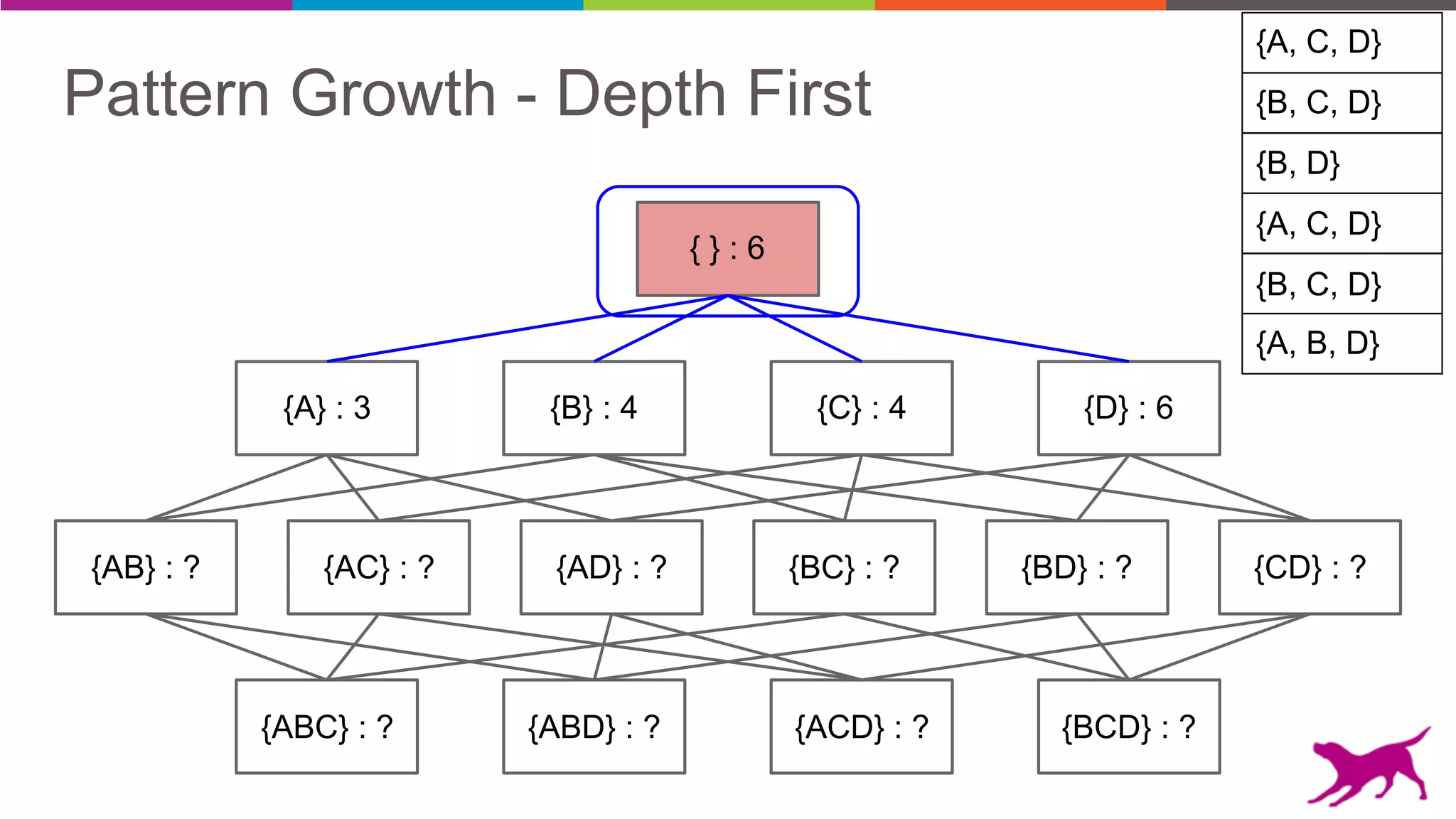
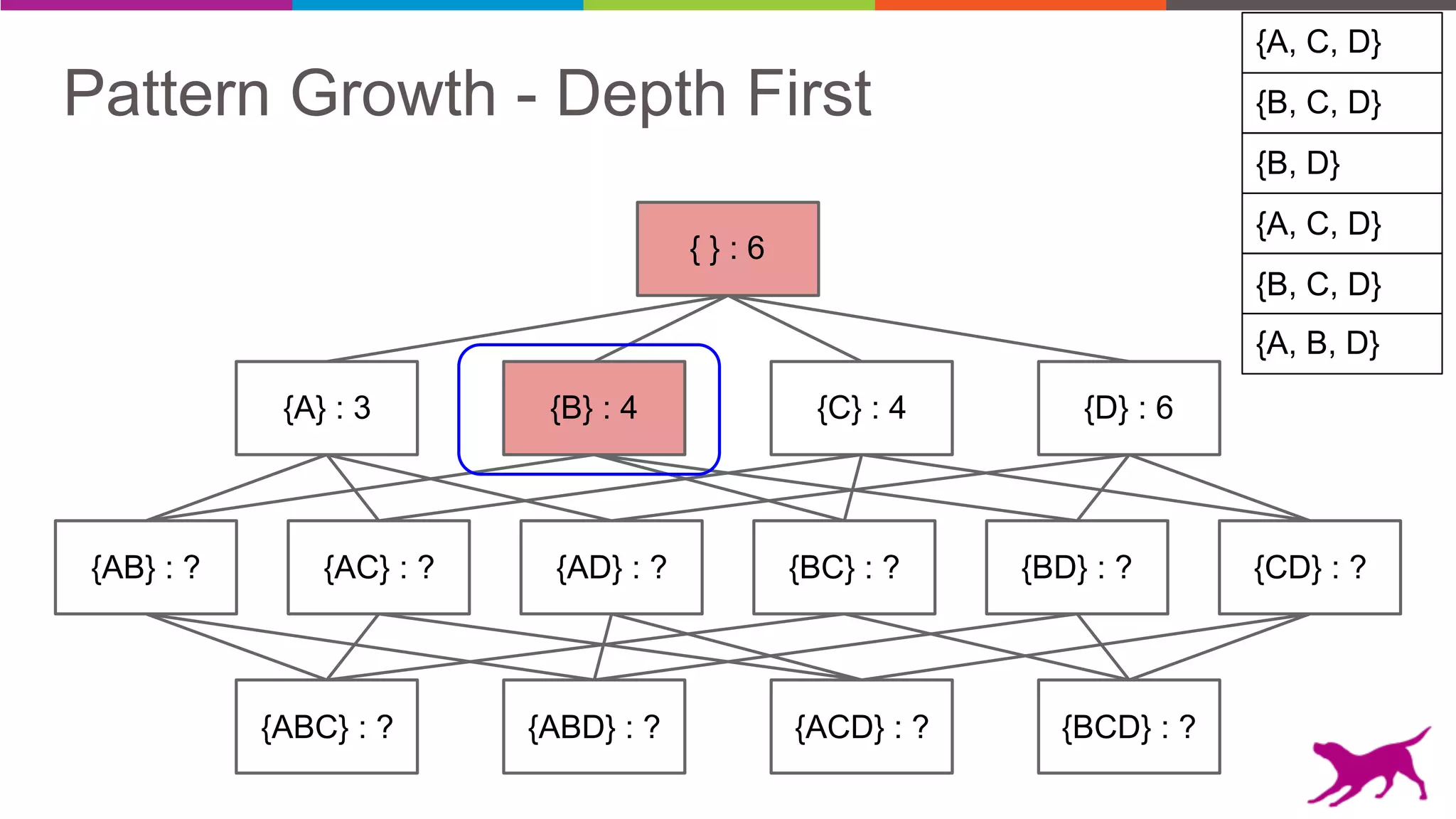
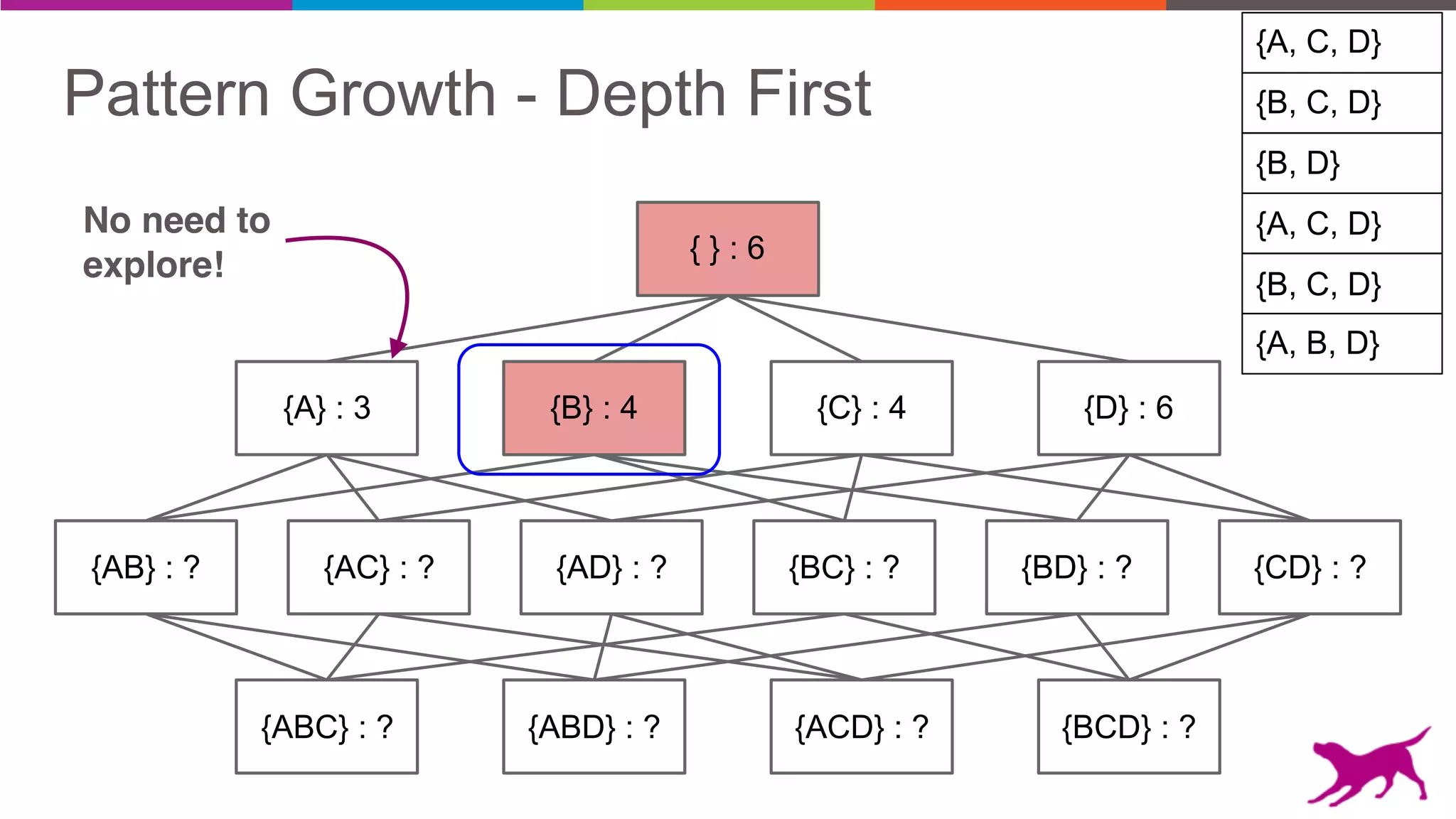
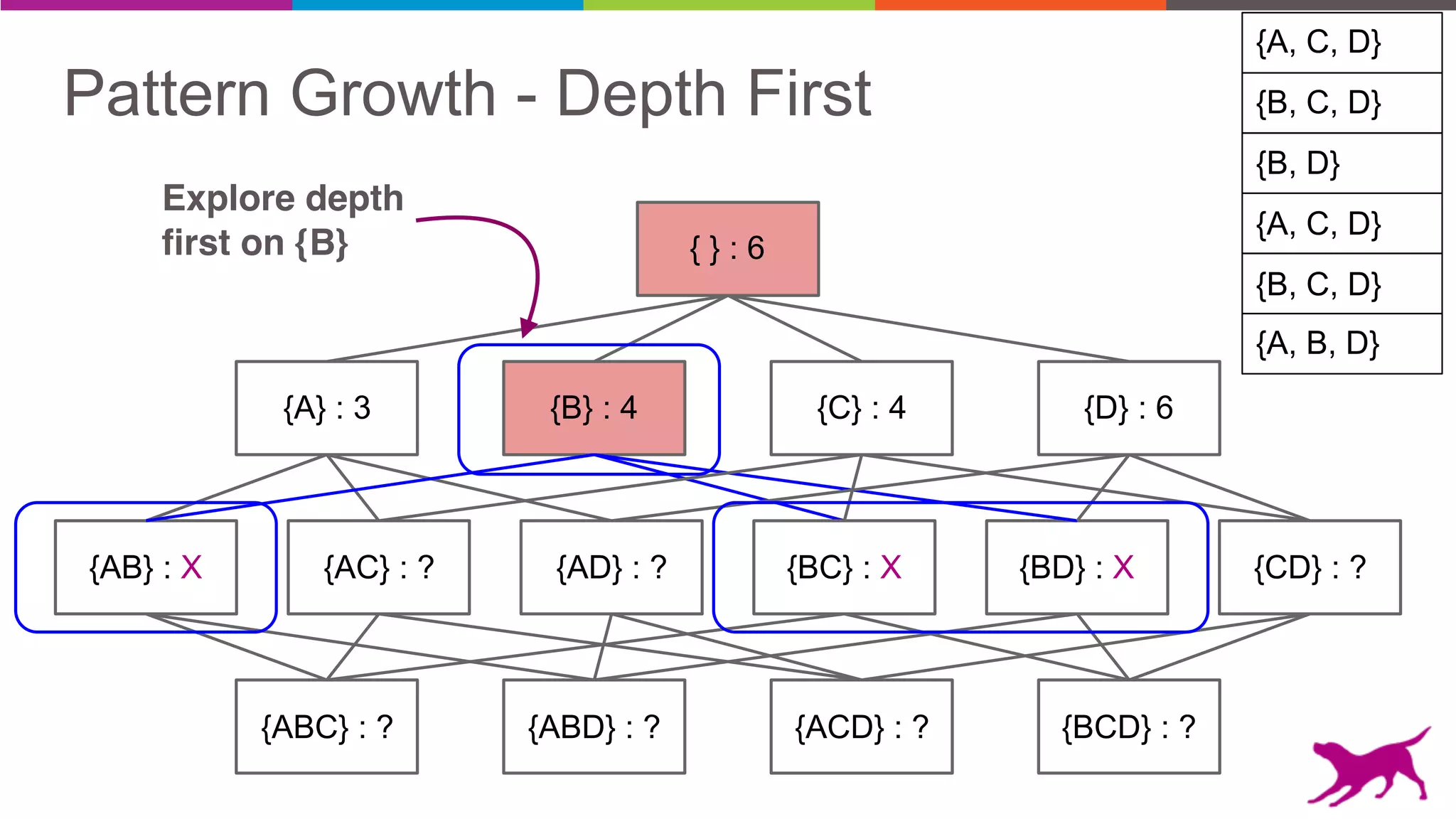
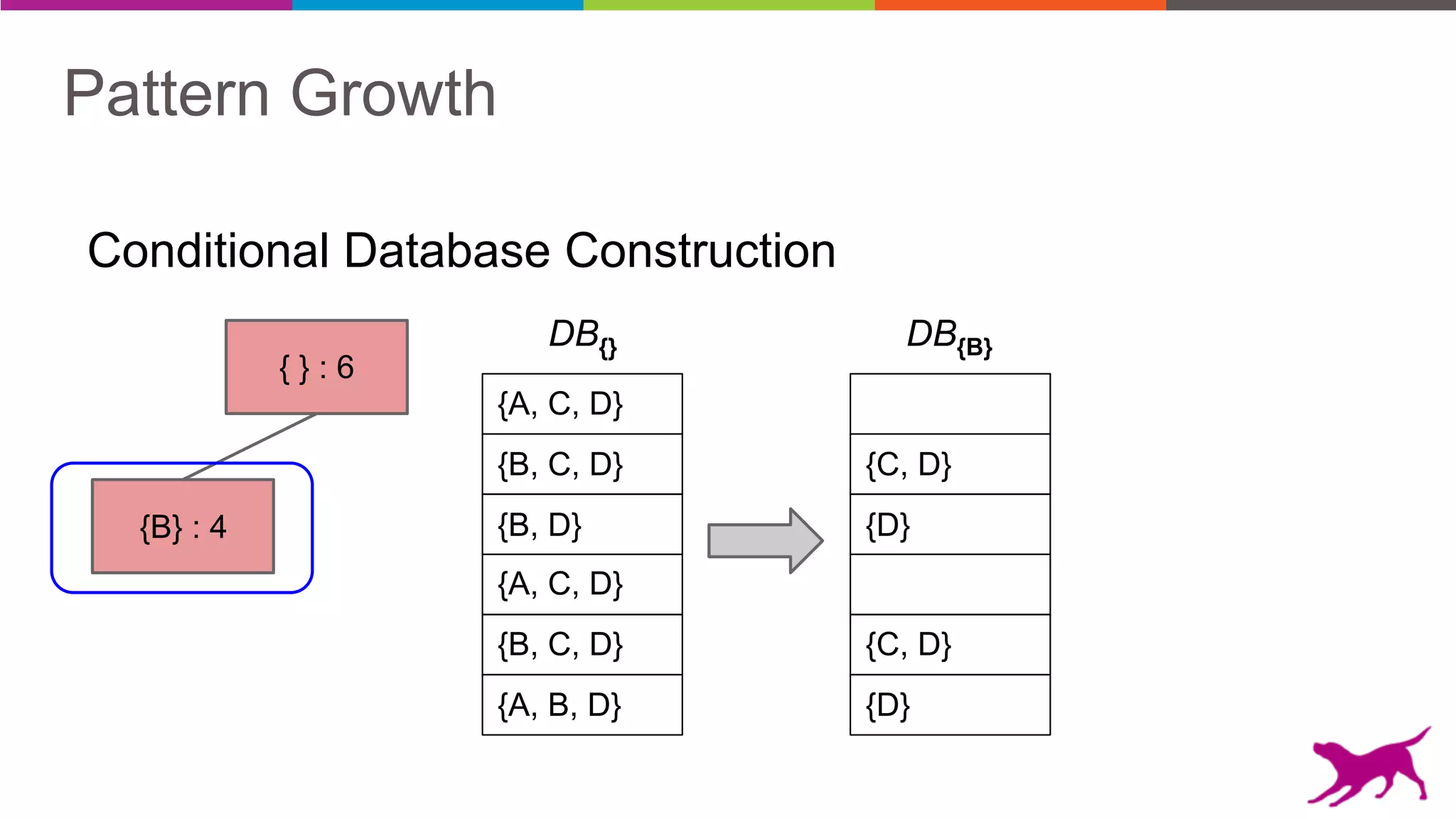
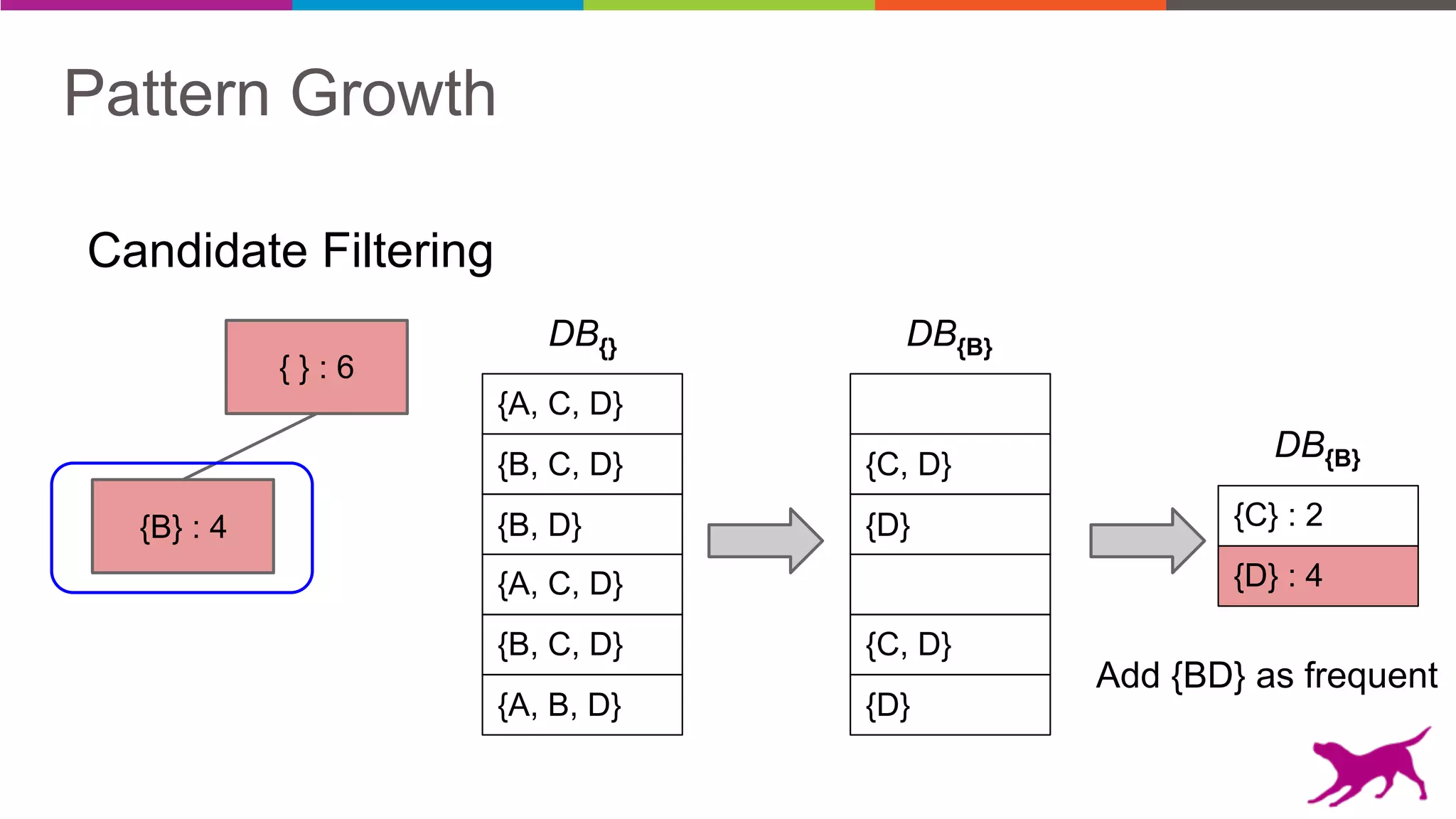
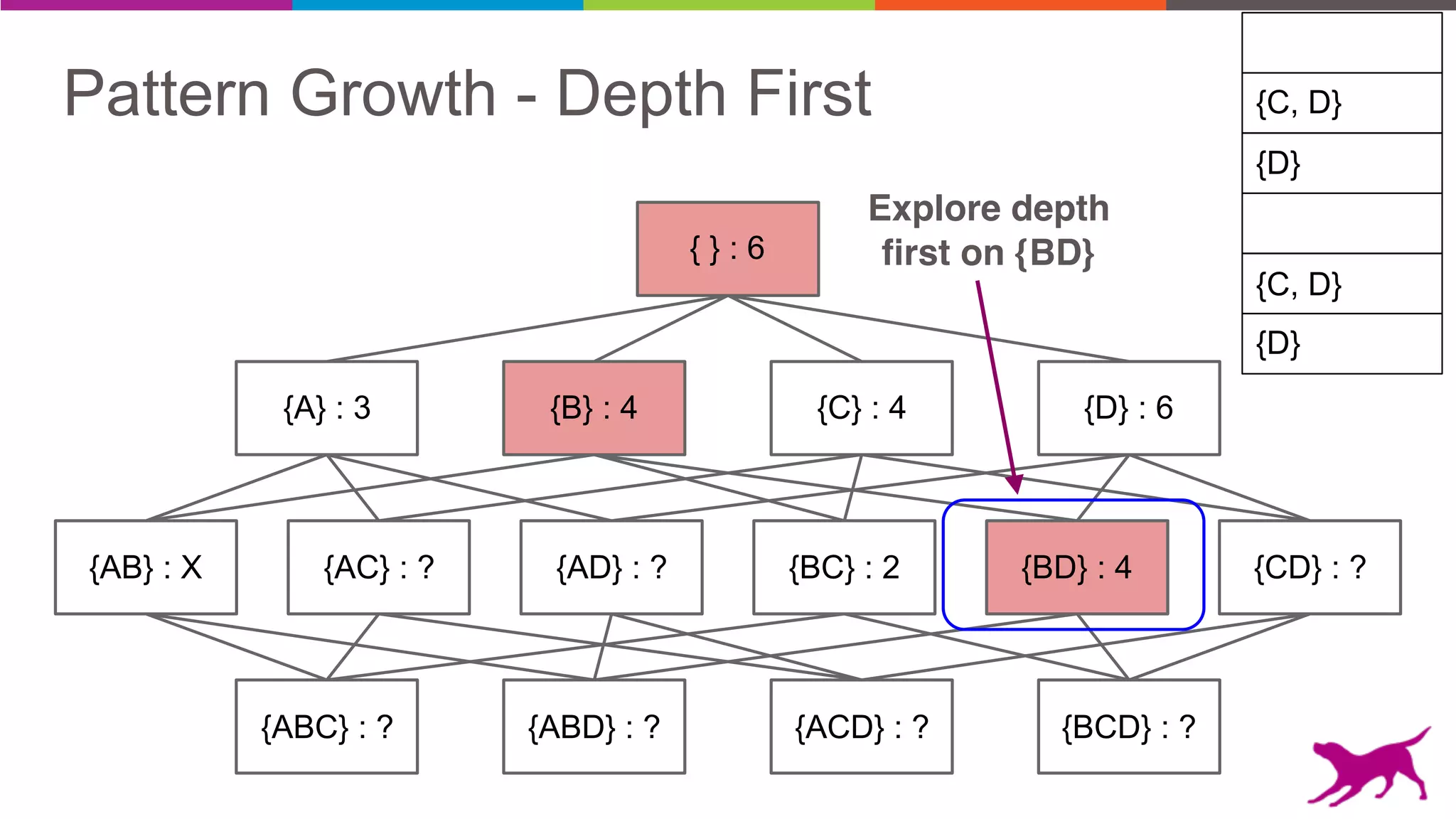
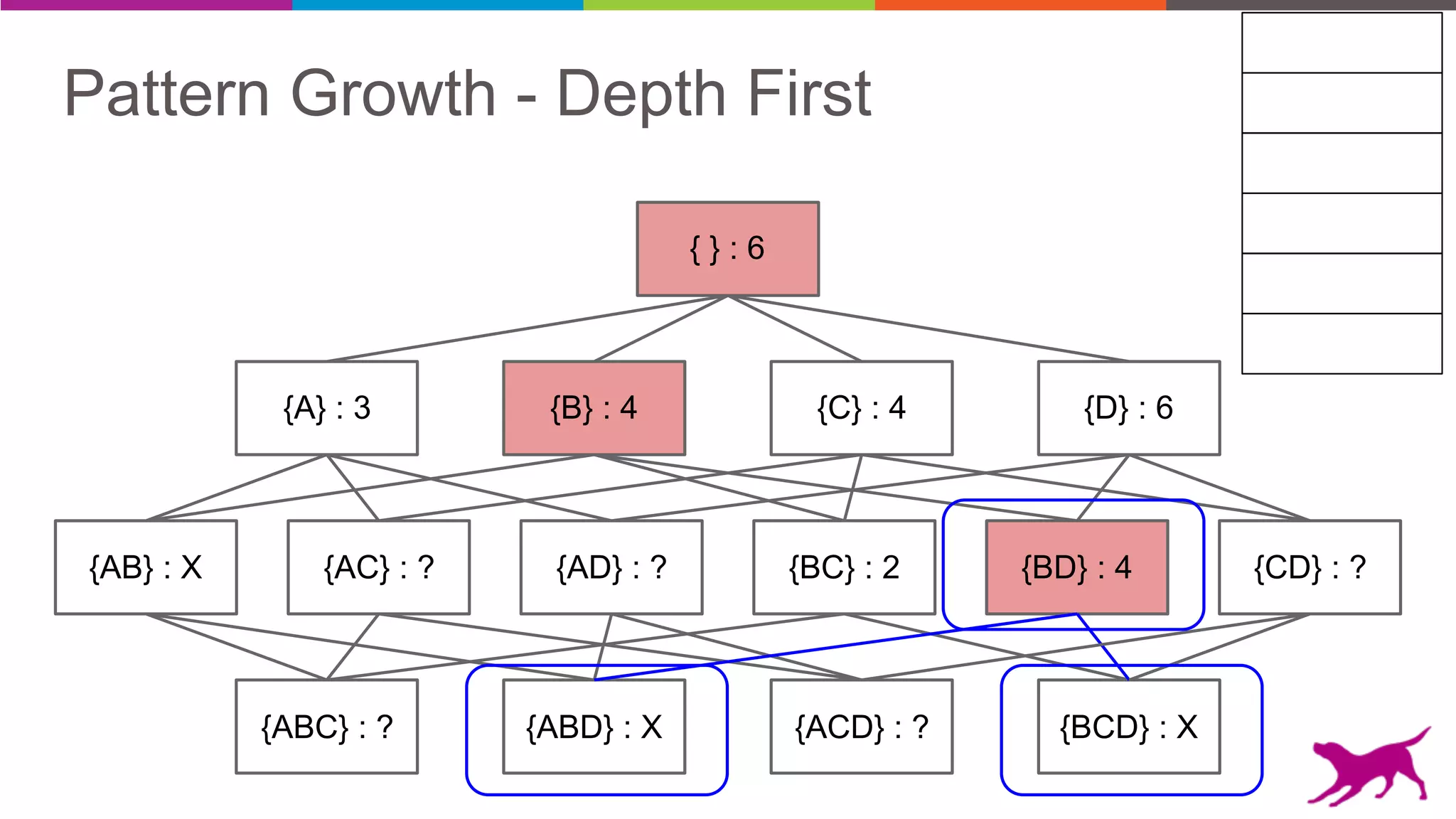
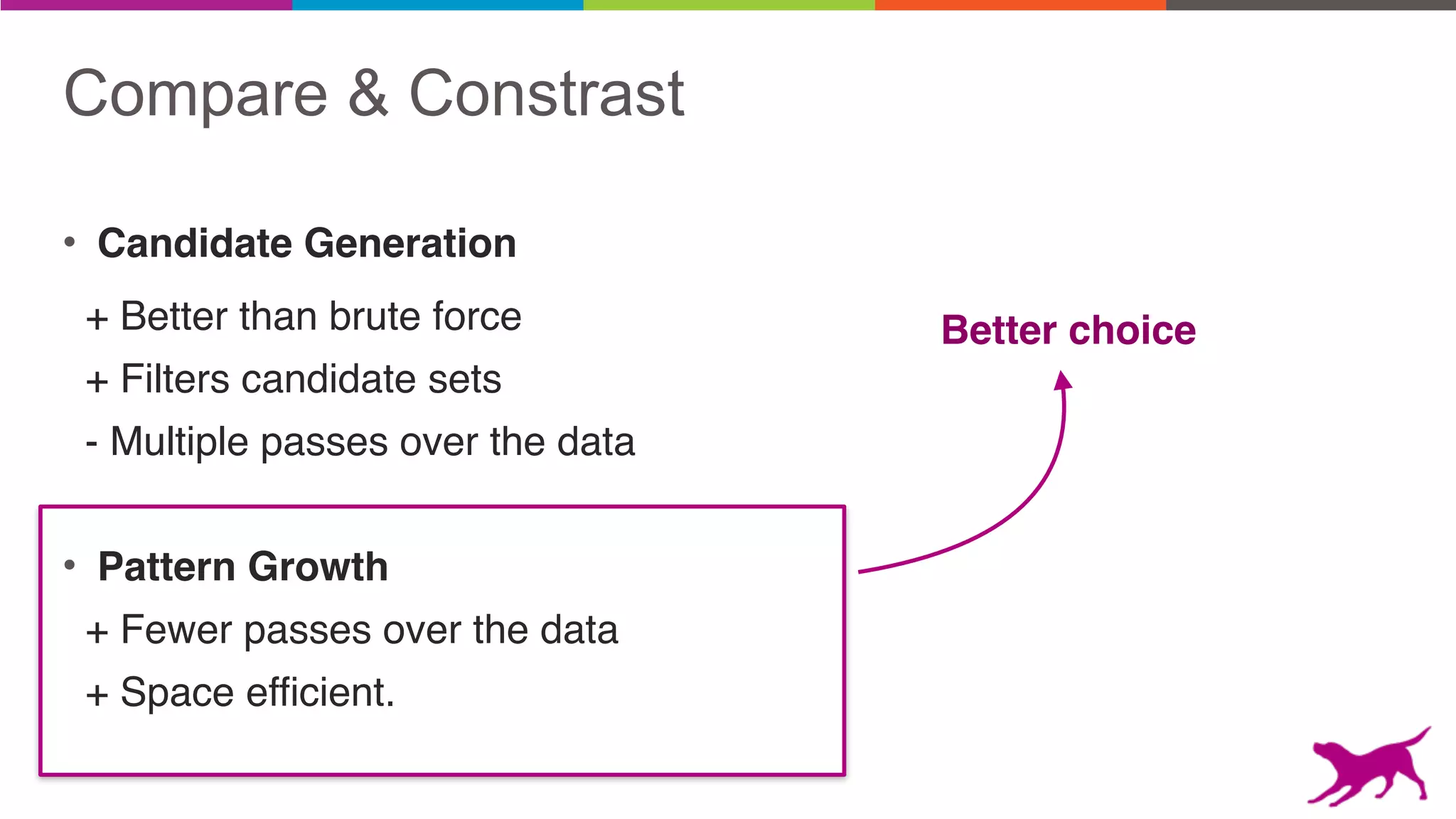
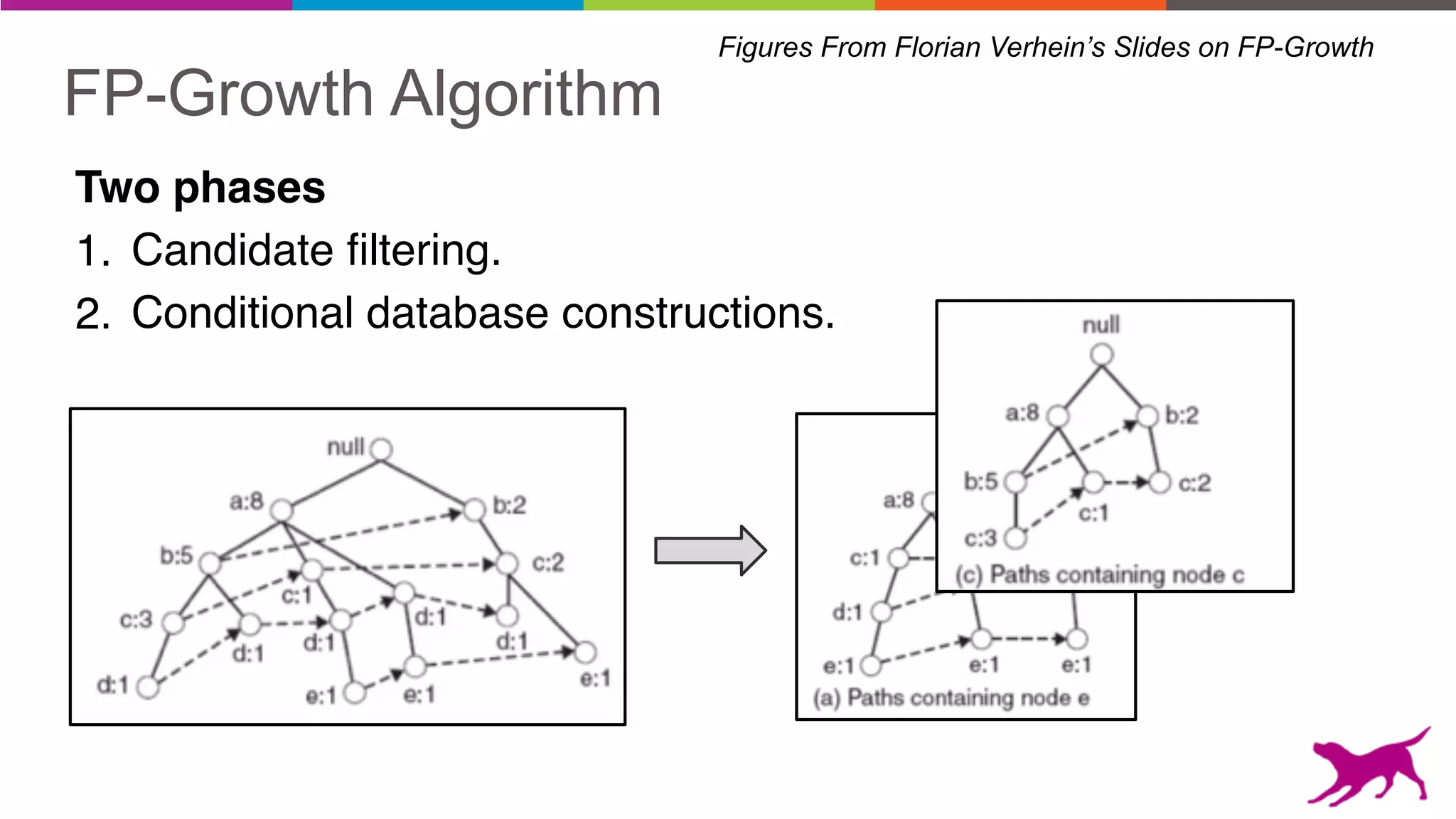
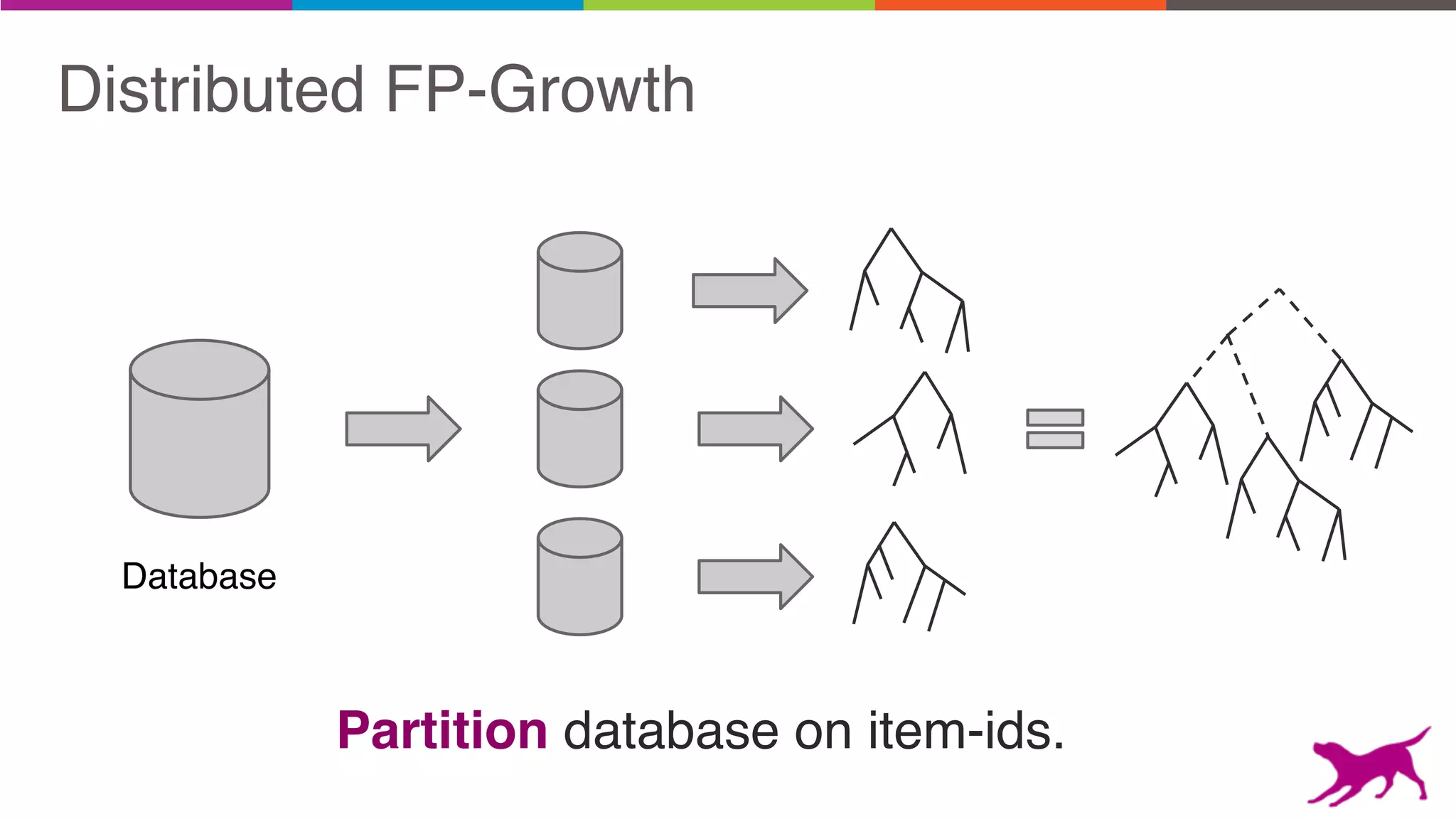
The document discusses pattern mining techniques for extracting insights from log data, focusing on algorithms like Apriori and FP-Growth. It covers the principles of what constitutes frequent patterns, and details the methods for candidate generation and filtering. The goal is to demonstrate how log mining can lead to valuable insights and facilitate data-driven decisions.