2
Association rule mining:
Findingfrequent patterns, associations, correlations, or causal structures
among sets of items or objects in transaction databases, relational
databases, and other information repositories.
Frequent pattern: pattern (set of items, sequence, etc.) that occurs
frequently in a database
Motivation: finding regularities in data:
What products were often purchased together? — Beer and diapers?!
What are the subsequent purchases after buying a PC?
What kinds of DNA are sensitive to this new drug?
Can we automatically classify web documents?
What is Association Mining?
3.
3
Itemset X={x1, …,xk}
Find all the rules XY with min confidence and support.
support, s, probability that a transaction contains XY
confidence, c, conditional probability that a transaction
having X also contains Y.
Basic concepts:
Transaction-id Items bought
10 A, B, C
20 A, C
30 A, D
40 B, E, F
Let min_support = 50%, min_conf = 50%:
We have :
1) A C
support = support({A}{C}) = 50%
confidence =
support({A}{C})/support({A}) = 66.6%
2) C A
support = support({A}{C}) = 50%
confidence =
support({A}{C})/support({C}) = 100%
4.
Apriori: A CandidateGeneration-and-test
Approach
Any subset of a frequent itemset must be frequent
if {beer, diaper, nuts} is frequent, so is {beer, diaper}
Every transaction having {beer, diaper, nuts} also contains {beer, diaper}
Apriori pruning principle: If there is any itemset which is
infrequent, its superset should not be generated/tested!
Method:
generate length (k+1) candidate itemsets from length k frequent itemsets, and
test the candidates against DB
4
5.
5
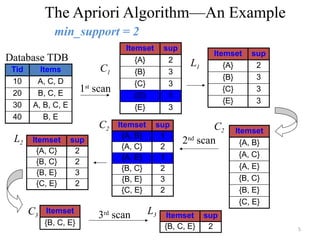
The Apriori Algorithm—AnExample
Frequency ≥ 50%, Confidence 100%:
A C
B E
BC E
CE B
BE C
Database TDB
1st
scan
C1
L1
L2
C2 C2
2nd
scan
C3 L3
3rd
scan
Tid Items
10 A, C, D
20 B, C, E
30 A, B, C, E
40 B, E
Itemset sup
{A} 2
{B} 3
{C} 3
{D} 1
{E} 3
Itemset sup
{A} 2
{B} 3
{C} 3
{E} 3
Itemset
{A, B}
{A, C}
{A, E}
{B, C}
{B, E}
{C, E}
Itemset sup
{A, B} 1
{A, C} 2
{A, E} 1
{B, C} 2
{B, E} 3
{C, E} 2
Itemset sup
{A, C} 2
{B, C} 2
{B, E} 3
{C, E} 2
Itemset
{B, C, E}
Itemset sup
{B, C, E} 2
min_support = 2
6.
6
The Apriori Algorithm
Pseudo-code:
Ck:Candidate itemset of size k
Lk : frequent itemset of size k
L1 = {frequent items};
for (k = 1; Lk !=; k++) do begin
Ck+1 = candidates generated from Lk;
for each transaction t in database do
increment the count of all candidates in Ck+1
that are contained in t
Lk+1 = candidates in Ck+1 with min_support
end
return k Lk;
7.
7
Important Details ofApriori
•How to generate candidates?
Step 1: self-joining Lk
Step 2: pruning
•How to count supports of candidates?
•Example of Candidate-generation
L3={abc, abd, acd, ace, bcd}
Self-joining: L3*L3
abcd from abc and abd
acde from acd and ace
Pruning:
acde is removed because ade is not in L3
C4={abcd}
8.
8
Important Details ofApriori
Suppose the items in Lk-1 are listed in an order
Step 1: self-joining Lk-1
insert into Ck
select p.item1, p.item2, …, p.itemk-1, q.itemk-1
from Lk-1 p, Lk-1 q
where p.item1=q.item1, …, p.itemk-2=q.itemk-2, p.itemk-1 < q.itemk-1
Step 2: pruning
itemsets c in Ck do
(k-1)-subsets s of c do
if (s is not in Lk-1) then delete c from Ck
9.
9
Bottleneck of frequentitemsets
Multiple database scans are costly
Mining long patterns needs many passes of scanning and
generates lots of candidates
To find frequent itemset i1i2…i100
Number of scans: 100
Number of Candidates: + + …
= - 1 = 1.27 * ;
10.
10
Mining frequent patternswithout candidate generation
Grow long patterns from short ones using local frequent items
“abc” is a frequent pattern
Get all transactions having “abc”: DB|abc
“d” is a local frequent item in DB|abc abcd is a frequent
pattern;
12
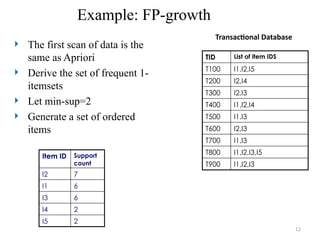
Example: FP-growth
Thefirst scan of data is the
same as Apriori
Derive the set of frequent 1-
itemsets
Let min-sup=2
Generate a set of ordered
items
TID List of item IDS
T100 I1,I2,I5
T200 I2,I4
T300 I2,I3
T400 I1,I2,I4
T500 I1,I3
T600 I2,I3
T700 I1,I3
T800 I1,I2,I3,I5
T900 I1,I2,I3
Transactional Database
Item ID Support
count
I2 7
I1 6
I3 6
I4 2
I5 2
13.
13
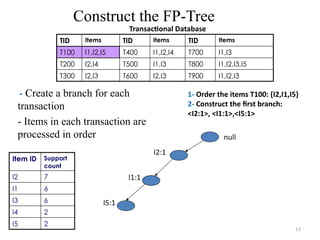
Construct the FP-Tree
TransactionalDatabase
Item ID Support
count
I2 7
I1 6
I3 6
I4 2
I5 2
null
- Create a branch for each
transaction
- Items in each transaction are
processed in order
1- Order the items T100: {I2,I1,I5}
2- Construct the first branch:
<I2:1>, <I1:1>,<I5:1>
TID Items TID Items TID Items
T100 I1,I2,I5 T400 I1,I2,I4 T700 I1,I3
T200 I2,I4 T500 I1,I3 T800 I1,I2,I3,I5
T300 I2,I3 T600 I2,I3 T900 I1,I2,I3
I2:1
I1:1
I5:1
14.
14
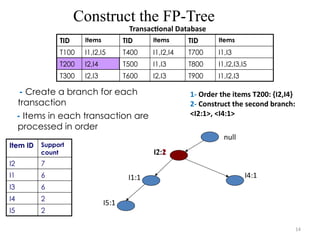
Construct the FP-Tree
TransactionalDatabase
Item ID Support
count
I2 7
I1 6
I3 6
I4 2
I5 2
null
- Create a branch for each
transaction
- Items in each transaction are
processed in order
1- Order the items T200: {I2,I4}
2- Construct the second branch:
<I2:1>, <I4:1>
TID Items TID Items TID Items
T100 I1,I2,I5 T400 I1,I2,I4 T700 I1,I3
T200 I2,I4 T500 I1,I3 T800 I1,I2,I3,I5
T300 I2,I3 T600 I2,I3 T900 I1,I2,I3
I2:1
I1:1
I5:1
I4:1
I2:2
15.
15
Construct the FP-Tree
TransactionalDatabase
Item ID Support
count
I2 7
I1 6
I3 6
I4 2
I5 2
null
- Create a branch for each
transaction
- Items in each transaction are
processed in order
1- Order the items T300: {I2,I3}
2- Construct the third branch:
<I2:2>, <I3:1>
TID Items TID Items TID Items
T100 I1,I2,I5 T400 I1,I2,I4 T700 I1,I3
T200 I2,I4 T500 I1,I3 T800 I1,I2,I3,I5
T300 I2,I3 T600 I2,I3 T900 I1,I2,I3
I2:2
I1:1
I5:1
I4:1
I3:1
I2:3
16.
16
Construct the FP-Tree
TransactionalDatabase
Item ID Support
count
I2 7
I1 6
I3 6
I4 2
I5 2
null
- Create a branch for each
transaction
- Items in each transaction are
processed in order
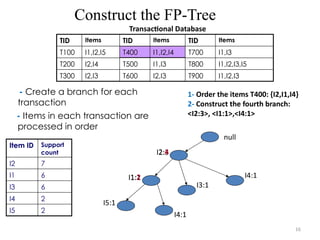
1- Order the items T400: {I2,I1,I4}
2- Construct the fourth branch:
<I2:3>, <I1:1>,<I4:1>
TID Items TID Items TID Items
T100 I1,I2,I5 T400 I1,I2,I4 T700 I1,I3
T200 I2,I4 T500 I1,I3 T800 I1,I2,I3,I5
T300 I2,I3 T600 I2,I3 T900 I1,I2,I3
I1:1
I5:1
I4:1
I3:1
I2:3
I4:1
I1:2
I2:4
17.
17
Construct the FP-Tree
TransactionalDatabase
Item ID Support
count
I2 7
I1 6
I3 6
I4 2
I5 2
null
- Create a branch for each
transaction
- Items in each transaction are
processed in order
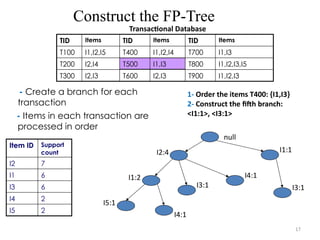
1- Order the items T400: {I1,I3}
2- Construct the fifth branch:
<I1:1>, <I3:1>
TID Items TID Items TID Items
T100 I1,I2,I5 T400 I1,I2,I4 T700 I1,I3
T200 I2,I4 T500 I1,I3 T800 I1,I2,I3,I5
T300 I2,I3 T600 I2,I3 T900 I1,I2,I3
I1:2
I5:1
I4:1
I3:1
I2:4
I4:1
I1:1
I3:1
18.
18
Construct the FP-Tree
TransactionalDatabase
Item ID Support
count
I2 7
I1 6
I3 6
I4 2
I5 2
null
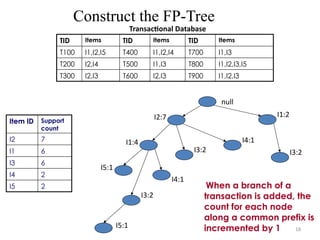
TID Items TID Items TID Items
T100 I1,I2,I5 T400 I1,I2,I4 T700 I1,I3
T200 I2,I4 T500 I1,I3 T800 I1,I2,I3,I5
T300 I2,I3 T600 I2,I3 T900 I1,I2,I3
I1:4
I5:1
I4:1
I3:2
I2:7
I4:1
I1:2
I3:2
I3:2
I5:1
When a branch of a
transaction is added, the
count for each node
along a common prefix is
incremented by 1
19.
19
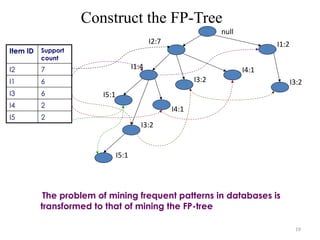
Construct the FP-Tree
ItemID Support
count
I2 7
I1 6
I3 6
I4 2
I5 2
null
I1:4
I5:1
I4:1
I3:2
I2:7
I4:1
I1:2
I3:2
I3:2
I5:1
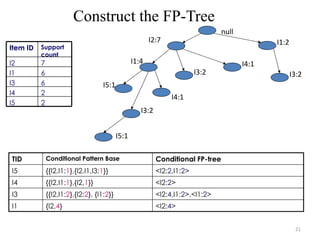
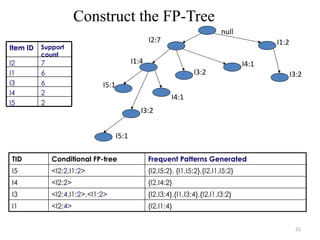
The problem of mining frequent patterns in databases is
transformed to that of mining the FP-tree
20.
20
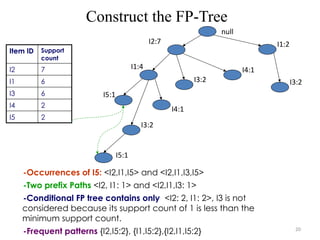
Construct the FP-Tree
-Occurrencesof I5: <I2,I1,I5> and <I2,I1,I3,I5>
-Two prefix Paths <I2, I1: 1> and <I2,I1,I3: 1>
-Conditional FP tree contains only <I2: 2, I1: 2>, I3 is not
considered because its support count of 1 is less than the
minimum support count.
-Frequent patterns {I2,I5:2}, {I1,I5:2},{I2,I1,I5:2}
Item ID Support
count
I2 7
I1 6
I3 6
I4 2
I5 2
null
I1:4
I5:1
I4:1
I3:2
I2:7
I4:1
I1:2
I3:2
I3:2
I5:1
23
FP-growth properties
FP-growthtransforms the problem of finding long frequent patterns
to searching for shorter once recursively and concatenating the
suffix
It reduces the search cost
If the tree does not fit into main memory, partition the database
Efficient and scalable for mining both long and short frequent
patterns