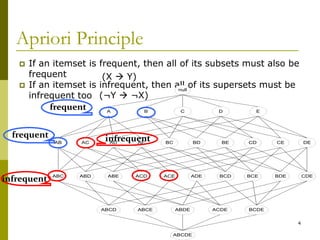
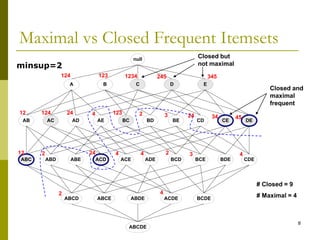
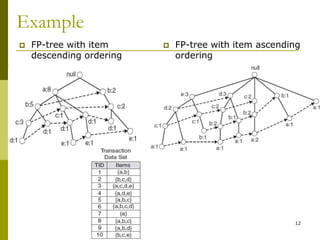
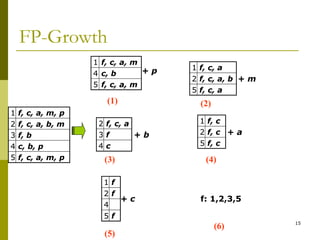
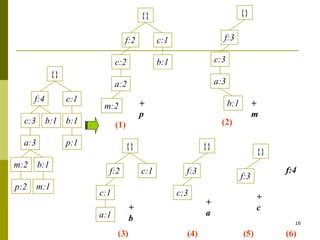
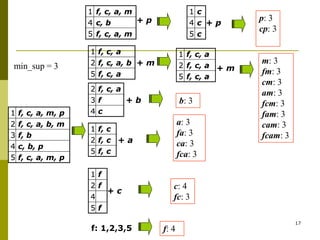
The document discusses frequent pattern mining and summarizes the Apriori and FP-growth algorithms. Apriori generates frequent itemsets in multiple passes over the data by joining candidate itemsets of length k with themselves. FP-growth avoids candidate generation by building a compact data structure called an FP-tree to store frequent patterns, then mining the tree. FP-growth is more efficient for sparse data as it avoids expensive support counting during candidate generation.