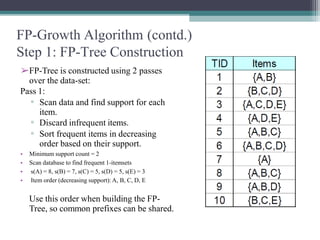
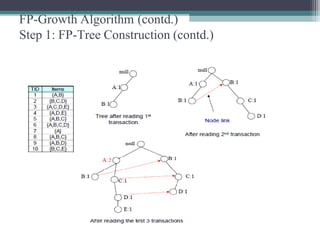
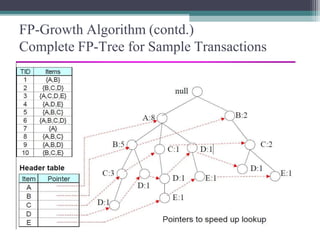
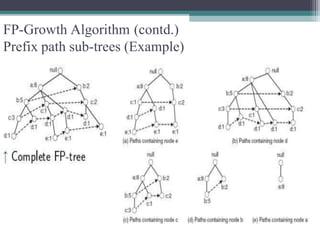
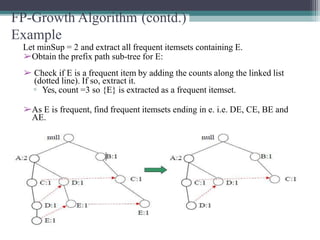
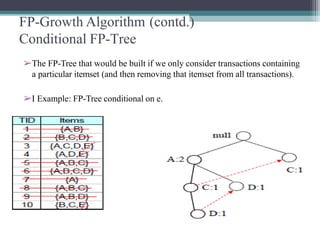
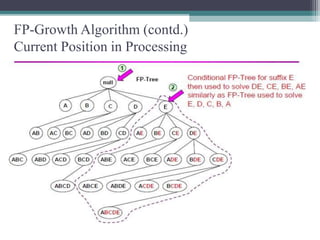
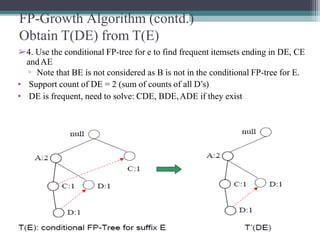
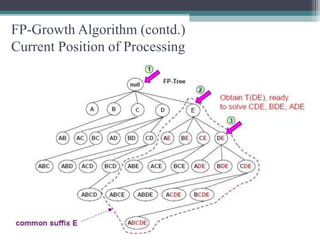
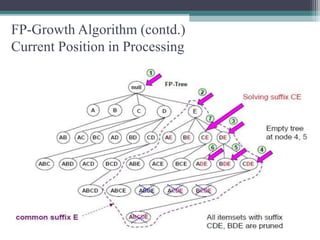
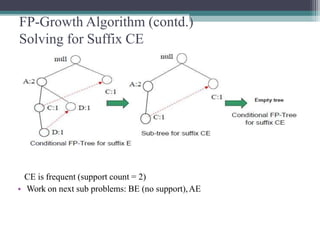
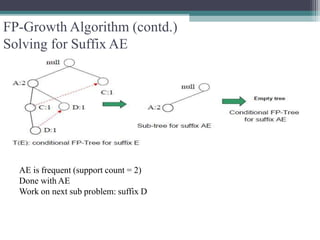
The FP-Growth algorithm allows for the efficient discovery of frequent itemsets without candidate generation. It uses a two-step approach: 1) building a compact FP-tree from transaction data, and 2) extracting frequent itemsets directly from the FP-tree. It proceeds by finding prefix path sub-trees in the FP-tree and recursively mining conditional frequent patterns.