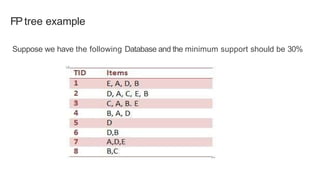
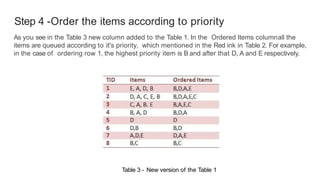
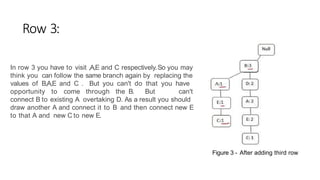
The FP-Growth algorithm is a method for finding frequent item sets without candidate generation by utilizing a data structure called the frequent-pattern tree (FP-tree). It works by compressing the input database, generating conditional databases based on frequent patterns, and then mining these databases separately. This approach improves performance while preserving essential transactional information and reducing irrelevant data.