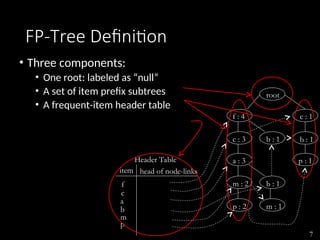
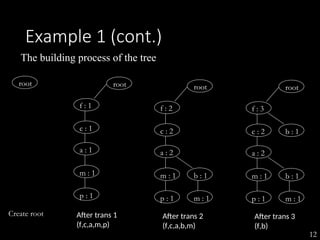
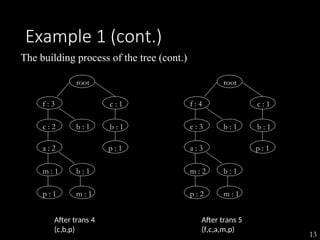
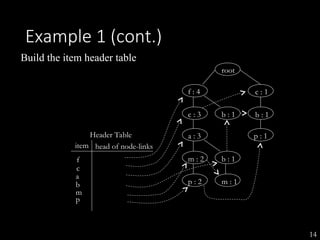
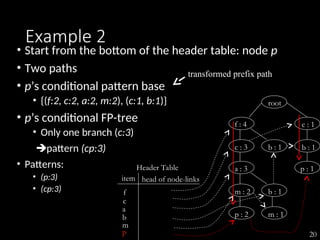
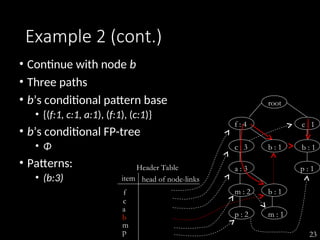
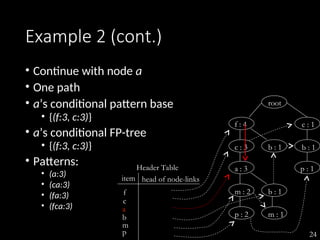
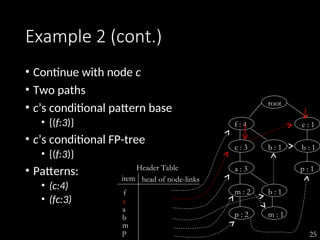
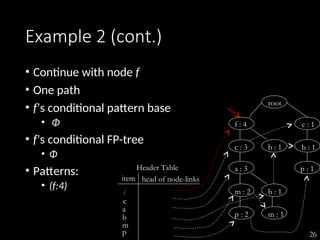
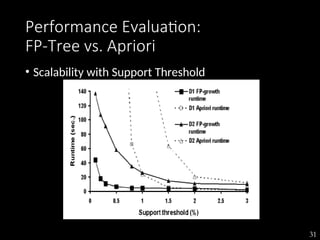
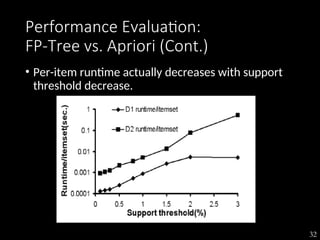
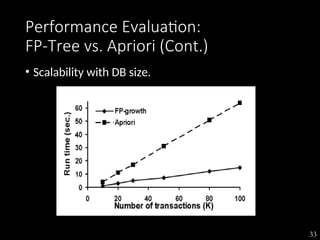
The document discusses the method of mining frequent patterns without candidate generation using the FP-tree and FP-growth algorithms. It outlines the construction of the FP-tree, examples of its application, and performance evaluations comparing it to the Apriori algorithm. Additionally, it emphasizes the advantages of FP-tree's compactness, completeness, and traversal efficiency for mining tasks.