【DL輪読会】Replacing Labeled Real-Image Datasets With Auto-Generated Contours
1.
1
DEEP LEARNING JP
[DLPapers]
http://deeplearning.jp/
Replacing Labeled Real-Image Datasets With Auto-
Generated Contours
Shunsuke Chiba(the university of Tokyo B3)
2.
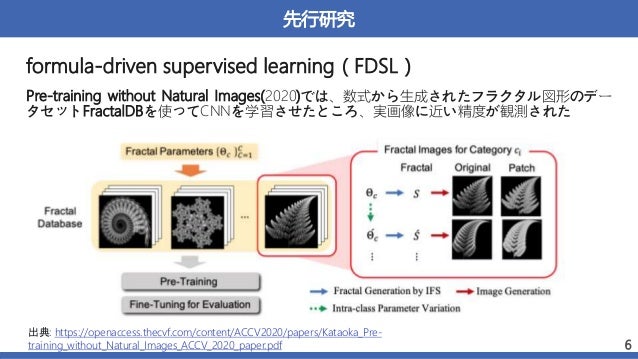
書誌情報
著者:Hirokatsu Kataoka, RyoHayamizu, Ryosuke Yamada, Kodai Nakashima,
Sora Takashima, Xinyu Zhang, Edgar Josafat Martinez-Noriega, Nakamasa Inoue,
Rio Yokota,Tsinghua University
2
タ イ ト ル : Replacing Labeled Real-Image Datasets With Auto-Generated
Contours
カンファレンス:CVPR 2022
※本資料で使用されている図や画像は特に言及がない限り、本論文または公式サイトからの引用です。
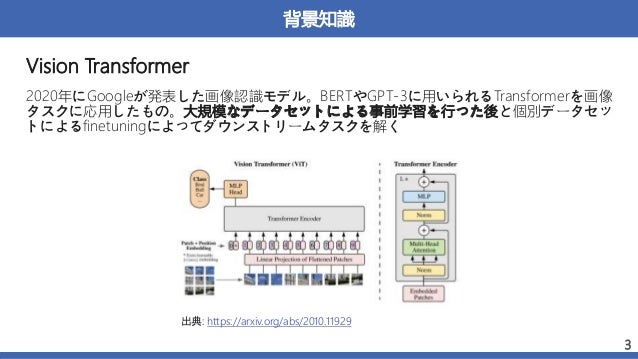
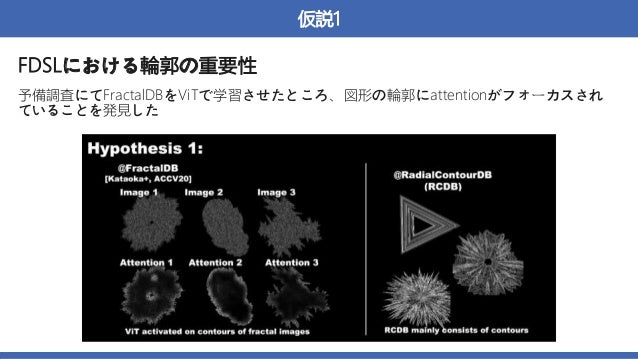
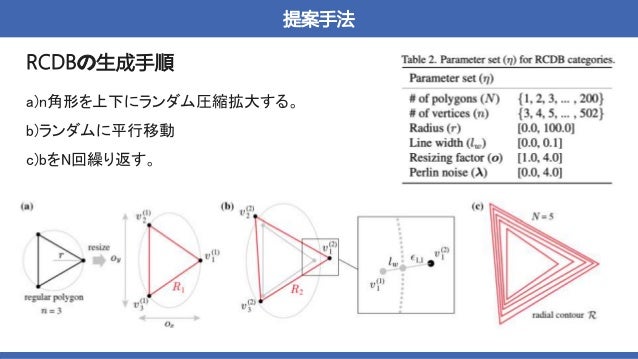
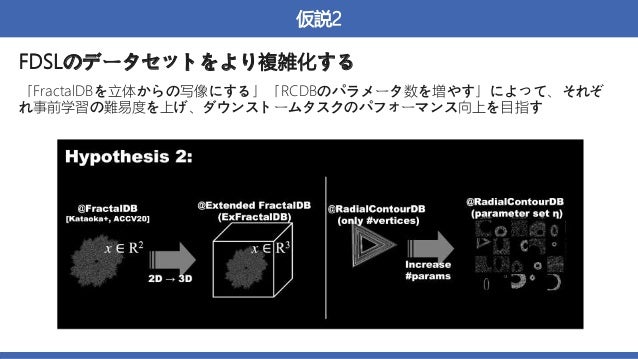
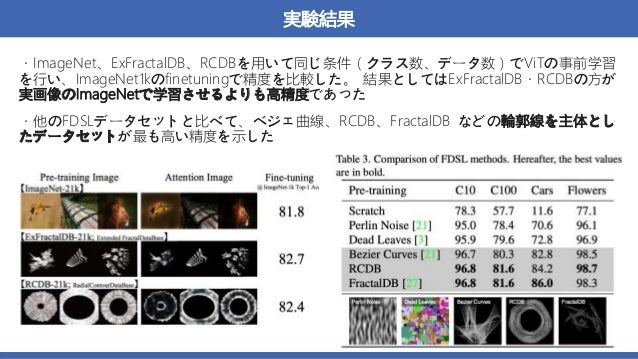
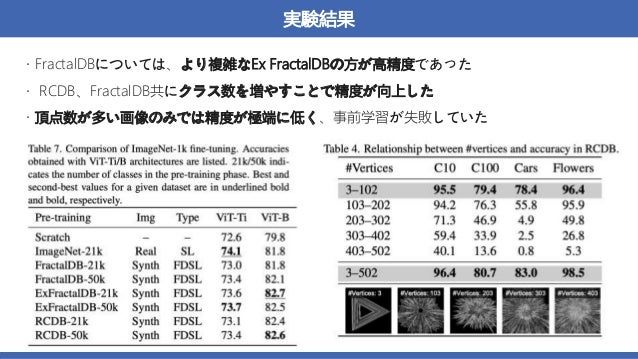
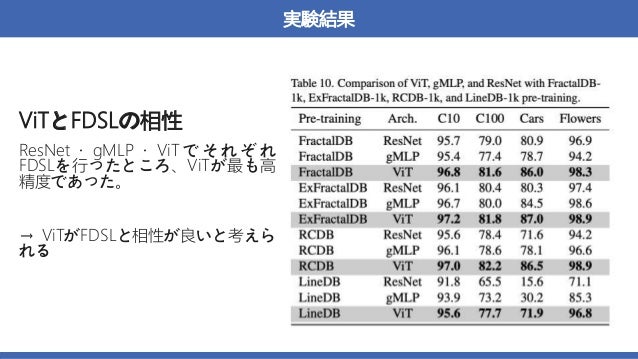
概要:数式から生成された画像を用いた、VisionTransformer(ViT)の事前学習
→実画像を用いて事前学習させた時と同等かそれ以上の精度を達成した
![1
DEEP LEARNING JP
[DL Papers]
http://deeplearning.jp/
Replacing Labeled Real-Image Datasets With Auto-
Generated Contours
Shunsuke Chiba(the university of Tokyo B3)](https://image.slidesharecdn.com/dlp220617chibashunsukev0-220617030537-f76841ee/95/DL-Replacing-Labeled-Real-Image-Datasets-With-Auto-Generated-Contours-1-638.jpg)







![[DL輪読会]data2vec: A General Framework for Self-supervised Learning in Speech,...](https://cdn.slidesharecdn.com/ss_thumbnails/220204nonakadl1-220204025334-thumbnail.jpg?width=640&height=640&fit=bounds)
![SSII2022 [SS2] 少ないデータやラベルを効率的に活用する機械学習技術 〜 足りない情報をどのように補うか?〜](https://cdn.slidesharecdn.com/ss_thumbnails/ss2ssii2022-220607054716-2760bd30-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DL輪読会]Graph R-CNN for Scene Graph Generation](https://cdn.slidesharecdn.com/ss_thumbnails/graphr-cnnforscenegraphgenerationkobayashi1130-181130001547-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]Temporal DifferenceVariationalAuto-Encoder](https://cdn.slidesharecdn.com/ss_thumbnails/20181130new-190205051636-thumbnail.jpg?width=640&height=640&fit=bounds)









![[DL輪読会]Focal Loss for Dense Object Detection](https://cdn.slidesharecdn.com/ss_thumbnails/focalloss-180208092846-thumbnail.jpg?width=640&height=640&fit=bounds)





![[DL輪読会]ICLR2020の分布外検知速報](https://cdn.slidesharecdn.com/ss_thumbnails/iclr2020ood-190927011524-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]Grokking: Generalization Beyond Overfitting on Small Algorithmic Datasets](https://cdn.slidesharecdn.com/ss_thumbnails/20220325okimura-220405024717-thumbnail.jpg?width=640&height=640&fit=bounds)












![[DL輪読会]BANMo: Building Animatable 3D Neural Models from Many Casual Videos](https://cdn.slidesharecdn.com/ss_thumbnails/banmo-220225035310-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]PointNet++: Deep Hierarchical Feature Learning on Point Sets in a Metr...](https://cdn.slidesharecdn.com/ss_thumbnails/181214dlpointnet-181214053349-thumbnail.jpg?width=640&height=640&fit=bounds)




![[DL輪読会]Deep Face Recognition: A Survey](https://cdn.slidesharecdn.com/ss_thumbnails/20181221-181221023935-thumbnail.jpg?width=640&height=640&fit=bounds)























