Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
Submit search
EN
KN
Uploaded by
Keigo Nishida
PDF, PPTX
24,272 views
Layer Normalization@NIPS+読み会・関西
Layer Normalization論文の紹介スライドです https://arxiv.org/abs/1607.06450 間違い等ありましたらご指摘いただけると嬉しいです
Technology
◦
Related topics:
Deep Learning
•
Read more
47
Save
Share
Embed
Embed presentation
Download
Download as PDF, PPTX
1
/ 44
2
/ 44
Most read
3
/ 44
4
/ 44
5
/ 44
6
/ 44
7
/ 44
8
/ 44
9
/ 44
10
/ 44
11
/ 44
12
/ 44
Most read
13
/ 44
14
/ 44
15
/ 44
16
/ 44
17
/ 44
18
/ 44
19
/ 44
20
/ 44
21
/ 44
22
/ 44
23
/ 44
24
/ 44
25
/ 44
26
/ 44
Most read
27
/ 44
28
/ 44
29
/ 44
30
/ 44
31
/ 44
32
/ 44
33
/ 44
34
/ 44
35
/ 44
36
/ 44
37
/ 44
38
/ 44
39
/ 44
40
/ 44
41
/ 44
42
/ 44
43
/ 44
44
/ 44
More Related Content
PPTX
[DL輪読会]Focal Loss for Dense Object Detection
by
Deep Learning JP
PPTX
【DL輪読会】Efficiently Modeling Long Sequences with Structured State Spaces
by
Deep Learning JP
PPTX
【DL輪読会】High-Resolution Image Synthesis with Latent Diffusion Models
by
Deep Learning JP
PDF
SSII2021 [OS2-01] 転移学習の基礎:異なるタスクの知識を利用するための機械学習の方法
by
SSII
PDF
ドメイン適応の原理と応用
by
Yoshitaka Ushiku
PDF
初めてのグラフカット
by
Tsubasa Hirakawa
PPTX
Curriculum Learning (関東CV勉強会)
by
Yoshitaka Ushiku
PPTX
[DL輪読会]ドメイン転移と不変表現に関するサーベイ
by
Deep Learning JP
[DL輪読会]Focal Loss for Dense Object Detection
by
Deep Learning JP
【DL輪読会】Efficiently Modeling Long Sequences with Structured State Spaces
by
Deep Learning JP
【DL輪読会】High-Resolution Image Synthesis with Latent Diffusion Models
by
Deep Learning JP
SSII2021 [OS2-01] 転移学習の基礎:異なるタスクの知識を利用するための機械学習の方法
by
SSII
ドメイン適応の原理と応用
by
Yoshitaka Ushiku
初めてのグラフカット
by
Tsubasa Hirakawa
Curriculum Learning (関東CV勉強会)
by
Yoshitaka Ushiku
[DL輪読会]ドメイン転移と不変表現に関するサーベイ
by
Deep Learning JP
What's hot
PPTX
深層学習の数理
by
Taiji Suzuki
PDF
深層生成モデルと世界モデル(2020/11/20版)
by
Masahiro Suzuki
PDF
[DL輪読会]Learning Transferable Visual Models From Natural Language Supervision
by
Deep Learning JP
PDF
自己教師学習(Self-Supervised Learning)
by
cvpaper. challenge
PPTX
[DL輪読会]NVAE: A Deep Hierarchical Variational Autoencoder
by
Deep Learning JP
PPTX
強化学習アルゴリズムPPOの解説と実験
by
克海 納谷
PPTX
深層学習の数理:カーネル法, スパース推定との接点
by
Taiji Suzuki
PDF
PRML学習者から入る深層生成モデル入門
by
tmtm otm
PDF
数学で解き明かす深層学習の原理
by
Taiji Suzuki
PDF
Active Learning 入門
by
Shuyo Nakatani
PPTX
画像認識と深層学習
by
Yusuke Uchida
PPTX
畳み込みニューラルネットワークの高精度化と高速化
by
Yusuke Uchida
PDF
最適輸送の解き方
by
joisino
PPTX
強化学習 DQNからPPOまで
by
harmonylab
PDF
【メタサーベイ】数式ドリブン教師あり学習
by
cvpaper. challenge
PPTX
【DL輪読会】時系列予測 Transfomers の精度向上手法
by
Deep Learning JP
PDF
モデルではなく、データセットを蒸留する
by
Takahiro Kubo
PPTX
SSII2020SS: グラフデータでも深層学習 〜 Graph Neural Networks 入門 〜
by
SSII
PDF
全力解説!Transformer
by
Arithmer Inc.
PDF
SSII2022 [SS2] 少ないデータやラベルを効率的に活用する機械学習技術 〜 足りない情報をどのように補うか?〜
by
SSII
深層学習の数理
by
Taiji Suzuki
深層生成モデルと世界モデル(2020/11/20版)
by
Masahiro Suzuki
[DL輪読会]Learning Transferable Visual Models From Natural Language Supervision
by
Deep Learning JP
自己教師学習(Self-Supervised Learning)
by
cvpaper. challenge
[DL輪読会]NVAE: A Deep Hierarchical Variational Autoencoder
by
Deep Learning JP
強化学習アルゴリズムPPOの解説と実験
by
克海 納谷
深層学習の数理:カーネル法, スパース推定との接点
by
Taiji Suzuki
PRML学習者から入る深層生成モデル入門
by
tmtm otm
数学で解き明かす深層学習の原理
by
Taiji Suzuki
Active Learning 入門
by
Shuyo Nakatani
画像認識と深層学習
by
Yusuke Uchida
畳み込みニューラルネットワークの高精度化と高速化
by
Yusuke Uchida
最適輸送の解き方
by
joisino
強化学習 DQNからPPOまで
by
harmonylab
【メタサーベイ】数式ドリブン教師あり学習
by
cvpaper. challenge
【DL輪読会】時系列予測 Transfomers の精度向上手法
by
Deep Learning JP
モデルではなく、データセットを蒸留する
by
Takahiro Kubo
SSII2020SS: グラフデータでも深層学習 〜 Graph Neural Networks 入門 〜
by
SSII
全力解説!Transformer
by
Arithmer Inc.
SSII2022 [SS2] 少ないデータやラベルを効率的に活用する機械学習技術 〜 足りない情報をどのように補うか?〜
by
SSII
Viewers also liked
PDF
行動計量シンポジウム20140321 http://lab.synergy-marketing.co.jp/activity/bsj_98th
by
Yoichi Motomura
PPTX
距離が付加された要素集合をコンパクトに表現できるDistance Bloom Filterの提案とP2Pネットワークにおける最短経路探索への応用
by
Kota Abe
PDF
ベイジアンネット技術とサービス工学におけるビッグデータ活用技術
by
Yoichi Motomura
PPTX
ニューラル・ネットワークと技術革新の展望
by
maruyama097
KEY
次数制限モデルにおける全てのCSPに対する最適な定数時間近似アルゴリズムと近似困難性
by
Yuichi Yoshida
PDF
Statistical Semantic入門 ~分布仮説からword2vecまで~
by
Yuya Unno
PDF
Convolutional Neural Netwoks で自然言語処理をする
by
Daiki Shimada
PPTX
Greed is Good: 劣モジュラ関数最大化とその発展
by
Yuichi Yoshida
行動計量シンポジウム20140321 http://lab.synergy-marketing.co.jp/activity/bsj_98th
by
Yoichi Motomura
距離が付加された要素集合をコンパクトに表現できるDistance Bloom Filterの提案とP2Pネットワークにおける最短経路探索への応用
by
Kota Abe
ベイジアンネット技術とサービス工学におけるビッグデータ活用技術
by
Yoichi Motomura
ニューラル・ネットワークと技術革新の展望
by
maruyama097
次数制限モデルにおける全てのCSPに対する最適な定数時間近似アルゴリズムと近似困難性
by
Yuichi Yoshida
Statistical Semantic入門 ~分布仮説からword2vecまで~
by
Yuya Unno
Convolutional Neural Netwoks で自然言語処理をする
by
Daiki Shimada
Greed is Good: 劣モジュラ関数最大化とその発展
by
Yuichi Yoshida
Similar to Layer Normalization@NIPS+読み会・関西
PPTX
Group normalization
by
Ryutaro Yamauchi
PPTX
全体セミナー20180124 final
by
Jiro Nishitoba
PDF
SSII2019TS: Shall We GANs? ~GANの基礎から最近の研究まで~
by
SSII
PDF
[DL輪読会] Spectral Norm Regularization for Improving the Generalizability of De...
by
Deep Learning JP
PDF
Batch normalization effectiveness_20190206
by
Masakazu Shinoda
PPTX
[DL輪読会]Batch Renormalization: Towards Reducing Minibatch Dependence in Batch-...
by
Deep Learning JP
PDF
SSII2019TS: Shall We GANs? ~GANの基礎から最近の研究まで~
by
SSII
PDF
Casual learning machine learning with_excel_no5
by
KazuhiroSato8
PDF
Deep learning入門
by
magoroku Yamamoto
PPTX
機械学習 / Deep Learning 大全 (2) Deep Learning 基礎編
by
Daiyu Hatakeyama
PDF
SGD+α: 確率的勾配降下法の現在と未来
by
Hidekazu Oiwa
PPTX
Image net classification with Deep Convolutional Neural Networks
by
Shingo Horiuchi
PPTX
Large scale gan training for high fidelity natural
by
KCS Keio Computer Society
PPTX
Bayesian Uncertainty Estimation for Batch Normalized Deep Networks
by
harmonylab
PDF
[DL輪読会]Learning to Simulate Complex Physics with Graph Networks
by
Deep Learning JP
PDF
20170422 数学カフェ Part1
by
Kenta Oono
PDF
Building High-level Features Using Large Scale Unsupervised Learning
by
Takuya Minagawa
PPT
Deep Learningの技術と未来
by
Seiya Tokui
PDF
[DL Hacks] Deterministic Variational Inference for RobustBayesian Neural Netw...
by
Deep Learning JP
PDF
20140726.西野研セミナー
by
Hayaru SHOUNO
Group normalization
by
Ryutaro Yamauchi
全体セミナー20180124 final
by
Jiro Nishitoba
SSII2019TS: Shall We GANs? ~GANの基礎から最近の研究まで~
by
SSII
[DL輪読会] Spectral Norm Regularization for Improving the Generalizability of De...
by
Deep Learning JP
Batch normalization effectiveness_20190206
by
Masakazu Shinoda
[DL輪読会]Batch Renormalization: Towards Reducing Minibatch Dependence in Batch-...
by
Deep Learning JP
SSII2019TS: Shall We GANs? ~GANの基礎から最近の研究まで~
by
SSII
Casual learning machine learning with_excel_no5
by
KazuhiroSato8
Deep learning入門
by
magoroku Yamamoto
機械学習 / Deep Learning 大全 (2) Deep Learning 基礎編
by
Daiyu Hatakeyama
SGD+α: 確率的勾配降下法の現在と未来
by
Hidekazu Oiwa
Image net classification with Deep Convolutional Neural Networks
by
Shingo Horiuchi
Large scale gan training for high fidelity natural
by
KCS Keio Computer Society
Bayesian Uncertainty Estimation for Batch Normalized Deep Networks
by
harmonylab
[DL輪読会]Learning to Simulate Complex Physics with Graph Networks
by
Deep Learning JP
20170422 数学カフェ Part1
by
Kenta Oono
Building High-level Features Using Large Scale Unsupervised Learning
by
Takuya Minagawa
Deep Learningの技術と未来
by
Seiya Tokui
[DL Hacks] Deterministic Variational Inference for RobustBayesian Neural Netw...
by
Deep Learning JP
20140726.西野研セミナー
by
Hayaru SHOUNO
Layer Normalization@NIPS+読み会・関西
1.
Layer Normalization Jimmy Lei
Ba Jamie Ryan Kiros Geoffrey E.Hinton 紹介者:西田 圭吾 阪大 生命機能 M1 第2回「NIPS+読み会・関西」
2.
• 西田 圭吾 •
大阪大学 生命機能研究科 M1 • 理研QBiC 計算分子設計研究グループ(泰地研) 研修生 • 科学技術計算専用チップ設計 • 学部時代は細胞のイメージングとか、半導体メモリの結晶評価とか 自己紹介 例)分子動力学計算専用計算機 MDGRAPE-4
3.
• 自己紹介 • Layer
Normalization 論文概要 • 背景 • Batch Normalization • Weight Normalization • Layer Normalization • 以上3つの比較 目次
4.
• 目的 State-of-the-artなDNNの学習時間を短縮したい 中間層の出力を正規化することで実現させる • アイデア Batch
Normalizationを作り変えてみた 1. バッチサイズに依存しない(オンライン学習や小さなミニバッチOK) 2. 学習とテストの計算方法が同一 3. そのままRNNに適応可能 • その他関連研究との比較 Layer Normalization 概要
5.
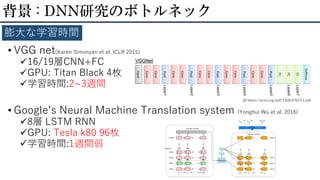
• VGG net(Karen
Simonyan et al. ICLR 2015) 16/19層CNN+FC GPU: Titan Black 4枚 学習時間:2~3週間 • Google’s Neural Machine Translation system (Yonghui Wu et al. 2016) 8層 LSTM RNN GPU: Tesla k80 96枚 学習時間:1週間弱 背景 : DNN研究のボトルネック 膨大な学習時間 図 https://arxiv.org/pdf/1509.07627v1.pdf
6.
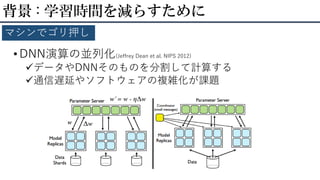
• DNN演算の並列化(Jeffrey Dean
et al. NIPS 2012) データやDNNそのものを分割して計算する 通信遅延やソフトウェアの複雑化が課題 背景 : 学習時間を減らすために マシンでゴリ押し
7.
• 勾配法そのものを改良する 2次微分を扱うものになると計算コスト膨大 背景 :
学習時間を減らすために 学習の効率を上げる
8.
• パラメータ空間幾何を修正する Batch Normalization(Sergey
Ioffe et al. NIPS 2015)が学習時間の削減に 成功 勾配消失の問題が解決(飽和活性化関数も利用可能に) 背景 : 学習時間を減らすために 学習の効率を上げる
9.
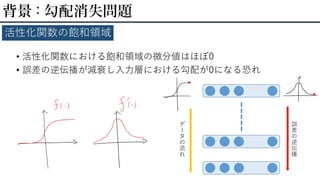
• 活性化関数における飽和領域の微分値はほぼ0 • 誤差の逆伝播が減衰し入力層における勾配が0になる恐れ 背景
: 勾配消失問題 活性化関数の飽和領域 デ ー タ の 流 れ 誤 差 の 逆 伝 播
10.
• 飽和領域をなくす ReLU(x) =
max(x,0) • 初期化の工夫 • 小さな学習率の利用 学習によって飽和領域に行くことを防ぐ 背景 : 勾配消失問題 解決策 学習に時間がかかる 原因の一つ Q. そもそもなぜ、DNNは最適化してるのに飽和状態へネットワークが陥るのか A. 学習するごとに各層の出力分布が変わる(internal) covariate shiftが生じるから
11.
• 共変量シフトが起きる場合の学習はドメイン学習としてよく扱われる • 論文ではDNNの各層ごとに起きる共変量シフトについて考察 背景
: covariate shift (共変量シフト) 訓練時とテスト時の入力分布の変化 入出力規則(与えられた入力に対する出力の生成規則)は訓練時と テスト時で変わらないが,入力(共変量)の分布が訓練時とテスト時 で異なるという状況は共変量シフトと呼ばれている 共変量シフト下での教師付き学習 杉山 将 日本神経回路学会誌, vol.13, no3, pp.111-118, 2006
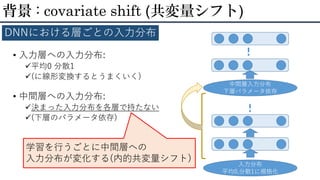
12.
• 入力層への入力分布: 平均0 分散1 (に線形変換するとうまくいく) •
中間層への入力分布: 決まった入力分布を各層で持たない (下層のパラメータ依存) 背景 : covariate shift (共変量シフト) DNNにおける層ごとの入力分布 入力分布 平均0,分散1に規格化 中間層入力分布 下層パラメータ依存 学習を行うごとに中間層への 入力分布が変化する(内的共変量シフト)
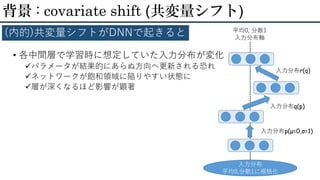
13.
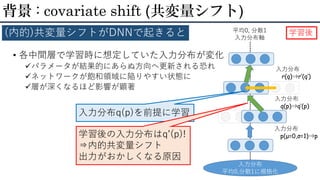
• 各中間層で学習時に想定していた入力分布が変化 パラメータが結果的にあらぬ方向へ更新される恐れ ネットワークが飽和領域に陥りやすい状態に 層が深くなるほど影響が顕著 背景 :
covariate shift (共変量シフト) (内的)共変量シフトがDNNで起きると 入力分布 平均0,分散1に規格化 平均0, 分散1 入力分布軸 入力分布p(μ=0,σ=1) 入力分布q(p) 入力分布r(q)
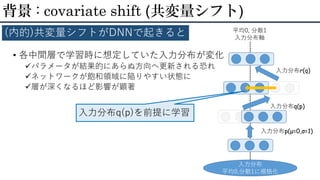
14.
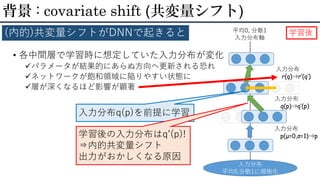
• 各中間層で学習時に想定していた入力分布が変化 パラメータが結果的にあらぬ方向へ更新される恐れ ネットワークが飽和領域に陥りやすい状態に 層が深くなるほど影響が顕著 背景 :
covariate shift (共変量シフト) (内的)共変量シフトがDNNで起きると 入力分布 平均0,分散1に規格化 平均0, 分散1 入力分布軸 入力分布q(p) 入力分布r(q) 入力分布q(p)を前提に学習 入力分布p(μ=0,σ=1)
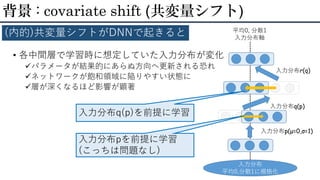
15.
• 各中間層で学習時に想定していた入力分布が変化 パラメータが結果的にあらぬ方向へ更新される恐れ ネットワークが飽和領域に陥りやすい状態に 層が深くなるほど影響が顕著 背景 :
covariate shift (共変量シフト) (内的)共変量シフトがDNNで起きると 入力分布 平均0,分散1に規格化 平均0, 分散1 入力分布軸 入力分布q(p) 入力分布r(q) 入力分布p(μ=0,σ=1) 入力分布q(p)を前提に学習 入力分布pを前提に学習 (こっちは問題なし)
16.
• 各中間層で学習時に想定していた入力分布が変化 パラメータが結果的にあらぬ方向へ更新される恐れ ネットワークが飽和領域に陥りやすい状態に 層が深くなるほど影響が顕著 背景 :
covariate shift (共変量シフト) (内的)共変量シフトがDNNで起きると 入力分布 平均0,分散1に規格化 平均0, 分散1 入力分布軸 入力分布 q(p)⇒q’(p) 入力分布 r(q)⇒r’(q’) 学習後 入力分布 p(μ=0,σ=1)⇒p 入力分布q(p)を前提に学習 学習後の入力分布はq’(p)! ⇒内的共変量シフト 出力がおかしくなる原因
17.
• 各中間層で学習時に想定していた入力分布が変化 パラメータが結果的にあらぬ方向へ更新される恐れ ネットワークが飽和領域に陥りやすい状態に 層が深くなるほど影響が顕著 背景 :
covariate shift (共変量シフト) (内的)共変量シフトがDNNで起きると 入力分布 平均0,分散1に規格化 平均0, 分散1 入力分布軸 入力分布 q(p)⇒q’(p) 入力分布 r(q)⇒r’(q’) 学習後 入力分布 p(μ=0,σ=1)⇒p 入力分布q(p)を前提に学習 学習後の入力分布はq’(p)! ⇒内的共変量シフト 出力がおかしくなる原因
18.
• 各中間層で出力を正規化する 各中間層の入力分布を一定に 大きな学習率の利用が可能 学習の効率を改善させる • 様々なアプローチ Batch
Normalization(Sergey Ioffe et al. NIPS 2015) Weight Normalization(Tim Salimans et al. NIPS 2016) Layer Normalization(Jimmy Lei Ba et al. NIPS 2016) 背景 : 隠れユニットの正規化 正規化層の導入 入力分布 平均0,分散1に規格化 平均0, 分散1 入力分布軸 norm norm norm
19.
Batch Normalization
20.
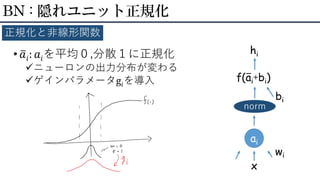
• ニューロンへの入力和: 𝑎𝑖 •
𝑎𝑖 = 𝑤𝑖 𝑇 𝑥 • ニューロンの出力: ℎ𝑖 • ℎ𝑖 = 𝑓(𝑎𝑖 + 𝑏𝑖) BN : 隠れユニット正規化 ニューロンの基本形 ai x wi f(ai+bi) bi hi
21.
• ത𝑎𝑖: 𝑎𝑖を平均0,分散1に正規化 ニューロンの出力分布が変わる ゲインパラメータg𝑖を導入 BN
: 隠れユニット正規化 正規化と非線形関数 ai x wi f(ai+bi) norm bi hi ー
22.
• 各ニューロンのバッチごとに計算 • ത𝑎𝑖
= g𝑖 σ𝑖 (𝑎𝑖 − μ𝑖) • μ𝑖 = 𝐸[𝑎𝑖], σ𝑖 = 𝐸 𝑎𝑖 − μ𝑖 2 BN : 隠れユニット正規化 Batch Normalization ai x wi f(ai+bi) norm bi hi ー ai batch size
23.
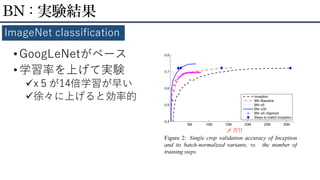
• GoogLeNetがベース • 学習率を上げて実験 x5が14倍学習が早い 徐々に上げると効率的 BN
: 実験結果 ImageNet classification メガ!!
24.
• 学習率を上げると重みのスケールが大きくなる 逆誤差伝播で誤差が発散する原因 • BNはそのスケールを正規化して発散を防ぐ BN
: うまくいった理由 BNによる重みのスケール補正 𝐵𝑁 𝑊𝑢 = 𝐵𝑁 𝑎𝑊 𝑢 スケール(𝑎倍)しても出力は等価 𝜕𝐵𝑁 𝑎𝑊 𝑢 𝜕𝑢 = 𝜕𝐵𝑁 𝑊𝑢 𝜕𝑢 ヤコビも等価 𝜕𝐵𝑁 𝑎𝑊 𝑢 𝜕(𝑎𝑊) = 1 𝑎 · 𝜕𝐵𝑁 𝑊𝑢 𝜕𝑊 勾配は1/𝑎倍(程よく収束)
25.
Weight Normalization
26.
•重みを正規化 • ミニバッチのサンプル間の依存関係は無し • オンライン学習やRNNに拡張可能 •CNNのように重みの数が小さいものに対して計算が軽い •
データ依存重み初期化が活用できる •大まかにはBNの低コストな近似計算 • 比較に使うための紹介程度です WN : まとめ Weight Normalization
27.
• 各ニューロンの出力から重みを正規化 • 𝒕
= 𝒘 𝑇 𝒙 + 𝑏 • μ = 𝐸 𝒕 , σ = 𝐸 𝒕 − μ 2 • ഥ𝒘 ← 1 σ 𝒘, ത𝑏 ← 𝑏−μ σ • 𝒉 = f( 𝑡−μ σ ) = f(ഥ𝒘 𝑇 𝒙 + ത𝑏) WN : 隠れユニット正規化 Weight Normalization a x w f( ) norm b h wTx+b --
28.
Layer Normalization
29.
•同じ層のニューロン間で正規化 •ミニバッチのサンプル間の依存関係は無し •オンライン学習やRNNに拡張可能 •CNNはBatch Normより上手くいかない場合が... LN :
まとめ Layer Normalization
30.
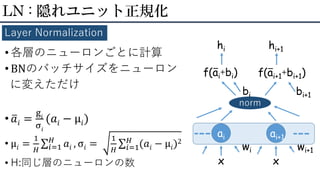
• 各層のニューロンごとに計算 • BNのバッチサイズをニューロン に変えただけ •
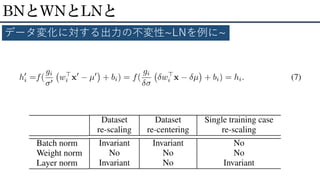
ത𝑎𝑖 = g𝑖 σ𝑖 (𝑎𝑖 − μ𝑖) • μ𝑖 = 1 𝐻 σ𝑖=1 𝐻 𝑎𝑖 , σ𝑖 = 1 𝐻 σ𝑖=1 𝐻 (𝑎𝑖 − μ𝑖)2 • H:同じ層のニューロンの数 LN : 隠れユニット正規化 Layer Normalization ai x wi f(ai+bi) norm bi hi ー x wi+1 f(ai+1+bi+1) bi+1 hi+1 ー ai+1
31.
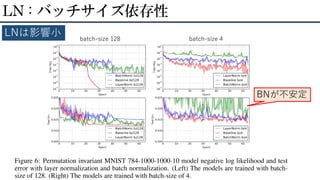
LN : バッチサイズ依存性 LNは影響小
batch-size 128 batch-size 4 BNが不安定
32.
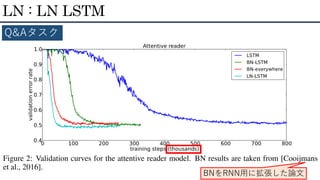
LN : LN
LSTM Q&Aタスク BNをRNN用に拡張した論文
33.
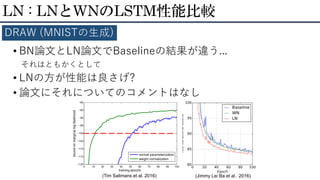
• BN論文とLN論文でBaselineの結果が違う... それはともかくとして • LNの方が性能は良さげ? •
論文にそれについてのコメントはなし LN : LNとWNのLSTM性能比較 DRAW (MNISTの生成) (Tim Salimans et al. 2016) (Jimmy Lei Ba et al. 2016)
34.
BNとWNとLNと 何が違うのか • それぞれ出力を正規化している 正規化の性質は? • 重みやデータに定数倍やバイアス加えてみる 出力が不変かどうかで性質をとらえる •
学習はどのように進むのか 多様体構造の曲率をフィッシャー情報量から暗黙にとらえる norm norm norm
35.
BNとWNとLNと 重み変化に対する出力の不変性~LNを例に~
36.
BNとWNとLNと データ変化に対する出力の不変性~LNを例に~
37.
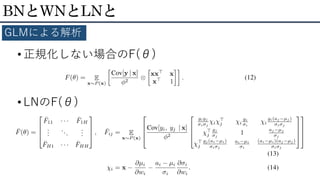
BNとWNとLNと 学習の進み方は? • 学習は多様体の周りを動くものととらえれば、その曲 率はFisher情報量行列によって暗黙的にとらえられる 曲率の2次形式ds2をFisher情報量行列で近似 ネットワークのモデルは一般化線形モデル(GLM)で近似 • 結論 LNの正規化パラメータσは学習が進むにつれて大きくなる と学習率を下げて学習を安定化させる働きがある
38.
BNとWNとLNと GLMによる解析準備 • Generalized Linear
Model (GLM)による近似 • F(θ)に注目する
39.
BNとWNとLNと GLMによる解析 • 正規化しない場合のF(θ) • LNのF(θ)
40.
BNとWNとLNと GLMによる解析 • 正規化しない場合のF(θ) • LNのF(θ) 曲率が入力データの大きさに依存 入力データの大きさは反映されにくい (正規化されているので)
41.
BNとWNとLNと GLMによる解析 • 正規化しない場合のF(θ) • LNのF(θ) wi方向:
wiが2倍→σiもおよそ2倍 ⇒ wi方向の曲率は1/2に ⇒学習率の低下と捉えられる(らしい)
42.
BNとWNとLNと • 入力の大きさに影響を受けない(BN)受けにくい(LN) ゲインの更新は予測誤差程度の大きさ ゲインによる比較~BN,LN~ 出力を決める大事なパラメータでした 正規化されている
43.
BNとWNとLNと ゲインによる比較~WN~ 出力を決める大事なパラメータでした • 入力の大きさに影響を受ける(WN) ゲインの更新は予測誤差程度の大きさと入力(ai)の大きさに依存する BNやLNに比べて学習が安定しにくい可能性あり
44.
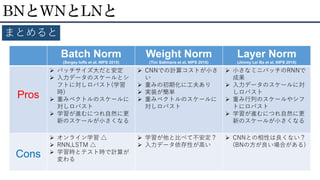
BNとWNとLNと まとめると Batch Norm (Sergey Ioffe
et al. NIPS 2015) Weight Norm (Tim Salimans et al. NIPS 2016) Layer Norm (Jimmy Lei Ba et al. NIPS 2016) Pros バッチサイズ大だと安定 入力データのスケールとシ フトに対しロバスト(学習 時) 重みベクトルのスケールに 対しロバスト 学習が進むにつれ自然に更 新のスケールが小さくなる CNNでの計算コストが小さ い 重みの初期化に工夫あり 実装が簡単 重みベクトルのスケールに 対しロバスト 小さなミニバッチのRNNで 成果 入力データのスケールに対 しロバスト 重み行列のスケールやシフ トにロバスト 学習が進むにつれ自然に更 新のスケールが小さくなる Cons オンライン学習 △ RNN,LSTM △ 学習時とテスト時で計算が 変わる 学習が他と比べて不安定? 入力データ依存性が高い CNNとの相性は良くない? (BNの方が良い場合がある)
Download










![• 各ニューロンのバッチごとに計算
• ത𝑎𝑖 =
g𝑖
σ𝑖
(𝑎𝑖 − μ𝑖)
• μ𝑖 = 𝐸[𝑎𝑖], σ𝑖 = 𝐸 𝑎𝑖 − μ𝑖
2
BN : 隠れユニット正規化
Batch Normalization
ai
x
wi
f(ai+bi)
norm
bi
hi
ー
ai
batch size](https://image.slidesharecdn.com/nipsyomi2nishida-161227102930/85/Layer-Normalization-NIPS-22-320.jpg)














![[DL輪読会]Focal Loss for Dense Object Detection](https://cdn.slidesharecdn.com/ss_thumbnails/focalloss-180208092846-thumbnail.jpg?width=640&height=640&fit=bounds)


![SSII2021 [OS2-01] 転移学習の基礎:異なるタスクの知識を利用するための機械学習の方法](https://cdn.slidesharecdn.com/ss_thumbnails/os2-02final-210610091211-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DL輪読会]ドメイン転移と不変表現に関するサーベイ](https://cdn.slidesharecdn.com/ss_thumbnails/20190614iwasawa-190614005939-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DL輪読会]Learning Transferable Visual Models From Natural Language Supervision](https://cdn.slidesharecdn.com/ss_thumbnails/dlkobayashi0115-210115012308-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]NVAE: A Deep Hierarchical Variational Autoencoder](https://cdn.slidesharecdn.com/ss_thumbnails/nvaeadeephierarchicalvariationalautoencoder-201113004930-thumbnail.jpg?width=640&height=640&fit=bounds)














![SSII2022 [SS2] 少ないデータやラベルを効率的に活用する機械学習技術 〜 足りない情報をどのように補うか?〜](https://cdn.slidesharecdn.com/ss_thumbnails/ss2ssii2022-220607054716-2760bd30-thumbnail.jpg?width=640&height=640&fit=bounds)











![[DL輪読会] Spectral Norm Regularization for Improving the Generalizability of De...](https://cdn.slidesharecdn.com/ss_thumbnails/dlhackspectralnorm1-170907072536-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]Batch Renormalization: Towards Reducing Minibatch Dependence in Batch-...](https://cdn.slidesharecdn.com/ss_thumbnails/dlu8f2au8aadu4f1av2-170407001546-thumbnail.jpg?width=640&height=640&fit=bounds)








![[DL輪読会]Learning to Simulate Complex Physics with Graph Networks](https://cdn.slidesharecdn.com/ss_thumbnails/learningtosimulatecomplexphysicswithgraphnetworks-200508054213-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DL Hacks] Deterministic Variational Inference for RobustBayesian Neural Netw...](https://cdn.slidesharecdn.com/ss_thumbnails/adobepdffile2-190628001736-thumbnail.jpg?width=640&height=640&fit=bounds)
