Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
EN
Uploaded by
Deep Learning JP
PPTX, PDF
4,531 views
[DL輪読会]Grokking: Generalization Beyond Overfitting on Small Algorithmic Datasets
2022/03/25 Deep Learning JP: http://deeplearning.jp/seminar-2/
Technology
◦
Related topics:
Deep Learning
•
Read more
1
Save
Share
Embed
Embed presentation
Download
Downloaded 75 times
1
/ 17
2
/ 17
3
/ 17
4
/ 17
Most read
5
/ 17
6
/ 17
7
/ 17
8
/ 17
Most read
9
/ 17
Most read
10
/ 17
11
/ 17
12
/ 17
13
/ 17
14
/ 17
15
/ 17
16
/ 17
17
/ 17
More Related Content
PDF
深層生成モデルと世界モデル(2020/11/20版)
by
Masahiro Suzuki
PPTX
[DL輪読会]相互情報量最大化による表現学習
by
Deep Learning JP
PPTX
【DL輪読会】Scaling Laws for Neural Language Models
by
Deep Learning JP
PPTX
【DL輪読会】DayDreamer: World Models for Physical Robot Learning
by
Deep Learning JP
PPTX
[DL輪読会]Dream to Control: Learning Behaviors by Latent Imagination
by
Deep Learning JP
PPTX
[DL輪読会]Learning Latent Dynamics for Planning from Pixels
by
Deep Learning JP
PDF
【DL輪読会】"Secrets of RLHF in Large Language Models Part I: PPO"
by
Deep Learning JP
PPTX
【DL輪読会】ViT + Self Supervised Learningまとめ
by
Deep Learning JP
深層生成モデルと世界モデル(2020/11/20版)
by
Masahiro Suzuki
[DL輪読会]相互情報量最大化による表現学習
by
Deep Learning JP
【DL輪読会】Scaling Laws for Neural Language Models
by
Deep Learning JP
【DL輪読会】DayDreamer: World Models for Physical Robot Learning
by
Deep Learning JP
[DL輪読会]Dream to Control: Learning Behaviors by Latent Imagination
by
Deep Learning JP
[DL輪読会]Learning Latent Dynamics for Planning from Pixels
by
Deep Learning JP
【DL輪読会】"Secrets of RLHF in Large Language Models Part I: PPO"
by
Deep Learning JP
【DL輪読会】ViT + Self Supervised Learningまとめ
by
Deep Learning JP
What's hot
PPTX
モデルアーキテクチャ観点からの高速化2019
by
Yusuke Uchida
PDF
画像生成・生成モデル メタサーベイ
by
cvpaper. challenge
PPTX
モデル高速化百選
by
Yusuke Uchida
PDF
最適輸送入門
by
joisino
PPTX
SSII2020SS: グラフデータでも深層学習 〜 Graph Neural Networks 入門 〜
by
SSII
PDF
ブラックボックス最適化とその応用
by
gree_tech
PPTX
【論文紹介】How Powerful are Graph Neural Networks?
by
Masanao Ochi
PDF
Transformerを多層にする際の勾配消失問題と解決法について
by
Sho Takase
PPTX
Swin Transformer (ICCV'21 Best Paper) を完璧に理解する資料
by
Yusuke Uchida
PDF
ELBO型VAEのダメなところ
by
KCS Keio Computer Society
PDF
【DL輪読会】How Much Can CLIP Benefit Vision-and-Language Tasks?
by
Deep Learning JP
PPTX
【DL輪読会】Efficiently Modeling Long Sequences with Structured State Spaces
by
Deep Learning JP
PDF
機械学習のためのベイズ最適化入門
by
hoxo_m
PDF
最適化超入門
by
Takami Sato
PPTX
【DL輪読会】High-Resolution Image Synthesis with Latent Diffusion Models
by
Deep Learning JP
PPTX
Curriculum Learning (関東CV勉強会)
by
Yoshitaka Ushiku
PPTX
[DL輪読会]Pay Attention to MLPs (gMLP)
by
Deep Learning JP
PDF
3D CNNによる人物行動認識の動向
by
Kensho Hara
PDF
【メタサーベイ】数式ドリブン教師あり学習
by
cvpaper. challenge
PDF
Optunaを使ったHuman-in-the-loop最適化の紹介 - 2023/04/27 W&B 東京ミートアップ #3
by
Preferred Networks
モデルアーキテクチャ観点からの高速化2019
by
Yusuke Uchida
画像生成・生成モデル メタサーベイ
by
cvpaper. challenge
モデル高速化百選
by
Yusuke Uchida
最適輸送入門
by
joisino
SSII2020SS: グラフデータでも深層学習 〜 Graph Neural Networks 入門 〜
by
SSII
ブラックボックス最適化とその応用
by
gree_tech
【論文紹介】How Powerful are Graph Neural Networks?
by
Masanao Ochi
Transformerを多層にする際の勾配消失問題と解決法について
by
Sho Takase
Swin Transformer (ICCV'21 Best Paper) を完璧に理解する資料
by
Yusuke Uchida
ELBO型VAEのダメなところ
by
KCS Keio Computer Society
【DL輪読会】How Much Can CLIP Benefit Vision-and-Language Tasks?
by
Deep Learning JP
【DL輪読会】Efficiently Modeling Long Sequences with Structured State Spaces
by
Deep Learning JP
機械学習のためのベイズ最適化入門
by
hoxo_m
最適化超入門
by
Takami Sato
【DL輪読会】High-Resolution Image Synthesis with Latent Diffusion Models
by
Deep Learning JP
Curriculum Learning (関東CV勉強会)
by
Yoshitaka Ushiku
[DL輪読会]Pay Attention to MLPs (gMLP)
by
Deep Learning JP
3D CNNによる人物行動認識の動向
by
Kensho Hara
【メタサーベイ】数式ドリブン教師あり学習
by
cvpaper. challenge
Optunaを使ったHuman-in-the-loop最適化の紹介 - 2023/04/27 W&B 東京ミートアップ #3
by
Preferred Networks
Similar to [DL輪読会]Grokking: Generalization Beyond Overfitting on Small Algorithmic Datasets
PPTX
Explanation of the mysterious phenomenon in deep learning models: Grokking.
by
satoyuta0112
PDF
[DL輪読会]A Bayesian Perspective on Generalization and Stochastic Gradient Descent
by
Deep Learning JP
PDF
東大大学院 電子情報学特論講義資料「深層学習概論と理論解析の課題」大野健太
by
Preferred Networks
PPTX
[DL輪読会]Understanding deep learning requires rethinking generalization
by
Deep Learning JP
PPTX
[DL輪読会]Learning to Adapt: Meta-Learning for Model-Based Control
by
Deep Learning JP
PDF
PRML s1
by
eizoo3010
PDF
強化学習その2
by
nishio
PDF
ディープラーニング入門 ~ 画像処理・自然言語処理について ~
by
Kensuke Otsuki
PPTX
ノンパラメトリックベイズを用いた逆強化学習
by
Shota Ishikawa
PPTX
MASTERING ATARI WITH DISCRETE WORLD MODELS (DreamerV2)
by
harmonylab
PPTX
海鳥の経路予測のための逆強化学習
by
Tsubasa Hirakawa
PDF
強化学習と逆強化学習を組み合わせた模倣学習
by
Eiji Uchibe
PDF
論文紹介:Relational inductive biases, deep learning, and graph networks
by
Tatsuhiko Kato
PDF
20150310 第1回 ディープラーニング勉強会
by
哲朗 島田
PDF
クラシックな機械学習の入門 4. 学習データと予測性能
by
Hiroshi Nakagawa
PDF
[DL輪読会]Train longer, generalize better: closing the generalization gap in lar...
by
Deep Learning JP
PPTX
強化学習における好奇心
by
Shota Imai
PDF
[DL輪読会]Shaping Belief States with Generative Environment Models for RL
by
Deep Learning JP
PDF
[Dl輪読会]introduction of reinforcement learning
by
Deep Learning JP
PDF
Large Scale Incremental Learning
by
cvpaper. challenge
Explanation of the mysterious phenomenon in deep learning models: Grokking.
by
satoyuta0112
[DL輪読会]A Bayesian Perspective on Generalization and Stochastic Gradient Descent
by
Deep Learning JP
東大大学院 電子情報学特論講義資料「深層学習概論と理論解析の課題」大野健太
by
Preferred Networks
[DL輪読会]Understanding deep learning requires rethinking generalization
by
Deep Learning JP
[DL輪読会]Learning to Adapt: Meta-Learning for Model-Based Control
by
Deep Learning JP
PRML s1
by
eizoo3010
強化学習その2
by
nishio
ディープラーニング入門 ~ 画像処理・自然言語処理について ~
by
Kensuke Otsuki
ノンパラメトリックベイズを用いた逆強化学習
by
Shota Ishikawa
MASTERING ATARI WITH DISCRETE WORLD MODELS (DreamerV2)
by
harmonylab
海鳥の経路予測のための逆強化学習
by
Tsubasa Hirakawa
強化学習と逆強化学習を組み合わせた模倣学習
by
Eiji Uchibe
論文紹介:Relational inductive biases, deep learning, and graph networks
by
Tatsuhiko Kato
20150310 第1回 ディープラーニング勉強会
by
哲朗 島田
クラシックな機械学習の入門 4. 学習データと予測性能
by
Hiroshi Nakagawa
[DL輪読会]Train longer, generalize better: closing the generalization gap in lar...
by
Deep Learning JP
強化学習における好奇心
by
Shota Imai
[DL輪読会]Shaping Belief States with Generative Environment Models for RL
by
Deep Learning JP
[Dl輪読会]introduction of reinforcement learning
by
Deep Learning JP
Large Scale Incremental Learning
by
cvpaper. challenge
More from Deep Learning JP
PPTX
【DL輪読会】AdaptDiffuser: Diffusion Models as Adaptive Self-evolving Planners
by
Deep Learning JP
PPTX
【DL輪読会】事前学習用データセットについて
by
Deep Learning JP
PPTX
【DL輪読会】 "Learning to render novel views from wide-baseline stereo pairs." CVP...
by
Deep Learning JP
PPTX
【DL輪読会】Zero-Shot Dual-Lens Super-Resolution
by
Deep Learning JP
PPTX
【DL輪読会】BloombergGPT: A Large Language Model for Finance arxiv
by
Deep Learning JP
PPTX
【DL輪読会】マルチモーダル LLM
by
Deep Learning JP
PDF
【 DL輪読会】ToolLLM: Facilitating Large Language Models to Master 16000+ Real-wo...
by
Deep Learning JP
PPTX
【DL輪読会】AnyLoc: Towards Universal Visual Place Recognition
by
Deep Learning JP
PDF
【DL輪読会】Can Neural Network Memorization Be Localized?
by
Deep Learning JP
PPTX
【DL輪読会】Hopfield network 関連研究について
by
Deep Learning JP
PPTX
【DL輪読会】SimPer: Simple self-supervised learning of periodic targets( ICLR 2023 )
by
Deep Learning JP
PDF
【DL輪読会】RLCD: Reinforcement Learning from Contrast Distillation for Language M...
by
Deep Learning JP
PPTX
【DL輪読会】"Language Instructed Reinforcement Learning for Human-AI Coordination "
by
Deep Learning JP
PPTX
【DL輪読会】Llama 2: Open Foundation and Fine-Tuned Chat Models
by
Deep Learning JP
PDF
【DL輪読会】"Learning Fine-Grained Bimanual Manipulation with Low-Cost Hardware"
by
Deep Learning JP
PPTX
【DL輪読会】Parameter is Not All You Need:Starting from Non-Parametric Networks fo...
by
Deep Learning JP
PDF
【DL輪読会】Drag Your GAN: Interactive Point-based Manipulation on the Generative ...
by
Deep Learning JP
PDF
【DL輪読会】Self-Supervised Learning from Images with a Joint-Embedding Predictive...
by
Deep Learning JP
PPTX
【DL輪読会】Towards Understanding Ensemble, Knowledge Distillation and Self-Distil...
by
Deep Learning JP
PPTX
【DL輪読会】VIP: Towards Universal Visual Reward and Representation via Value-Impl...
by
Deep Learning JP
【DL輪読会】AdaptDiffuser: Diffusion Models as Adaptive Self-evolving Planners
by
Deep Learning JP
【DL輪読会】事前学習用データセットについて
by
Deep Learning JP
【DL輪読会】 "Learning to render novel views from wide-baseline stereo pairs." CVP...
by
Deep Learning JP
【DL輪読会】Zero-Shot Dual-Lens Super-Resolution
by
Deep Learning JP
【DL輪読会】BloombergGPT: A Large Language Model for Finance arxiv
by
Deep Learning JP
【DL輪読会】マルチモーダル LLM
by
Deep Learning JP
【 DL輪読会】ToolLLM: Facilitating Large Language Models to Master 16000+ Real-wo...
by
Deep Learning JP
【DL輪読会】AnyLoc: Towards Universal Visual Place Recognition
by
Deep Learning JP
【DL輪読会】Can Neural Network Memorization Be Localized?
by
Deep Learning JP
【DL輪読会】Hopfield network 関連研究について
by
Deep Learning JP
【DL輪読会】SimPer: Simple self-supervised learning of periodic targets( ICLR 2023 )
by
Deep Learning JP
【DL輪読会】RLCD: Reinforcement Learning from Contrast Distillation for Language M...
by
Deep Learning JP
【DL輪読会】"Language Instructed Reinforcement Learning for Human-AI Coordination "
by
Deep Learning JP
【DL輪読会】Llama 2: Open Foundation and Fine-Tuned Chat Models
by
Deep Learning JP
【DL輪読会】"Learning Fine-Grained Bimanual Manipulation with Low-Cost Hardware"
by
Deep Learning JP
【DL輪読会】Parameter is Not All You Need:Starting from Non-Parametric Networks fo...
by
Deep Learning JP
【DL輪読会】Drag Your GAN: Interactive Point-based Manipulation on the Generative ...
by
Deep Learning JP
【DL輪読会】Self-Supervised Learning from Images with a Joint-Embedding Predictive...
by
Deep Learning JP
【DL輪読会】Towards Understanding Ensemble, Knowledge Distillation and Self-Distil...
by
Deep Learning JP
【DL輪読会】VIP: Towards Universal Visual Reward and Representation via Value-Impl...
by
Deep Learning JP
[DL輪読会]Grokking: Generalization Beyond Overfitting on Small Algorithmic Datasets
1.
1 DEEP LEARNING JP [DL
Papers] http://deeplearning.jp/ “Grokking: Generalization Beyond Overfitting on Small Algorithmic Datasets” (ICLR 2021 workshop) Okimura Itsuki, Matsuo Lab, B4
2.
アジェンダ 1. 書誌情報 2. 概要 3.
背景 4. 実験 2
3.
1 書誌情報 タイトル: Grokking:
Generalization Beyond Overfitting on Small Algorithmic Datasets 出典: ICLR 2021 (1st Mathematical Reasoning in General Artificial Intelligence Workshop) https://nips.cc/Conferences/2021/ScheduleMultitrack?event=25970 著者: Alethea Power, Yuri Burda, Harri Edwards, Igor Babuschkin & Vedant Misra (OpenAI) 選んだ理由:現象が面白い 3
4.
2 概要 • 一般的にニューラルネットワークはある一定の学習ステップ数を経ると 以降の検証データで損失が減少しない過学習に陥るとされる. •
しかし、数式の答えを求めるタスクにおいて 過学習するステップ数を遥かに超えて学習を続けると, ニューラルネットワークがデータ中のパターンを 「理解する(Grokking)」プロセスを通じて学習し, 急激な汎化性能の向上が見られる場合があることを示した. • この現象において,より小さなデータセットを用いた場合, 汎化のためのステップ数の必要量が増加することも示した. 4
5.
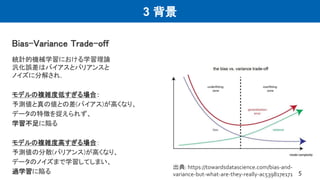
3 背景 5 Bias-Variance Trade-off 出典:
https://towardsdatascience.com/bias-and- variance-but-what-are-they-really-ac539817e171 統計的機械学習における学習理論 汎化誤差はバイアスとバリアンスと ノイズに分解され, モデルの複雑度低すぎる場合: 予測値と真の値との差(バイアス)が高くなり、 データの特徴を捉えられず、 学習不足に陥る モデルの複雑度高すぎる場合: 予測値の分散(バリアンス)が高くなり、 データのノイズまで学習してしまい、 過学習に陥る
6.
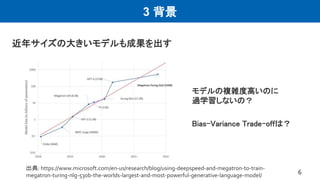
3 背景 6 近年サイズの大きいモデルも成果を出す モデルの複雑度高いのに 過学習しないの? Bias-Variance Trade-offは? 出典:
https://www.microsoft.com/en-us/research/blog/using-deepspeed-and-megatron-to-train- megatron-turing-nlg-530b-the-worlds-largest-and-most-powerful-generative-language-model/
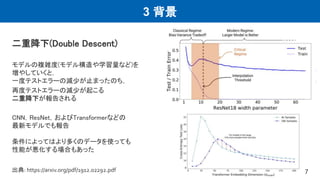
7.
3 背景 二重降下(Double Descent) モデルの複雑度(モデル構造や学習量など)を 増やしていくと, 一度テストエラーの減少が止まったのち, 再度テストエラーの減少が起こる 二重降下が報告される CNN,ResNet,およびTransformerなどの 最新モデルでも報告 条件によってはより多くのデータを使っても 性能が悪化する場合もあった 7 出典:
https://arxiv.org/pdf/1912.02292.pdf
8.
3 背景 8 GPT-3はパラメータ数が13Bを超えると足し算、引き算が解け始める Few-shotの設定において パラメータ数が6.7B以下のモデル ほとんど四則演算が解けない パラメータ数が13Bのモデル 二桁の足し算、引き算を50%前後解ける パラメータ数が175Bのモデル 二桁の足し算、引き算は98%以上, 三桁の足し算、引き算は80%以上解ける 掛け算や複合演算なども20%前後解ける →解けるかどうかはパラメータ数依存? 出典: https://arxiv.org/pdf/2005.14165.pdf
9.
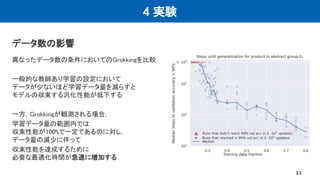
4 実験 9 二項演算を小規模なニューラルネットにより汎化できるか検証 𝑎 ∘
𝑏 = 𝑐の形の等式のデータセット (0 ≤ 𝑎, 𝑏 < 97)に対して サイズの小さい(400Kパラメーター) Transformerで学習を行う すべての可能な等式の適切な部分集合に ついてニューラルネットワークを訓練することは、右図の 二項演算表の空白を埋めることに等しい トークン化されるため内部的な情報 (ex. 10進数での表記)にはアクセスできず 離散的な記号の他の要素との相関から 二項演算を解くことができるか?
10.
4 実験 Grokking 10 *grok【他動】〈米俗〉完全に[しっかり・ 心底から]理解[把握]する 102step程度から訓練データでの損失と 検証データでの損失に乖離が見え始め, 103step程度で訓練データでの損失が0近くになる その後105 stepから検証データでの損失が 下がり始める. そして106 stepで検証データでも損失が0近くになる →過学習し始してからその1000倍以上の 最適化stepを経ることで急激に検証データでの 精度が急激に向上する。(Grokking) 出典: https://eow.alc.co.jp/search?q=grok
11.
4 実験 データ数の影響 11 異なったデータ数の条件においてのGrokkingを比較 一般的な教師あり学習の設定において データが少ないほど学習データ量を減らすと モデルの収束する汎化性能が低下する 一方,Grokkingが観測される場合, 学習データ量の範囲内では 収束性能が100%で一定であるのに対し, データ量の減少に伴って 収束性能を達成するために 必要な最適化時間が急速に増加する
12.
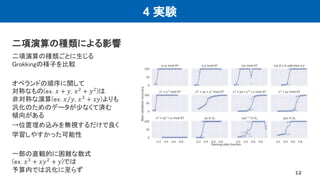
4 実験 二項演算の種類による影響 12 二項演算の種類ごとに生じる Grokkingの様子を比較 オペランドの順序に関して 対称なもの(ex. 𝑥
+ 𝑦, 𝑥2 + 𝑦2 )は 非対称な演算(ex. 𝑥 𝑦, 𝑥3 + 𝑥𝑦)よりも 汎化のためのデータが少なくて済む 傾向がある →位置埋め込みを無視するだけで良く 学習しやすかった可能性 一部の直観的に困難な数式 (ex. 𝑥3 + 𝑥𝑦2 + 𝑦)では 予算内では汎化に至らず
13.
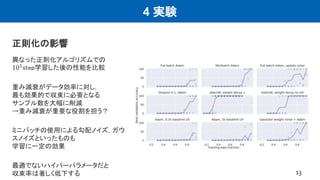
4 実験 正則化の影響 13 異なった正則化アルゴリズムでの 105step学習した後の性能を比較 重み減衰がデータ効率に対し, 最も効果的で収束に必要となる サンプル数を大幅に削減 →重み減衰が重要な役割を担う? ミニバッチの使用による勾配ノイズ,ガウ スノイズといったものも 学習に一定の効果 最適でないハイパーパラメータだと 収束率は著しく低下する
14.
4 実験 出力層の可視化 14 𝑥 +
𝑦で学習したTransformerの 埋め込み層をt-SNEを用いて可視化する 各要素に8を加えた数列が示される →埋め込み層が数学的な特徴を捉えている
15.
まとめ 15 • 一般的にニューラルはある一定の学習ステップ数を経ると 以降の検証データで損失が減少しない過学習に陥るとされる. • しかし、数式の答えを求めるタスクにおいて 過学習するステップ数を遥かに超えて学習を続けると, ニューラルネットワークがデータ中のパターンを 「理解する(Grokking)」プロセスを通じて学習し, 急激な汎化性能の向上が見られる場合があることを示した. •
この現象において,より小さなデータセットを用いた場合, 汎化のためのステップ数の必要量が増加することも示した.
16.
感想 16 (確かに“完全に理解した曲線”っぽい) パラメーター数の小さなモデルでも汎化に到達するのが意外だった。 パラメータ数が増えた場合にGrokkingに到達するまでの比較は見たかった。 今回の実験では二項演算を97×97の数字の表の空きスロットを埋める計算として定義。 実際の計算よりはかなり小規模なスケール 各桁数字ごとにトークン化すればより大きな桁でのGrokkingに到達できる? 小さいモデルでも実現可能な一方で,Grokkingは学習率を比較的狭い範囲(1桁以内)で 調整する必要があるらしく,やはりモデルの複雑度を上げるのにもパラメータを増やすのが有力?
17.
DEEP LEARNING JP [DL
Papers] “Grokking: Generalization Beyond Overfitting on Small Algorithmic Datasets” (ICLR 2021 workshop) Okimura Itsuki, Matsuo Lab, B4 http://deeplearning.jp/
Download
![1
DEEP LEARNING JP
[DL Papers]
http://deeplearning.jp/
“Grokking: Generalization Beyond Overfitting on Small
Algorithmic Datasets” (ICLR 2021 workshop)
Okimura Itsuki, Matsuo Lab, B4](https://image.slidesharecdn.com/20220325okimura-220405024717/85/DL-Grokking-Generalization-Beyond-Overfitting-on-Small-Algorithmic-Datasets-1-320.jpg)
![1
DEEP LEARNING JP
[DL Papers]
http://deeplearning.jp/
“Grokking: Generalization Beyond Overfitting on Small
Algorithmic Datasets” (ICLR 2021 workshop)
Okimura Itsuki, Matsuo Lab, B4](https://image.slidesharecdn.com/20220325okimura-220405024717/75/DL-Grokking-Generalization-Beyond-Overfitting-on-Small-Algorithmic-Datasets-1-2048.jpg)





![4 実験
Grokking
10
*grok【他動】〈米俗〉完全に[しっかり・
心底から]理解[把握]する
102step程度から訓練データでの損失と
検証データでの損失に乖離が見え始め,
103step程度で訓練データでの損失が0近くになる
その後105
stepから検証データでの損失が
下がり始める.
そして106
stepで検証データでも損失が0近くになる
→過学習し始してからその1000倍以上の
最適化stepを経ることで急激に検証データでの
精度が急激に向上する。(Grokking)
出典: https://eow.alc.co.jp/search?q=grok](https://image.slidesharecdn.com/20220325okimura-220405024717/85/DL-Grokking-Generalization-Beyond-Overfitting-on-Small-Algorithmic-Datasets-10-320.jpg)



![DEEP LEARNING JP
[DL Papers]
“Grokking: Generalization Beyond Overfitting on Small
Algorithmic Datasets” (ICLR 2021 workshop)
Okimura Itsuki, Matsuo Lab, B4
http://deeplearning.jp/](https://image.slidesharecdn.com/20220325okimura-220405024717/85/DL-Grokking-Generalization-Beyond-Overfitting-on-Small-Algorithmic-Datasets-17-320.jpg)


![[DL輪読会]相互情報量最大化による表現学習](https://cdn.slidesharecdn.com/ss_thumbnails/20190913iwasawa-190913002312-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DL輪読会]Dream to Control: Learning Behaviors by Latent Imagination](https://cdn.slidesharecdn.com/ss_thumbnails/20200313furutav2-200313025657-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]Learning Latent Dynamics for Planning from Pixels](https://cdn.slidesharecdn.com/ss_thumbnails/taniguchi20181221-190104064850-thumbnail.jpg?width=640&height=640&fit=bounds)


















![[DL輪読会]Pay Attention to MLPs (gMLP)](https://cdn.slidesharecdn.com/ss_thumbnails/kobayashi-210528032327-thumbnail.jpg?width=640&height=640&fit=bounds)




![[DL輪読会]A Bayesian Perspective on Generalization and Stochastic Gradient Descent](https://cdn.slidesharecdn.com/ss_thumbnails/20171106dl2-171108033614-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]Understanding deep learning requires rethinking generalization](https://cdn.slidesharecdn.com/ss_thumbnails/dlhacks20170217-170217024917-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]Learning to Adapt: Meta-Learning for Model-Based Control](https://cdn.slidesharecdn.com/ss_thumbnails/20180511dl-180511004107-thumbnail.jpg?width=640&height=640&fit=bounds)










![[DL輪読会]Train longer, generalize better: closing the generalization gap in lar...](https://cdn.slidesharecdn.com/ss_thumbnails/dlhacks20170721-170721035045-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]Shaping Belief States with Generative Environment Models for RL](https://cdn.slidesharecdn.com/ss_thumbnails/20190705suzuki-191204061058-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Dl輪読会]introduction of reinforcement learning](https://cdn.slidesharecdn.com/ss_thumbnails/dlintroductionofreinforcementlearning-161121061444-thumbnail.jpg?width=640&height=640&fit=bounds)




















