Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
Submit search
EN
Uploaded by
Deep Learning JP
PPTX, PDF
479 views
【DL輪読会】マルチモーダル LLM
2023/8/16 Deep Learning JP http://deeplearning.jp/seminar-2/
Technology
◦
Related topics:
Deep Learning
•
Read more
0
Save
Share
Embed
Embed presentation
Download
Download to read offline
1
/ 14
2
/ 14
Most read
3
/ 14
4
/ 14
5
/ 14
6
/ 14
Most read
7
/ 14
8
/ 14
9
/ 14
10
/ 14
11
/ 14
12
/ 14
13
/ 14
14
/ 14
More Related Content
PDF
Encoding and Controlling Global Semantics for Long-form Video Question Answering
by
harmonylab
PDF
【DeepLearning研修】Transformerの基礎と応用 -- 第1回 Transformerの基本
by
Sony - Neural Network Libraries
PDF
【DeepLearning研修】Transfomerの基礎と応用 --第4回 マルチモーダルへの展開
by
Sony - Neural Network Libraries
PPTX
マルチモーダル深層学習の研究動向
by
Koichiro Mori
PPTX
[DL輪読会]MetaFormer is Actually What You Need for Vision
by
Deep Learning JP
PPTX
「解説資料」MetaFormer is Actually What You Need for Vision
by
Takumi Ohkuma
PPTX
【DL輪読会】マルチモーダル 基盤モデル
by
Deep Learning JP
PDF
[DL輪読会]One Model To Learn Them All
by
Deep Learning JP
Encoding and Controlling Global Semantics for Long-form Video Question Answering
by
harmonylab
【DeepLearning研修】Transformerの基礎と応用 -- 第1回 Transformerの基本
by
Sony - Neural Network Libraries
【DeepLearning研修】Transfomerの基礎と応用 --第4回 マルチモーダルへの展開
by
Sony - Neural Network Libraries
マルチモーダル深層学習の研究動向
by
Koichiro Mori
[DL輪読会]MetaFormer is Actually What You Need for Vision
by
Deep Learning JP
「解説資料」MetaFormer is Actually What You Need for Vision
by
Takumi Ohkuma
【DL輪読会】マルチモーダル 基盤モデル
by
Deep Learning JP
[DL輪読会]One Model To Learn Them All
by
Deep Learning JP
Similar to 【DL輪読会】マルチモーダル LLM
PDF
【メタサーベイ】基盤モデル / Foundation Models
by
cvpaper. challenge
PDF
【メタサーベイ】Video Transformer
by
cvpaper. challenge
PDF
全力解説!Transformer
by
Arithmer Inc.
PDF
【学会聴講報告】CVPR2025からみるVision最先端トレンド / CVPR2025 report
by
Sony - Neural Network Libraries
PDF
論文紹介:InternVideo2: Scaling Foundation Models for Multimodal Video Understanding
by
Toru Tamaki
PDF
20150930
by
nlab_utokyo
PDF
論文紹介:VLP: A Survey on Vision-Language Pre-training
by
Toru Tamaki
PDF
【 DL輪読会】ToolLLM: Facilitating Large Language Models to Master 16000+ Real-wo...
by
Deep Learning JP
PDF
[DL輪読会]Stereo Magnification: Learning view synthesis using multiplane images, +α
by
Deep Learning JP
PPTX
ChatGPT(LLMによる生成系AI)の追加学習を No Code で行う ~ 概念モデリング教本を元に ~
by
Knowledge & Experience
PDF
論文紹介:A Survey of Vision-Language Pre-Trained Models
by
Toru Tamaki
PDF
20160601画像電子学会
by
nlab_utokyo
【メタサーベイ】基盤モデル / Foundation Models
by
cvpaper. challenge
【メタサーベイ】Video Transformer
by
cvpaper. challenge
全力解説!Transformer
by
Arithmer Inc.
【学会聴講報告】CVPR2025からみるVision最先端トレンド / CVPR2025 report
by
Sony - Neural Network Libraries
論文紹介:InternVideo2: Scaling Foundation Models for Multimodal Video Understanding
by
Toru Tamaki
20150930
by
nlab_utokyo
論文紹介:VLP: A Survey on Vision-Language Pre-training
by
Toru Tamaki
【 DL輪読会】ToolLLM: Facilitating Large Language Models to Master 16000+ Real-wo...
by
Deep Learning JP
[DL輪読会]Stereo Magnification: Learning view synthesis using multiplane images, +α
by
Deep Learning JP
ChatGPT(LLMによる生成系AI)の追加学習を No Code で行う ~ 概念モデリング教本を元に ~
by
Knowledge & Experience
論文紹介:A Survey of Vision-Language Pre-Trained Models
by
Toru Tamaki
20160601画像電子学会
by
nlab_utokyo
More from Deep Learning JP
PDF
【DL輪読会】Deep Transformers without Shortcuts: Modifying Self-attention for Fait...
by
Deep Learning JP
PDF
【DL輪読会】Self-Supervised Learning from Images with a Joint-Embedding Predictive...
by
Deep Learning JP
PDF
【DL輪読会】Drag Your GAN: Interactive Point-based Manipulation on the Generative ...
by
Deep Learning JP
PPTX
【DL輪読会】Llama 2: Open Foundation and Fine-Tuned Chat Models
by
Deep Learning JP
PDF
【DL輪読会】Can Neural Network Memorization Be Localized?
by
Deep Learning JP
PDF
【DL輪読会】"Secrets of RLHF in Large Language Models Part I: PPO"
by
Deep Learning JP
PPTX
【DL輪読会】Hopfield network 関連研究について
by
Deep Learning JP
PDF
【DL輪読会】RLCD: Reinforcement Learning from Contrast Distillation for Language M...
by
Deep Learning JP
PDF
【DL輪読会】"Learning Fine-Grained Bimanual Manipulation with Low-Cost Hardware"
by
Deep Learning JP
PPTX
【DL輪読会】"Language Instructed Reinforcement Learning for Human-AI Coordination "
by
Deep Learning JP
PPTX
【DL輪読会】SimPer: Simple self-supervised learning of periodic targets( ICLR 2023 )
by
Deep Learning JP
PPTX
【DL輪読会】Parameter is Not All You Need:Starting from Non-Parametric Networks fo...
by
Deep Learning JP
PPTX
【DL輪読会】事前学習用データセットについて
by
Deep Learning JP
PPTX
【DL輪読会】Towards Understanding Ensemble, Knowledge Distillation and Self-Distil...
by
Deep Learning JP
PPTX
【DL輪読会】VIP: Towards Universal Visual Reward and Representation via Value-Impl...
by
Deep Learning JP
PPTX
【DL輪読会】 "Learning to render novel views from wide-baseline stereo pairs." CVP...
by
Deep Learning JP
PPTX
【DL輪読会】AdaptDiffuser: Diffusion Models as Adaptive Self-evolving Planners
by
Deep Learning JP
PPTX
【DL輪読会】BloombergGPT: A Large Language Model for Finance arxiv
by
Deep Learning JP
PPTX
【DL輪読会】AnyLoc: Towards Universal Visual Place Recognition
by
Deep Learning JP
PPTX
【DL輪読会】Zero-Shot Dual-Lens Super-Resolution
by
Deep Learning JP
【DL輪読会】Deep Transformers without Shortcuts: Modifying Self-attention for Fait...
by
Deep Learning JP
【DL輪読会】Self-Supervised Learning from Images with a Joint-Embedding Predictive...
by
Deep Learning JP
【DL輪読会】Drag Your GAN: Interactive Point-based Manipulation on the Generative ...
by
Deep Learning JP
【DL輪読会】Llama 2: Open Foundation and Fine-Tuned Chat Models
by
Deep Learning JP
【DL輪読会】Can Neural Network Memorization Be Localized?
by
Deep Learning JP
【DL輪読会】"Secrets of RLHF in Large Language Models Part I: PPO"
by
Deep Learning JP
【DL輪読会】Hopfield network 関連研究について
by
Deep Learning JP
【DL輪読会】RLCD: Reinforcement Learning from Contrast Distillation for Language M...
by
Deep Learning JP
【DL輪読会】"Learning Fine-Grained Bimanual Manipulation with Low-Cost Hardware"
by
Deep Learning JP
【DL輪読会】"Language Instructed Reinforcement Learning for Human-AI Coordination "
by
Deep Learning JP
【DL輪読会】SimPer: Simple self-supervised learning of periodic targets( ICLR 2023 )
by
Deep Learning JP
【DL輪読会】Parameter is Not All You Need:Starting from Non-Parametric Networks fo...
by
Deep Learning JP
【DL輪読会】事前学習用データセットについて
by
Deep Learning JP
【DL輪読会】Towards Understanding Ensemble, Knowledge Distillation and Self-Distil...
by
Deep Learning JP
【DL輪読会】VIP: Towards Universal Visual Reward and Representation via Value-Impl...
by
Deep Learning JP
【DL輪読会】 "Learning to render novel views from wide-baseline stereo pairs." CVP...
by
Deep Learning JP
【DL輪読会】AdaptDiffuser: Diffusion Models as Adaptive Self-evolving Planners
by
Deep Learning JP
【DL輪読会】BloombergGPT: A Large Language Model for Finance arxiv
by
Deep Learning JP
【DL輪読会】AnyLoc: Towards Universal Visual Place Recognition
by
Deep Learning JP
【DL輪読会】Zero-Shot Dual-Lens Super-Resolution
by
Deep Learning JP
Recently uploaded
PDF
第21回 Gen AI 勉強会「NotebookLMで60ページ超の スライドを作成してみた」
by
嶋 是一 (Yoshikazu SHIMA)
PDF
自転車ユーザ参加型路面画像センシングによる点字ブロック検出における性能向上方法の模索 (20260123 SeMI研)
by
Yuto Matsuda
PDF
ST2024_PM1_2_Case_study_of_local_newspaper_company.pdf
by
akipii ogaoga
PDF
Team Topology Adaptive Organizational Design for Rapid Delivery of Valuable S...
by
akipii ogaoga
PDF
2025→2026宙畑ゆく年くる年レポート_100社を超える企業アンケート総まとめ!!_企業まとめ_1229_3版
by
sorabatake
PDF
100年後の知財業界-生成AIスライドアドリブプレゼン イーパテントYouTube配信
by
e-Patent Co., Ltd.
PDF
Reiwa 7 IT Strategist Afternoon I Question-1 Ansoff's Growth Vector
by
akipii ogaoga
PDF
Reiwa 7 IT Strategist Afternoon I Question-1 3C Analysis
by
akipii ogaoga
PDF
Starlink Direct-to-Cell (D2C) 技術の概要と将来の展望
by
CRI Japan, Inc.
PDF
FY2025 IT Strategist Afternoon I Question-1 Balanced Scorecard
by
akipii ogaoga
PDF
PMBOK 7th Edition_Project Management Process_WF Type Development
by
akipii ogaoga
PDF
PMBOK 7th Edition Project Management Process Scrum
by
akipii ogaoga
PDF
PMBOK 7th Edition_Project Management Context Diagram
by
akipii ogaoga
第21回 Gen AI 勉強会「NotebookLMで60ページ超の スライドを作成してみた」
by
嶋 是一 (Yoshikazu SHIMA)
自転車ユーザ参加型路面画像センシングによる点字ブロック検出における性能向上方法の模索 (20260123 SeMI研)
by
Yuto Matsuda
ST2024_PM1_2_Case_study_of_local_newspaper_company.pdf
by
akipii ogaoga
Team Topology Adaptive Organizational Design for Rapid Delivery of Valuable S...
by
akipii ogaoga
2025→2026宙畑ゆく年くる年レポート_100社を超える企業アンケート総まとめ!!_企業まとめ_1229_3版
by
sorabatake
100年後の知財業界-生成AIスライドアドリブプレゼン イーパテントYouTube配信
by
e-Patent Co., Ltd.
Reiwa 7 IT Strategist Afternoon I Question-1 Ansoff's Growth Vector
by
akipii ogaoga
Reiwa 7 IT Strategist Afternoon I Question-1 3C Analysis
by
akipii ogaoga
Starlink Direct-to-Cell (D2C) 技術の概要と将来の展望
by
CRI Japan, Inc.
FY2025 IT Strategist Afternoon I Question-1 Balanced Scorecard
by
akipii ogaoga
PMBOK 7th Edition_Project Management Process_WF Type Development
by
akipii ogaoga
PMBOK 7th Edition Project Management Process Scrum
by
akipii ogaoga
PMBOK 7th Edition_Project Management Context Diagram
by
akipii ogaoga
【DL輪読会】マルチモーダル LLM
1.
©︎MATSUO INSTITUTE, INC. DEEP
LEARNING JP [DL Papers] マルチモーダル LLM Takaomi Hasegawa http://deeplearning.jp/
2.
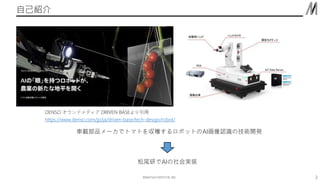
©︎MATSUO INSTITUTE, INC. 自己紹介 2 https://www.denso.com/jp/ja/driven-base/tech-design/robot/ DENSO
オウンドメディア DRIVEN BASEより引用 車載部品メーカでトマトを収穫するロボットのAI画像認識の技術開発 松尾研でAIの社会実装
3.
©︎MATSUO INSTITUTE, INC. 書誌情報
VideoChat 3 出典) https://arxiv.org/abs/2305.06355 ・タイトル VideoChat ・著者 OpenGVLab(Generalized vision-based AI) Shanghai AI Lab, 南京大学、香港大学、 深圳等 ・概要 - End-to-Endのチャットベースのビデオ理解システム - データセットも合わせて提案 - コードも公開
4.
©︎MATSUO INSTITUTE, INC. 選定理由 4 ・ChatGPTでLanguage-to-Languageが注目されているが、個 人的にマルチモーダル(特に画像)に興味があった ・GitHubのStarが2000以上と注目度が高い https://github.com/OpenGVLab/Ask-Anything
5.
©︎MATSUO INSTITUTE, INC. 関連発表 5 https://deeplearning.jp/%e3%83%9e%e3%83%ab%e3%83%81%e3%83%a2%e3%83%bc%e3%83%80%e3% 83%ab-%e5%9f%ba%e7%9b%a4%e3%83%a2%e3%83%87%e3%83%ab/ マルチモーダル
基盤モデル(原田さん) Visual ChatGPT(今井さん) https://deeplearning.jp/visual-chatgpt-talking-drawing-and-editing-with-visual-foundation-models/ 結構被ってました… 動画 + LLMは初めてということでご容赦を
6.
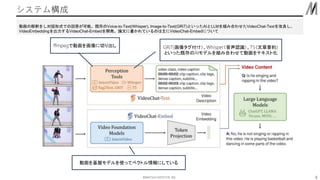
©︎MATSUO INSTITUTE, INC. システム構成 6 動画の解釈をし対話形式での回答が可能。既存のVoice-to-Text(Whisper),
Image-to-Text(GRiT)といったAIとLLMを組み合わせたVideoChat-Textを改良し、 VideoEmbeddingを出力するVideoChat-Embedを開発。論文に書かれているのは主にVideoChat-Embedについて GRiT(画像タグ付け)、Whisper(音声認識)、T5(文章要約) といった既存のAIモデルを組み合わせて動画をテキスト化 動画を基盤モデルを使ってベクトル情報にしている ffmpegで動画を画像に切り出し
7.
©︎MATSUO INSTITUTE, INC. ユーザーインターフェース 7 動画に対して質問すると回答が得られる。動画は1min以内(実際のサンプル動画はほとんど5秒〜10秒)
8.
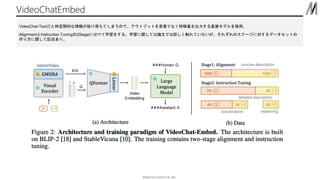
©︎MATSUO INSTITUTE, INC. VideoChatEmbed VideoChat-Textだと時空間的な情報が抜け落ちてしまうので、アウトプットを言葉でなく特徴量を出力する基盤モデルを使用。 AlignmentとInstruction
Tuningの2Stageに分けて学習をする。学習に関しては論文では詳しく触れていないが、それぞれのステージに対するデータセットの 作り方に関して記述あり。
9.
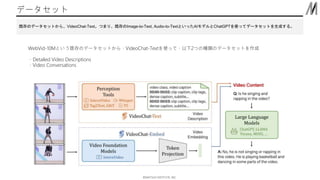
©︎MATSUO INSTITUTE, INC. データセット 既存のデータセットから、VideoChat-Text。つまり、既存のImage-to-Text,
Audio-to-TextといったAIモデルとChatGPTを使ってデータセットを生成する。 WebVid-10Mという既存のデータセットから、VideoChat-Textを使って、以下2つの種類のデータセットを作成 ・Detailed Video Descriptions ・Video Conversations
10.
©︎MATSUO INSTITUTE, INC. Detailed
Video Descriptions VideoChat-Textの出力に対して、ChatGPTの2段階のプロンプトを通す。1段目(Table3)は多彩なラベルを分かりやすいストーリーにする。 2段目(Table4)は、文章をリファインすることでハルシネーションを抑制する。 出力例 2段階のプロンプト
11.
©︎MATSUO INSTITUTE, INC. Video
Conversations 3種類(descriptive, temporal, casual)のプロンプトを使うことで、動画に対する会話例を得る
12.
©︎MATSUO INSTITUTE, INC. まとめとFuture
work まとめとFuture workと所感 まとめ 以下の2つの手法を提案。VideoChat-Embedの方が時空間の推論と因果関係をよく表している ・VideoChat-Text:テキストベースバージョン ・VideoChat-Embed: end-to-endバージョン Future work 以下3点 ・モデルのスケール(大規模化) ・ベンチマーク ・長時間のビデオ対応 所感 ・データセットChatGPTでつくっている点、プロンプトの工夫(2段階、3種類)は面白い(商用利用は不可?) ・長時間の動画は難しそう。すぐ実用化するとしたら、動画内を自然言語で検索(Appendix 1)して時間特定、他のトリガを使うとい った工夫が必要そう ・言語というインターフェースの限界(情報量の低下)を感じた(Appendix 2)
13.
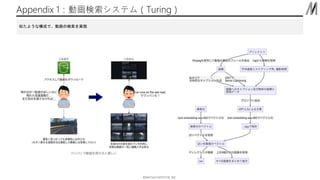
©︎MATSUO INSTITUTE, INC. Appendix
1:動画検索システム(Turing) 似たような構成で、動画の検索を実現
14.
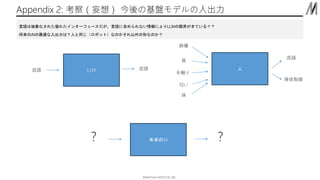
©︎MATSUO INSTITUTE, INC. Appendix
2: 考察(妄想) 今後の基盤モデルの入出力 LLM 言語 言語 人 音 映像 手触り 匂い 味 言語 身体制御 言語は抽象化された優れたインターフェースだが、言語に含められない情報によりLLMの限界がきている?? 将来のAIの最適な入出力は?人と同じ(ロボット)なのかそれ以外の形なのか? 未来のAI ? ?
Download
![©︎MATSUO INSTITUTE, INC.
DEEP LEARNING JP
[DL Papers]
マルチモーダル LLM
Takaomi Hasegawa
http://deeplearning.jp/](https://image.slidesharecdn.com/llm20230803-230816031643-032a1160/85/DL-LLM-1-320.jpg)












![[DL輪読会]MetaFormer is Actually What You Need for Vision](https://cdn.slidesharecdn.com/ss_thumbnails/20220121metaformer-220121085750-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DL輪読会]One Model To Learn Them All](https://cdn.slidesharecdn.com/ss_thumbnails/dljp20170714ono-170714005853-thumbnail.jpg?width=640&height=640&fit=bounds)








![[DL輪読会]Stereo Magnification: Learning view synthesis using multiplane images, +α](https://cdn.slidesharecdn.com/ss_thumbnails/stereomagnification-201002033144-thumbnail.jpg?width=640&height=640&fit=bounds)



































