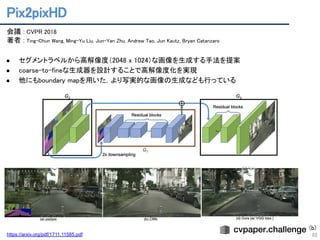
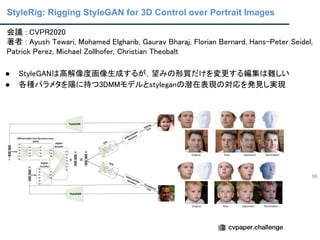
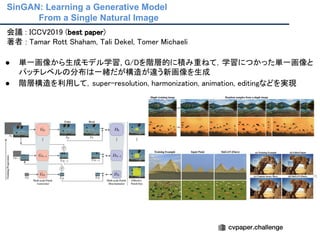
Unsupervised Disentanglement Learning
11
会議: ICLR2017
著者 : I. Higgins, L. Matthey, A. Pal, C. Burgess, X. Glorot, M. Botvinick, S. Mo-hamed, and A. Lerchner
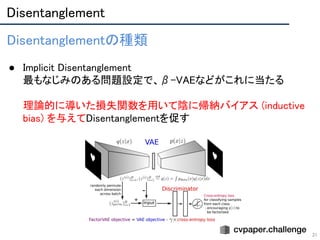
● VAEの目的関数中の潜在次元のキャパシティと再構成能力をバランス調整するHyperparameter β を
VAEに拡張.
○ β=1のとき,通常のVAE.
○ βが大きいほど,潜在空間が正規分布に従うことを強制 = Disentanglementの促進.
beta-VAE: Learning Basic Visual Concepts
with a Constrained Variational Framework
12.
InfoGAN: Interpretable RepresentationLearning
by Information Maximizing Generative Adversarial Nets
12
会議 : NIPS2016
著者 : X. Chen, Y. Duan, R. Houthooft, J. Schulman, I. Sutskever, and P. Abbeel
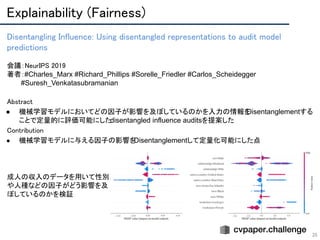
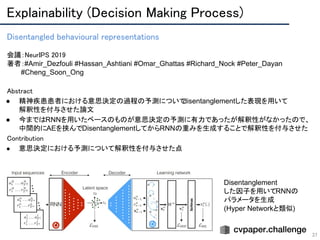
● 二変数の依存関係を測る相互情報量を最大化することでDisentanglementするInfoGANを提案
○ これにより,潜在コード C がノイズ Z と独立する
● Cで制御可能な回転などの変動因子が獲得されたことを報告
Unsupervised Disentanglement Learning
13.
Understanding disentangling inβ-VAE
13
会議 : NIPS2017 Workshops
著者 : C. P. Burgess, I. Higgins, A. Pal, L. Matthey, N. Watters, G. Desjardins,and A. Lerchner
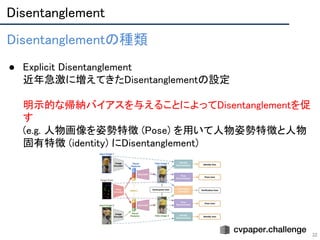
● β-VAEにはより良いDisentanglementのためには,再構成能力を犠牲にする必要があった(trade-off
問題)
● この問題を解決するために,Hyperparameter C を線形に増加することで,潜在表現の キャパシティ
を徐々に増加させる.
○ 学習済みのDisentangled表現を維持しながら,より多くの変動因子をDisentanglementしようとし
た.
Unsupervised Disentanglement Learning
14.
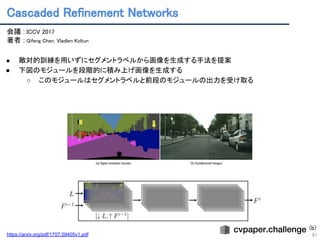
Disentangling by Factorising
14
会議: ICML2018
著者 : H. Kim and A. Mnih
● trade-off問題の解決のために,確率変数間の依存性を測るTotal Correlation (TC) の誤差をVAEの目
的関数に追加
● 入力がq(z)とbar{q}(z)のどちらかを分類するDiscriminatorでTCを近似
Unsupervised Disentanglement Learning
15.
Isolating Sources ofDisentanglement in Variational Autoencoders
15
会議 : NIPS2018
著者 : T. Q. Chen, X. Li, R. B. Grosse, and D. K. Duvenaud
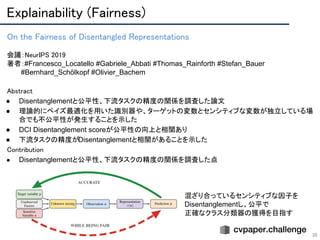
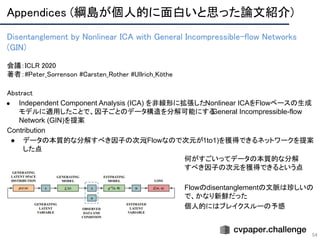
● VAEのKL項を,データサンプルと潜在変数との相互情報量,TC項,次元ごとのKL項に分解
● TC項を提案するbiased Monte-Carloによって近似し,実際にTC項がdisentanglementに関連することを
明らかにした
○ FactorVAEと違い,追加の学習パラメータがない.
Unsupervised Disentanglement Learning
Challenging Common Assumptionsin the Unsupervised Learning of Disentangled
Representations
17
会議 : F. Locatello, S. Bauer, M. Lucic, G. Raetsch, S. Gelly, B. Sch ̈olkopf, and O. Bachem
著者 : ICML2019 (Best paper)
● Disentangled表現を教師なし学習することは,データとモデルの両方に帰納バイアスを持たないと不可
能であると理論的に証明した.
● Disentangled表現の有用性について大規模実験.
● 実験よりわかったことは
○ Disentanglement Learning におけるハイパラはモデルより重要であり,データセット間に共通す
るよいハイパラもなく,さらにGTがないとよいハイパラとわからない.
○ 学習された表現から変動因子を予測する Downstream task で Disentangled表現が有効である
ことを証明することができなかった.
○ Disentanglement Learning においては実験の再現性が重要であり,そのためのプラットフォーム
を提供した.
■ https://github.com/google-research/disentanglement_lib
Unsupervised Disentanglement Learningの限界
18.
Semi-Supervised StyleGAN forDisentanglement Learning
18
会議 : arXiv:2003.03461
著者 : W. Nie, T. Karras, A. Garg, S. Debhath, A. Patney, A. B. Patel, and A. Anandkumar,
● 前述の研究を踏まえて,semi-, weakly-supervised設定の
disentanglementが注目を集めている.
● 高解像度画像に対するDisentanglement,学習困難性,教師な
し設定でのnon-identifiabilityの問題を,少量のラベルを与える
semi-supervised設定のInfoGAN + StyleGAN で解決
● 実験から,0.25 〜 2.5%のラベルで合成とリアルデータセットで良
いDisentanglementを達成できることが明らかになった.
Semi-supervised Disentanglement Learning
Unsupervised Disentanglement Metric
40
UnsupervisedModel Selection for Variational Disentangled Representation Learning
会議:ICLR 2020
著者:#Sunny_Duan #Loic_Matthey #Andre_Saraiva #Nick_Watters #Chris_Burgess
#Alexander_Lerchner #Irina_Higgins
余談
● Introの冒頭にある一文が非常に印象的な論文でした
Happy families are all alike;
every unhappy family is unhappy in its own way.
ロシアの文豪レフ・トルストイの著作「アンナ・カレーニナ」の冒頭の一文です
直訳は「幸せな家庭はどれも同じように幸せだが、不幸な家庭はそれぞれの行先で不幸である」
これの一文が指していることは恐らく「うまくDisentanglementできているものはロバストに評価できるが
(幸せな家庭はどれも同じように幸せ)、できていないものはseedに振られたりして悪い方向で安定してない
(不幸な家庭はそれぞれの行先で不幸である)」だと思います
DeepMindのNeuro Science研の論文ですが、とても詩的で一度読んでから論文のインパクト然り冒頭の
一文のインパクト然りでお気に入りの論文の一つです
Appllicability to realworld dataset
42
On the Transfer of Inductive Bias from Simulation to the Real World: a New
Disentanglement Dataset
会議:NeurIPS 2019
著者:#Muhammad_Waleed_Gondal #Manuel_Wuthrich #Djordje_Miladinovic
#Francesco_Locatello #Martin_Breidt #Valentin_Volchkov #Joel_Akpo #Olivier_Bachem
#Bernhard_Schölkopf #Stefan_Bauer
Abstract
● 今までのデータセットは所詮トイプロブレムであったので、実データにおいて7つの因子を含むデータ
セットを収集したMPI3Dを提案した.
● データセットはtoy、realistic、realの3つをそれぞれ100万枚以上集めて、転移性についてなどを調査
した.結論使うデータセットがrealisticだとrealにもうまく適用できる
Contribution
● 実世界3Dデータの画像を初めて提案した点
● 集めたデータで帰納バイアスとデータの転移性を調べた点
次ページに続く
43.
Appllicability to realworld dataset
43
On the Transfer of Inductive Bias from Simulation to the Real World: a New
Disentanglement Dataset
会議:NeurIPS 2019
著者:#Muhammad_Waleed_Gondal #Manuel_Wuthrich #Djordje_Miladinovic
#Francesco_Locatello #Martin_Breidt #Valentin_Volchkov #Joel_Akpo #Olivier_Bachem
#Bernhard_Schölkopf #Stefan_Bauer
7つの因子を保持する
ようにロボットアームを
動かして撮影
MPI3D-hogeが集めたデータセット
各100万枚以上収集
realisticが実データに近いsyntheticな
データ
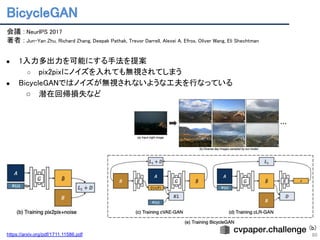
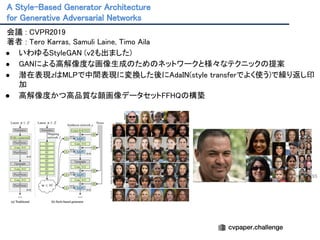
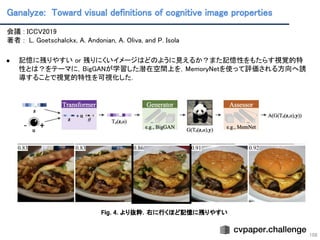
Ganalyze: Toward visualdefinitions of cognitive image properties
108
会議 : ICCV2019
著者 : L. Goetschalckx, A. Andonian, A. Oliva, and P. Isola
● 記憶に残りやすい or 残りにくいイメージはどのように見えるか?また記憶性をもたらす視覚的特
性とは?をテーマに,BigGANが学習した潜在空間上を,MemoryNetを使って評価される方向へ誘
導することで視覚的特性を可視化した.
Fig. 4. より抜粋.右に行くほど記憶に残りやすい
109.
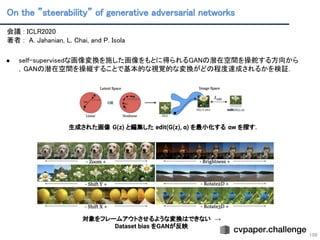
On the ”steerability”of generative adversarial networks
109
会議 : ICLR2020
著者 : A. Jahanian, L. Chai, and P. Isola
● self-supervisedな画像変換を施した画像をもとに得られるGANの潜在空間を操舵する方向から
,GANの潜在空間を操縦することで基本的な視覚的な変換がどの程度達成されるかを検証.
生成された画像 G(z) と編集した edit(G(z), α) を最小化する αw を探す.
対象をフレームアウトさせるような変換はできない →
Dataset bias をGANが反映
110.
Controlling generative models
with continuous factors of variations
110
会議 : ICLR2020
著者 : A. Plumerault, H. L. Borgne, and C. Hudelot
● 生成モデルの潜在空間上から,物体の位置やスケールなどの特性を制御可能にする方向を見つ
ける方法を提案.GANalyze や GAN Steerability との違いは,
○ Gが再現不可能な高周波数画像成分を低減する再構成誤差
○ 潜在空間の軌跡の候補を再帰的に生成した後,方向を決定するモデルを学習
○ Saliency detectionによる定量評価
111.
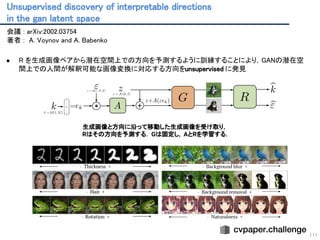
Unsupervised discovery ofinterpretable directions
in the gan latent space
111
会議 : arXiv:2002.03754
著者 : A. Voynov and A. Babenko
● R を生成画像ペアから潜在空間上での方向を予測するように訓練することにより,GANの潜在空
間上での人間が解釈可能な画像変換に対応する方向をunsupervised に発見
生成画像と方向に沿って移動した生成画像を受け取り,
Rはその方向を予測する. Gは固定し,AとRを学習する.




























































![Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks
(CycleGAN)
68
会議 : ICCV2017
著者 : Jun-Yan Zhu, Taesung Park, Phillip Isola, Alexei A. Efros
[Abst]
・ペアの訓練データがない場合の画像変換を行った
・逆写像とCycle-conistency Lossを用いて元画像を復元できるように学習させた
[Results]
・色やテクスチャに関する変換は成功した
・形状変化を伴う変換はうまくいかなかった
(a)
https://arxiv.org/abs/1703.10593](https://image.slidesharecdn.com/ganfightersvariousthemefinaltrue-200503145608/85/Generative-Models-68-320.jpg)
![DualGAN: Unsupervised Dual Learning for Image-to-Image Translation
69
会議 : ICCV2017
著者 : Zili Yi, Hao Zhang, Ping Tan, and Minglun Gong
[Abst]
・2つのドメインのラベル付けされていない2つのセットから画像変換を学習できるようにした
・既存のGANはドメイン→ドメインへの変換を学習、Dual GANはドメイン⇄ドメインを学習するようにした
[Results]
・他のGANの出力よりも鮮明な変換ができた
・アーキテクチャは基本的にCycleGANと同じ(CycleGANの方が論文投稿が先)
(a)
https://arxiv.org/abs/1704.02510](https://image.slidesharecdn.com/ganfightersvariousthemefinaltrue-200503145608/85/Generative-Models-69-320.jpg)
![Unsupervised Image-to-Image Translation Networks
70
会議 : NIPS2017
著者 : Ming-Yu Liu, Thomas Breuel, Jan Kautz
[Abst]
・潜在空間が共通するという仮定のもとに教師なしimage-to-imageのフレームワークを提案
・VAEとCoupled GANを組み合わせたアーキテクチャでドメイン毎にEncoder, Generator, Discriminator
がある
[Results]
・複数のデータセットで画像変換を実行できた
・鞍点探索の問題により学習が不安定になる場合がある
(a)https://arxiv.org/abs/1703.00848](https://image.slidesharecdn.com/ganfightersvariousthemefinaltrue-200503145608/85/Generative-Models-70-320.jpg)
![TuiGAN: Learning Versatile Image-to-Image Translation with Two
Unpaired Images
71
会議 : arXiv2020
著者 : Jianxin Lin, Yingxue Pang, Yingce Xia, Zhibo Chen, Jiebo Luo
[Abst]
・UI2Iを2つのUnpairな画像のみで可能にした
・ドメイン間の分布の変化を効果的にキャプチャするためにSinGANのように粗い画像から
細かい画像へと段階的に変換する手法を採用
[Results]
・CycleGANよりは良い結果が得られていないような記述
・極めてデータが少ないケースの教師なし学習のきっかけになりそう
(a)
https://arxiv.org/abs/2004.04634](https://image.slidesharecdn.com/ganfightersvariousthemefinaltrue-200503145608/85/Generative-Models-71-320.jpg)


![従来では解決されていない問題点が徐々に解決されつつある
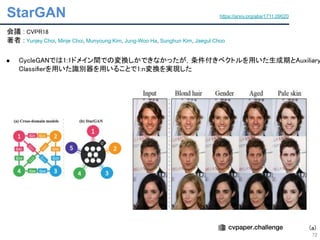
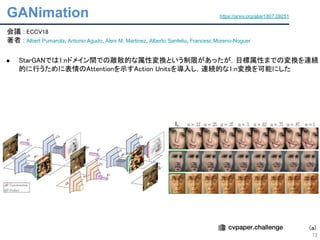
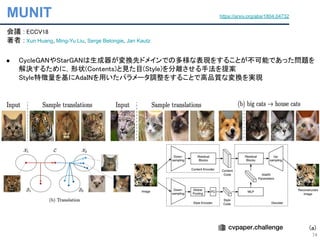
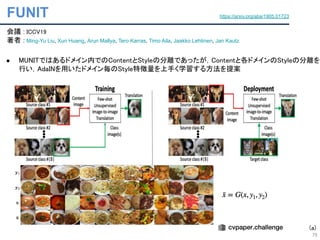
● CycleGAN[ICCV17].Pix2Pix[CVPR17]で1:1ドメイン間の変換が提案された
● StarGAN[CVPR18]で1:nドメイン間の変換が提案された
● MUNIT[ECCV18]で1:1ドメイン間の変換だが,変換先を操作できるような機構が提案された
● FUNIT[ICCV19]でStarGANより多クラス間の参照画像を用いた変換が提案された
● RelGAN[ICCV19]でより補完性の高いドメイン間の変換が提案された
● StarGANv2[CVPR20]で従来より圧倒的に綺麗な参照画像を用いた変換が提案された
(a)物体変換の発展
78
● 実験に使用されるデータセットはCelebAの人の顔や動物の顔でしか行われ
ていない問題
● 実際にデモを動かしてみるとうまくいかないサンプルなどの存在
● 学習時間が長すぎる問題
● まだまだ取り組める課題は多い
● 画像生成モデルであるStyleGANを上手に利用した研究との融合
(a)](https://image.slidesharecdn.com/ganfightersvariousthemefinaltrue-200503145608/85/Generative-Models-78-320.jpg)





















![Walking in the GAN Latent Space
107
GANは潜在空間上の2点間の滑らかな内挿が可能
この性質を使うことで,
GANの解釈性の改善とGANの制御性の検証ができる
このトピックでは
特定の画像変換に対応する潜在空間上の方向を
- 教師ありで [Goetschalckx+ 2019]
- 自己教師で [Jahanian+ 2020], [Plumerault+ 2020]
- 教師なしで [Voynov+ 2020]
発見する手法を調査](https://image.slidesharecdn.com/ganfightersvariousthemefinaltrue-200503145608/85/Generative-Models-107-320.jpg)








![SSII2021 [OS2-02] 深層学習におけるデータ拡張の原理と最新動向](https://cdn.slidesharecdn.com/ss_thumbnails/os2-03latest-210610045610-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]Focal Loss for Dense Object Detection](https://cdn.slidesharecdn.com/ss_thumbnails/focalloss-180208092846-thumbnail.jpg?width=640&height=640&fit=bounds)






![[DL輪読会]Vision Transformer with Deformable Attention (Deformable Attention Tra...](https://cdn.slidesharecdn.com/ss_thumbnails/dl0114-220114032933-thumbnail.jpg?width=640&height=640&fit=bounds)





![[DL輪読会]Learning Latent Dynamics for Planning from Pixels](https://cdn.slidesharecdn.com/ss_thumbnails/taniguchi20181221-190104064850-thumbnail.jpg?width=640&height=640&fit=bounds)




![[DL輪読会]Temporal DifferenceVariationalAuto-Encoder](https://cdn.slidesharecdn.com/ss_thumbnails/20181130new-190205051636-thumbnail.jpg?width=640&height=640&fit=bounds)

![SSII2021 [OS2-01] 転移学習の基礎:異なるタスクの知識を利用するための機械学習の方法](https://cdn.slidesharecdn.com/ss_thumbnails/os2-02final-210610091211-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]Wasserstein GAN/Towards Principled Methods for Training Generative Adv...](https://cdn.slidesharecdn.com/ss_thumbnails/wgan-1-170224021826-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]Life-Long Disentangled Representation Learning with Cross-Domain Laten...](https://cdn.slidesharecdn.com/ss_thumbnails/20180914iwasawa-180919025635-thumbnail.jpg?width=640&height=640&fit=bounds)












![[DL Hacks 実装]Representation Learning by Rotating Your Faces](https://cdn.slidesharecdn.com/ss_thumbnails/representaitonlearningbyrotatingyourface1-171120115059-thumbnail.jpg?width=640&height=640&fit=bounds)





