Download as PDF, PPTX










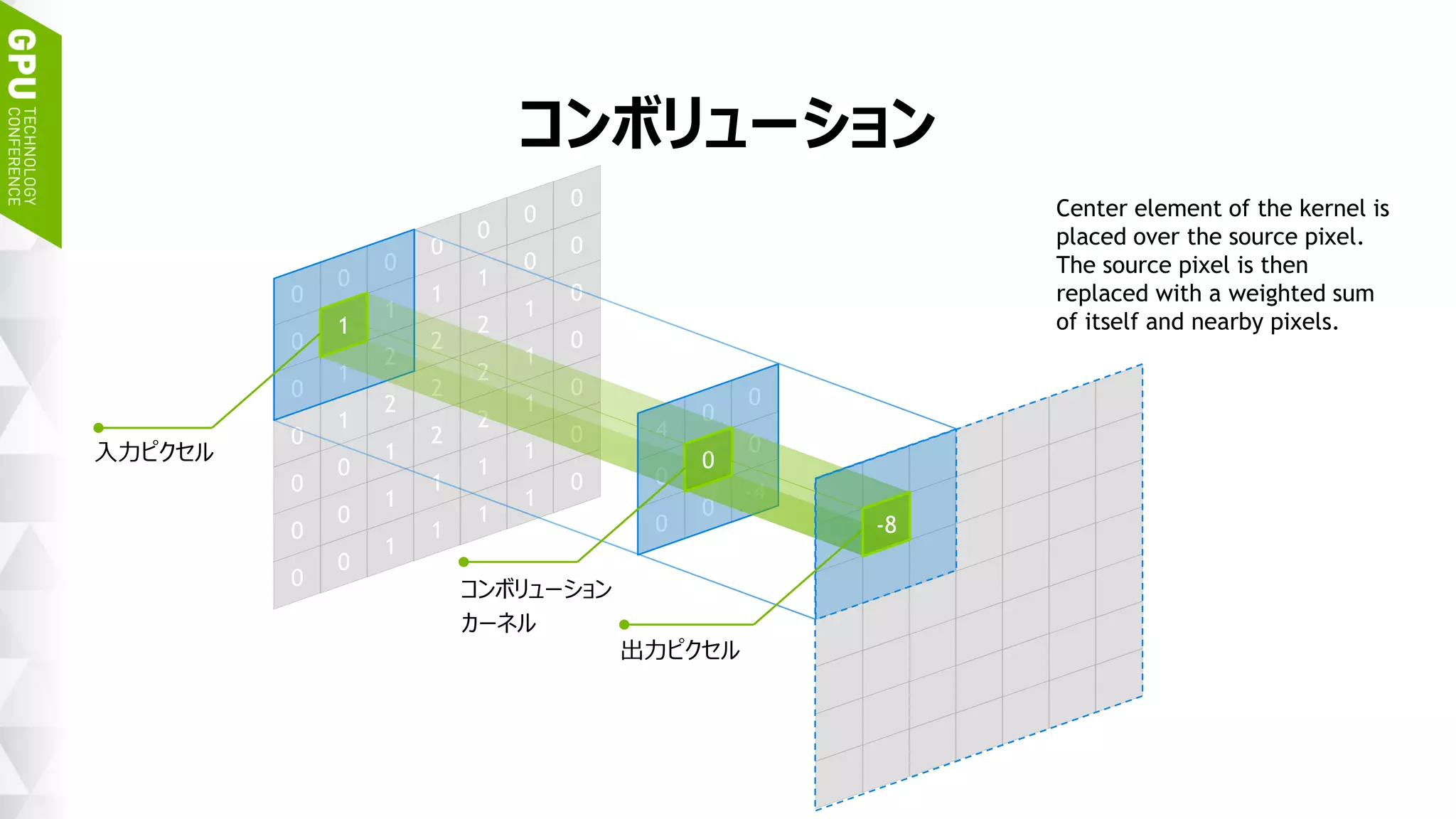


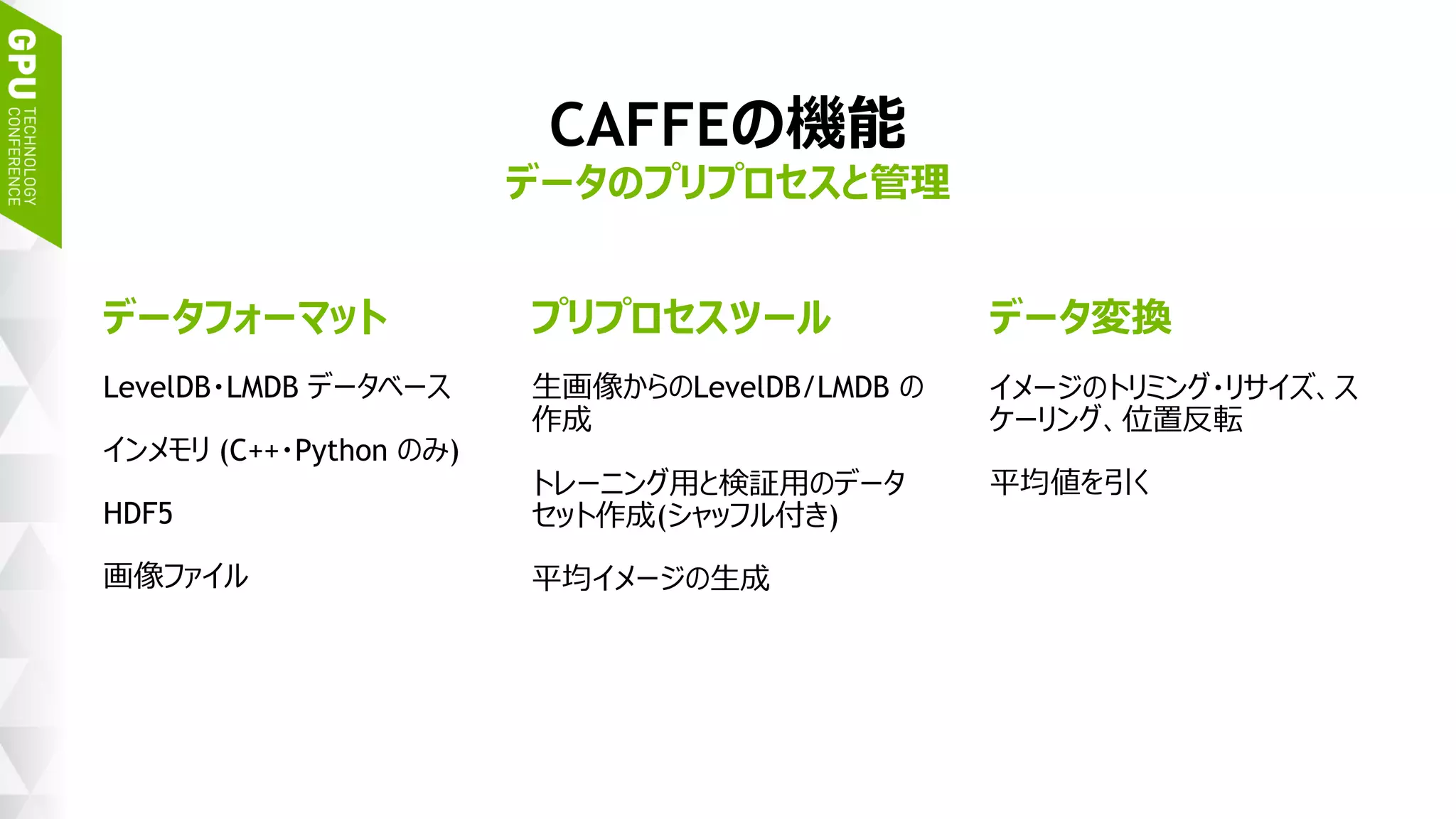




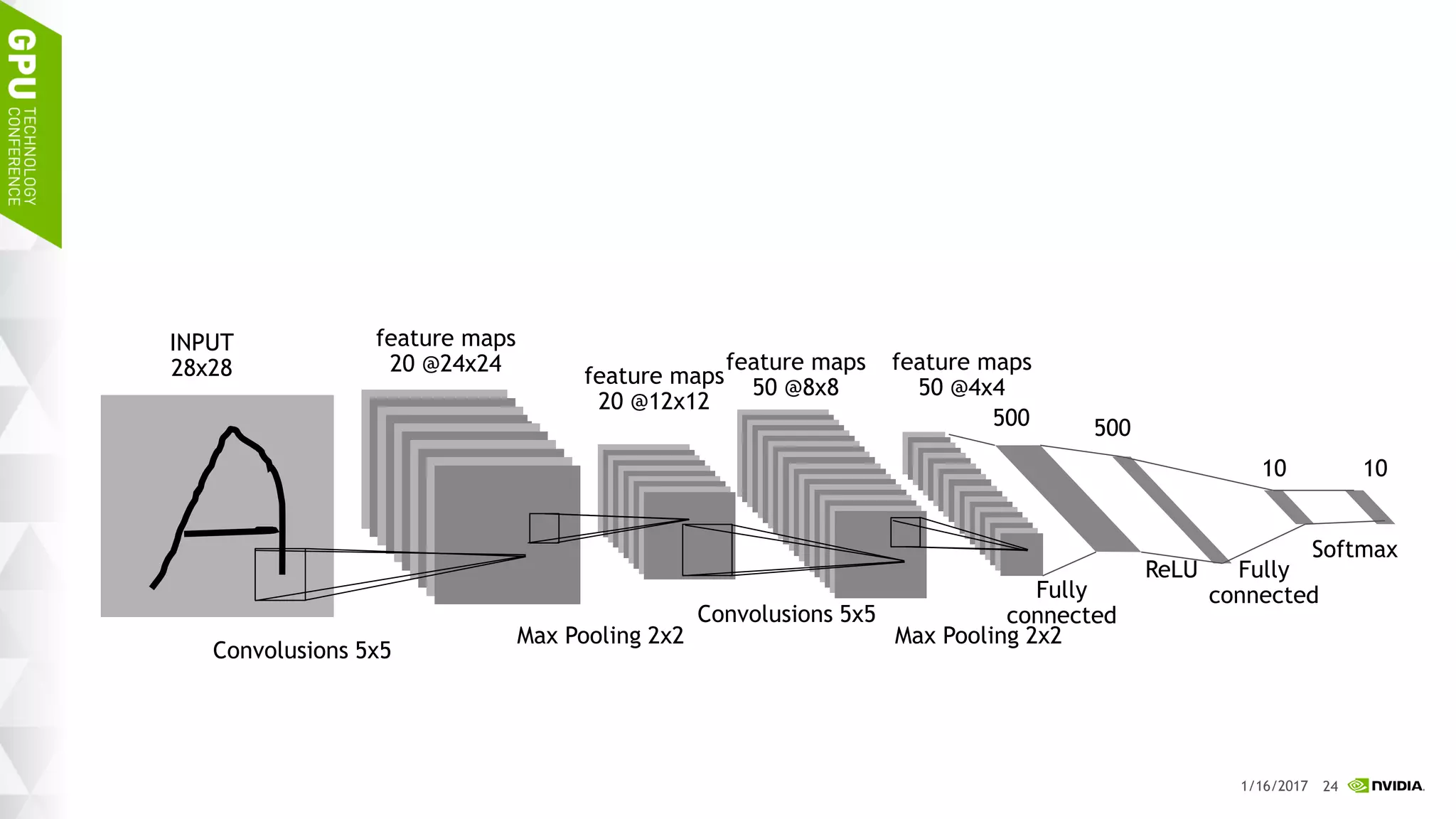
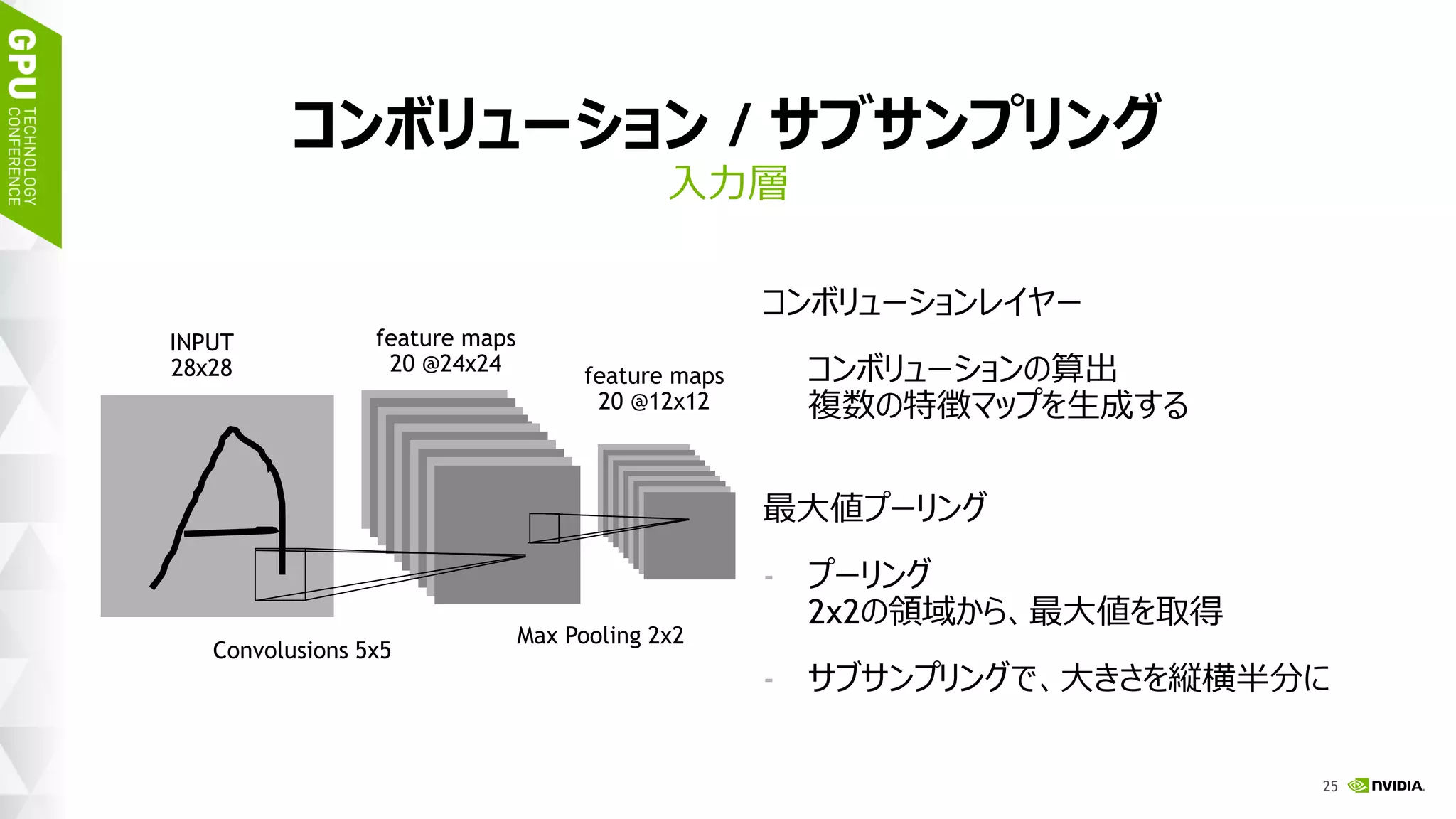





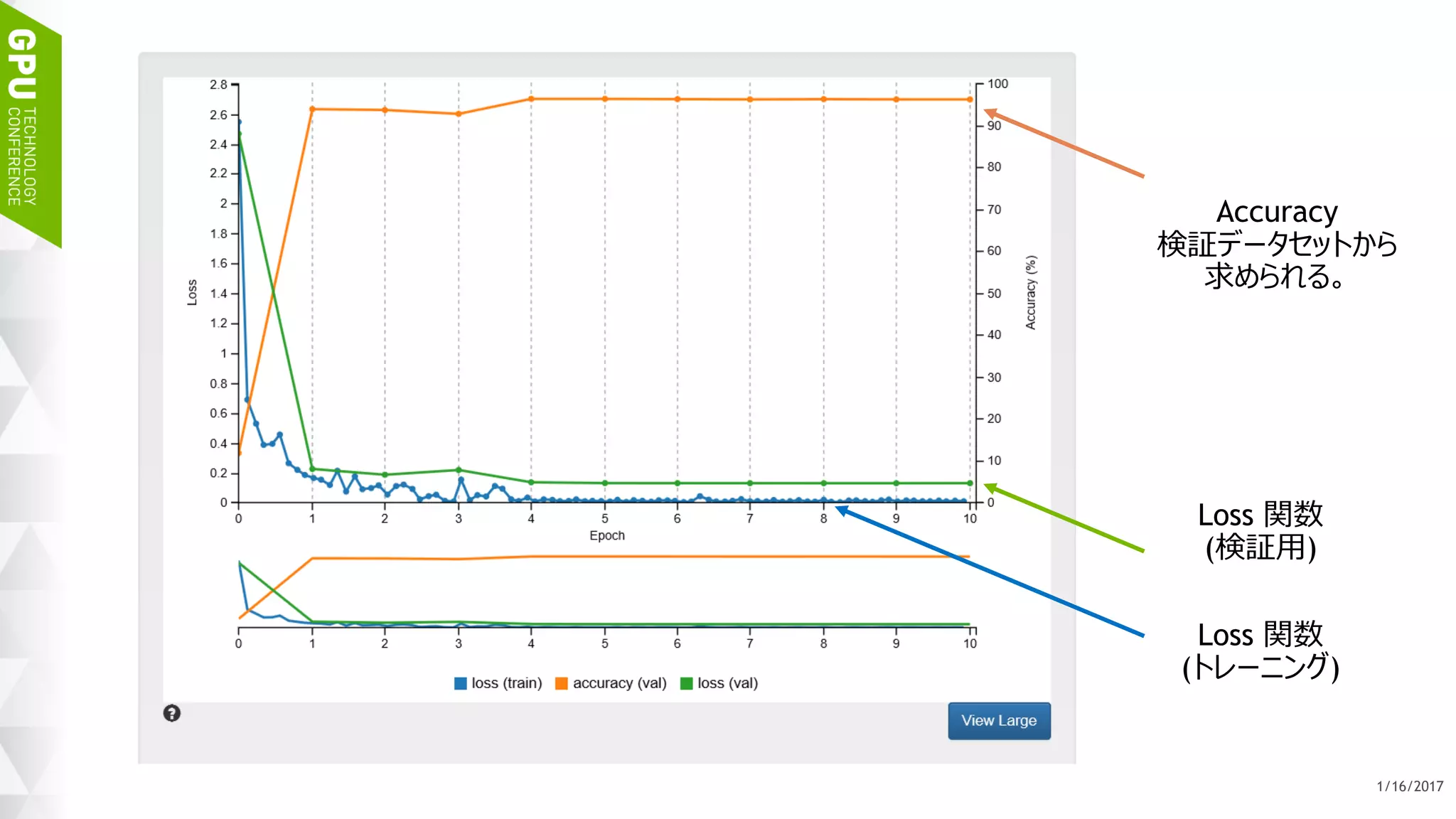
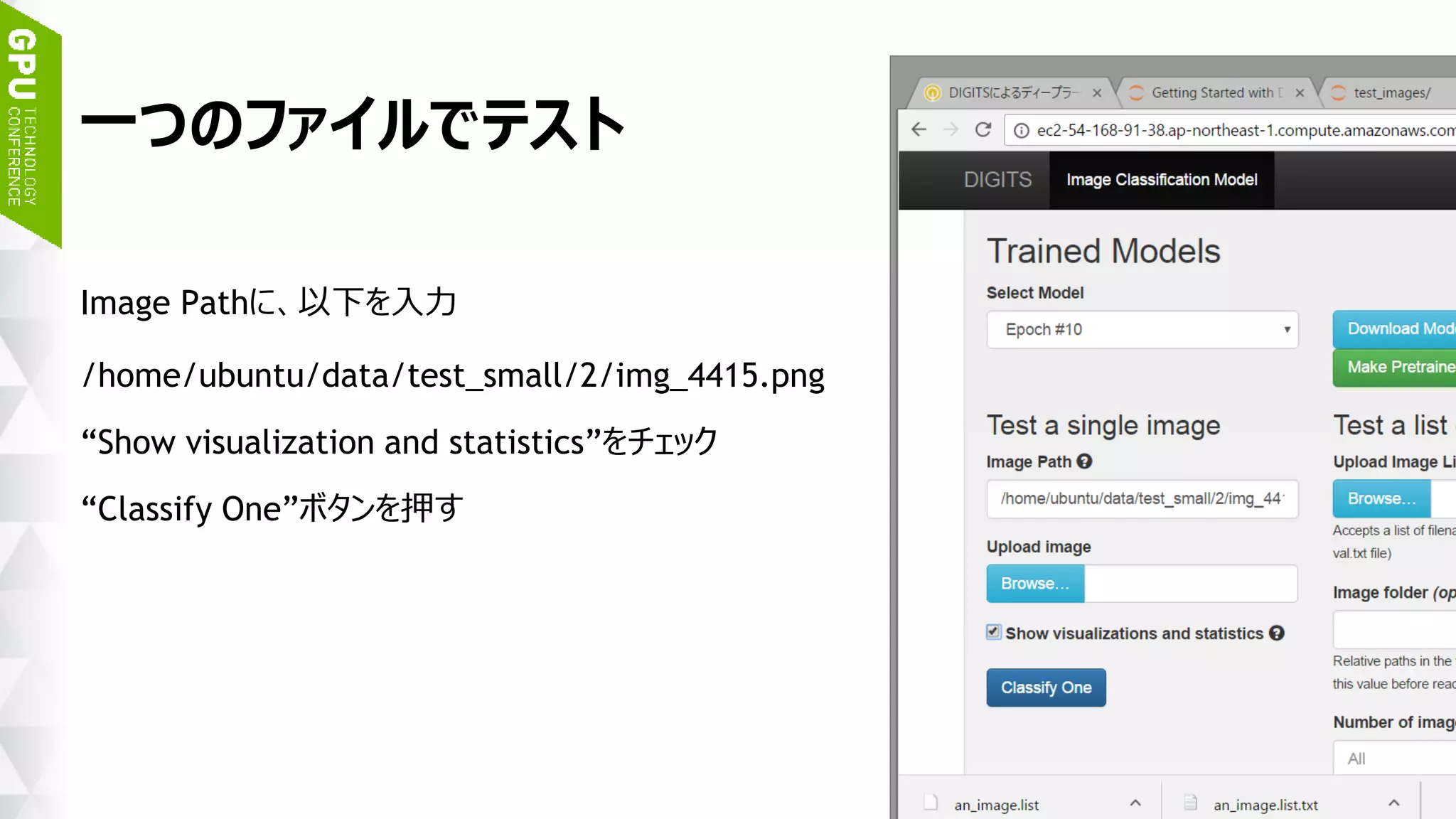
![45
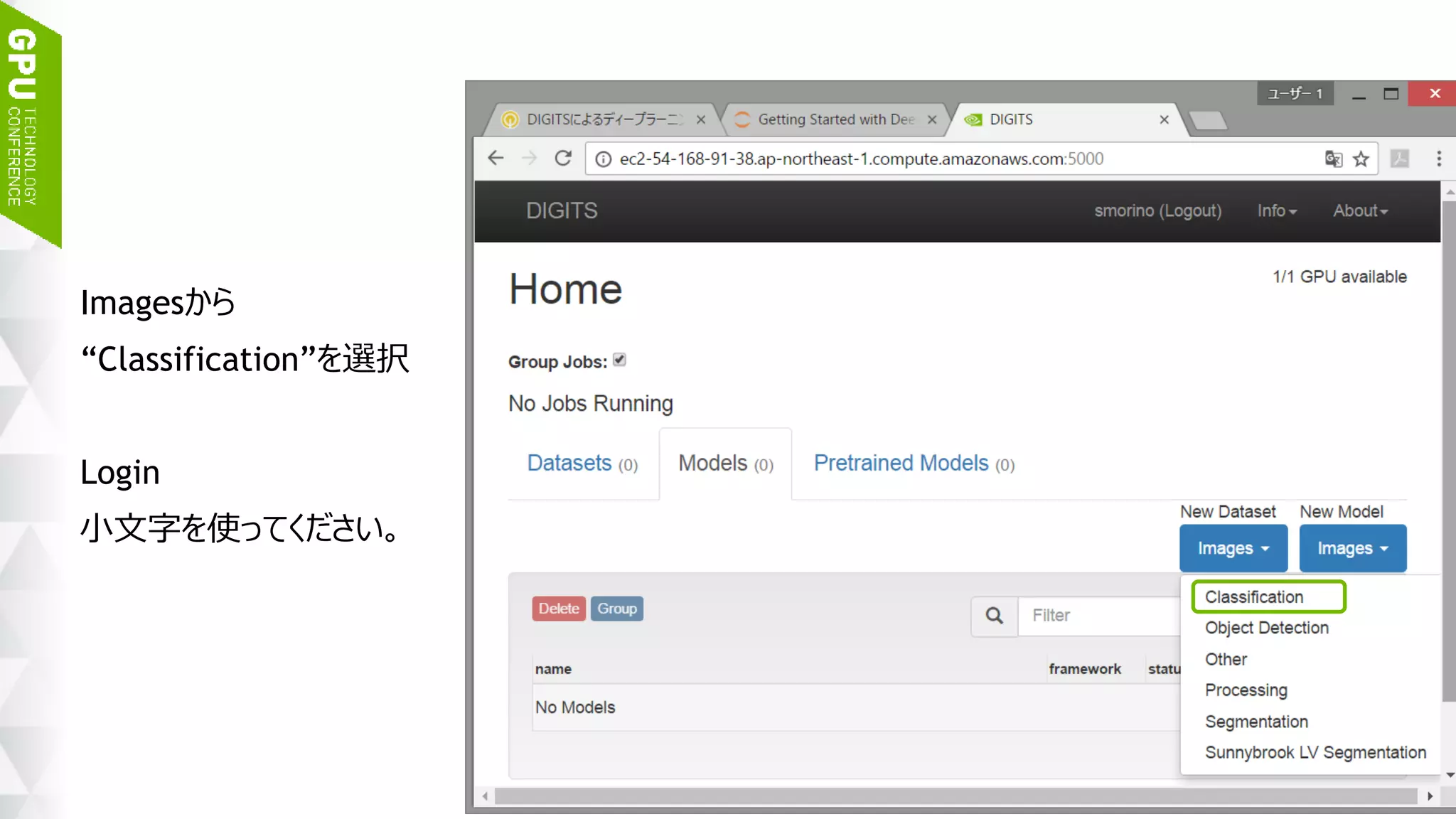
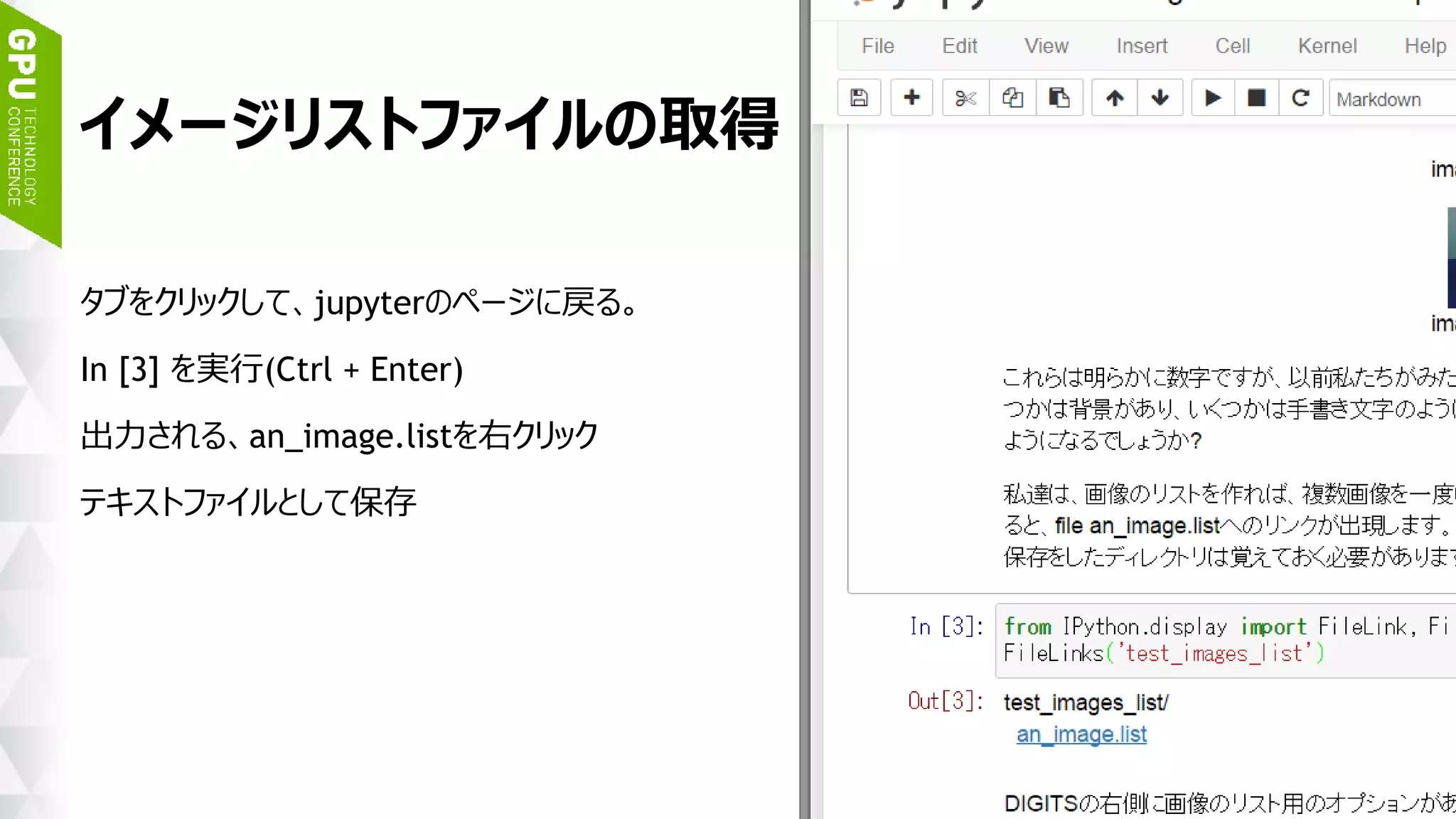
イメージリストファイルの取得
jupyterのページに戻る。
In [3] を実行(Ctrl + Enter)
出力される、an_image.listを右クリック
「テキストファイル」 として保存](https://image.slidesharecdn.com/20170117gettingstartedwithdeeplearning-170116231451/75/DIGITS-40-2048.jpg)

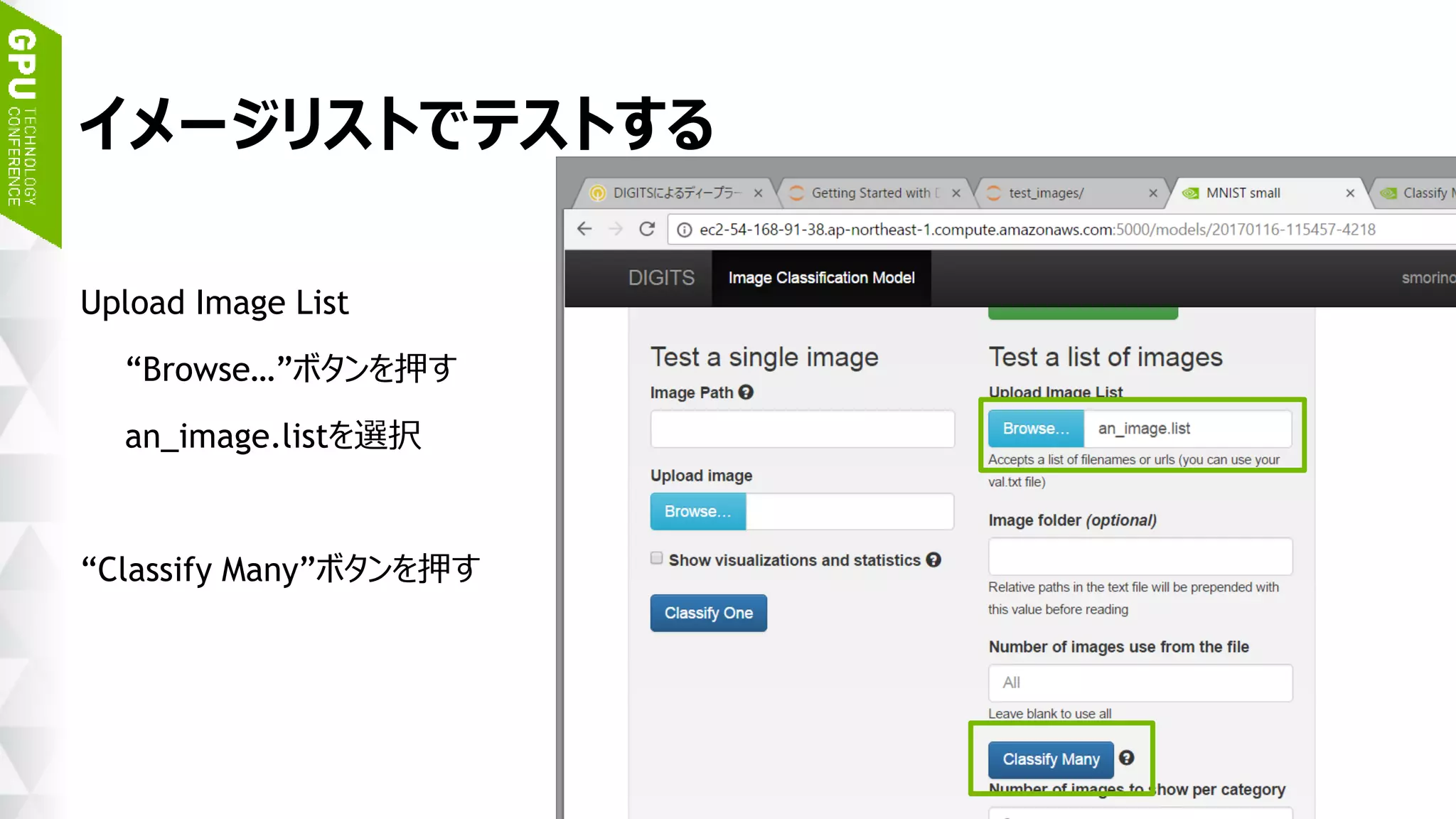
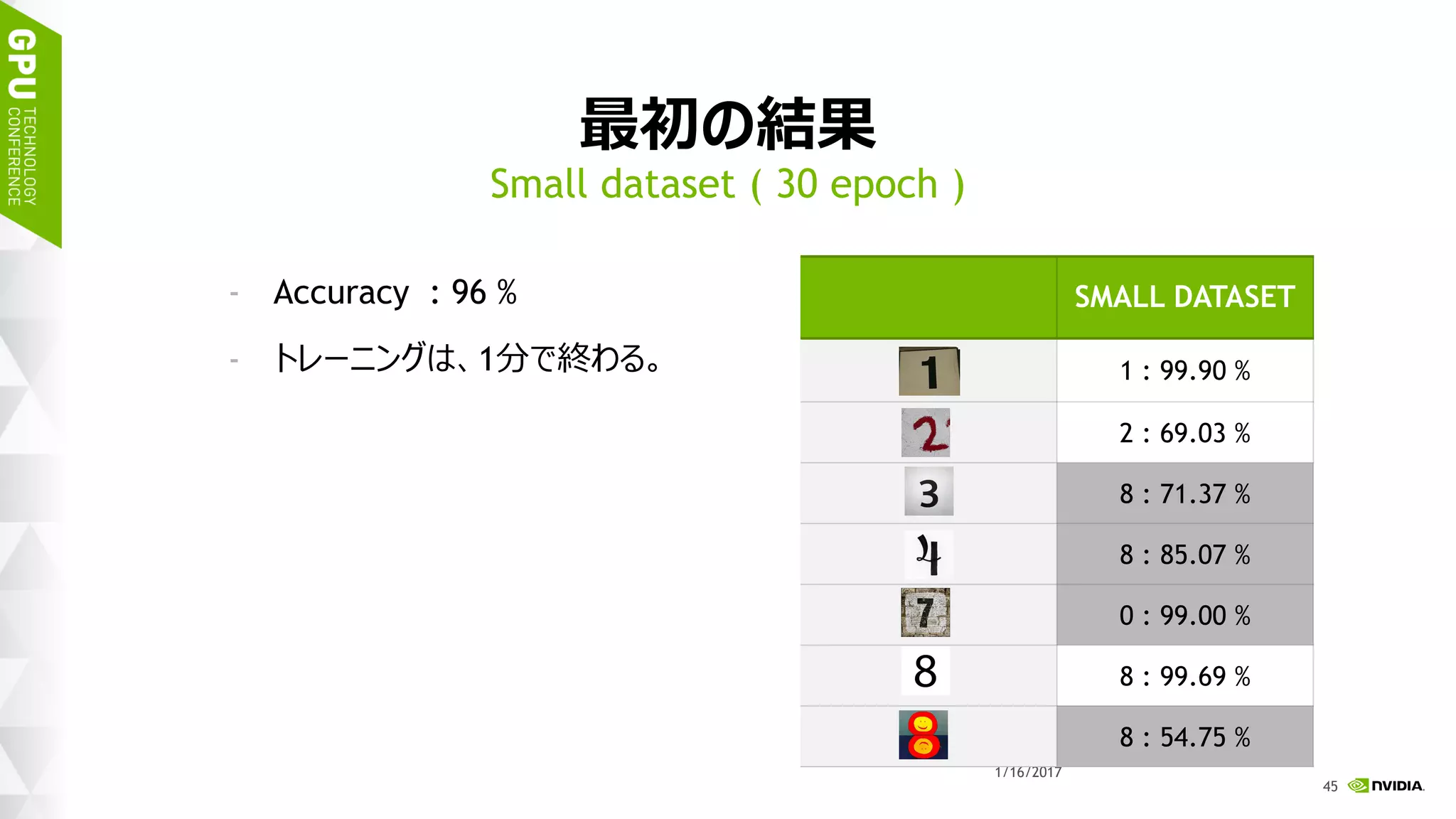

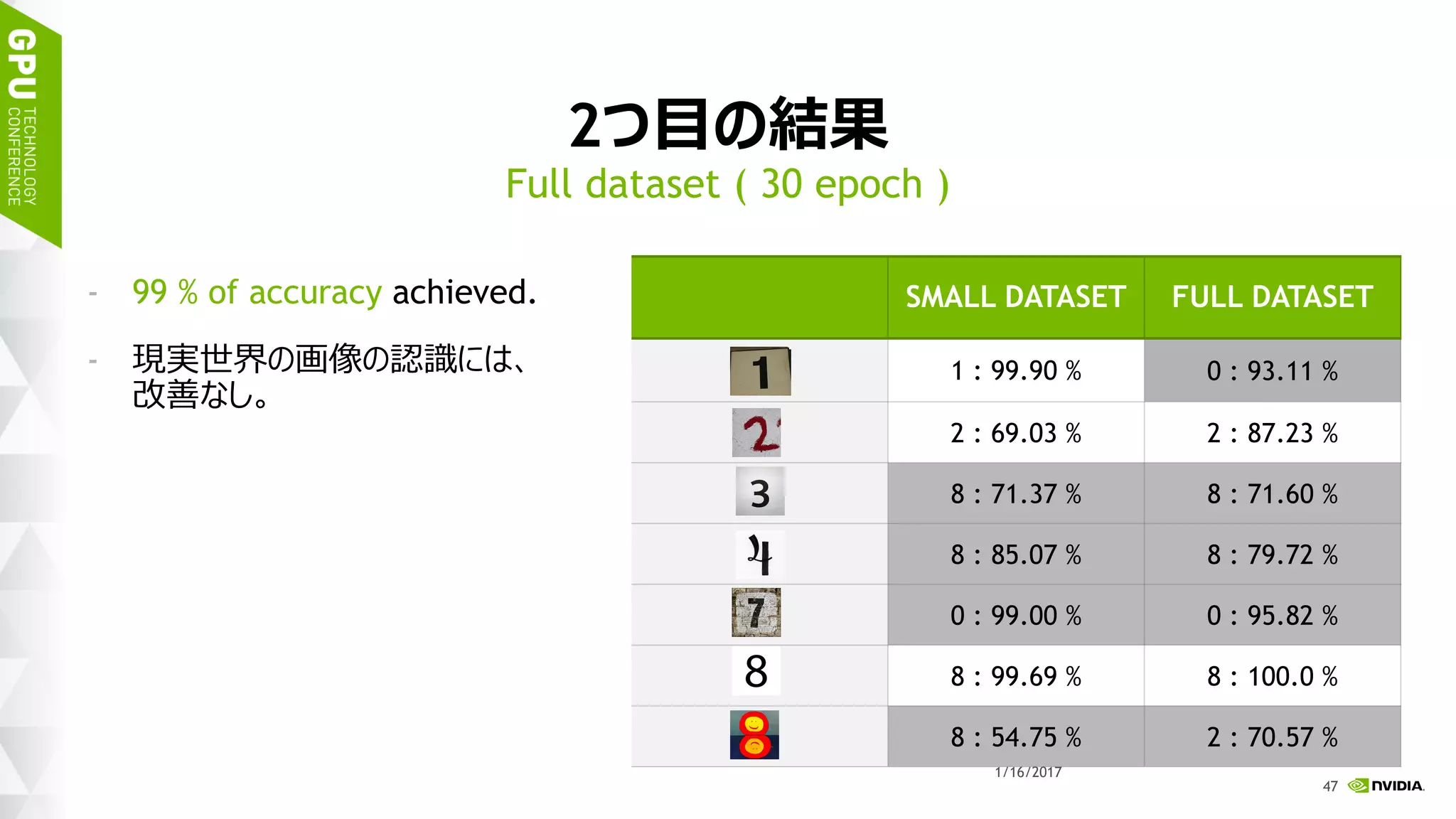

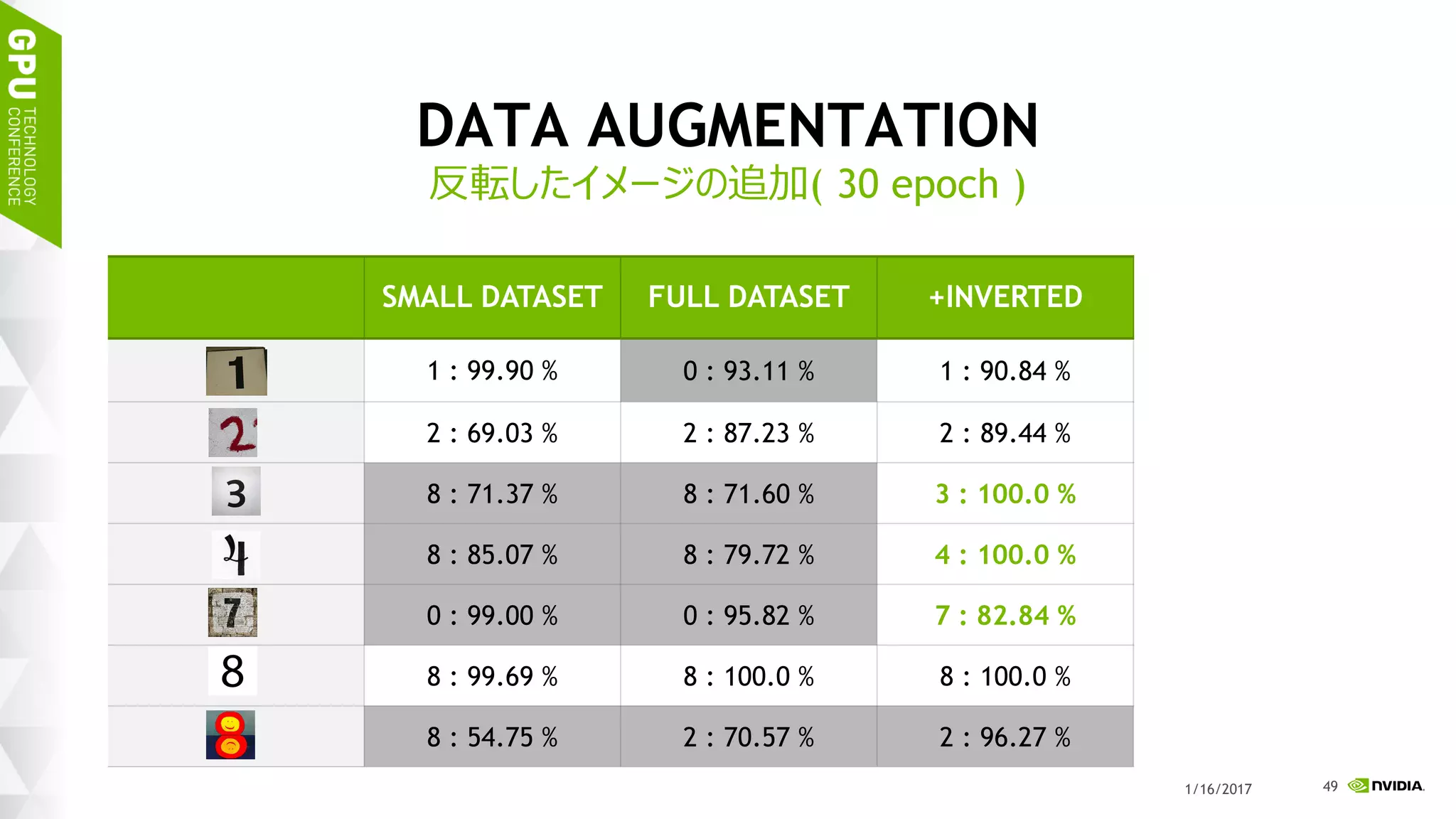
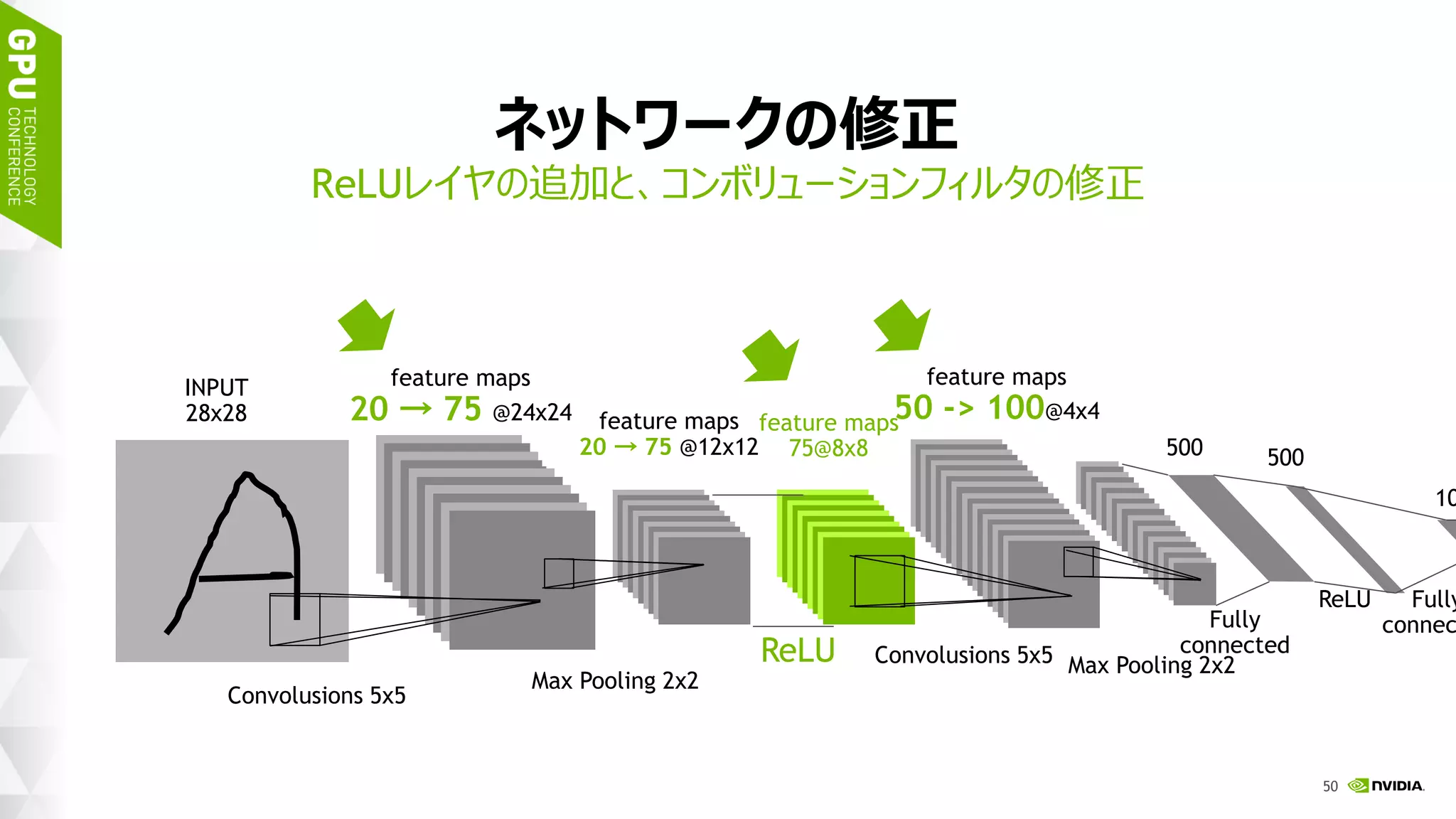



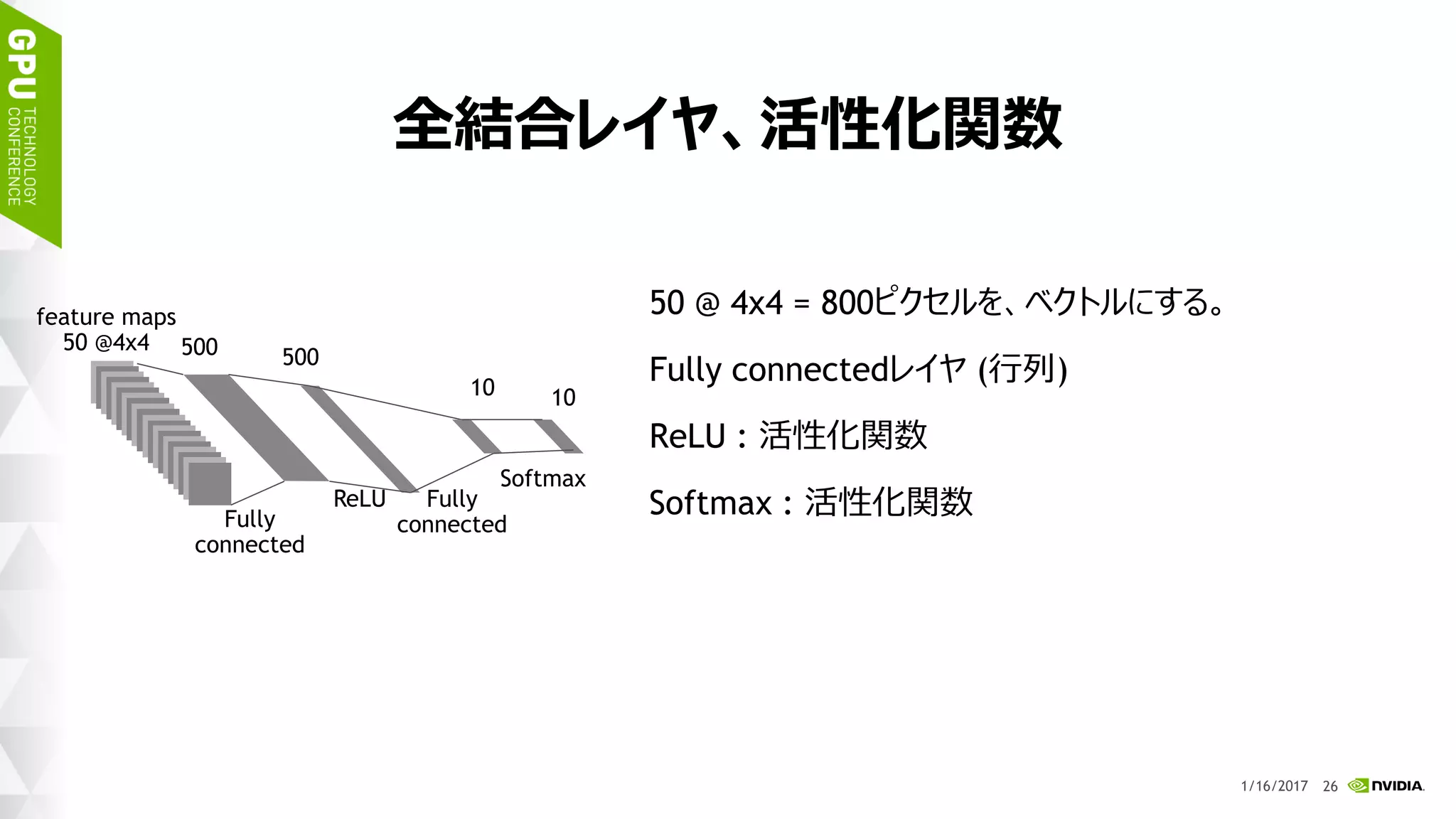
このスライドは 2017 年 1 月 17 日 (火)、ベルサール高田馬場で開催された「NVIDIA Deep Learning Institute 2017」のハンズオン トレーニング、「DIGITS で始めるディープラーニング画像分類」にて、エヌビディア合同会社 ディープラーニング部 森野 慎也が講演したものです。 このハンズオン トレーニングでは NVIDIA DIGITS を用いて、ディープ ニューラル ネットワークを用いた画像分類を実現するためのワークフローを体験します。内容として、最初に、データの前処理、ネットワークモデルの定義、学習、検証など、一連のトレーニング (学習) に関するワークフローを通して実行します。加えて、画像分類の精度を向上するために、データ拡大 (data augmentation) を試みます。学習には、GPU を用います。 このハンズオン トレーニングを受講することにより、NVIDIA DIGITS を用い、画像分類を行うために、ディープ ニューラル ネットワークをトレーニングすることができるようになります。


































![SSII2022 [TS3] コンテンツ制作を支援する機械学習技術〜 イラストレーションやデザインの基礎から最新鋭の技術まで 〜](https://cdn.slidesharecdn.com/ss_thumbnails/ts32022ssiiess-220607054523-e80be8dc-thumbnail.jpg?width=640&height=640&fit=bounds)









![[論文紹介] Convolutional Neural Network(CNN)による超解像](https://cdn.slidesharecdn.com/ss_thumbnails/cnn-presen-161218113749-thumbnail.jpg?width=640&height=640&fit=bounds)


































