1
DEEP LEARNING JP
[DLPapers]
http://deeplearning.jp/
"Deep Face Recognition: A Survey"
Mei Wang, Weihong Deng
Presentater: Koichiro Tamura, Matsuo Lab. M2
2.
書誌情報
• タイトル: DeepFace Recognition: A Survey
• https://arxiv.org/abs/1804.06655
• Submitted on 18 Apr 2018 (v1), last revised 28 Sep 2018 (this version, v7)
• 著者: Mei Wang, Weihong Deng
• 顔認識にまつわる研究をまとめたサーベイ論文
• DLによるFace Recognition(FR)のAlgorithmsおよびloss functionの研究の発展に関する体系的な整理
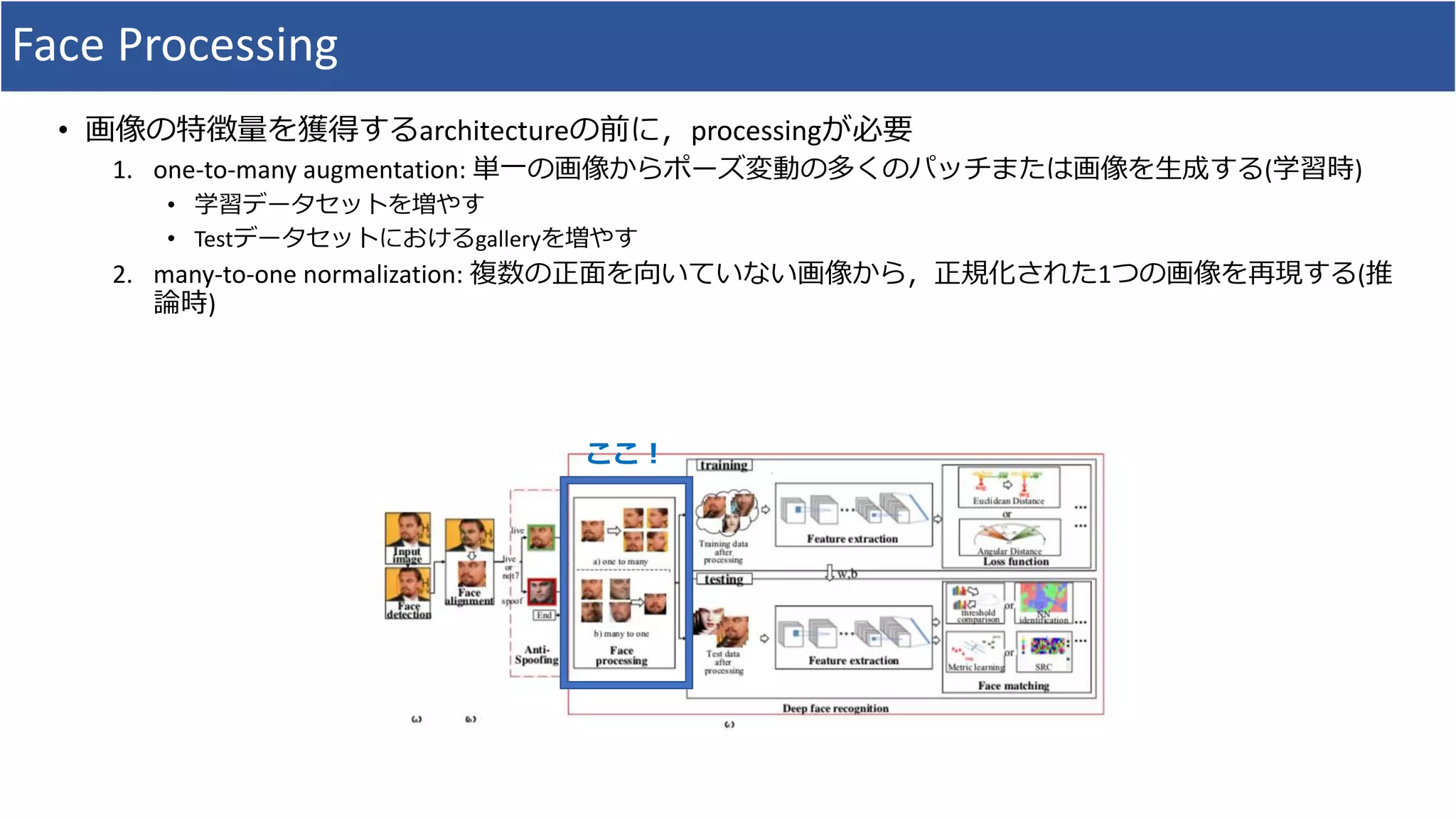
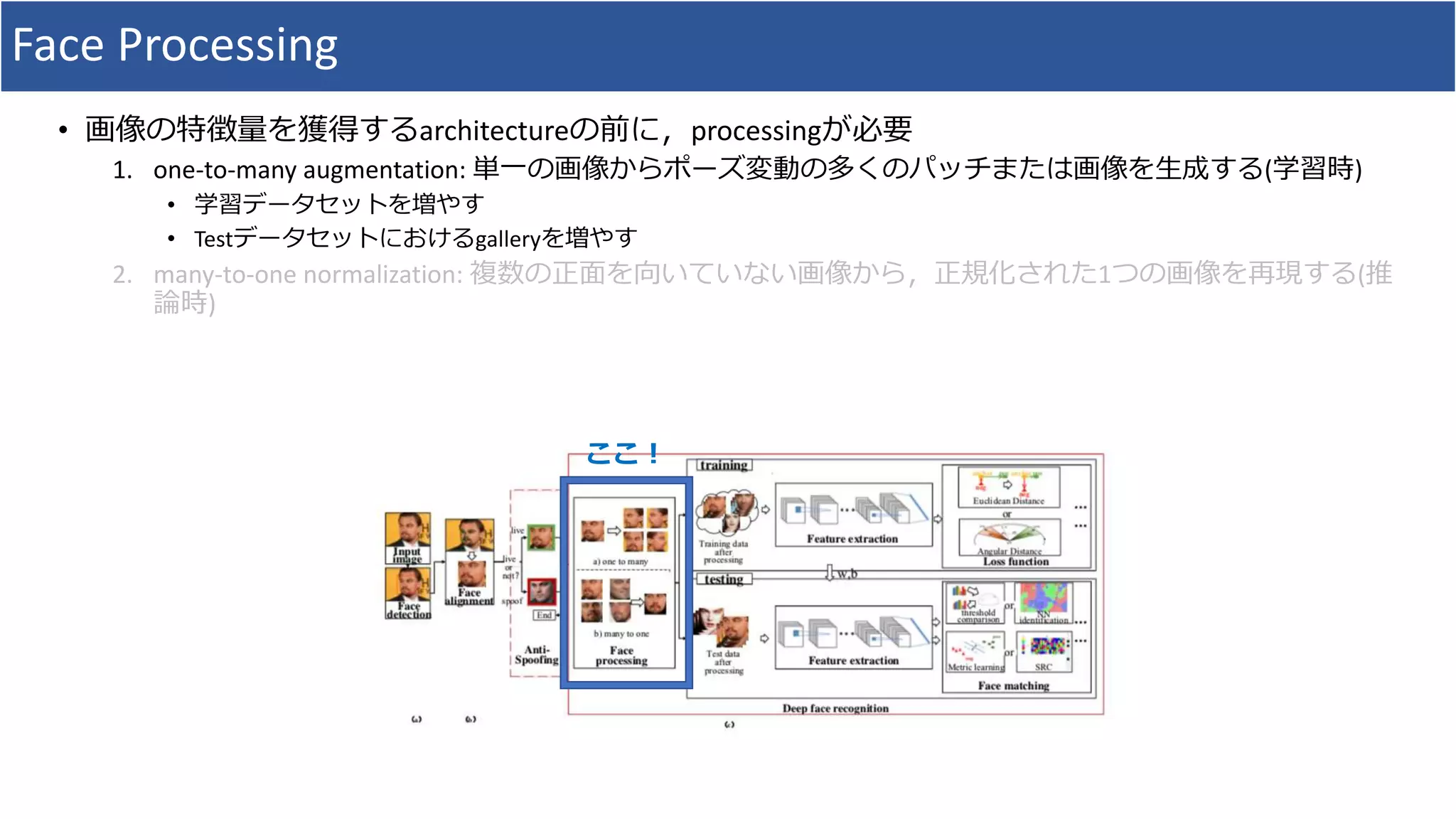
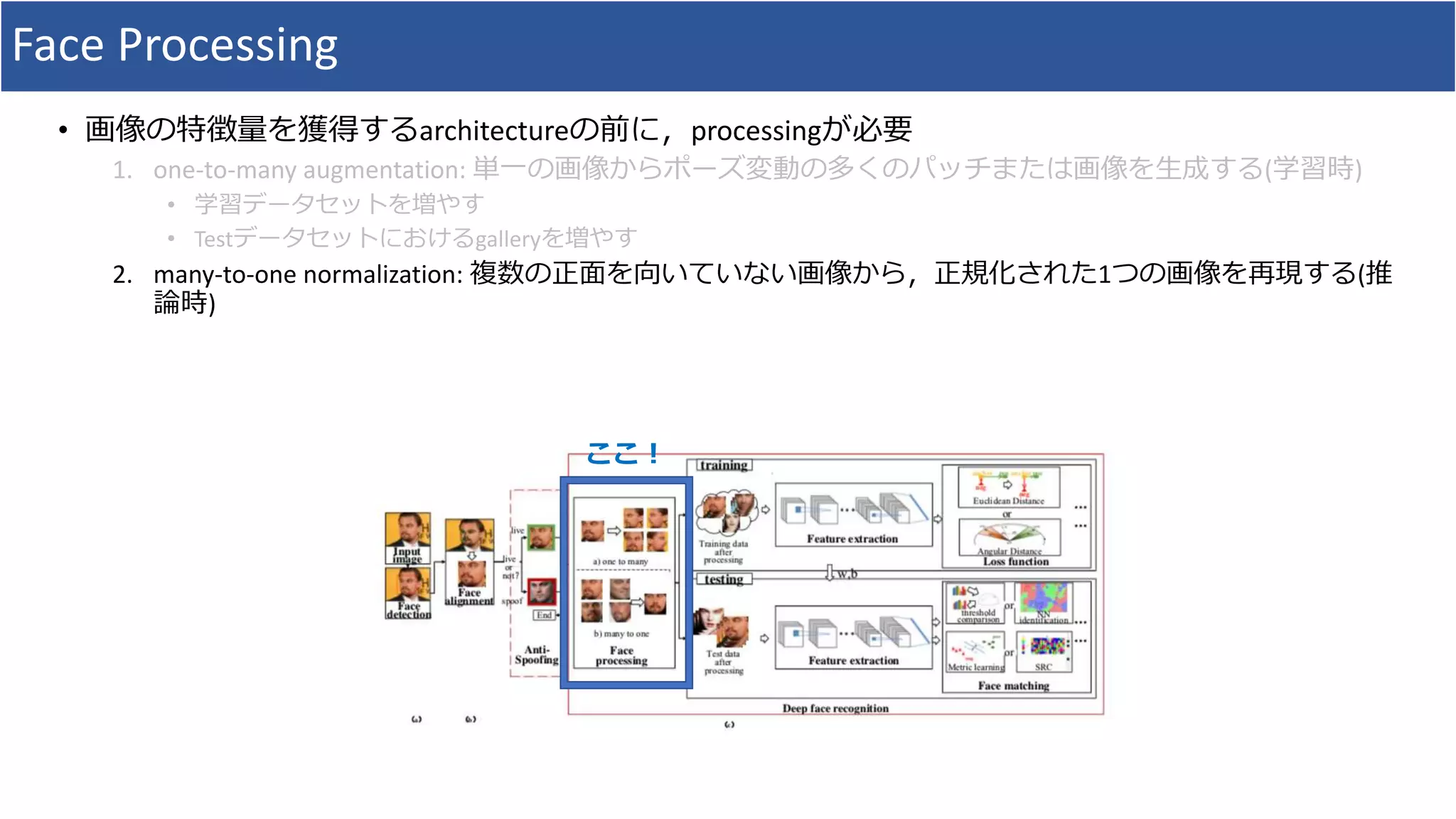
• Face Processingにおいて,「one-to-many augmentation」と「many-to-one normalization」の研究における
体系的整理
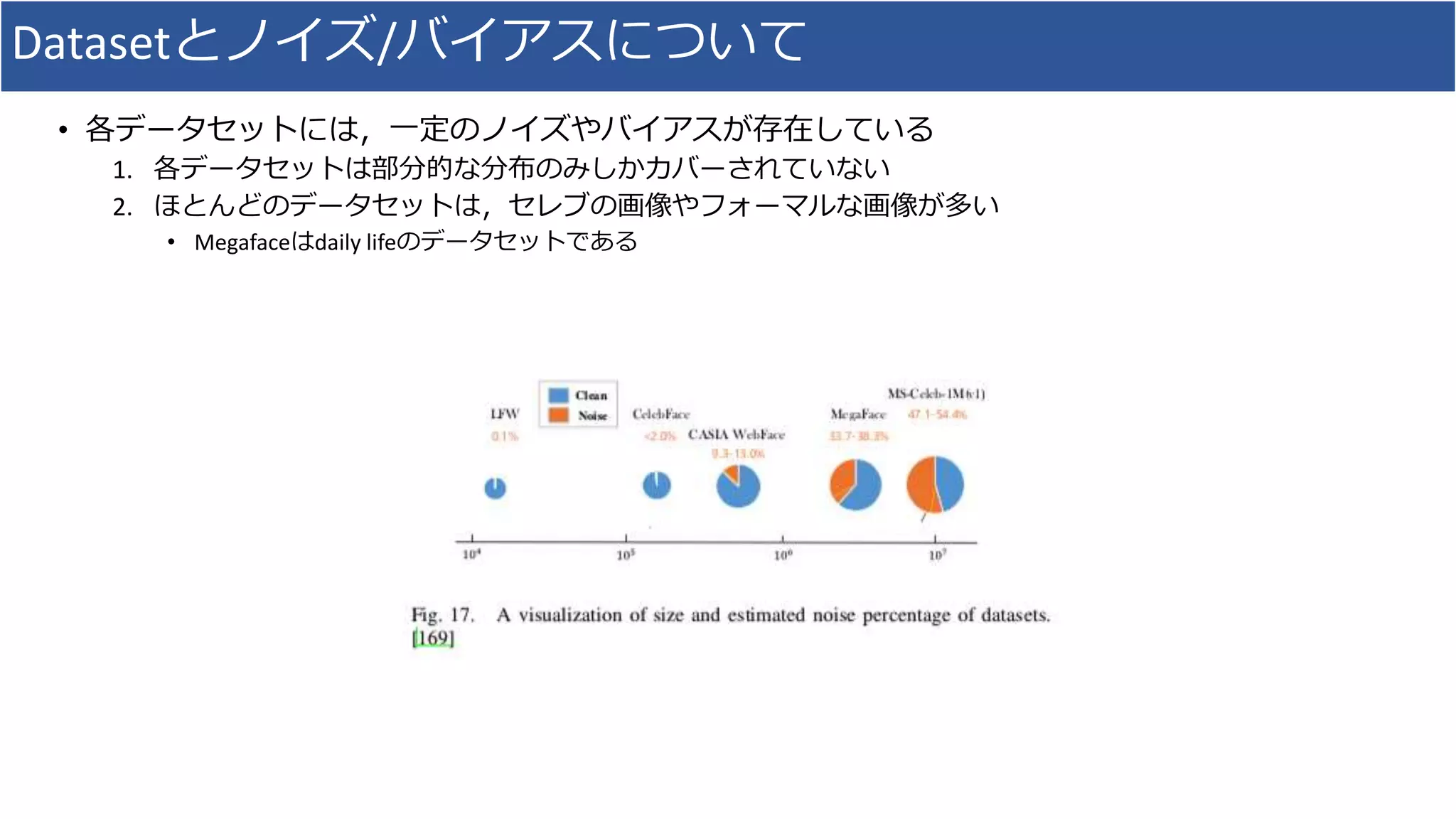
• データセットとおよび訓練・評価のプロトコルの整理
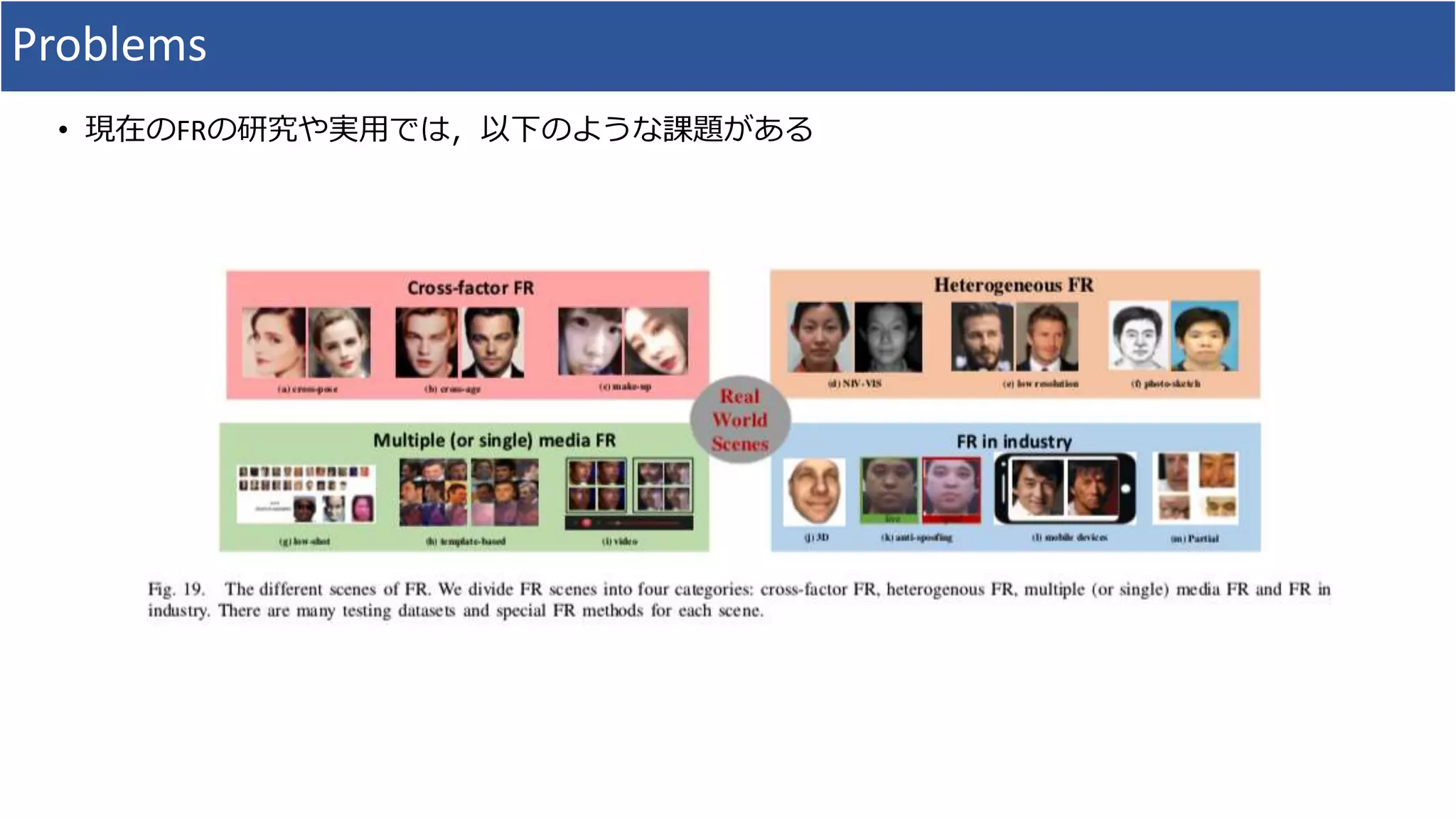
• Anti-spoofingをはじめとした12の課題の提示
3.
目次 *論文と構成を少し変えています
1. Background
2.Components and Definition
3. Network architecture & Loss function
4. Face processing
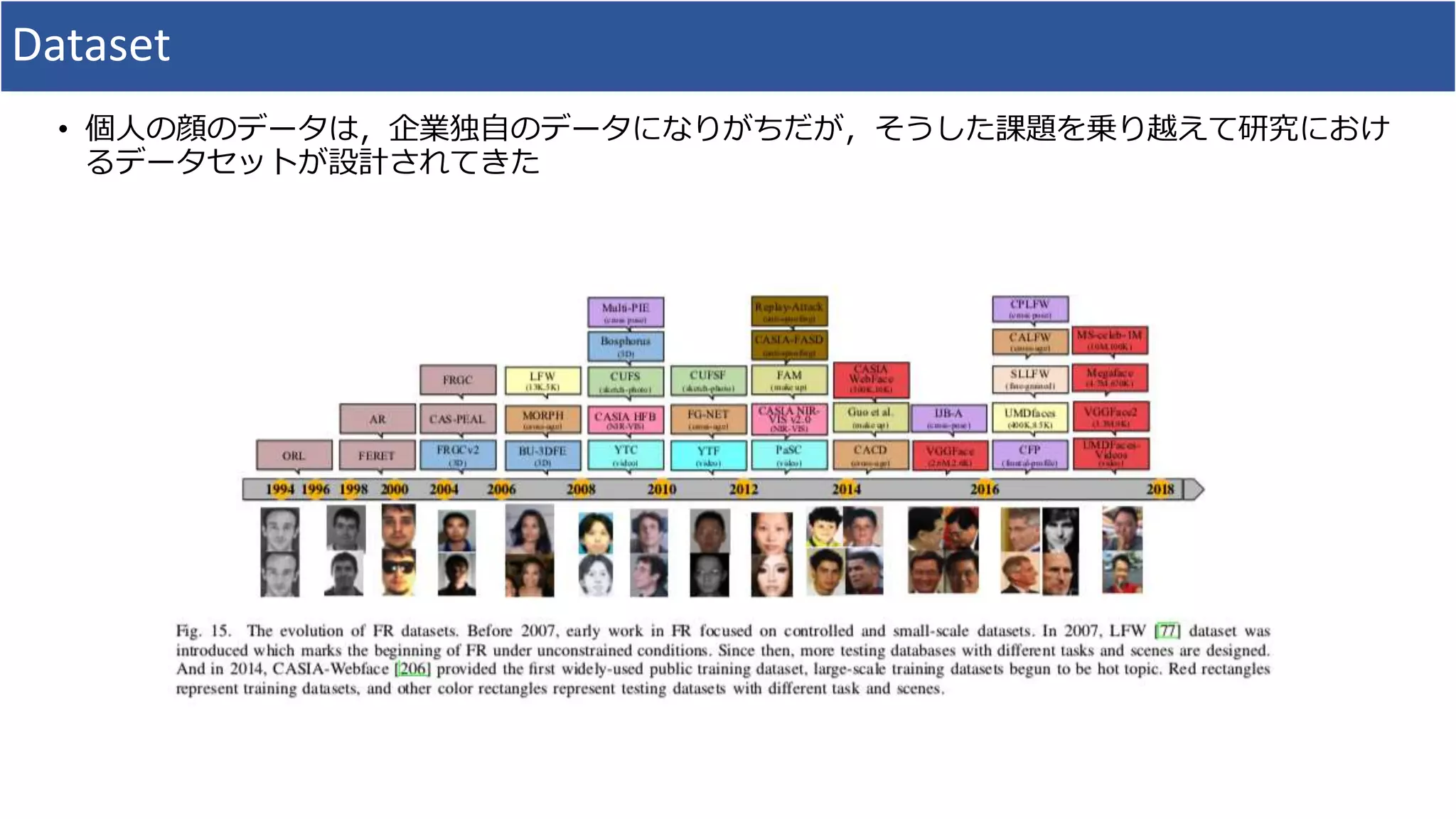
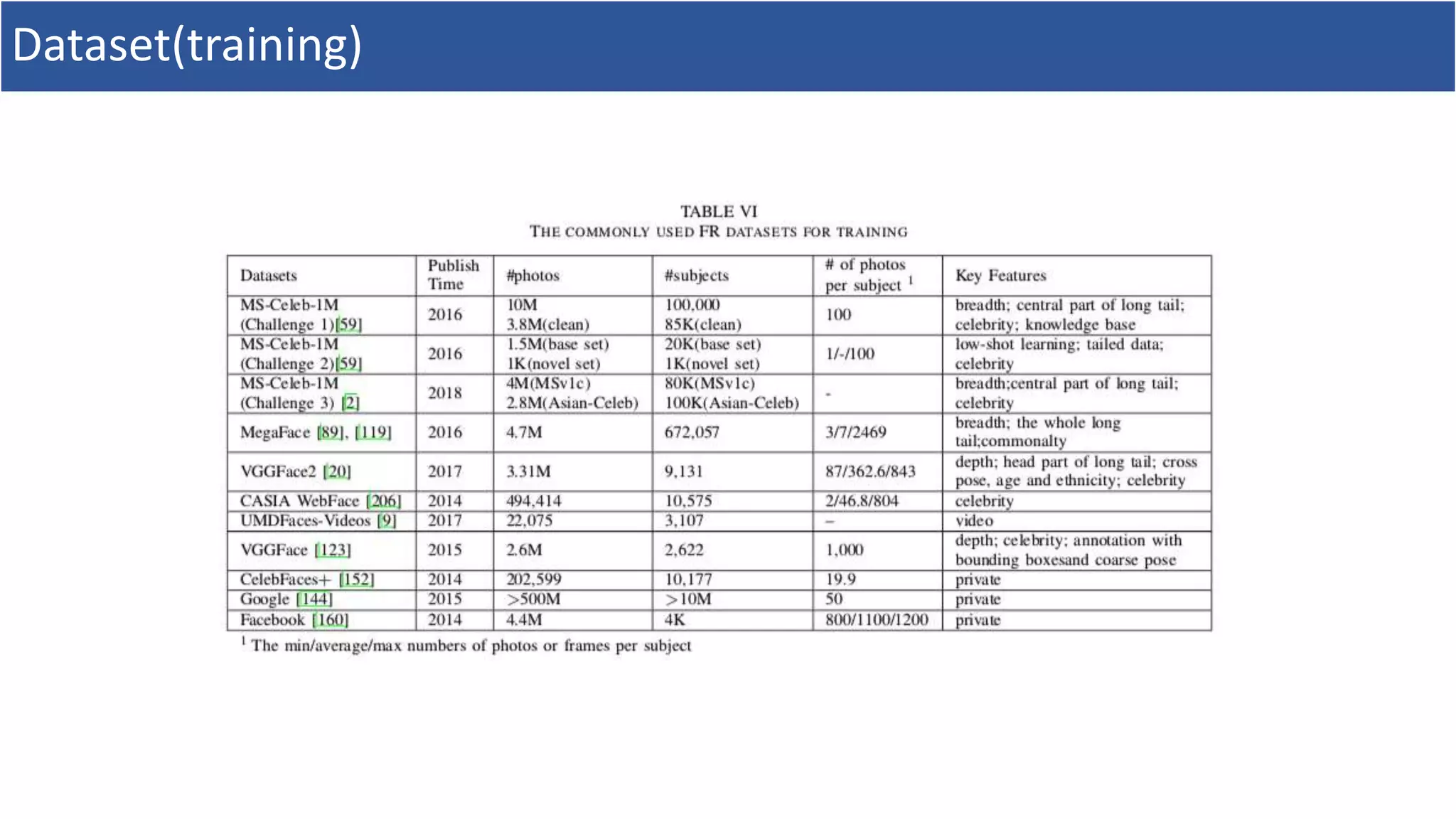
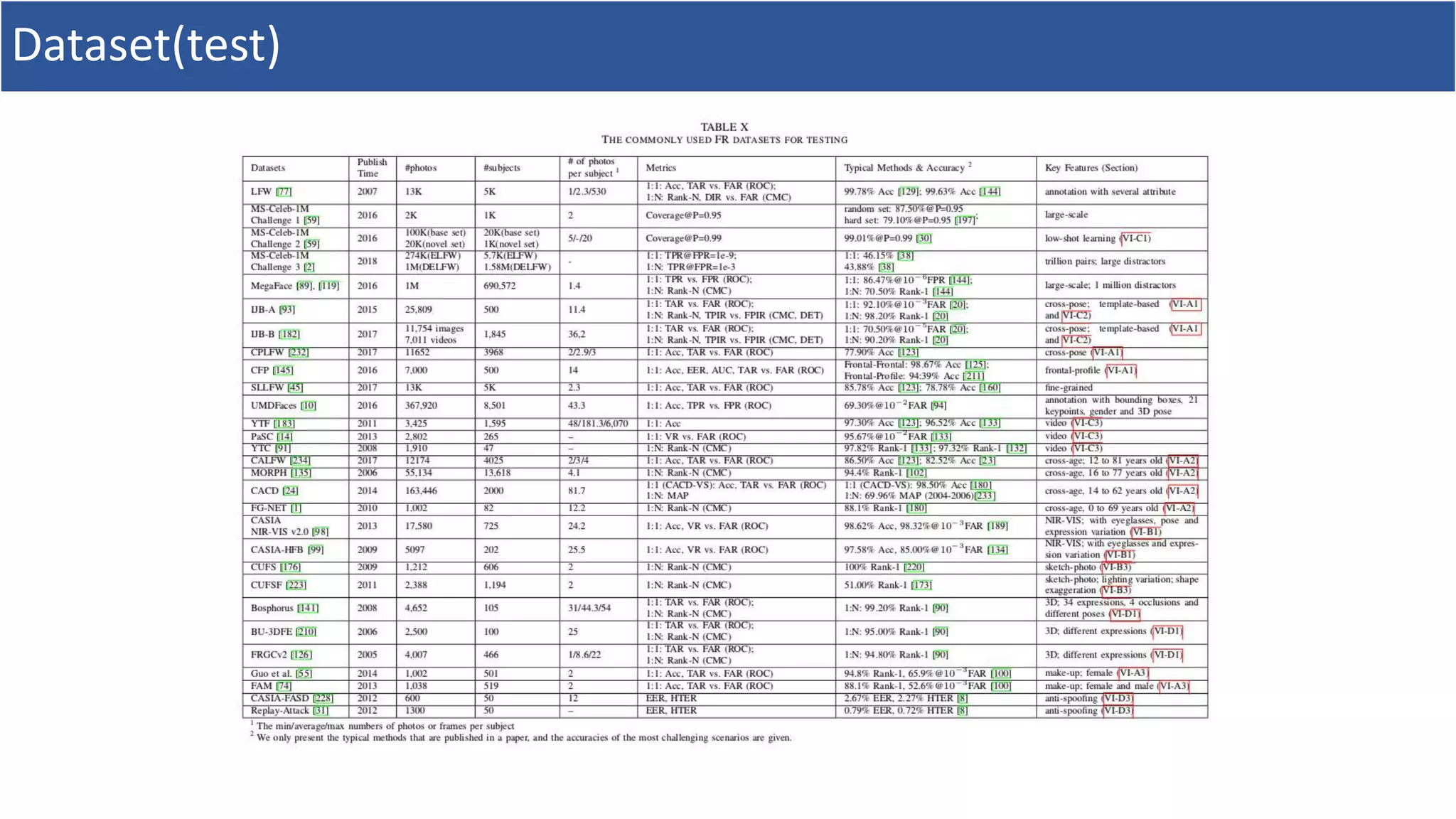
5. Dataset
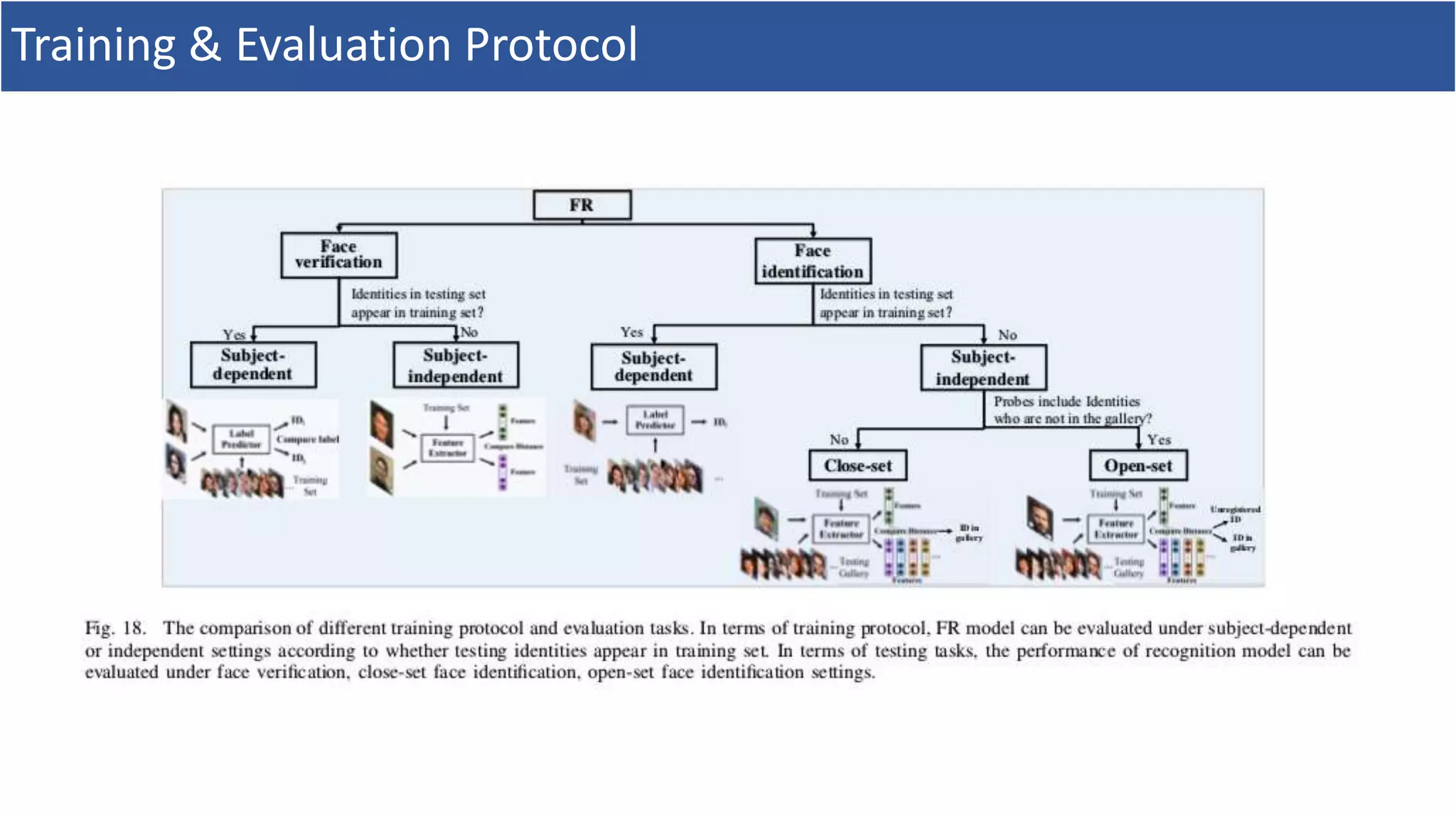
6. Training & Evaluation Protocol
7. Problems
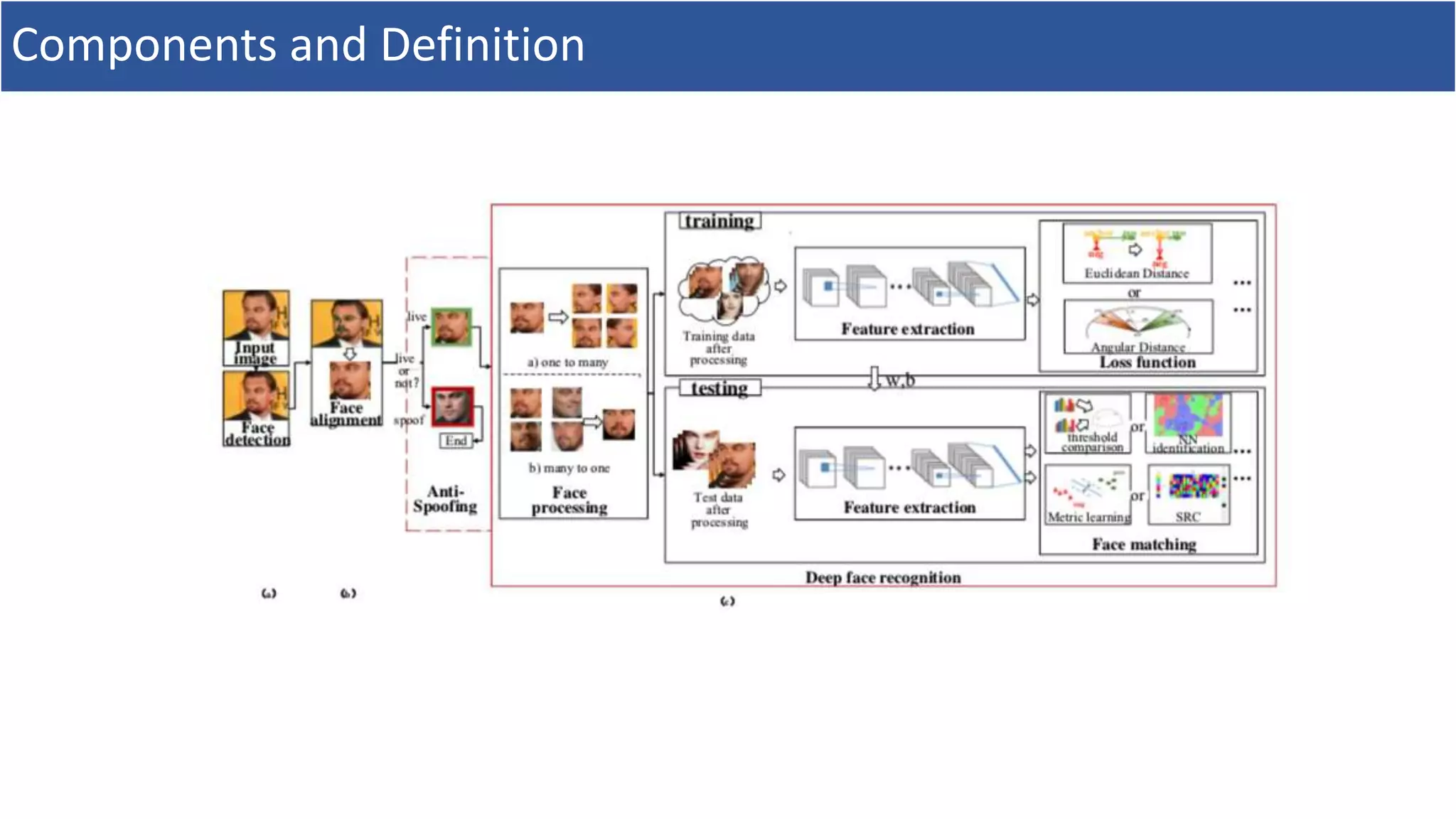
Components and Definition
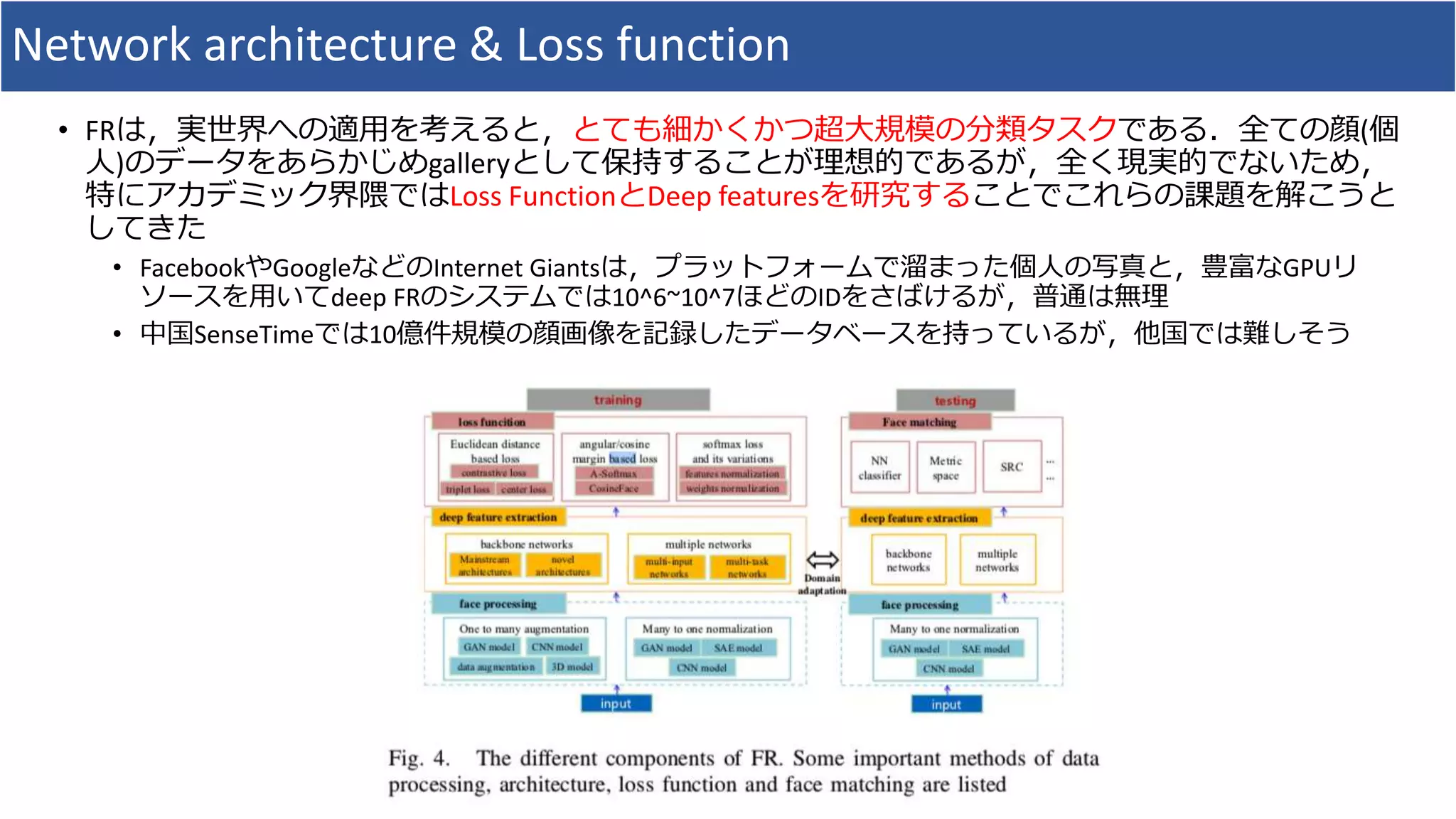
•FRの全体のシステムとして,
1. Face Detection => 本論文の範囲外(Deep Learning for Understanding Faces: Machines May Be Just as Good, or Better, than Humans)
2. Face Alignment => 本論文の範囲外(Deep Learning for Understanding Faces: Machines May Be Just as Good, or Better, than Humans)
3. Deep Face Recognition
• FRのタスクは,大きく以下の2つに分類
1. Face Verification: 1対1の類似度判定タスク
2. Face identification: 1=>多の類似度判定タスク
• データは,以下の2つに分類
1. Gallery: 既知の(顔)画像
2. Probe: 未知の(顔)画像
• Face identificationも
• Closed-set identification: Probe ∈ Gallery
• Open-set identification: Probe ∉ Gallery
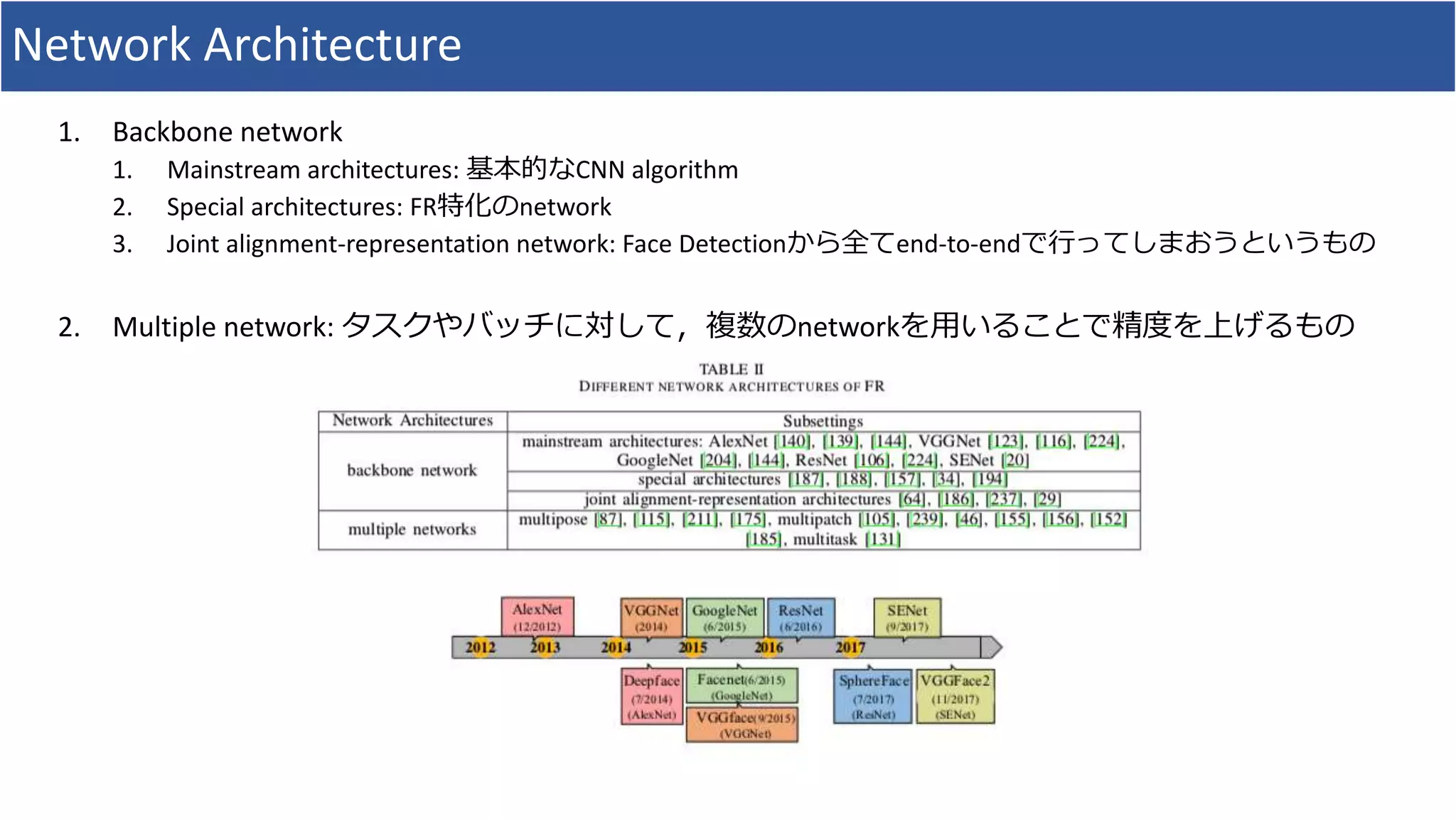
Special architectures, Jointalignment-representation network
• FRのための特別なarchitecturesも提案されている
• Light CNN: max-feature-map(MFM, maxoutという活性化関数自体を学習する手法をfully connected layerに導
入したもの)を用いている
• A Light CNN for Deep Face Representation with Noisy Labels
• Binary CNN
• One-to- many face recognition with bilinear cnns
• Trunk CNN
• Face recognition with contrastive convolution
• Pairwise relational network(PRN)
• Pairwise relational networks for face recognition
• Conditional CNN(c-CNN)
• Conditional convolutional neural network for modality-aware face recognition
• FRにおいて,Face Detectionから何から何までend-to-endでやってしまうという研究も存在
• Joint registration and representation learning for unconstrained face identification
Problems
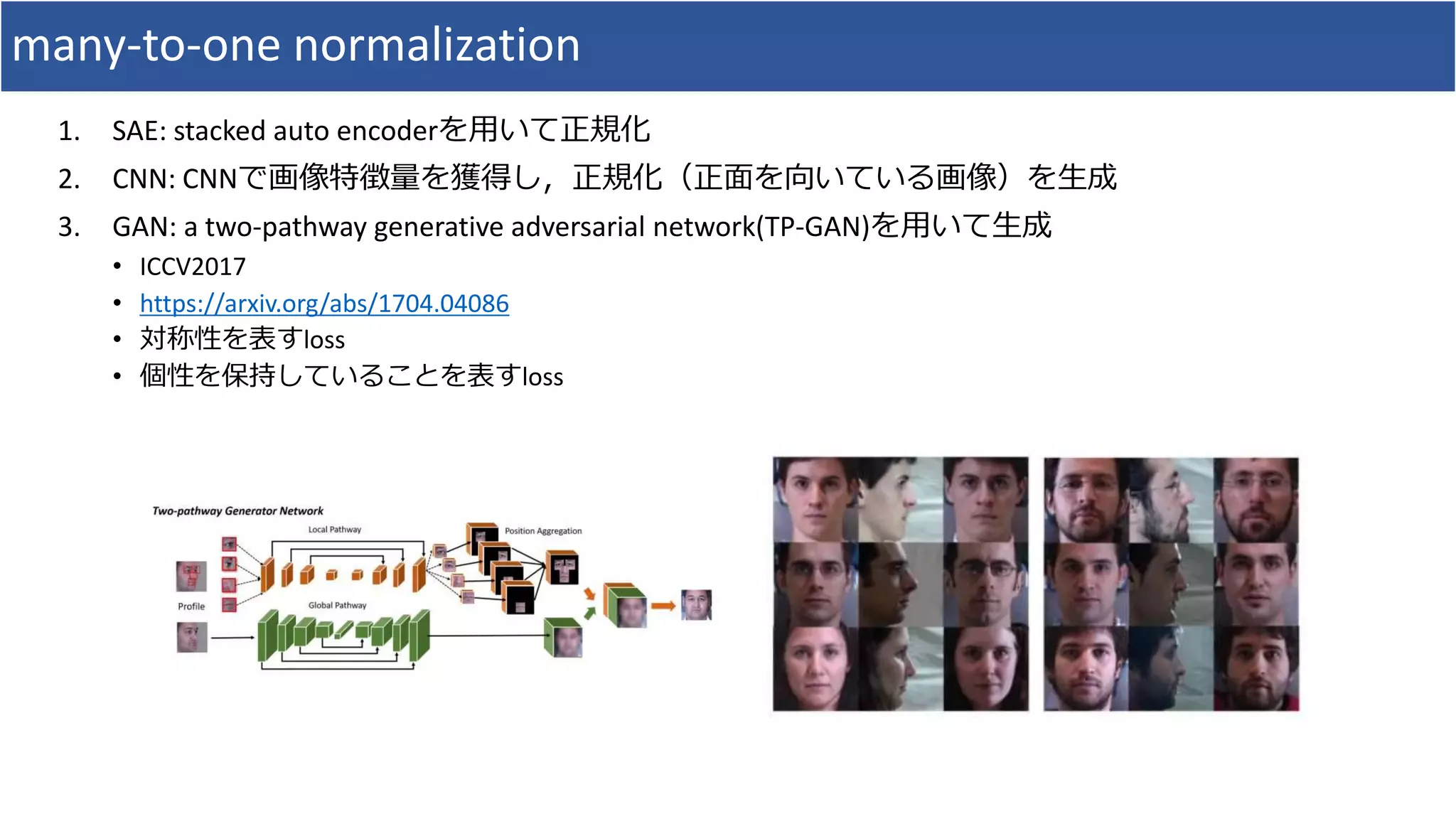
1. Cross-Pose FaceRecognition
• 正面を向いた画像が少ない
• One-to-many normalizationなどで克服を試みる
2. Cross-Age Face Recognition
• 認証に用いるのに,経年変化するという決定的な課題
• 年齢を追加
• 年齢で条件付けた画像をGANで生成
3. Makeup Face Recognition
• メイクすると誰か分からなくなる問題(汎用課題)
• ノーメイクの画像を生成する手法などが提案
4. NIR-VIS Face Recognition
• くらいシーンでのFRの問題
5. Low-Resolution Face Recognition
• 画質の問題
6. Photo-Sketch Face Recognition
34.
Problems
7. Low-Shot FaceRecognition
• 実用では,とても少ないデータセット(1枚の場合も)で特定する必要がある場合も
8. Set/Template-Based Face Recognition
• Probe/gallery共にデータのセット(単一画像でない)である場合
9. Video Face Recognition
• VideoでFRを行う必要がある場合
10. 3D Face Recognition
• 3DでFRすることができる手法はまだ少ない
11. Partial Face Recognition
• 部分的な写りこみだと難しい
12. Face Anti-spoofing
• Print attack, replay attach, 3dマスクなどの学習に対する攻撃は驚異
13. Face Recognition for Mobile Devices
• モバイルでFRできるかどうか
![1
DEEP LEARNING JP
[DL Papers]
http://deeplearning.jp/
"Deep Face Recognition: A Survey"
Mei Wang, Weihong Deng
Presentater: Koichiro Tamura, Matsuo Lab. M2](https://image.slidesharecdn.com/20181221-181221023935/75/DL-Deep-Face-Recognition-A-Survey-1-2048.jpg)


![Background
• [社会背景]Face Recognition(FR)のタスクは,軍事や金融,セキュリティ,エンタメなどの分野での
応用が期待されいる
• Ex1: 警備や保安の自動化
1. 人件費に課題を抱えている
2. 監視カメラ(スマホ&自動運転でセンサが増加されると見込まれる)の普及
• Ex2: 決済などの金融における本人確認
• キャッシュレス化のトレンド
• 本人確認書類の時間・金銭的コストの問題
• [技術背景]Deep Learningの登場によって,飛躍的に精度が向上](https://image.slidesharecdn.com/20181221-181221023935/75/DL-Deep-Face-Recognition-A-Survey-4-2048.jpg)



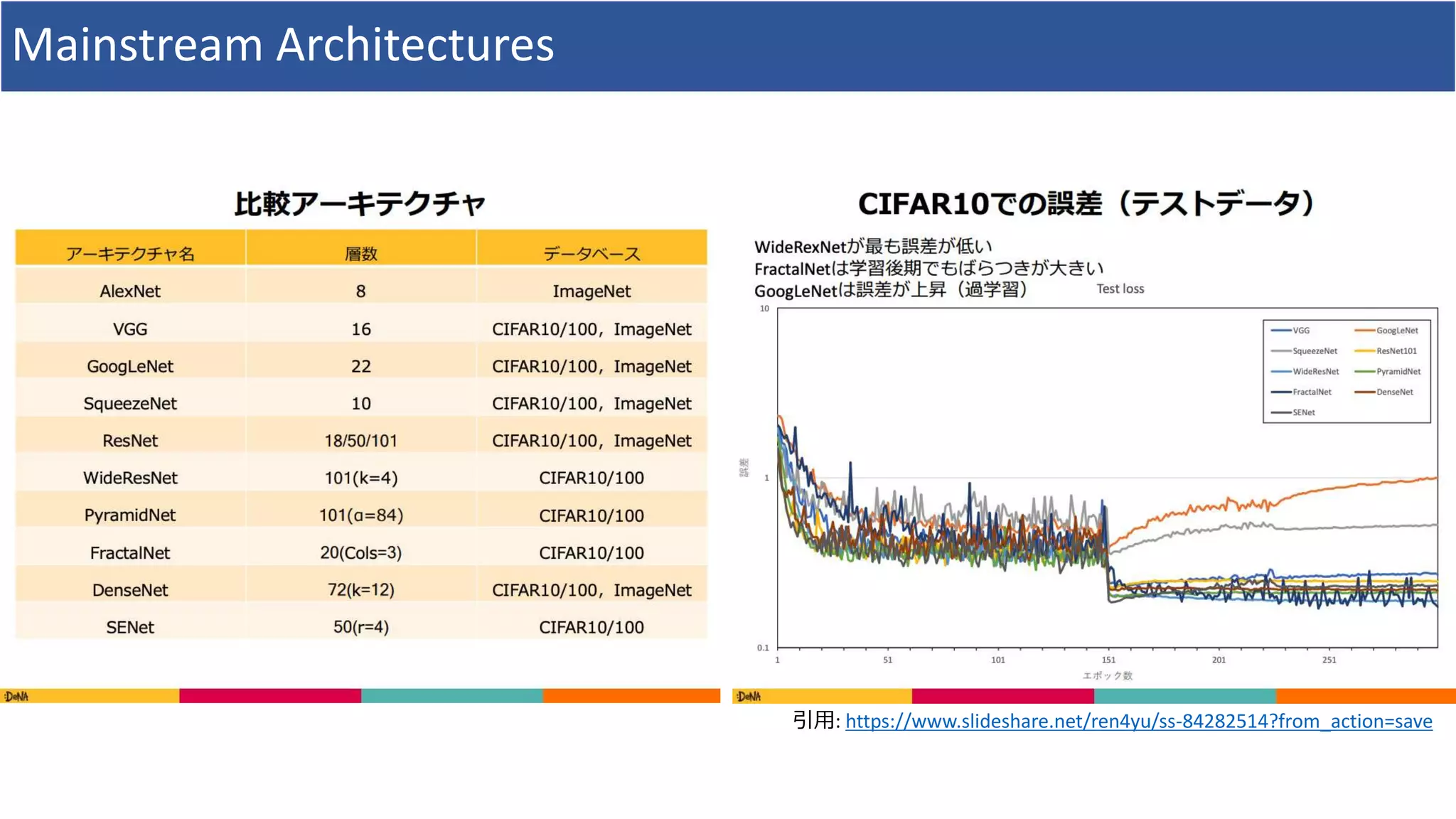

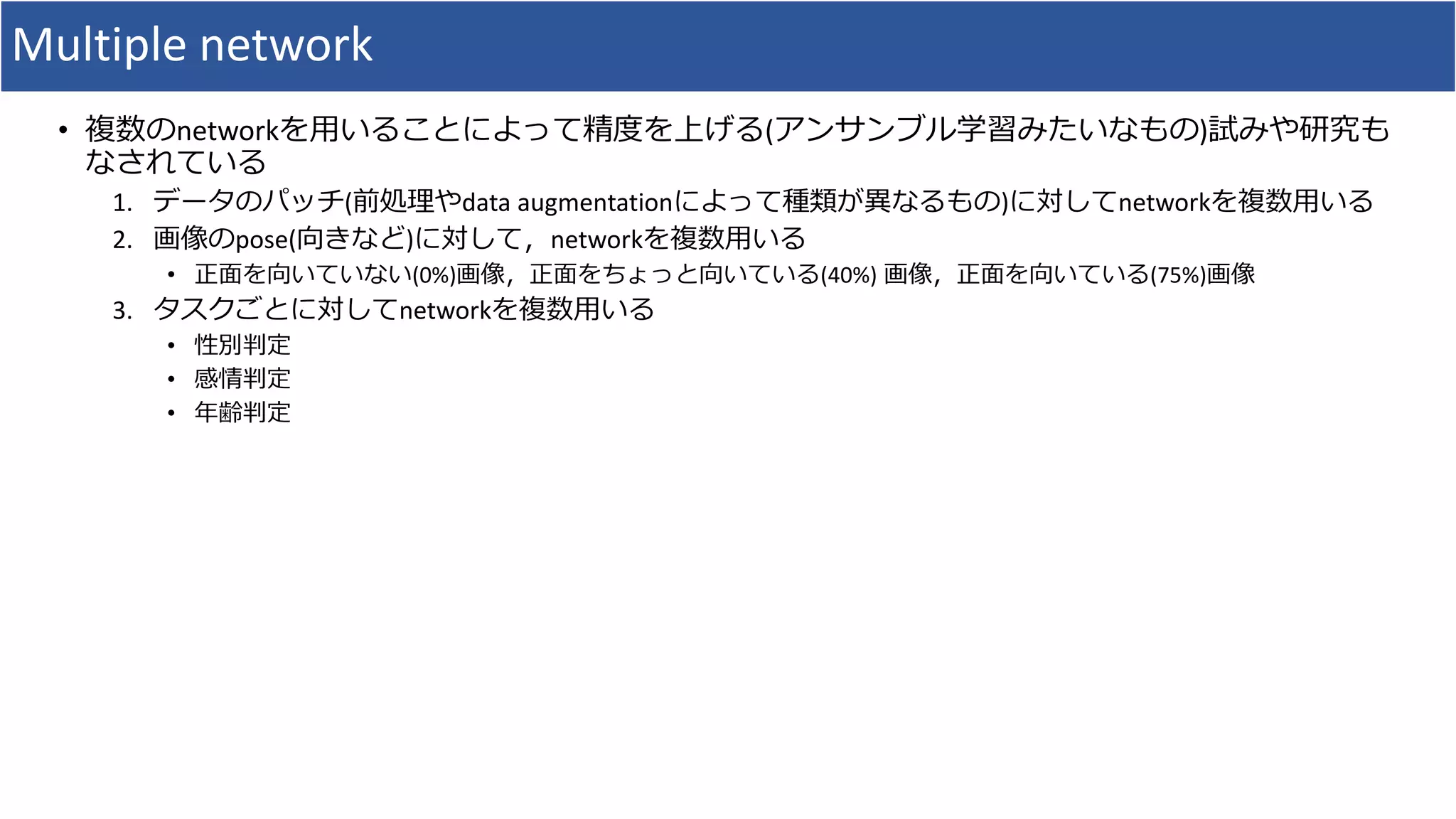

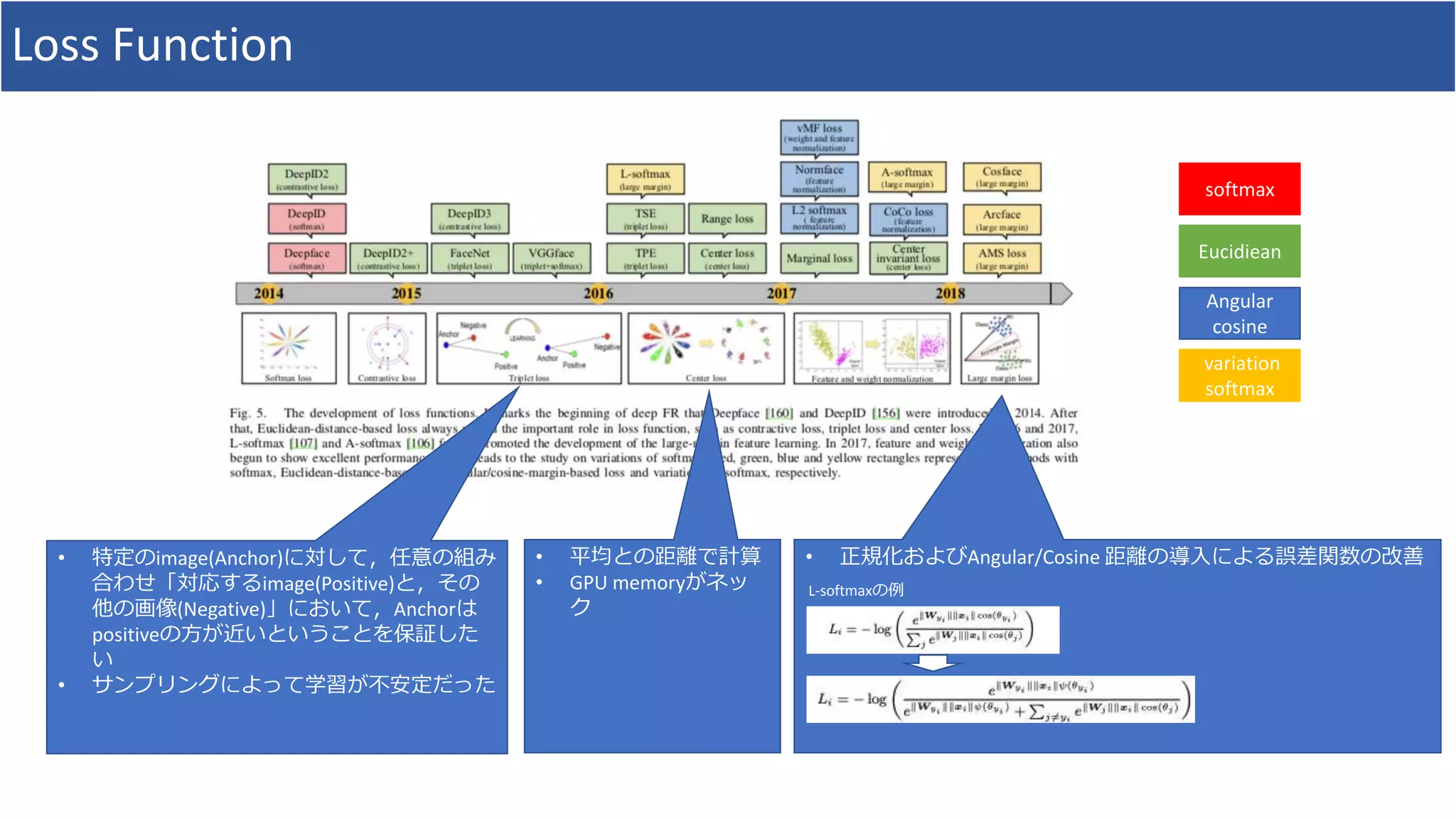






![参考文献
• 畳み込みニューラルネットワークの研究動向
• https://www.slideshare.net/ren4yu/ss-84282514
• [DL輪読会]Squeeze-and-Excitation Networks
• https://www.slideshare.net/DeepLearningJP2016/dlsqueezeandexcitation-networks
• Triplet Lossによる Person Re-identification
• https://www.slideshare.net/KoheiNishino/triplet-loss-person-reidentification
• CVPR 2018に44本の論文が採択
• https://www.sensetime.jp/single-post/2018/05/15/CVPR-
2018%E3%81%AB44%E6%9C%AC%E3%81%AE%E8%AB%96%E6%96%87%E3%81%8C%E6%8E%A1%E6%8A%9E
• 数式で書き下す Maxout Networks
• http://blog.yusugomori.com/post/133257383300/%E6%95%B0%E5%BC%8F%E3%81%A7%E6%9B%B8%E3%81%8D
%E4%B8%8B%E3%81%99-maxout-networks
• 同じか否かを判定するための距離学習(Metric Learning)
• https://qiita.com/tancoro/items/8d3438cab574a02319cc
• 論文まとめ:Dual-Agent GANs for Photorealistic and Identity Preserving Profile Face Synthesis
• https://qiita.com/masataka46/items/4f7e4a3d1036de55affd](https://image.slidesharecdn.com/20181221-181221023935/75/DL-Deep-Face-Recognition-A-Survey-35-2048.jpg)







![[DL輪読会]Focal Loss for Dense Object Detection](https://cdn.slidesharecdn.com/ss_thumbnails/focalloss-180208092846-thumbnail.jpg?width=640&height=640&fit=bounds)


![SSII2021 [OS2-02] 深層学習におけるデータ拡張の原理と最新動向](https://cdn.slidesharecdn.com/ss_thumbnails/os2-03latest-210610045610-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]MetaFormer is Actually What You Need for Vision](https://cdn.slidesharecdn.com/ss_thumbnails/20220121metaformer-220121085750-thumbnail.jpg?width=640&height=640&fit=bounds)















![[DL輪読会]モデルベース強化学習とEnergy Based Model](https://cdn.slidesharecdn.com/ss_thumbnails/energybasedmodel-191129002008-thumbnail.jpg?width=640&height=640&fit=bounds)




![[DL輪読会]HoloGAN: Unsupervised learning of 3D representations from natural images](https://cdn.slidesharecdn.com/ss_thumbnails/hologanslideshare-190906010228-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]BANMo: Building Animatable 3D Neural Models from Many Casual Videos](https://cdn.slidesharecdn.com/ss_thumbnails/banmo-220225035310-thumbnail.jpg?width=640&height=640&fit=bounds)
















































