【DL輪読会】Visual ChatGPT: Talking, Drawing and Editing with Visual Foundation Models
1.
1
DEEP LEARNING JP
[DLPapers]
http://deeplearning.jp/
Visual ChatGPT: Talking, Drawing and Editing
with Visual Foundation Models
3/10 今井翔太 (松尾研究室)
@ImAI_Eruel
2.
書誌情報
タイトル:Visual ChatGPT:Talking, Drawing and Editing with Visual
Foundation Models
出典:https://arxiv.org/abs/2303.04671
著者:Microsoft Research Asiaの研究者ら
日本時間で昨日(正確には3/8)発表された論文
Shota Imai | The University of Tokyo
2
3.
今回の発表について
ChatGPTのような大規模モデルを一から学習した研究ではない
研究ではなく,既存のChatGPTや基盤モデルを組み合わせて有益なシステムをつくる,
エンジニアリングのお話に近い
そもそもChatGPTを使っていない(使っているのはtext-davinci-003)ほか,論文の内容
もかなりざっくりで,ChatGPTの流行に乗っかった商品紹介みがある
既存の学習済みVisual Foundation ModelとChatGPTを組み合わせたシステムであり,
我々にも真似できる手法という点では重要なアイディア
(自分で読むのを選んでおいてアレですが)マイクロソフトが「ChatGPT」の名前を借
りて出した割には,ちょっと荒っぽさがある内容
Shota Imai | The University of Tokyo
3
Visual 〇〇というネーミン
グがマイクロソフト感あり
(Visual Stadio,Vscode...)
4.
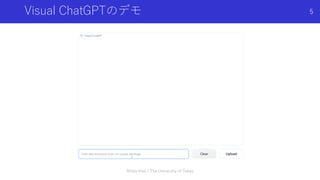
Visual ChatGPTの概要
テキストと画像を入力とし,入力画像に対する操作や質問を対話をしながら実行できる
システム
-この画像のソファを机に置き換えてください,色を変えてください,背景を変えてください,
入力した画像を参考に〇〇な画像を出力してください等
言語入力を受け取って操作や応答を出力する言語モデル,画像に対する操作を実行する
Visual Foundation Model,画像などの言語でないものを言語モデルへの指示に変換する
Prompt Managerからなる
Shota Imai | The University of Tokyo
4
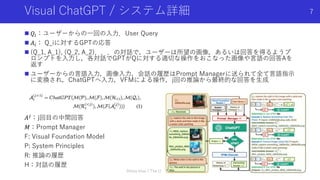
Visual ChatGPT /システム詳細
𝑄𝑖:ユーザーからの一回の入力.User Query
𝐴𝑖: Q_iに対するGPTの応答
(Q_1, A_1), (Q_2, A_2)...の対話で,ユーザーは所望の画像,あるいは回答を得るようプ
ロンプトを入力し,各対話でGPTがQに対する適切な操作をおこなった画像や言語の回答Aを
返す
ユーザーからの言語入力,画像入力,会話の履歴はPrompt Managerに送られて全て言語指示
に変換され,ChatGPTへ入力,VFMによる操作,j回の推論から最終的な回答を生成
𝐴𝑗
:j回目の中間回答
𝑀:Prompt Manager
F: Visual Foundation Model
P: System Principles
R: 推論の履歴
H:対話の履歴
Shota Imai | The University of Tokyo
7
8.
大雑把な処理の流れ
1. ユーザーが入力Qを画像と一緒に入力
2. VisualChatGPTのPrompt ManagerがQの言語部分と,事前に準備されているSystem
PrincipleやVFMのドキュメントを見て,ChatGPTに入力するプロンプトを作成
3. プロンプトをChatGPTに入力し,言語出力と,VFMを使用するかどうかの決定,VFM
に入力する場合にはVFMへのプロンプトや,入力形式を決定
4. VFMを使う必要がなければ,ChatGPTの回答をユーザーに返す.使う必要があれば
VFMを呼び出し,ユーザーから入力された画像と,ChatGPTの出力プロンプトを処理
5. VFMの処理結果を見て,さらに処理を行うか決定.処理する場合には現在の出力を参
考に,3から繰り返す
Shota Imai | The University of Tokyo
8
9.
Visual Foundation Model(VFN)
pix2pixや,text2imageなど,現在よく使われている学習済みの画像関連の基盤モデルの
集合𝐹 = {𝑓1, 𝑓2, … , 𝑓𝑁}
Prompt Managerの出力から,現在のユーザーのQに対する回答を生成するのに最も適し
たVFMを選択し,画像への操作を実行
Shota Imai | The University of Tokyo
9
10.
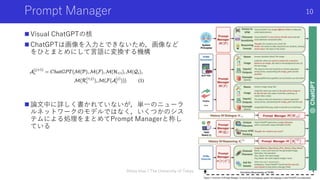
Prompt Manager
VisualChatGPTの核
ChatGPTは画像を入力とできないため,画像など
をひとまとめにして言語に変換する機構
論文中に詳しく書かれていないが,単一のニューラ
ルネットワークのモデルではなく,いくつかのシス
テムによる処理をまとめてPrompt Managerと称し
ている
Shota Imai | The University of Tokyo
10
11.
Prompt Manager /System Principleの処理
ChatGPTに対し,現在必要な操作の基本的方針を出力
どのVFMを使うか,ファイル名の扱い,推論に使用するフォーマットなどの指示
Shota Imai | The University of Tokyo
11
12.
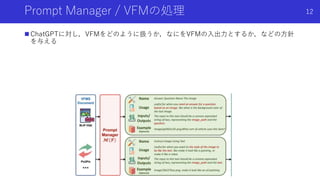
Prompt Manager /VFMの処理
ChatGPTに対し,VFMをどのように扱うか,なにをVFMの入出力とするか,などの方針
を与える
Shota Imai | The University of Tokyo
12
13.
Prompt Manager /中間出力の処理
Visual ChatGPTがVFMで出力した結果から,さらなる操作を行うかどうかを決定
ユーザーの処理が曖昧な場合は,この時点でユーザーに対してさらなる操作の指示を聞
く
Shota Imai | The University of Tokyo
13
14.
実験
Visual ChatGPTの仕様
-言語モデル:text-davinci-003(GPT-3.5)
- LangChain
- Visual Foundation Model: HuggingFace Transformers,Maskformer, ControlNetなど22個
- 計算リソース:V100 GPU 4個
- 会話履歴の最大トークン数:2000
System PrincipleのPrompt Managing, VFMのPrompt Managingなどのケーススタディ
- 色々載っているが,要するにVisual ChatGPTの処理の失敗例と成功例を並べたもの
Shota Imai | The University of Tokyo
14
![1
DEEP LEARNING JP
[DL Papers]
http://deeplearning.jp/
Visual ChatGPT: Talking, Drawing and Editing
with Visual Foundation Models
3/10 今井翔太 (松尾研究室)
@ImAI_Eruel](https://image.slidesharecdn.com/dl0310imai-230310042156-aef7d2da/85/DL-Visual-ChatGPT-Talking-Drawing-and-Editing-with-Visual-Foundation-Models-1-320.jpg)













![[DL輪読会]Pay Attention to MLPs (gMLP)](https://cdn.slidesharecdn.com/ss_thumbnails/kobayashi-210528032327-thumbnail.jpg?width=640&height=640&fit=bounds)



![SSII2022 [OS3-02] Federated Learningの基礎と応用](https://cdn.slidesharecdn.com/ss_thumbnails/ssii2022-os3-02-220607020834-2b5f93ff-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DL輪読会]BERT: Pre-training of Deep Bidirectional Transformers for Language Und...](https://cdn.slidesharecdn.com/ss_thumbnails/dlreadingpaper20181019-181019010218-thumbnail.jpg?width=640&height=640&fit=bounds)











![[DL輪読会]Decision Transformer: Reinforcement Learning via Sequence Modeling](https://cdn.slidesharecdn.com/ss_thumbnails/decisiontransformer20210709zhangxin-210709021501-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]近年のオフライン強化学習のまとめ —Offline Reinforcement Learning: Tutorial, Review, an...](https://cdn.slidesharecdn.com/ss_thumbnails/20200626journalclubpub-200630064755-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]Vision Transformer with Deformable Attention (Deformable Attention Tra...](https://cdn.slidesharecdn.com/ss_thumbnails/dl0114-220114032933-thumbnail.jpg?width=640&height=640&fit=bounds)







![[DL輪読会]HoloGAN: Unsupervised learning of 3D representations from natural images](https://cdn.slidesharecdn.com/ss_thumbnails/hologanslideshare-190906010228-thumbnail.jpg?width=640&height=640&fit=bounds)












![[DL輪読会] MoCoGAN: Decomposing Motion and Content for Video Generation](https://cdn.slidesharecdn.com/ss_thumbnails/0911mocogan-170911121936-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]Learning to Simulate Complex Physics with Graph Networks](https://cdn.slidesharecdn.com/ss_thumbnails/learningtosimulatecomplexphysicswithgraphnetworks-200508054213-thumbnail.jpg?width=640&height=640&fit=bounds)






















