Downloaded 120 times
![DEEP LEARNING JP
[DL Papers]
ViT + Self Supervised Learningまとめ
発表者:岩澤有祐
http://deeplearning.jp/](https://image.slidesharecdn.com/20211203iwasawa-211203034918/85/DL-ViT-Self-Supervised-Learning-1-320.jpg)



![再構成による教師なし表現学習
• 右のような生成過程を考える
• log 𝑝 𝑥 = 𝑝 𝑥 𝑧 𝑑𝑧
• 良い生成を与えるような表現を学習する
• VAE系やGAN系など多数
– [Kingma+ 14] VAE
– [Donahue+ 17] bidirectional GAN
– [Dumoulin+ 17] adversarial learned inference
5
𝑥
𝑧](https://image.slidesharecdn.com/20211203iwasawa-211203034918/85/DL-ViT-Self-Supervised-Learning-5-320.jpg)

![Masked Language Modelと自己教師あり学習
7
① Language Model (LM, 言語モデル) ② Masked Language Model
大規模DNN 大規模DNN
Input: Language models determine
Output: word probability
by analyzing text data
Input: Language models determine [mask]
[mask] by [mask] text data
Input: Language models determine word
probability by analyzing text data
Original: Language models determine word probability by analyzing text data
原文を入力と予測対象に分割
自分(の一部)から自分を予測するため,自己教師あり学習とも呼ばれる](https://image.slidesharecdn.com/20211203iwasawa-211203034918/85/DL-ViT-Self-Supervised-Learning-7-320.jpg)

![具体例:SimCLR [Chen+2020]
14
正例:同じ画像を異なるデータ
拡張して得られた表現のペア
負例:別画像との表現](https://image.slidesharecdn.com/20211203iwasawa-211203034918/85/DL-ViT-Self-Supervised-Learning-10-320.jpg)






![手法2: Masked Patch Prediction
• ViT論文での自己教師あり学習
– BERT同様,入力パッチの一部の穴埋めタスク.
– 全パッチの50%のうち
• 80%を学習可能な[mask]埋め込みに変更
• 10%をランダムな他のパッチに変更
• 10%はそのままに
– 欠損した50%のパッチの平均RGBを対応する埋め込みから予測
• ViT/Bで実験,事前学習にJFTを利用.
– 100k位で後続タスクの性能向上はなくなったとの報告もあり.
• FTで79.9% top1 acc(Linear Provingは言及なし)
24](https://image.slidesharecdn.com/20211203iwasawa-211203034918/85/DL-ViT-Self-Supervised-Learning-20-320.jpg)








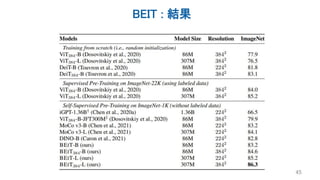
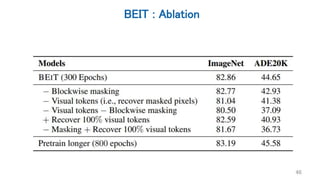
![MAEと他研究の違い:計算効率
• エンコーダデコーダ構造をしている
– iGPT:デコーダのみ
– ViT系:基本エンコーダのみ
• エンコーダにマスクトークン[mask]を入力しない(計算量削減)
– ほか研究はマスクした箇所に[mask]とPositional Encodingを入力
– つまりエンコーダに入るデータ長は元のパッチ数より少ない
• 大量のパッチを欠損させる(計算量削減)
– 画像はテキストと比べて情報が散らばっているので,欠損が少ないと簡単
• デコーダはエンコーダと比べて小さくする(計算量削減)
– Asymmetricな構造をしている
– デコーダには[mask]も当然入力するので系列が長くなるが,そもそも小さいので計算
量が増えすぎない
48](https://image.slidesharecdn.com/20211203iwasawa-211203034918/85/DL-ViT-Self-Supervised-Learning-44-320.jpg)


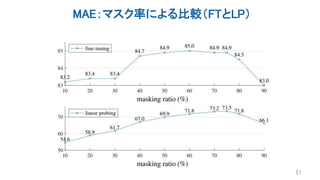

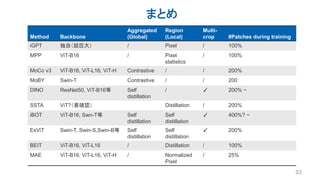




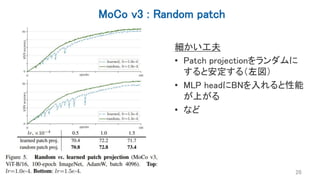
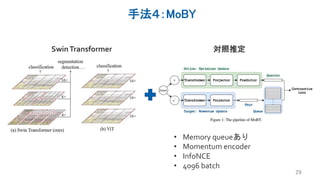
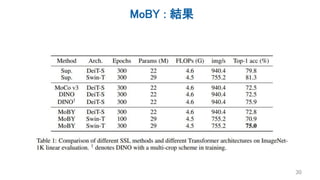
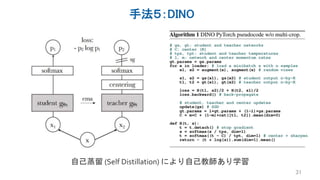
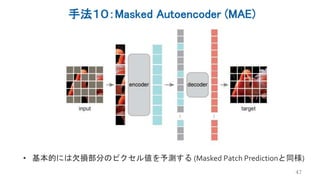
Several recent papers have explored self-supervised learning methods for vision transformers (ViT). Key approaches include: 1. Masked prediction tasks that predict masked patches of the input image. 2. Contrastive learning using techniques like MoCo to learn representations by contrasting augmented views of the same image. 3. Self-distillation methods like DINO that distill a teacher ViT into a student ViT using different views of the same image. 4. Hybrid approaches that combine masked prediction with self-distillation, such as iBOT.


![[DL輪読会]相互情報量最大化による表現学習](https://cdn.slidesharecdn.com/ss_thumbnails/20190913iwasawa-190913002312-thumbnail.jpg?width=640&height=640&fit=bounds)




![[DL輪読会]data2vec: A General Framework for Self-supervised Learning in Speech,...](https://cdn.slidesharecdn.com/ss_thumbnails/220204nonakadl1-220204025334-thumbnail.jpg?width=640&height=640&fit=bounds)


![SSII2021 [OS2-01] 転移学習の基礎:異なるタスクの知識を利用するための機械学習の方法](https://cdn.slidesharecdn.com/ss_thumbnails/os2-02final-210610091211-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]Swin Transformer: Hierarchical Vision Transformer using Shifted Windows](https://cdn.slidesharecdn.com/ss_thumbnails/swintransformer-210514020542-thumbnail.jpg?width=640&height=640&fit=bounds)










![[DL輪読会]Vision Transformer with Deformable Attention (Deformable Attention Tra...](https://cdn.slidesharecdn.com/ss_thumbnails/dl0114-220114032933-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]Dense Captioning分野のまとめ](https://cdn.slidesharecdn.com/ss_thumbnails/dlseminar-201202012355-thumbnail.jpg?width=640&height=640&fit=bounds)




















![[論文紹介] BlendedMVS: A Large-scale Dataset for Generalized Multi-view Stereo Ne...](https://cdn.slidesharecdn.com/ss_thumbnails/blendedmvsslideshare-200630044345-thumbnail.jpg?width=640&height=640&fit=bounds)

![ViT (Vision Transformer) Review [CDM]](https://cdn.slidesharecdn.com/ss_thumbnails/vitreviewcdm-201012184226-thumbnail.jpg?width=640&height=640&fit=bounds)







































