【DL輪読会】AdaptDiffuser: Diffusion Models as Adaptive Self-evolving Planners
1.
DEEP LEARNING JP
[DLPapers]
http://deeplearning.jp/
AdaptDiffuser: Diffusion Models as Adaptive Self-evolving Planners
Makoto Kawano (@mkt_kwn), Matsuo Lab.
2.
書誌情報
• AdaptDiffuser: DiffusionModels as Adaptive Self-evolving Planners
Liang, Z., Mu, Y., Ding, M., Ni, F., Tomizuka, M., and Luo, P
The University of Hong Kong, University of California, Berkeley, Tianjin University,
Shanghai AI Laboratory
ICML2023(oral)
• Planning with Diffusion for Flexible Behavior Synthesis
Janner, M., Du, Y., Tenenbaum, J.B., and Levine, S.
University of California, Berkeley, MIT
ICML2022
今回のメイン
前回少し触れたが
かなり簡素だったので
2
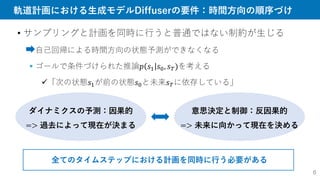
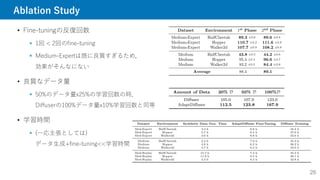
AdaptDiffuser
15
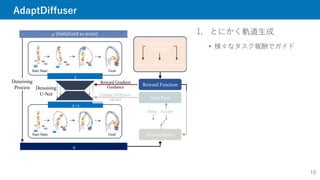
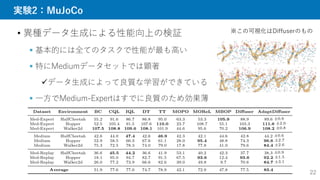
1. とにかく軌道生成
様々なタスク報酬でガイド
Goal
StartState
Goal
Start State
�
�
Reward Function
Denoising
U-Net
� (Initialized as noise)
�
Denoising
Process
Discriminator
Data Pool
Goal 1 Goal 2 Goal 3
Diverse Task
Generation
Update Diffusion
Model
Drop Accept
Reward Gradient
Guidance
16.
AdaptDiffuser
16
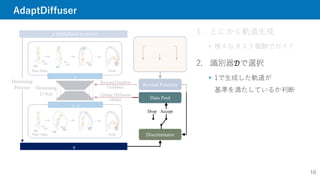
1. とにかく軌道生成
様々なタスク報酬でガイド
2.識別器𝒟で選択
1で生成した軌道が
基準を満たしているか判断
Goal
Start State
Goal
Start State
�
�
Reward Function
Denoising
U-Net
� (Initialized as noise)
�
Denoising
Process
Discriminator
Data Pool
Goal 1 Goal 2 Goal 3
Diverse Task
Generation
Update Diffusion
Model
Drop Accept
Reward Gradient
Guidance
17.
AdaptDiffuser
17
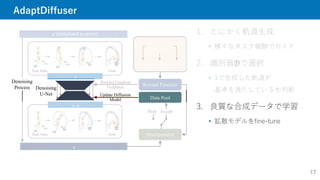
1. とにかく軌道生成
様々なタスク報酬でガイド
2.識別器𝒟で選択
1で生成した軌道が
基準を満たしているか判断
3. 良質な合成データで学習
拡散モデルをfine-tune
Goal
Start State
Goal
Start State
�
�
Reward Function
Denoising
U-Net
� (Initialized as noise)
�
Denoising
Process
Discriminator
Data Pool
Goal 1 Goal 2 Goal 3
Diverse Task
Generation
Update Diffusion
Model
Drop Accept
Reward Gradient
Guidance
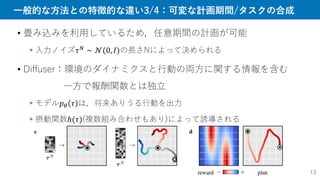
18.
AdaptDiffuser
18
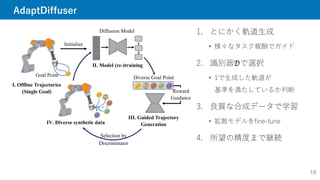
1. とにかく軌道生成
様々なタスク報酬でガイド
2.識別器𝒟で選択
1で生成した軌道が
基準を満たしているか判断
3. 良質な合成データで学習
拡散モデルをfine-tune
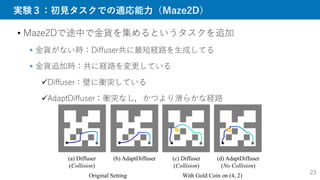
4. 所望の精度まで継続
Reward
Guidance
Diffusion Model
II. Model (re-)training
Diverse Goal Point
IV. Diverse synthetic data
III. Guided Trajectory
Generation
I. Offline Trajectories
(Single Goal)
Initialize
Selection by
Discriminator
Goal Point
![DEEP LEARNING JP
[DL Papers]
http://deeplearning.jp/
AdaptDiffuser: Diffusion Models as Adaptive Self-evolving Planners
Makoto Kawano (@mkt_kwn), Matsuo Lab.](https://image.slidesharecdn.com/main1-230825024509-eae34fd7/85/DL-AdaptDiffuser-Diffusion-Models-as-Adaptive-Self-evolving-Planners-1-320.jpg)





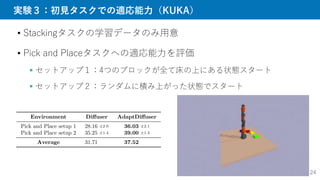
![Diffuserのアーキテクチャ
• 基本はU-Netの1d-Convバージョン
畳み込みのおかげで計画期間の長さは可変になる
• 学習も[Ho+, 2020]を利用
𝑖 ∼ 𝒰{1,2, … , 𝑁}:拡散方向のタイムステップ
𝜖 ∼ 𝒩(0, 𝐼):ターゲットノイズ
t
x
Conv1D
FC
Layer
Conv1D
GN Mish GN, Mish
8](https://image.slidesharecdn.com/main1-230825024509-eae34fd7/85/DL-AdaptDiffuser-Diffusion-Models-as-Adaptive-Self-evolving-Planners-8-320.jpg)
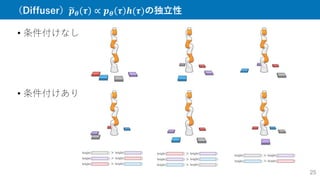
![「報酬」導入による Diffuserでの強化学習
• Control-as-inference[Levine, 2018]と同じように定式化
𝒪𝑡:時刻𝑡における軌道の最適性を表す二値確率変数
• 摂動関数ℎ 𝜏 = 𝑝(𝒪1:𝑇|𝜏)によって最適な軌道をサンプリング可能
ガウス分布で近似
9](https://image.slidesharecdn.com/main1-230825024509-eae34fd7/85/DL-AdaptDiffuser-Diffusion-Models-as-Adaptive-Self-evolving-Planners-9-320.jpg)








![[DL輪読会]Glow: Generative Flow with Invertible 1×1 Convolutions](https://cdn.slidesharecdn.com/ss_thumbnails/dlreadingpaper20180720-180723071258-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]Decision Transformer: Reinforcement Learning via Sequence Modeling](https://cdn.slidesharecdn.com/ss_thumbnails/decisiontransformer20210709zhangxin-210709021501-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DL輪読会]近年のエネルギーベースモデルの進展](https://cdn.slidesharecdn.com/ss_thumbnails/energybasedmodel-200124020855-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]When Does Label Smoothing Help?](https://cdn.slidesharecdn.com/ss_thumbnails/yokota20191227dl-191227001522-thumbnail.jpg?width=640&height=640&fit=bounds)









![[DL輪読会]Convolutional Conditional Neural Processesと Neural Processes Familyの紹介](https://cdn.slidesharecdn.com/ss_thumbnails/20191220readingpaperconvcnp-191220034420-thumbnail.jpg?width=640&height=640&fit=bounds)




![SSII2022 [SS2] 少ないデータやラベルを効率的に活用する機械学習技術 〜 足りない情報をどのように補うか?〜](https://cdn.slidesharecdn.com/ss_thumbnails/ss2ssii2022-220607054716-2760bd30-thumbnail.jpg?width=640&height=640&fit=bounds)




![[DL輪読会]Neural Ordinary Differential Equations](https://cdn.slidesharecdn.com/ss_thumbnails/nnasode1-190111001755-thumbnail.jpg?width=640&height=640&fit=bounds)



















![[DL輪読会]A Bayesian Perspective on Generalization and Stochastic Gradient Descent](https://cdn.slidesharecdn.com/ss_thumbnails/20171106dl2-171108033614-thumbnail.jpg?width=640&height=640&fit=bounds)




















