Download as PDF, PPTX



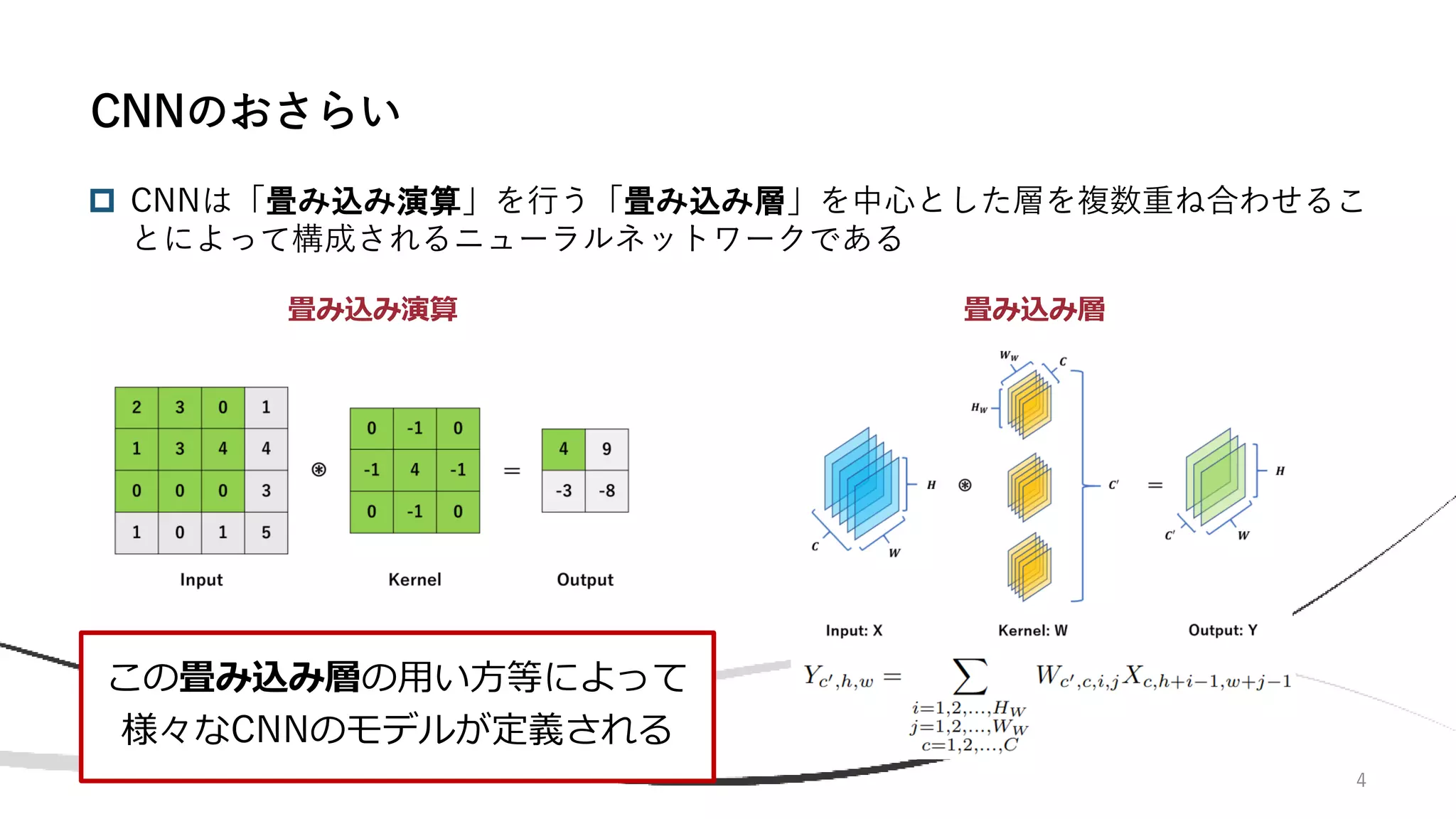
![7
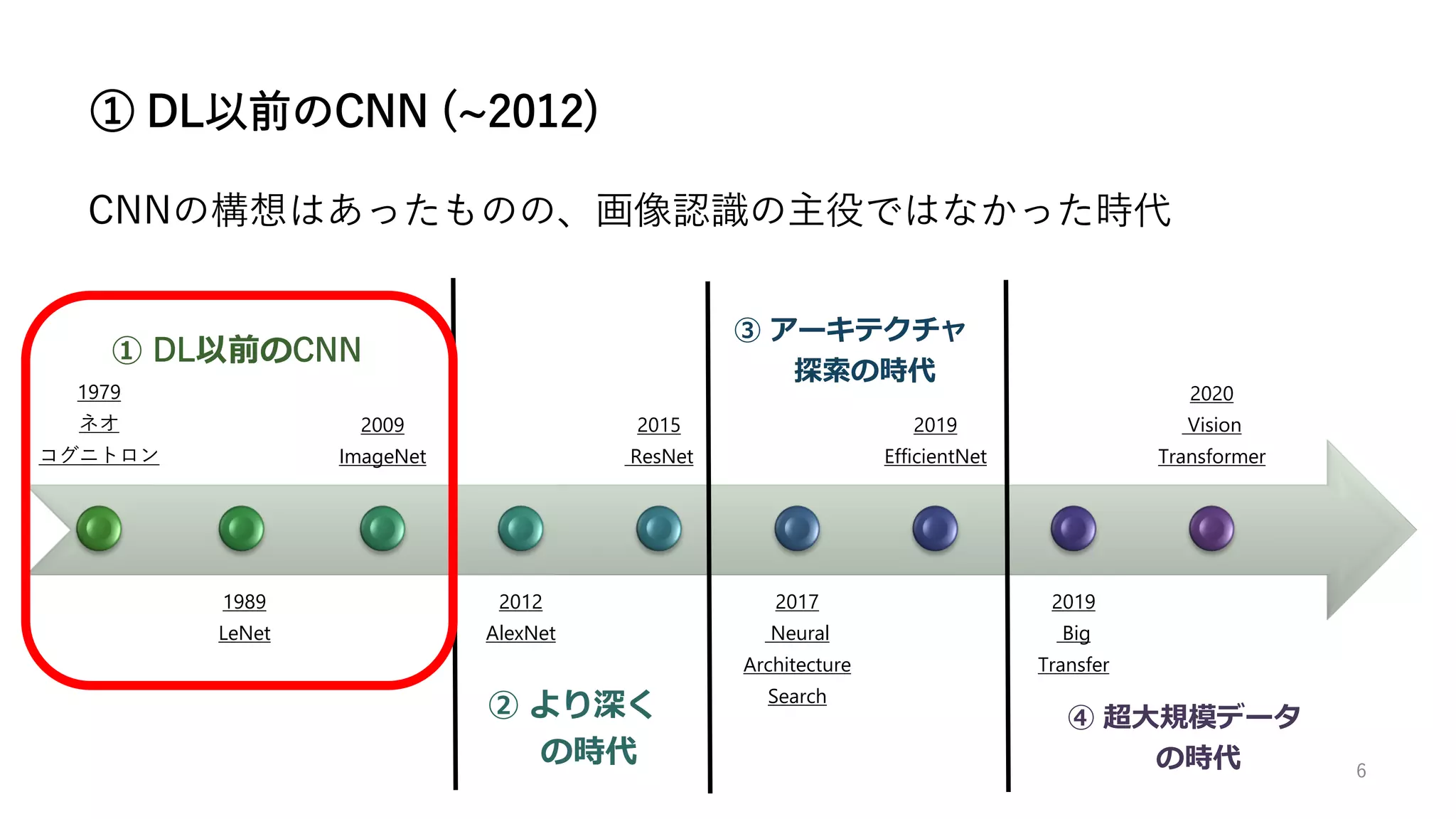
ネオコグニトロン (Neocognitron) [6] は1979年に福島邦彦によって提案さ
れた、CNNのもとになったニューラルネットワークである
ネオコグニトロン
[6] Fukushima K. Neocognitron: a self organizing neural network model for a mechanism of pattern recognition unaffected
by shift in position. Biol Cybern. 1980;36(4):193-202. doi: 10.1007/BF00344251. PMID: 7370364. 図も本論文より引用
ネオコグニトロンは、
画像の特徴量を抽出する「S細胞」
特徴の位置ずれを補正する「C細胞」
を中心として構成されている
S細胞が畳み込み層、C細胞がプーリング層
と似た働きをする](https://image.slidesharecdn.com/imageclassificationslideshare-210816092105/75/2021-8-Image-Classificaiton-7-2048.jpg)
![8
LeNet [7] は1989年にYann LeCunによって提案されたCNNであり、大枠とし
てはネオコグニトロンに誤差逆伝播法による学習を導入したものとみなせる
CNNという名前が登場したのはLeNetが最初であると思われる
LeNetは5層のCNNなのでLeNet-5とも呼ばれている
この研究は1998年まで続けられ、手書き文字認識において高い性能を発揮した
LeNet
[7] LeCun, Y.; Boser, B.; Denker, J. S.; Henderson, D.; Howard, R. E.; Hubbard, W. & Jackel, L. D. (1989).
Backpropagation applied to handwritten zip code recognition. Neural Computation, 1(4):541-551. 図も本論文より引用](https://image.slidesharecdn.com/imageclassificationslideshare-210816092105/75/2021-8-Image-Classificaiton-8-2048.jpg)

![ 1500万枚, 15000カテゴリと、当時存
在していたデータセットをはるかに
上回るスケール
英単語の概念辞書であるWordNetを
用い、体系的にクラスを定義
動物・乗り物・食べ物等、様々なクラス
のデータを含む
CNNの学習に必要なデータが整う
10
DLに必要な大規模データの整備に大きく貢献したのが、2009年に登場
したImageNetデータセット [8] である
ImageNet
[8] Deng, Jia, et al. "Imagenet: A large-scale hierarchical image
database." 2009 IEEE conference on computer vision and pattern
recognition. Ieee, 2009.
[9] https://image-net.org/static_files/files/imagenet_ilsvrc2017_v1.0.pdf
より画像を引用](https://image.slidesharecdn.com/imageclassificationslideshare-210816092105/75/2021-8-Image-Classificaiton-10-2048.jpg)
![11
ImageNet Large Scale Visual Recognition Challenge(ILSVRC)は
2010-2017年に開催された、ImageNetを用いた画像認識競技会
画像認識精度を同じ指標で世界中の研究チームが競うこととなり、大規模
データによる画像認識の研究が活性化される
ILSVRCで優勝したモデルが最先端技術として扱われる、という流れが出来上がる
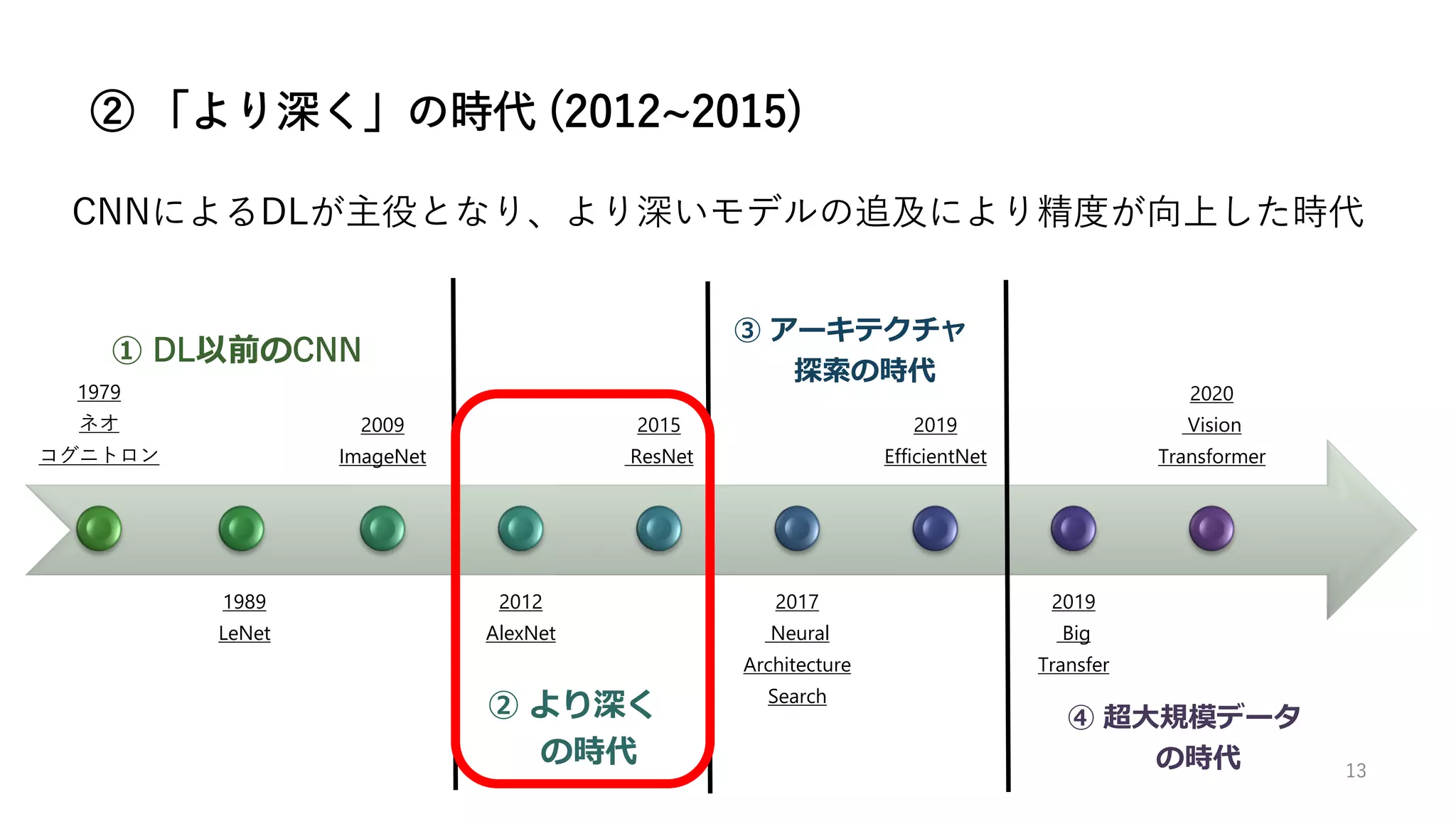
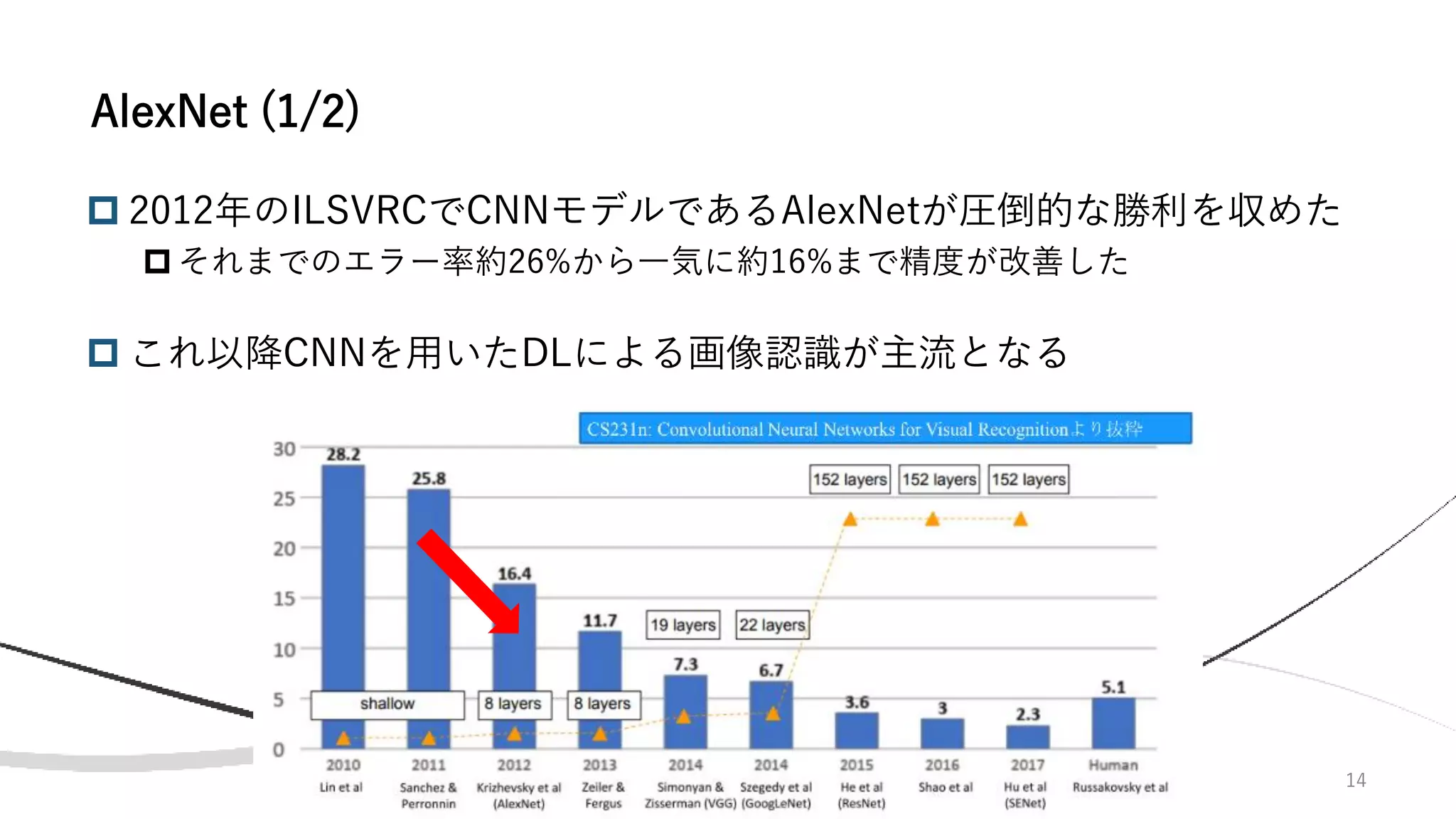
2012年にAlexNet [10]がこのILSVRCで圧勝し、DLが日の目を見ることになる
画像分類タスク(120万枚で1000クラス分類器を学習)が有名だが、その他
にも物体検出・詳細クラス分類・分類+位置推定といったタスクも行われた
ILSVRC
[10] Krizhevsky, Alex, Ilya Sutskever, and Geoffrey E. Hinton. "Imagenet classification with deep
convolutional neural networks." Advances in neural information processing systems 25 (2012): 1097-1105.](https://image.slidesharecdn.com/imageclassificationslideshare-210816092105/75/2021-8-Image-Classificaiton-11-2048.jpg)

![15
AlexNet [10]は以下の様な8層のアーキテクチャである
当時のGPUはメモリが小さかったので、2枚のGPUに分けて計算を行っている
活性化関数としてReLUを採用(勾配消失対策)
ドロップアウト・Data Augmentationの導入(過学習防止)
これ以降より精度の良いモデルが考案されるので、現在ではあまり使われない
AlexNet (2/2)
[10] Krizhevsky, Alex, Ilya Sutskever, and Geoffrey E. Hinton. "Imagenet classification with deep convolutional
neural networks." Advances in neural information processing systems 25 (2012): 1097-1105. 図も本論文より引用](https://image.slidesharecdn.com/imageclassificationslideshare-210816092105/75/2021-8-Image-Classificaiton-15-2048.jpg)

![17
AlexNet以降CNNを用いたDLが画像認識の中心となり、CNNのモデル
に関する研究が盛んになる
以降2015年のResNet (152層) [12] に至るまで、より深いネットワーク
を学習する方向で研究が進む
AlexNet以降の研究の方向性
[12] He, Kaiming, et al. "Deep
residual learning for image
recognition." Proceedings of
the IEEE conference on
computer vision and pattern
recognition. 2016.](https://image.slidesharecdn.com/imageclassificationslideshare-210816092105/75/2021-8-Image-Classificaiton-17-2048.jpg)
![VGG
VGG 19
VGG [13] は2014年のILSVRCでエラー率7.3%で2
位となったモデルである
右図の様にConv層、Pooling層、FC層からなるシ
ンプルなモデルで、19層ネットワークであるこ
とからVGG 19と呼ばれる
AlexNetと比較して、より深いモデルを学習する
ことで、より高い精度を達成
シンプルな構造ながら高い精度を達成出来るので、
現在でもVGGをベースとしたモデルが使われる
場合もある
[13] Simonyan, Karen, and Andrew Zisserman. "Very deep convolutional
networks for large-scale image recognition." arXiv preprint
arXiv:1409.1556 (2014).
[14] http://datahacker.rs/deep-learning-vgg-16-vs-vgg-19/ より図を引用 18](https://image.slidesharecdn.com/imageclassificationslideshare-210816092105/75/2021-8-Image-Classificaiton-18-2048.jpg)
![[16] Pawara, Pornntiwa, et al. "Comparing local descriptors and bags of visual words
to deep convolutional neural networks for plant recognition." International Conference
on Pattern Recognition Applications and Methods. Vol. 2. SciTePress, 2017.
より上図を引用
19
GoogLeNet [15]は2014年のILSVRCでエラー率6.7%を達成して優勝したモデル
Inception Moduleと呼ばれるモジュールを多層に重ねることで22層ネットワークを
構築(Inception Moduleは2層の畳み込み層を持つ)
GoogLeNet
Inception Module
GoogLeNet
(この図はDropoutとsoftmaxの間のFC層が抜けている)
[15] Szegedy, Christian, et al. "Going deeper with convolutions." Proceedings of
the IEEE conference on computer vision and pattern recognition. 2015.
上図もこちらから引用](https://image.slidesharecdn.com/imageclassificationslideshare-210816092105/75/2021-8-Image-Classificaiton-19-2048.jpg)
![20
AlexNetの8層からGoogLeNetの22層に至るまで、層を深くすることで
精度の向上に成功してきた
しかし、何故100層や200層といった非常に深いモデルではなく、22層
という微妙な層数のモデルを選んだのか?
✓ 層数が30を超えてくると最適化が難しくなり、精度が落ちるから
モデルを深くする難しさ
20層と56層ネットワークの精度を比較すると、訓練・テストデータの両方に対して
56層ネットワークの精度が劣っており、学習が上手く行っていないことがわかる
[12] He, Kaiming, et al. “Deep residual learning for
image recognition.” Proceedings of the IEEE
conference on computer vision and pattern
recognition. 2016. より図を引用](https://image.slidesharecdn.com/imageclassificationslideshare-210816092105/75/2021-8-Image-Classificaiton-20-2048.jpg)
![21
ResNet [12]は2015年のILSVRCで3.6%のエラー率で優勝
したモデルである
人間のエラー率が5.1%と言われ、これを上回った
ResNetではResidual Connectionを導入し、
30層以上のCNNは学習が難しいという課題を解決
ILSVRCで使われたResNetは152層である
Residual Connectionは右図のように、ある層の出力𝐹(𝒙)
に、少し前の層の出力𝒙を足し合わせるという機構である
この接続により、以前の層の情報が失われることを防ぎ、
学習を容易にしていると考えられる
Batch Normalization [17]、He Initialization [18]の導入
ResNet (1/3)
Residual Connection
[12] He, Kaiming, et al. “Deep residual learning for
image recognition.” Proceedings of the IEEE
conference on computer vision and pattern
recognition. 2016. 図も[12] より引用
[17] Ioffe, Sergey, and Christian Szegedy. "Batch
normalization: Accelerating deep network training by
reducing internal covariate shift." International
conference on machine learning. PMLR, 2015.
[18] He, Kaiming & Zhang, Xiangyu & Ren,
Shaoqing & Sun, Jian. “Delving Deep into
Rectifiers: Surpassing Human-Level Performance
on ImageNet Classification”. IEEE International
Conference on Computer Vision. 2015](https://image.slidesharecdn.com/imageclassificationslideshare-210816092105/75/2021-8-Image-Classificaiton-21-2048.jpg)
![22
ResNet (2/3)
ResNetでは、Bottleneck Residual Block (下図右) と呼ばれる 1×1, 3×3, 1×1の
カーネルサイズの畳み込み層を用いたモジュールを用いる場合もある
最初の1×1畳み込み層で次元削減、その後3×3の畳み込みを行った後、最後の
1×1の畳み込みで次元を基に戻すという計算が行われる
Bottleneckを用いることで 3×3の畳み込み演算の入出力次元を減らす事が出来、
パラメータ数を抑えることが出来る(同パラメータ数あたりの表現力の向上)
より深いResNet (ResNet-50/101/152) において、Bottleneck Blockは通常の
Residual Bolck (下図左) の代わりに用いられる
Basic Bottleneck
[12] He, Kaiming, et al. “Deep
residual learning for image
recognition.” Proceedings of the
IEEE conference on computer
vision and pattern recognition. 2016.
より図を引用](https://image.slidesharecdn.com/imageclassificationslideshare-210816092105/75/2021-8-Image-Classificaiton-22-2048.jpg)



![26
ResNet以降のCNNモデルは、Residual Connectionを中心とした様々な構
造を導入することで精度の向上を果たしている
代表的なモデルとして、以下のようなものが挙げられる
Wide Residual Network (Wide ResNet) [19]
ResNeXt [20]
Dense Convolutional Network (DenceNet) [21]
Squeeze-and-Excitation Networks (SENet) [22]
(他にも沢山ある)
Neural Architecture Search (NAS) を用いた、自動アーキテクチャ設計
ResNet以降のCNNモデル
[19] Zagoruyko, Sergey, and Nikos Komodakis. "Wide residual networks." arXiv preprint arXiv:1605.07146 (2016).
[20] Xie, Saining, et al. "Aggregated residual transformations for deep neural networks." Proceedings of the IEEE conference on computer vision and pattern recognition. 2017.
[21] Huang, Gao, et al. "Densely connected convolutional networks." Proceedings of the IEEE conference on computer vision and pattern recognition. 2017.
[22] Hu, Jie, Li Shen, and Gang Sun. "Squeeze-and-excitation networks." Proceedings of the IEEE conference on computer vision and pattern recognition. 2018.](https://image.slidesharecdn.com/imageclassificationslideshare-210816092105/75/2021-8-Image-Classificaiton-26-2048.jpg)
![27
Wide ResNet [19]は、ResNetのモデルの深さを抑えつつ、チャネル数
を増やすことで学習速度と精度を向上させることに成功
ResNetの、非常に深いモデルを学習して精度を高めることが出来るが、
深いモデルの学習には非常に時間がかかるという弱点を緩和
Wide ResNetのモデルは一般的に ‘WRN-D-K’ の様に表され、Dが層数、
Kが通常のResNetを基準としたチャネル数を示す
(例)WRN-28-10(28層のチャネル数10倍のWide ResNet)
Wide ResNet (1/2)
[19] Zagoruyko, Sergey, and Nikos Komodakis. "Wide
residual networks." arXiv preprint arXiv:1605.07146 (2016).](https://image.slidesharecdn.com/imageclassificationslideshare-210816092105/75/2021-8-Image-Classificaiton-27-2048.jpg)
![28
右図にResNetおよびWRNの学習時間と精度を示す
縦軸がforward+backwardにかかる時間、棒の左の値が
CIFAR10に対するエラー率
青棒が通常のResNet、赤棒がWRNを示している
同じ精度を出すために必要な計算時間が、圧倒的
にWRNの方が小さい
ResNet-1004とWRN-40-4がほぼ同じ精度だが、時間に
は約8倍もの差がある
ただし、計算時間は短くてもパラメータ数はWRN
の方が多いこともあるので注意が必要
ResNet-1004の10.2Mに対し、WRN-28-10は36.5M
Wide ResNet (2/2)
[19] Zagoruyko, Sergey, and Nikos Komodakis. “Wide residual
networks.” arXiv preprint arXiv:1605.07146 (2016). より図を引用](https://image.slidesharecdn.com/imageclassificationslideshare-210816092105/75/2021-8-Image-Classificaiton-28-2048.jpg)
![ ResNeXt [20]はResNetのBottleneck Block (下図左) をベースとし、複数の
パスに分割することで (Grouped Convolution) パラメータ数を削減 (下図
右)
パラメータ数あたりの表現力の向上
下図右のa~cは全て等価な表現である
ILSVRC 2016で2位となったモデル
ResNeXt
29
Bottleneck
(ResNet)
Module of ResNeXt
[20] Xie, Saining, et al. "Aggregated residual transformations
for deep neural networks." Proceedings of the IEEE
conference on computer vision and pattern recognition. 2017.
下図も本論文より引用](https://image.slidesharecdn.com/imageclassificationslideshare-210816092105/75/2021-8-Image-Classificaiton-29-2048.jpg)
![ DenseNet [21] はResNetのResidual Connection
を発展させ、より密なskip connectionを持つ
Dense Block (左図) を多段に重ねたCNN (下図)
Dense Blockのskip connectionはResNetとは異な
り、足し合わせではなくConcat (特徴マップの結
合) によって行われる
CVPR 2017のBest Paper
DenseNet
30
[21] Huang, Gao, et al. "Densely connected convolutional networks." Proceedings
of the IEEE conference on computer vision and pattern recognition. 2017.
図も本論文より引用](https://image.slidesharecdn.com/imageclassificationslideshare-210816092105/75/2021-8-Image-Classificaiton-30-2048.jpg)
![31
SENet [22]は下図のSqueeze-and-Excitation block (SE Block) を他のネッ
トワークと組み合わせたCNNである
SE Blockを用いることで、各特長マップに対する重要度を示す重みが計算
され (下図の𝐅sq ∙ , 及び𝐅ex(∙, 𝐖)で計算)、特徴マップとの積を取ることで
(𝐅s𝑐𝑎𝑙𝑒 ∙,∙ で計算) 重要度の高い特徴マップがより強調される
考え方としてはAttentionに近い
SENet (1/2)
[22] Hu, Jie, Li Shen, and Gang Sun.
"Squeeze-and-excitation
networks." Proceedings of the IEEE
conference on computer vision and
pattern recognition. 2018.
図も本論文より引用
Squeeze-and-Excitation block](https://image.slidesharecdn.com/imageclassificationslideshare-210816092105/75/2021-8-Image-Classificaiton-31-2048.jpg)
![32
SENetは、下図の様にGoogLeNet, ResNet等のモデルにSE Blockを加える
ことにより、モデルを構築する
ResNeXtをベースとしたSENetはILSVRC 2017において、
エラー率2.3%を達成して優勝した
SENet (2/2)
[22] Hu, Jie, Li Shen, and Gang Sun.
“Squeeze-and-excitation
networks.” Proceedings of the IEEE
conference on computer vision and
pattern recognition. 2018.
より図を引用](https://image.slidesharecdn.com/imageclassificationslideshare-210816092105/75/2021-8-Image-Classificaiton-32-2048.jpg)

![ 強化学習 (Reinforcement Learning) を用いたNAS
コントローラ (RNN) を用いて、CNNの層のハイパーパラメータ(フィルタ
サイズ・ストライド等)を順次定義することでCNN全体を定義する
定義されたCNNの精度Rを報酬として方策勾配を計算し、コントローラを
アップデート
学習が進むと、より精度の高いCNNが生成されるようになる
NAS with Reinforcement Learning [23] (1/3)
[23] Zoph, Barret, and Quoc V. Le. "Neural architecture
search with reinforcement learning.“, In Proc. of
International Conference on Computer Vision, 2017
図も本論文より引用
34](https://image.slidesharecdn.com/imageclassificationslideshare-210816092105/75/2021-8-Image-Classificaiton-34-2048.jpg)
![35
コントローラは以下のRNNで実現され、各レイヤーのハイパーパラメータ
(フィルタサイズ、ストライド、スキップコネクションの有無、フィルタ数)を出力
各出力は事前に定義した以下の探索空間から選択される
フィルタ数[24, 36, 48, 64]、フィルタサイズ[1, 3, 5, 7]、ストライド[1, 2, 3]
事前に定めた層数を超えたら生成をストップする
層数は学習初期には小さい値とし、順次大きくしていく
※コントローラの学習は強化学習で行われるが、本資料では詳細は割愛する
NAS with Reinforcement Learning (2/3)
[23] Zoph, Barret, and Quoc V. Le. "Neural
architecture search with reinforcement
learning.“, In Proc. of International
Conference on Computer Vision, 2017
より図を引用](https://image.slidesharecdn.com/imageclassificationslideshare-210816092105/75/2021-8-Image-Classificaiton-35-2048.jpg)
![36
層数15としたときの結果を左図に示す
FH, FWがフィルタサイズの縦・横
Nはフィルタ数
本モデルのスキップコネクションはConcatenate
(Residual Connectionではない)
生成したCNNに対し50 epoch (CIFAR10) の学習をし
て精度の検証をする、ということを数千回単位で行う
ので、莫大な計算量を必要とする
本研究では探索に800GPU×28daysを必要とした
ここでは紹介しないがCNN以外にもリカレントネット
ワークの構造探索も本研究では行っている
NAS with Reinforcement Learning (3/3)
[23] Zoph, Barret, and Quoc V. Le.
"Neural architecture search with
reinforcement learning.“, In Proc.
of International Conference on
Computer Vision, 2017
より図を引用](https://image.slidesharecdn.com/imageclassificationslideshare-210816092105/75/2021-8-Image-Classificaiton-36-2048.jpg)
![37
CNN全体ではなく、CNNを構成するセル(ブロック)を学習
ResNetやDenseNet等のモデルがResidual BlockやDense Blockといったブ
ロック(セル)単位で構成されていることから着想
探索空間を「ネットワーク全体」から「セル」に絞ることで、探索に必要な
計算量を削減することに成功し、また精度面でもNAS with RLを上回る
探索によって得られたセルは、他のデータセットにも有効に適応可能
CIFAR10を用いて得られたセルを、より大きなデータセットであるImageNetに転移す
ることで、直接ImageNetを用いて探索するよりも計算量を削減できる
学習はNAS with RLと同様、強化学習ベースで行われる
NASNet [24] (1/4)
[24] Zoph, Barret, et al. "Learning transferable architectures for scalable image recognition.
"Proceedings of the IEEE conference on computer vision and pattern recognition. 2018.](https://image.slidesharecdn.com/imageclassificationslideshare-210816092105/75/2021-8-Image-Classificaiton-37-2048.jpg)
![38
学習では、まずセルの繰り返し構造を人間が決める(左図)
CIFAR10とImageNetで繰り返し構造は異なるが、用いるセルは共通
NASを用いてNormal CellとReduction Cell (特徴マップを半
分・特徴マップ数を倍にするセル) の構造を生成・探索
上記の探索では、計算量削減のためCIFAR10で行い、得られ
た最適なセルをImageNet等の他のデータセットにも用いる
NASNet (2/4)
[24] Zoph, Barret, et al. "Learning
transferable architectures for scalable
image recognition." Proceedings of
the IEEE conference on computer
vision and pattern recognition. 2018.
より図を引用](https://image.slidesharecdn.com/imageclassificationslideshare-210816092105/75/2021-8-Image-Classificaiton-38-2048.jpg)
![39
NASNet (3/4)
セルの構造は下図左のRNNコントローラで生成される
まず、二つの隠れ状態を「直前のセルの出力、二つ前のセルの出力、以前の繰り
返しで生成された出力」から選択
それぞれの隠れ状態に対する変換を下図右の中から選択
変換後の隠れ状態の結合方法を選択
例として左図の様な計算方法が出漁される
これを既定の回数(下図左ではB timesなのでB回)繰り返すことでっ
セルの構造を決定
[24] Zoph, Barret, et al. "Learning transferable architectures
for scalable image recognition." Proceedings of the IEEE
conference on computer vision and pattern recognition. 2018.
より図を引用](https://image.slidesharecdn.com/imageclassificationslideshare-210816092105/75/2021-8-Image-Classificaiton-39-2048.jpg)
![40
NASNet (4/4)
[24] Zoph, Barret, et al. "Learning
transferable architectures for scalable
image recognition." Proceedings of
the IEEE conference on computer
vision and pattern recognition. 2018.
より図を引用
結果として以下のセルが生成された
要した計算量は500GPU×4days
NAS with RLの800GPU×28daysと比較すると約10分の1となっているが、
以前として莫大な計算量である](https://image.slidesharecdn.com/imageclassificationslideshare-210816092105/75/2021-8-Image-Classificaiton-40-2048.jpg)
![41
莫大な計算量が必要だったNASの計算量を大幅に削減
1GPU×0.45 daysでの学習が可能(NASNetから1000倍以上の高速化)
NASNetよりやや精度が劣るが、精度面でも優秀
コントローラにより生成される各CNN間で重みをシェアすることによって、
各モデルを最初から学習させる必要が無い
従来のNASでは、数千回単位でCNNを最初から学習する必要があった
NASNetで導入したセル毎の構造探索も用いられている
少々煩雑なので、詳細を知りたい方は論文や解説記事を参照
Efficient NAS [25]
[25] Pham, Hieu, et al. "Efficient neural architecture search via parameters
sharing." International Conference on Machine Learning. PMLR, 2018.](https://image.slidesharecdn.com/imageclassificationslideshare-210816092105/75/2021-8-Image-Classificaiton-41-2048.jpg)
![42
DARTS (Differentiable ARchiTecture Search) [26]
強化学習ではなく勾配降下法によってネットワークのセルの構造を探索
離散的なネットワーク構造を連続に緩和することによって、微分可能に
構造探索+モデルの学習を一気に行うことが可能となるため
計算量を大幅に削減することが可能に
1GPU daysでの学習が可能 (Efficient NASと同じくらい)
DARTS (1/2)
[26] Liu, Hanxiao, Karen Simonyan, and Yiming Yang. "Darts: Differentiable architecture
search.“, In Proc. International Conference on Learning Representations, 2019](https://image.slidesharecdn.com/imageclassificationslideshare-210816092105/75/2021-8-Image-Classificaiton-42-2048.jpg)
![43
まず、下図(a)の様な有向非巡回グラフを仮定
次に、下図(b)の様にグラフの各エッジを複製し、それぞれを異なる演算oに割り当て
式 (1)の重み付き和で出力が計算される(連続値に緩和)
式 (1) の重みαと各演算oに含まれるパラメータを同時に学習(下図(c))
重みが大きい演算のみを残すことで、セルの構造を決定(下図(d), 式(2))
DARTS (2/2)
(1)
(2)
[26] Liu, Hanxiao, Karen Simonyan, and Yiming
Yang. "Darts: Differentiable architecture search.“,
In Proc. International Conference on Learning
Representations, 2019 より図を引用](https://image.slidesharecdn.com/imageclassificationslideshare-210816092105/75/2021-8-Image-Classificaiton-43-2048.jpg)
![[27] Real, Esteban, et al. "Large-scale evolution
of image classifiers." International Conference
on Machine Learning. PMLR, 2017.
より図を引用
44
進化的アルゴリズムを用い、ランダムに複数のネットワークを生成・学習、精度の良
いものを残し・悪いものを削除、突然変異で新たなネットワークを作成、を繰り返す
ことで学習
下図で示すように、徐々に性能の良いネットワークが学習されていく
進化的アルゴリズムに基づくNAS](https://image.slidesharecdn.com/imageclassificationslideshare-210816092105/75/2021-8-Image-Classificaiton-44-2048.jpg)


![ 限られた計算リソースで出来るだけ高い精度を実現を目指したCNN
この頃になると、一般にCNNは深さ (層数)・幅 (チャネル数)・特徴マップサイズ (解
像度) を上げることで性能が向上することが分かってきており、当研究ではどのよう
な配分でこれらを大きくするのが最も効率が良いかを探索
更にNeural Architecture Searchで効率の良いベースモデルを定義し、これを基準に
スケールアップすることで、従来のモデルよりも大幅に小さいパラメータ数、計算量
で同等以上の精度を達成
アーキテクチャ追及の集大成ともいえる研究で、これ以降NASによるアーキテクチャ
探索でSOTAが更新されることは殆ど無くなった印象
現在でもEfficientNetは最先端のCNNとされ、CNNでSOTAを狙う研究の多くがEfficientNetをベー
スとして、新たな要素を付け加えたりしている
47
EfficientNet [28] (1/4)
[28] Tan, Mingxing, and Quoc Le. "Efficientnet: Rethinking model
scaling for convolutional neural networks." International
Conference on Machine Learning. PMLR, 2019.](https://image.slidesharecdn.com/imageclassificationslideshare-210816092105/75/2021-8-Image-Classificaiton-47-2048.jpg)
![48
十分なデータが利用可能ならば、基本的にCNNは大きい方が精度が高いが、パラメータ数や計算
量、メモリ量が大きくなる弱点がある
CNNのスケール方法は以下の図の様に、ベースライン(a)を基準にチャネル数を増やす(b)、層数
を増やす(c)、入力の解像度を高める(d)がある
チャネル数・層数・解像度の3つをバランスよく大きくする必要があり、どれか一つだけ大きくし
ても他の要素がボトルネックになって精度が頭打ちになりやすい
ResNetを単純に1000層以上としても精度が劇的には向上しないのはこれが原因と思われる
EfficientNet (2/4)
[28] Tan, Mingxing, and Quoc Le. "Efficientnet:
Rethinking model scaling for convolutional
neural networks." International Conference on
Machine Learning. PMLR, 2019. より図を引用](https://image.slidesharecdn.com/imageclassificationslideshare-210816092105/75/2021-8-Image-Classificaiton-48-2048.jpg)

![50
モデルのスケールアップのベースとなるモデルは、モデルの精度と計算量のトレードオ
フを考慮したNASであるMnasNetを用いて探索
探索されたモデルをEfficientNet-B0とし、これをベースにB1,...,B7 までスケールアップ
結果として、以下の図で示すように計算量・パラメータ数と精度のトレードオフが従来
のモデルよりも優れたモデルを構築することに成功
EfficientNet (4/4)
[28] Tan, Mingxing, and Quoc Le.
"Efficientnet: Rethinking model
scaling for convolutional neural
networks." International
Conference on Machine Learning.
PMLR, 2019. より図を引用](https://image.slidesharecdn.com/imageclassificationslideshare-210816092105/75/2021-8-Image-Classificaiton-50-2048.jpg)


![54
3億枚もの超大規模データセットを用いて巨大なCNNモデルを事前学習し、
各目的タスクに対するファインチューニングを行うことで、精度を劇的に向
上できることを示した
画像分類だけでなく、物体検出に対する有効性も確認
恐らく他のタスクにも効くと考えられる
数億枚規模のデータセットを用いた学習のノウハウは殆ど蓄積されていな
かったので(当たり前)、精度を出すための試行錯誤もしている
Big Transfer (BiT) [29] (1/3)
[29] Kolesnikov, Alexander, et al. "Big transfer (bit): General visual representation
learning.“, In Proc. of European Conference on Computer Vision, 2020.](https://image.slidesharecdn.com/imageclassificationslideshare-210816092105/75/2021-8-Image-Classificaiton-54-2048.jpg)
![[29] Kolesnikov, Alexander, et al. "Big
transfer (bit): General visual representation
learning.“, In Proc. of European
Conference on Computer Vision, 2020.
より左図を引用
[30] Sun, Chen, et al. "Revisiting
unreasonable effectiveness of data in
deep learning era." Proceedings of the
IEEE international conference on
computer vision. 2017.
55
メインの実験では5種類の大きさのResNetに対して、3種類の大きさのデータセット
で事前学習し、各タスクに対してファインチューニングし、精度を比較している
3種類のデータは、小さい方からILSVRCコンペ用のデータセット(128万枚)、ImageNet全体(1420
万枚)、Googleが所持している非公開データJFT-300M(3億枚) [30]
5種類の大きさのResNetはResNet-50からResNet-152x4(x4はチャネル数4倍を意味する)
3つのタスクに対して、モデルが十分な大きさがあれば、事前学習データセットを超
大規模にすることにより劇的な精度向上が可能(下図)
モデルが小さい場合、精度が途中で頭打ちになる
BiT (2/3)](https://image.slidesharecdn.com/imageclassificationslideshare-210816092105/75/2021-8-Image-Classificaiton-55-2048.jpg)
![[29] Kolesnikov, Alexander, et al. "Big
transfer (bit): General visual
representation learning.“, In Proc. of
European Conference on Computer
Vision, 2020. より図を引用
56
大規模データによる事前学習モデルを用いることで、データが非常に少ない状況下で
の学習でも高い精度を実現(下図)
巨大なモデル (ResNet-152x4は約10億パラメータ) を超大規模データセットで学習す
る為には当然莫大な学習コストがかかる
ResNet-152x4をJFT-300Mで学習する際には数万GPU hoursの計算を要した
本研究はGoogle Brainによるものであり、深層学習に特化したアクセラレータであるTPU-V3
を512枚使って学習を行っている
BiT (3/3)](https://image.slidesharecdn.com/imageclassificationslideshare-210816092105/75/2021-8-Image-Classificaiton-56-2048.jpg)

![59
2020年後半あたりから、自然言語処理で用いられているTransformer [31] を
用いた画像認識が高い精度を実現できる事が示されてきた
Transformerでは、Attentionと呼ばれる演算を用いることで、近年のデファクトスタ
ンダードである畳み込み演算を一切用いない
2021年7月末現在、TransformerとCNNのどちらが優れているのかの決着は
ついていないが、CNNと比較してTransformerの研究の歴史は浅いので、今
後Transformerが化ける可能性は十分にあると思う
現段階では、可能性を感じ取った非常に多くの研究チームがTransformerに
参入しており、混沌とした状況が続いている印象
どの手法が生き残るか不透明なので、本資料ではとりあえずTransformer×画像認識
の先駆けとなったVision Transformer (ViT) [32] をメインで説明する
Transformerを用いた画像認識
[31] Vaswani, Ashish, et al. “Attention is all you need.” Advances in neural information processing systems. 2017.
[32] Dosovitskiy, Alexey, et al. "An image is worth 16x16 words: Transformers for image recognition at scale." arXiv preprint arXiv:2010.11929 (2020).](https://image.slidesharecdn.com/imageclassificationslideshare-210816092105/75/2021-8-Image-Classificaiton-59-2048.jpg)
![60
TransformerはAttentionと呼ばれる機構を用いたニューラルネットワークで
あり、2017年に自然言語処理 (NLP) 用モデルとして登場した
NLPの様々なタスクに対して圧倒的な性能を実現し、以前のLSTM等の回帰型
ニューラルネットワークの手法に取って代わった
これ以前にも回帰型NN+Attentionモデルは存在したが、Transformerでは回帰型
NNは使われていない (Attention is All You Need)
Transformerを発展させた大規模モデルであるBERTやGPTが登場し、NLP
ではいち早く大規模モデル+大規模データの流れが到来
その後、画像認識や音声認識、点群認識などにも応用される
最近話題になったタンパク質構造予測のAlphaFold [33]もTransformerがベース
Transformerとは
[33] Senior, Andrew W., et al. "Improved protein structure prediction using potentials from deep learning." Nature 577.7792 (2020): 706-710.](https://image.slidesharecdn.com/imageclassificationslideshare-210816092105/75/2021-8-Image-Classificaiton-60-2048.jpg)
![61
Transformerに限らず自然言語処理では以下の様に単語埋め込みが行われる
単語埋め込み
[34].https://www.slideshare.net/DeepLear
ningJP2016/dltransformer-vit-perceiver-
frozen-pretrained-transformer-etc
より図を引用](https://image.slidesharecdn.com/imageclassificationslideshare-210816092105/75/2021-8-Image-Classificaiton-61-2048.jpg)
![62
Attentionは”Query”, “Key”, “Value”の3要素を用いて計算される。
Queryを𝑄 ∊ ℝ𝑛×𝑑𝑞、KeyををK ∊ ℝ𝑛𝑣×𝑑𝑞、ValueをV ∊ ℝ𝑛𝑣×𝑑𝑣として
𝐴𝑡𝑡 𝑄, 𝐾, 𝑉 = 𝑠𝑜𝑓𝑡𝑚𝑎𝑥
𝑄𝐾𝑇
𝑑𝑞
𝑉
と表すことができる (Dot-Product Attention)。
この式の意味は「queryベクトルとkeyベクトルの類似度を求め、 そ
の正規化した重みをvalueベクトルに適用して値を取り出す」と解釈
でき、出力は𝑉の行ごとの重み付き和である。
Attention
[31] Vaswani, Ashish, et al. “Attention
is all you need.” Advances in neural
information processing systems. 2017.
より図を引用, 一部改変](https://image.slidesharecdn.com/imageclassificationslideshare-210816092105/75/2021-8-Image-Classificaiton-62-2048.jpg)
![63
CNNの特徴量が複数のチャンネルを持つように、Attentionも複数のチャンネル (ヘッ
ドと呼ばれる) を並列させて表現力を高めることができる。
Multi-head Attention
[31] Vaswani, Ashish, et al.
"Attention is all you need."
Advances in neural information
processing systems. 2017.
より図を引用](https://image.slidesharecdn.com/imageclassificationslideshare-210816092105/75/2021-8-Image-Classificaiton-63-2048.jpg)
![Positional Encoding
64
[35] “Visual Guide to Transformer
Neural Networks – (Episode 1)
Position Embedding” (Youtube)
より図を引用](https://image.slidesharecdn.com/imageclassificationslideshare-210816092105/75/2021-8-Image-Classificaiton-64-2048.jpg)
![65
縦が位置、横が埋め込みベクトルの次元方向に対応
Positional Encoding 2
[36] “Transformer Architecture: The Positional Embedding” (Blog) より図を引用](https://image.slidesharecdn.com/imageclassificationslideshare-210816092105/75/2021-8-Image-Classificaiton-65-2048.jpg)
![66
(分類問題ではDecoderは使われない)
Transformer Encoderのアーキテクチャ
[31] Vaswani, Ashish, et al.
"Attention is all you need."
Advances in neural information
processing systems. 2017.
より図を引用](https://image.slidesharecdn.com/imageclassificationslideshare-210816092105/75/2021-8-Image-Classificaiton-66-2048.jpg)
![ ピクセルをトークンとして扱うこともできるが、数が多すぎて計算量が爆発
この問題の解決方法は手法により異なる(後述)
67
自然言語処理の「単語」に相当するトークンを画像認識ではどう設定するか?
画像認識におけるトークン
[34].https://www.slideshare.net/DeepLear
ningJP2016/dltransformer-vit-perceiver-
frozen-pretrained-transformer-etc
より図を引用](https://image.slidesharecdn.com/imageclassificationslideshare-210816092105/75/2021-8-Image-Classificaiton-67-2048.jpg)
![68
Vision Transformer [32]は、画像認識において畳み込みを用いずに
Attention用いて最高精度を達成した最初の研究 (Google Brain)
画像を一定サイズのパッチに分割してトークンとみなすことで、自然言語処
理のTransformerをほぼそのまま用いている
Big Transferと同じように、超大規模なデータセットによる事前学習+ファ
インチューニングも行っている
画像認識でもTransformerがCNNを駆逐するのではないかと注目が集まった
2021年7月末現在では駆逐には至っていない
Vision Transformer (ViT) (1/4)
[32] Dosovitskiy, Alexey, et al. "An image is worth 16x16 words: Transformers
for image recognition at scale." arXiv preprint arXiv:2010.11929 (2020).](https://image.slidesharecdn.com/imageclassificationslideshare-210816092105/75/2021-8-Image-Classificaiton-68-2048.jpg)
![69
ViTは以下の様な構造であり、画像を以下の図の様なパッチに分割してトー
クンとみなし、これを入力データとする
ViT (2/4)
[32] Dosovitskiy, Alexey, et al. "An image
is worth 16x16 words: Transformers for
image recognition at scale." arXiv
preprint arXiv:2010.11929 (2020).
より図を引用](https://image.slidesharecdn.com/imageclassificationslideshare-210816092105/75/2021-8-Image-Classificaiton-69-2048.jpg)
![70
ViTではパッチサイズは基本16x16で、画像サイズは自由(トークンの数は可変)
自然言語処理で自由な長さの単語を扱えることに相当する
最初にCLSトークンと呼ばれる特殊なトークンが用いられ、最後のクラス分類の際に用いられる
各パッチは一次元に平滑化され、線形変換によって埋め込みベクトルに変換
最も大きいモデルでは層数32, ヘッド数16, 埋め込みベクトル次元1280
ViT (3/4)
[32] Dosovitskiy, Alexey, et al. "An image
is worth 16x16 words: Transformers for
image recognition at scale." arXiv
preprint arXiv:2010.11929 (2020).
より図を引用](https://image.slidesharecdn.com/imageclassificationslideshare-210816092105/75/2021-8-Image-Classificaiton-70-2048.jpg)
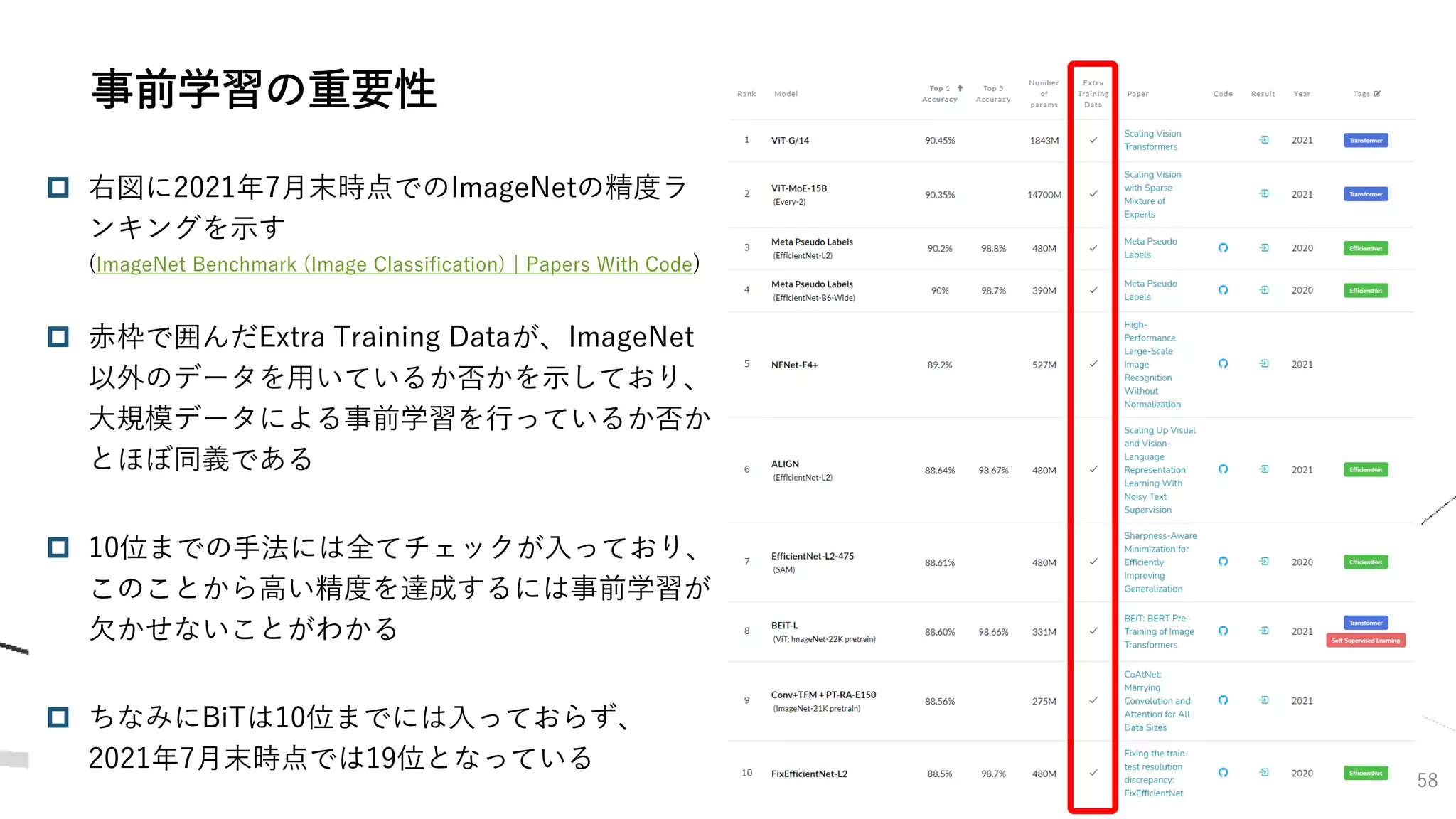
![71
ViTはBiTをやや上回る精度を達成したが、高い精度を出すためには超大規模データに
よる事前学習が必要不可欠
データ数が少ないときは、BiTを大きく下回る結果となった
CNNでは「畳み込み演算が画像に対して有効である」という仮定が置かれていたが、
Transformerではそのような仮定が無い分、データ量で補う必要がある?
ViT (4/4)
[32] Dosovitskiy, Alexey, et al.
"An image is worth 16x16 words:
Transformers for image
recognition at scale." arXiv
preprint arXiv:2010.11929 (2020).
より図を引用](https://image.slidesharecdn.com/imageclassificationslideshare-210816092105/75/2021-8-Image-Classificaiton-71-2048.jpg)

![73
2021年5月に、今度はMLPのみでCNNもAttentionすらも必要しない画像認
識手法 MLP-Mixer [37] が提案され、SOTAではないものの高い精度を達成
MLP×画像認識
[37] Tolstikhin, Ilya, et al.
"Mlp-mixer: An all-mlp
architecture for vision." arXiv
preprint arXiv:2105.01601 (2021).
より図を引用](https://image.slidesharecdn.com/imageclassificationslideshare-210816092105/75/2021-8-Image-Classificaiton-73-2048.jpg)
![74
データが少数な状況下では、CNNは勿論Transformer (VIT)よりも低精度
下の図は、ImageNetを用いた5-shot classificaitonに対して、事前学習に用いるデー
タの数を変化させた場合の精度をMixer, BiT, ViTで比較したもの
MLP×画像認識
[37] Tolstikhin, Ilya, et al.
"Mlp-mixer: An all-mlp
architecture for vision." arXiv
preprint arXiv:2105.01601 (2021).
より図を引用](https://image.slidesharecdn.com/imageclassificationslideshare-210816092105/75/2021-8-Image-Classificaiton-74-2048.jpg)




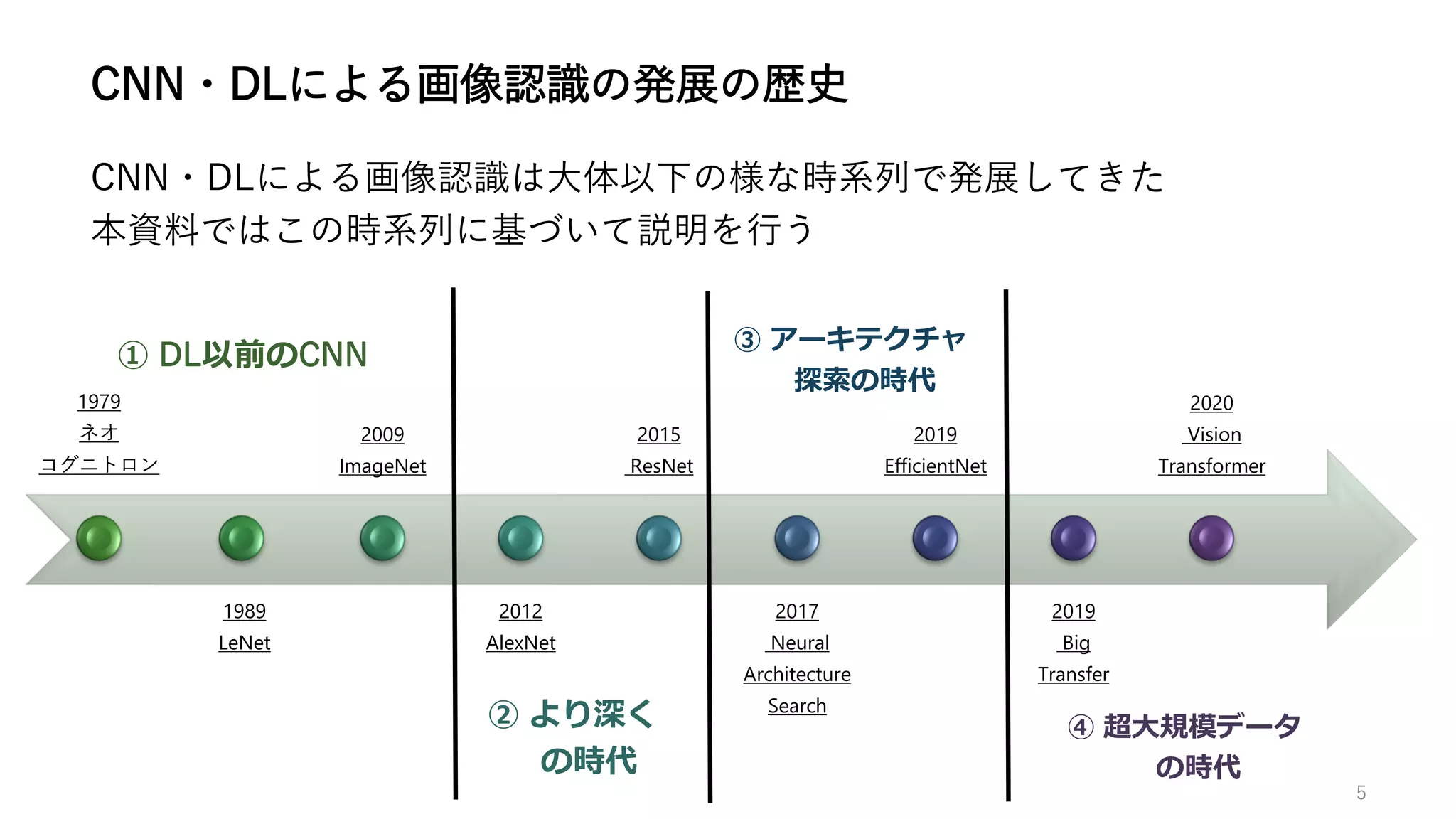
最新版はこちら:https://www.slideshare.net/awful/20223image-classificaiton 本資料は2021年度松尾研究室サマースクール画像認識第一回の講義で用いた資料である。 本資料では、近年画像認識において高い性能を発揮し続けているDeep Learningについて、Image Classificationに着目して技術の発展の歴史を解説する。 深層学習以前のCNN黎明期から、最新のVision TransformerやMLP-Mixerまでを網羅的にカバーする資料である。








![SSII2021 [OS2-02] 深層学習におけるデータ拡張の原理と最新動向](https://cdn.slidesharecdn.com/ss_thumbnails/os2-03latest-210610045610-thumbnail.jpg?width=640&height=640&fit=bounds)













![[DL輪読会]ICLR2020の分布外検知速報](https://cdn.slidesharecdn.com/ss_thumbnails/iclr2020ood-190927011524-thumbnail.jpg?width=640&height=640&fit=bounds)





















![[Japan Tech summit 2017] MAI 001](https://cdn.slidesharecdn.com/ss_thumbnails/techsummit2017pdfmai001-171115034129-thumbnail.jpg?width=640&height=640&fit=bounds)











