MLOps に基づく AI/ML 実運用最前線 ~画像、動画データにおける MLOps 事例のご紹介~ (映像情報メディア学会2021年冬季大会企画セッション 発表資料) 2021年12月16日 NTTデータ 山口 永



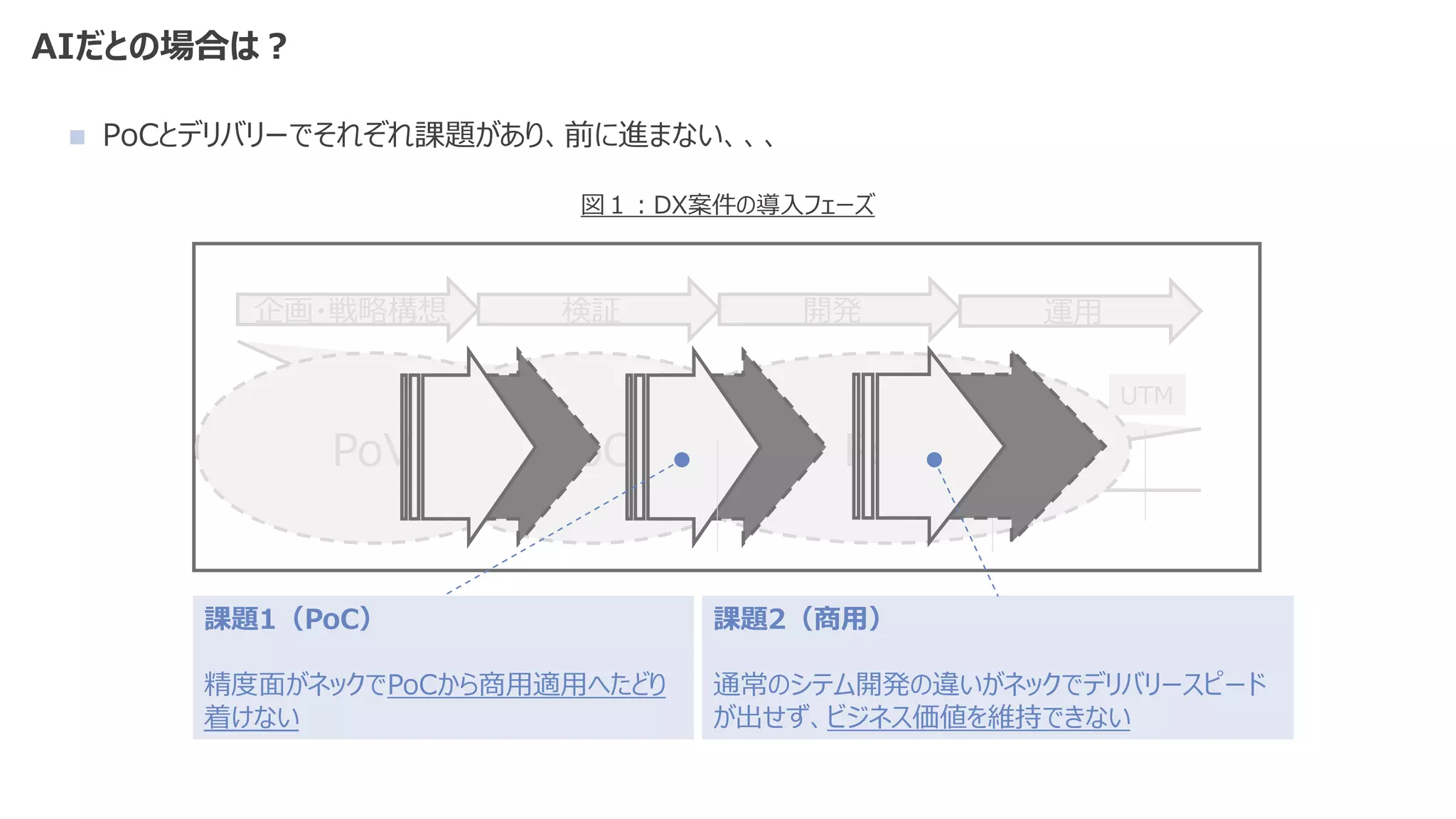
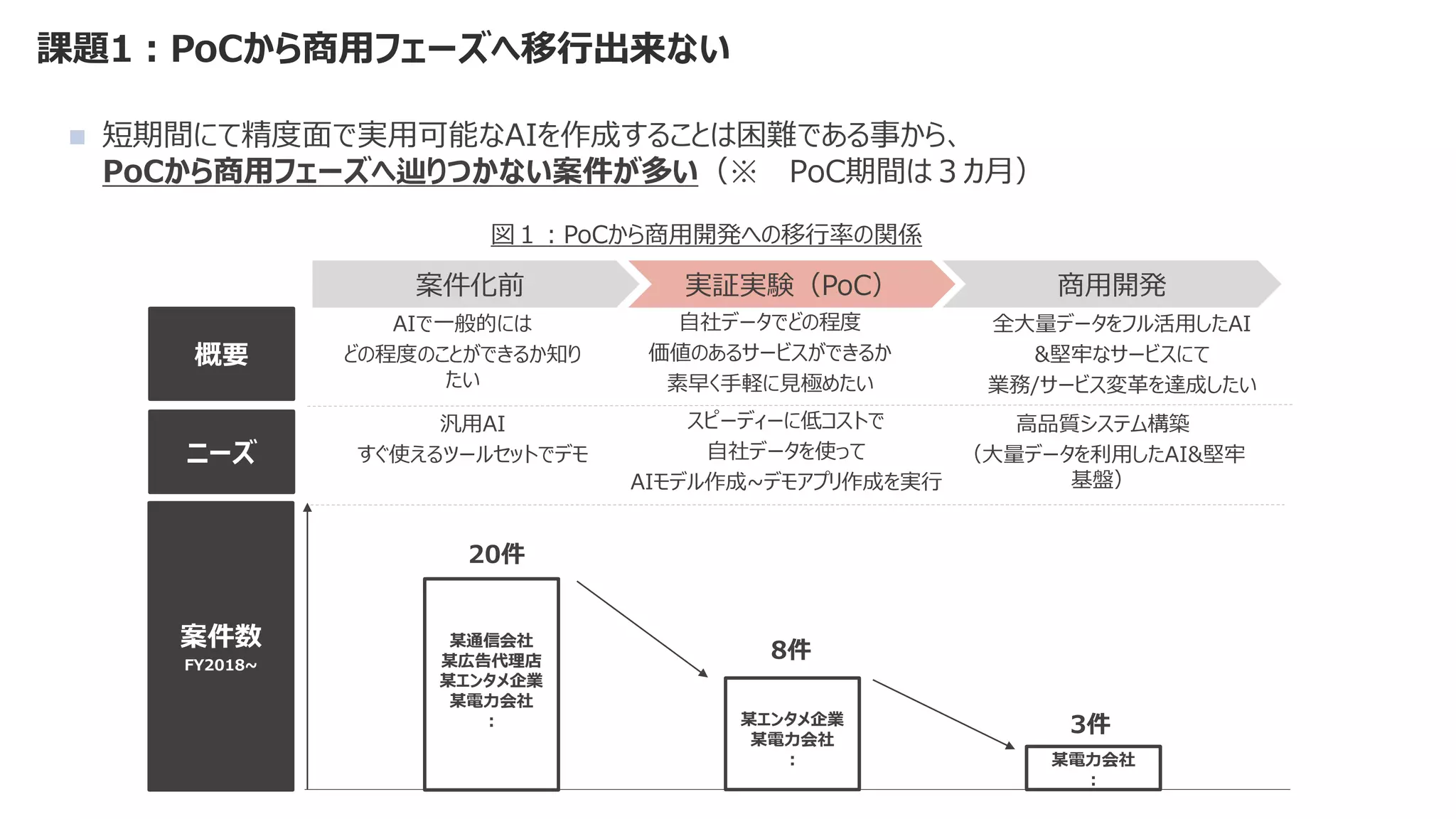

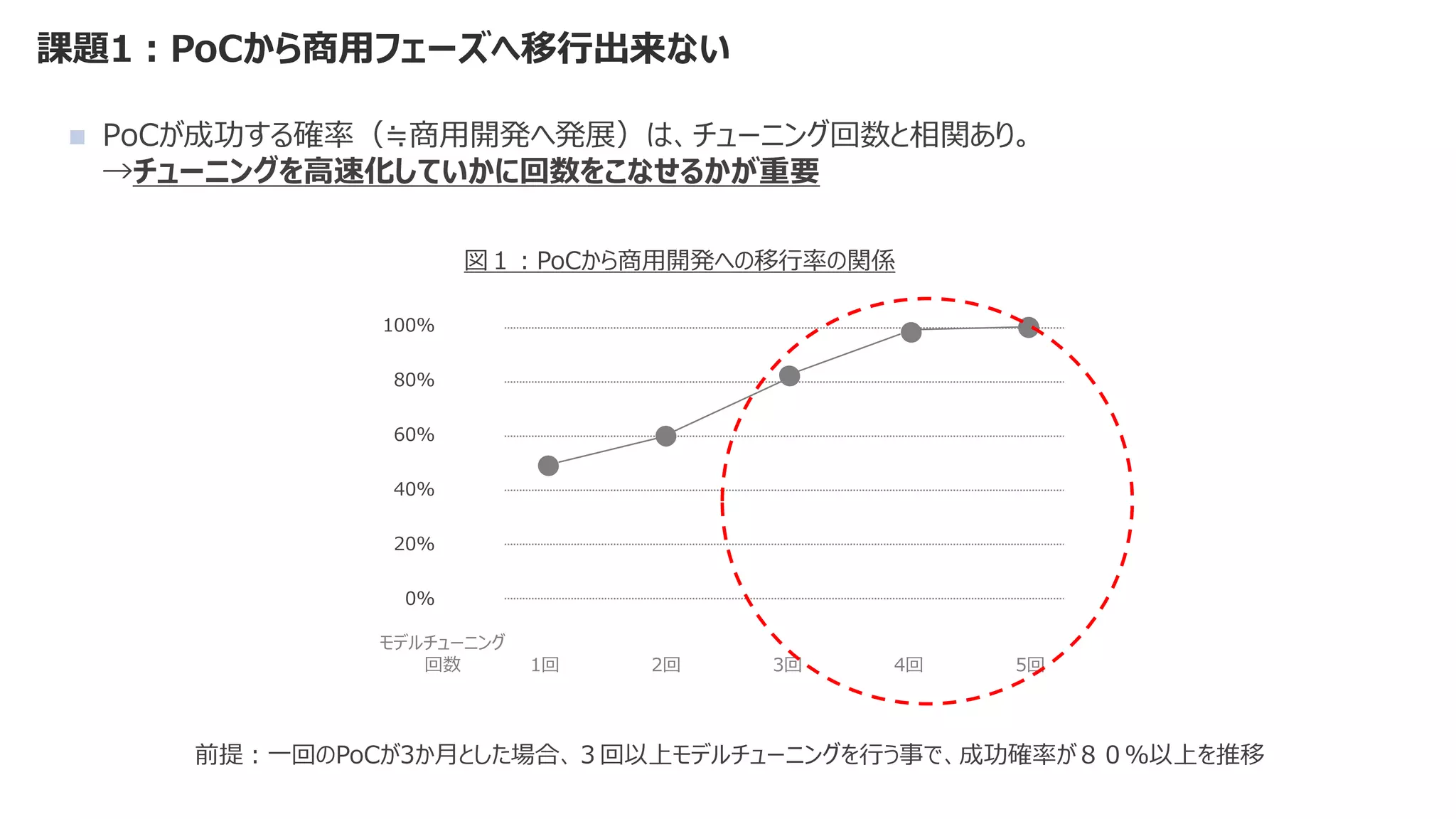
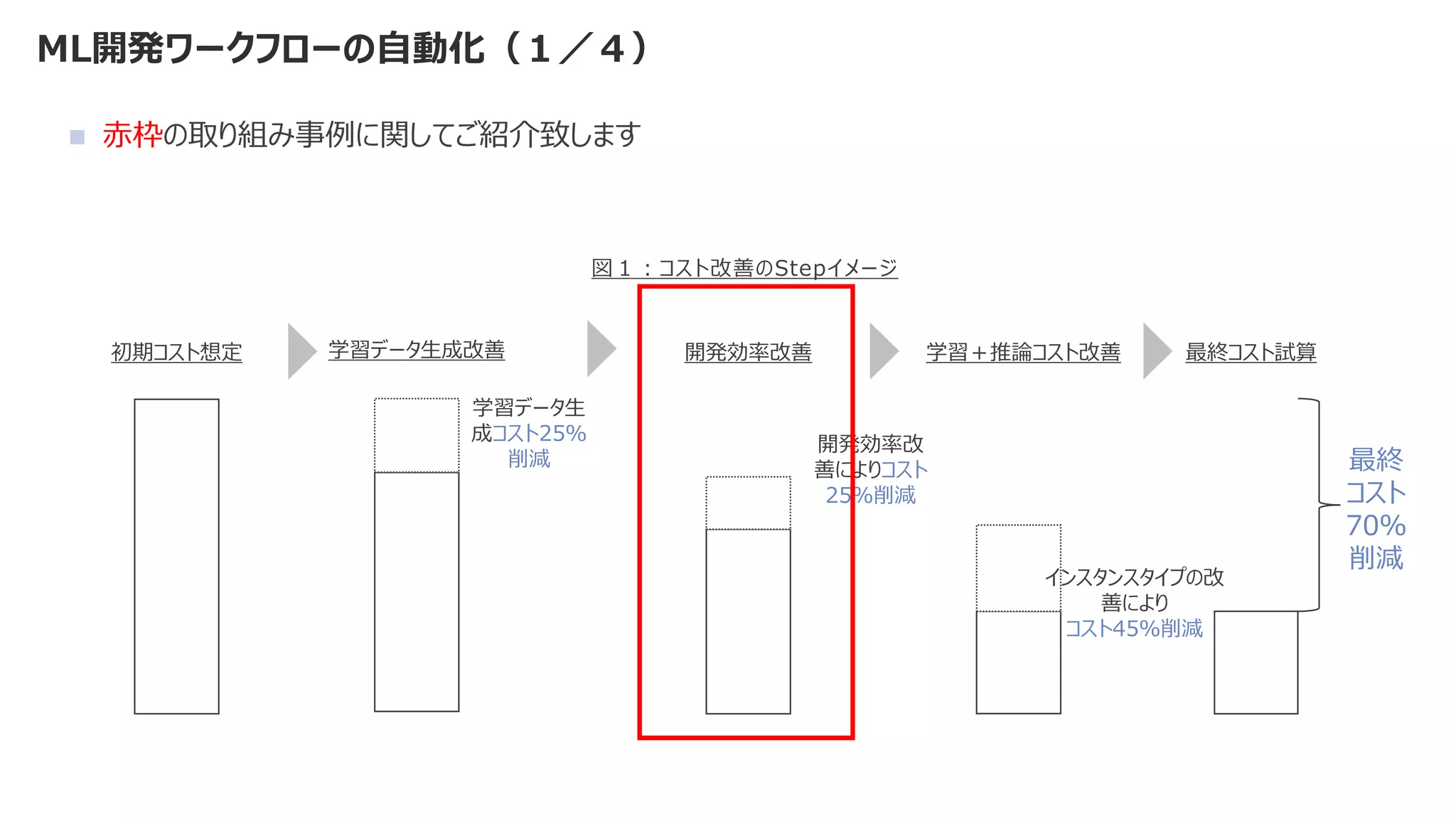
![課題2:デリバリースピードが出せずビジネス価値が維持できない
図1:[Sculley, 2015] より翻訳をして引用
URL:https://papers.nips.cc /paper/5656-hidden-technical-debt-in-machine-learning-systems.pdf
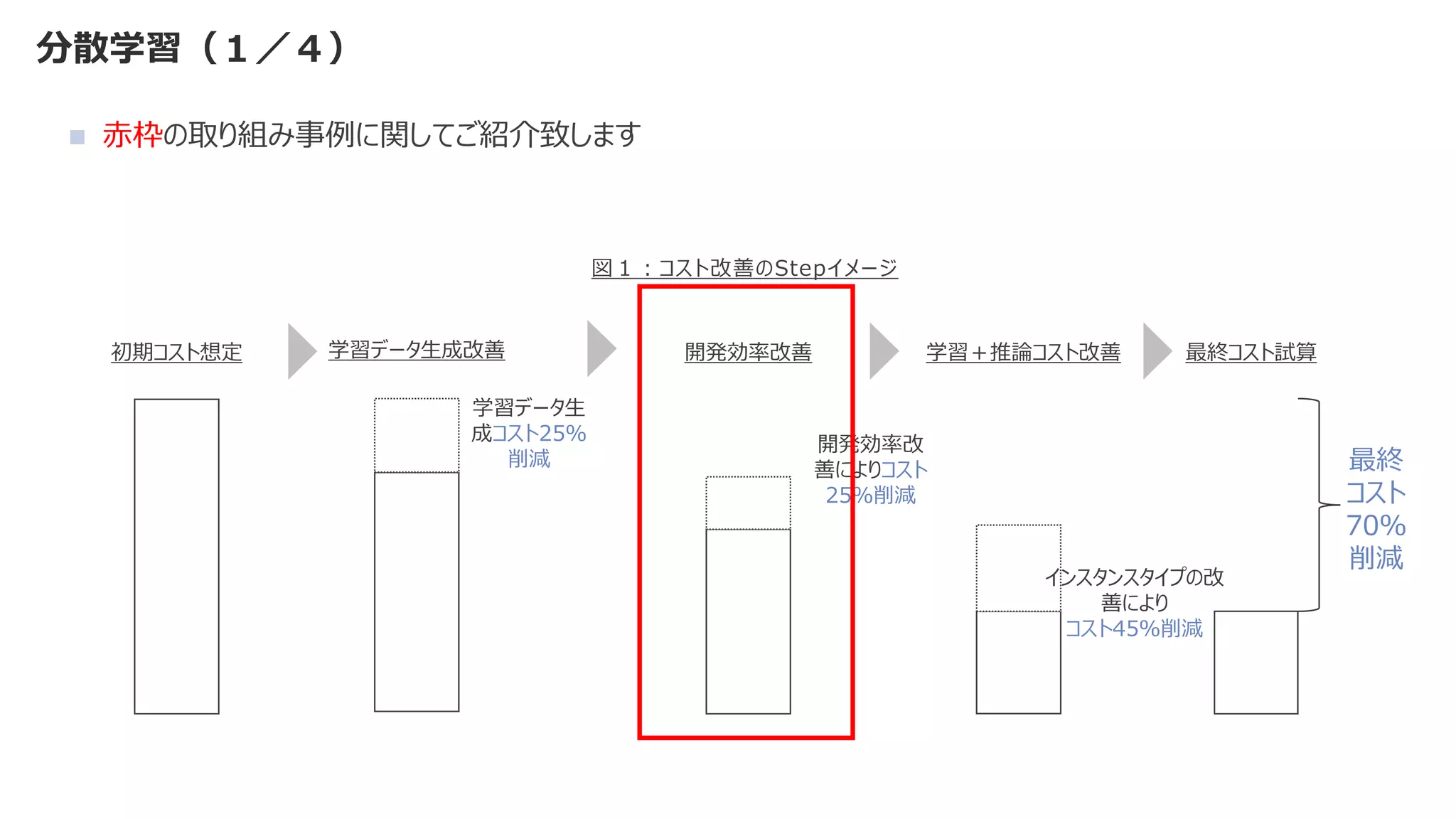
小さい、、、
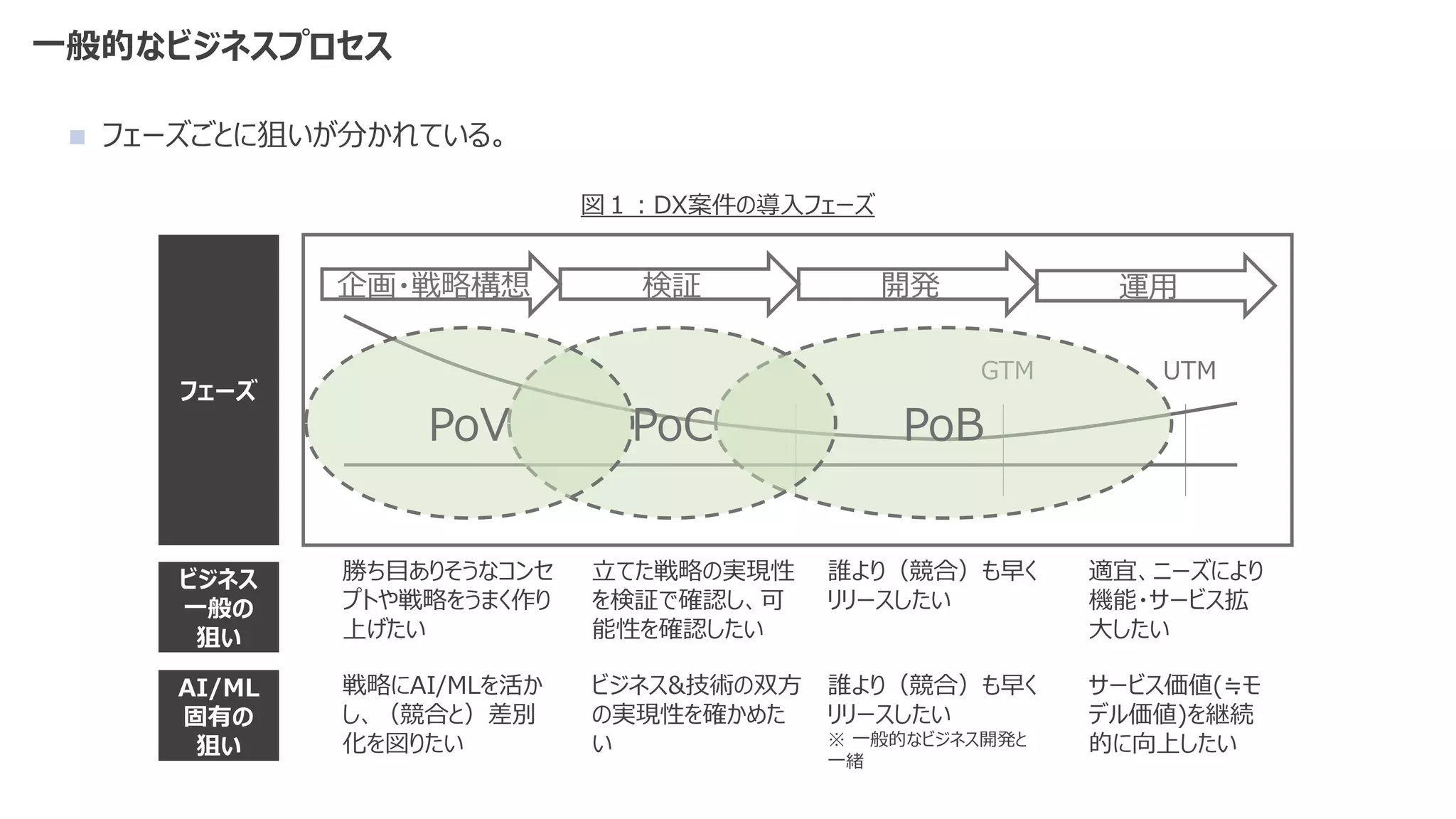
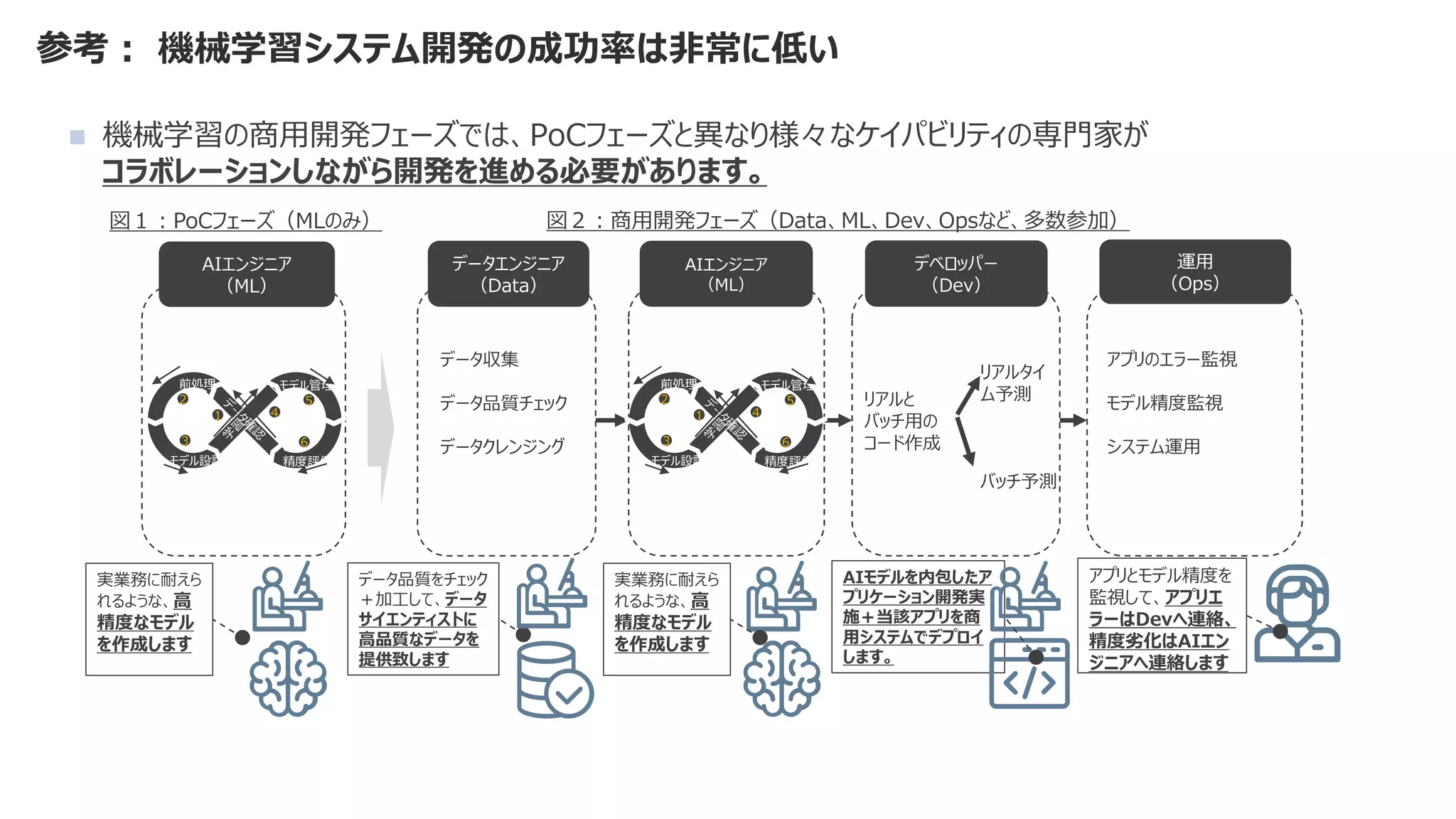
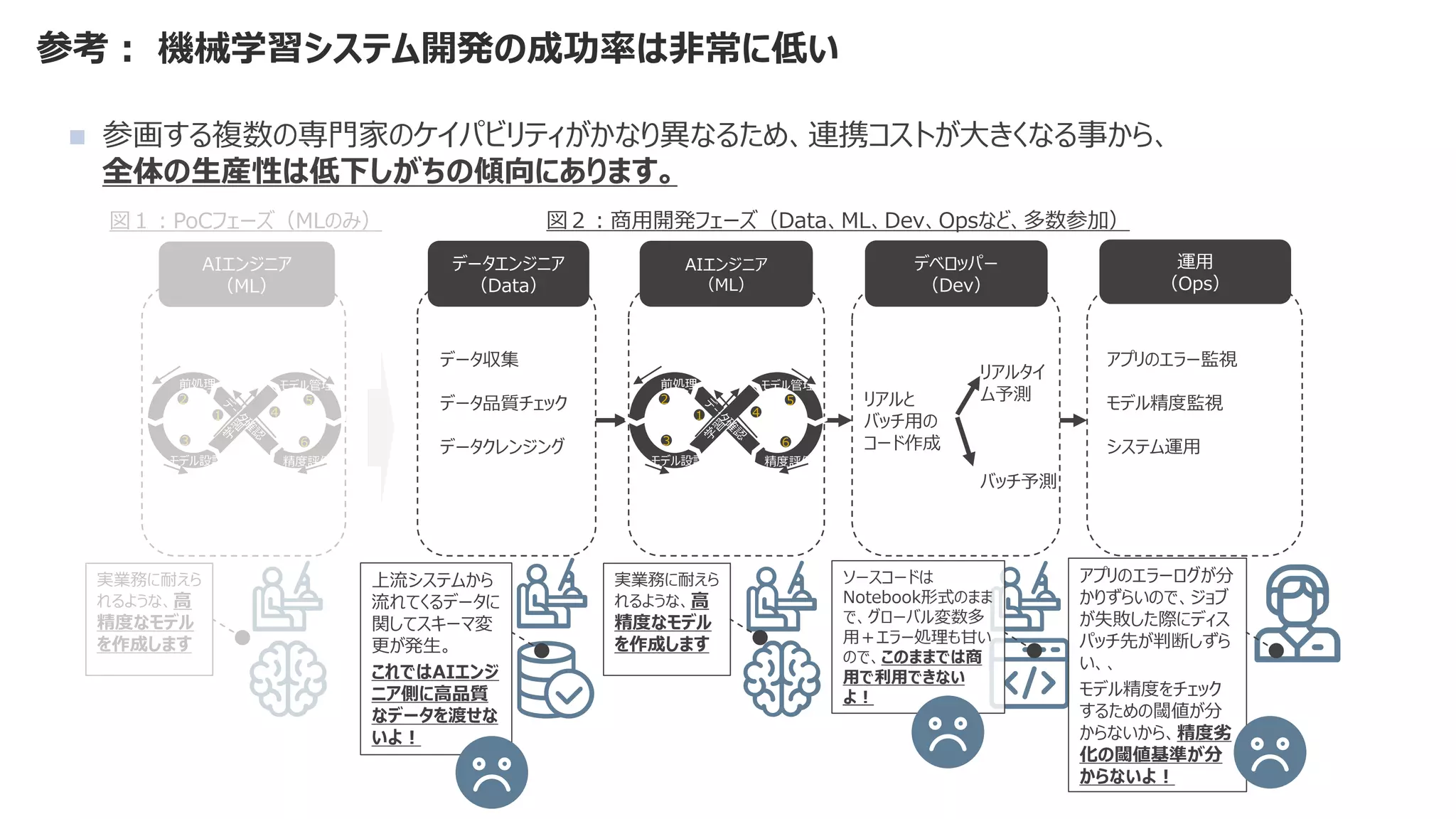
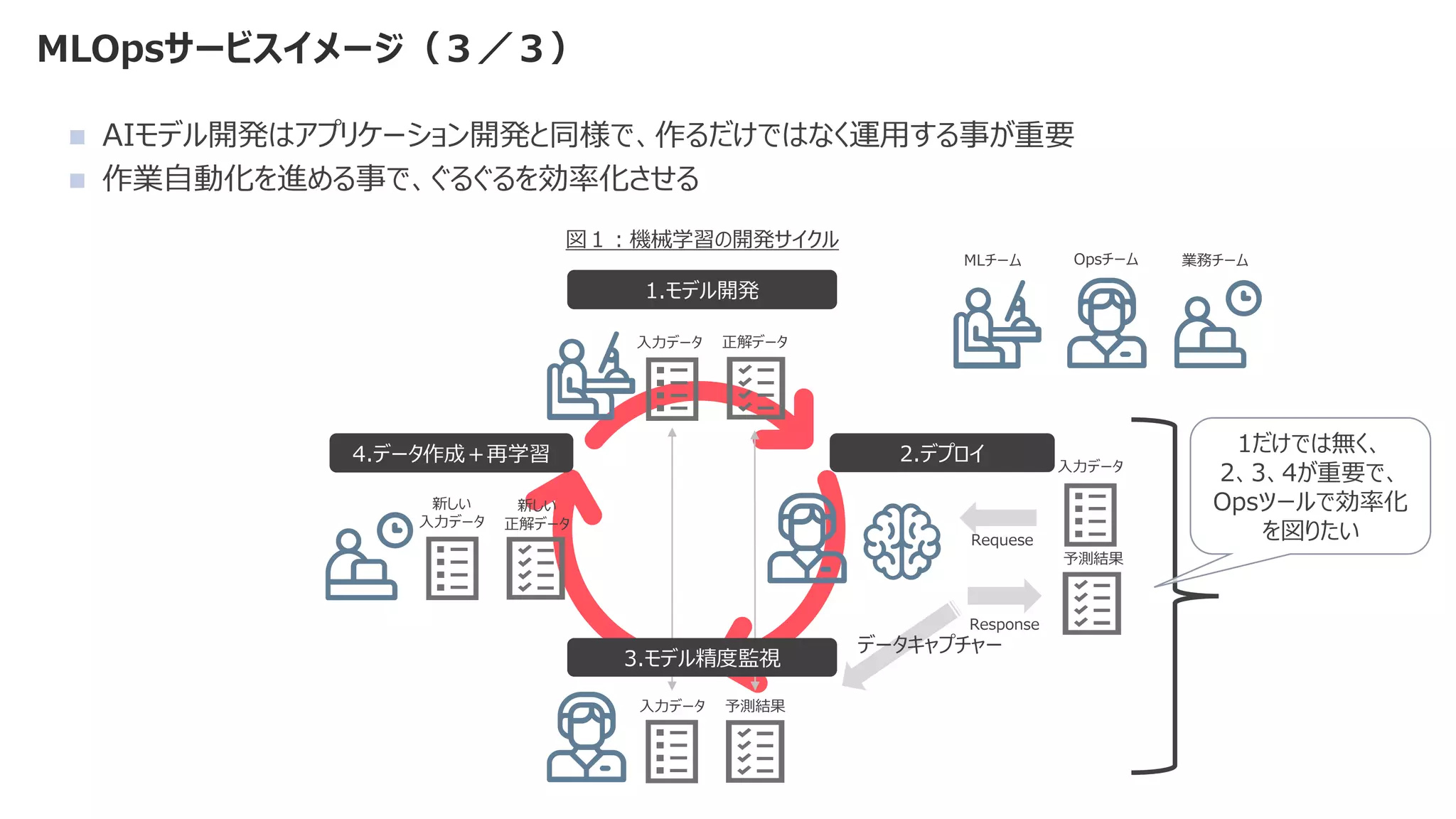
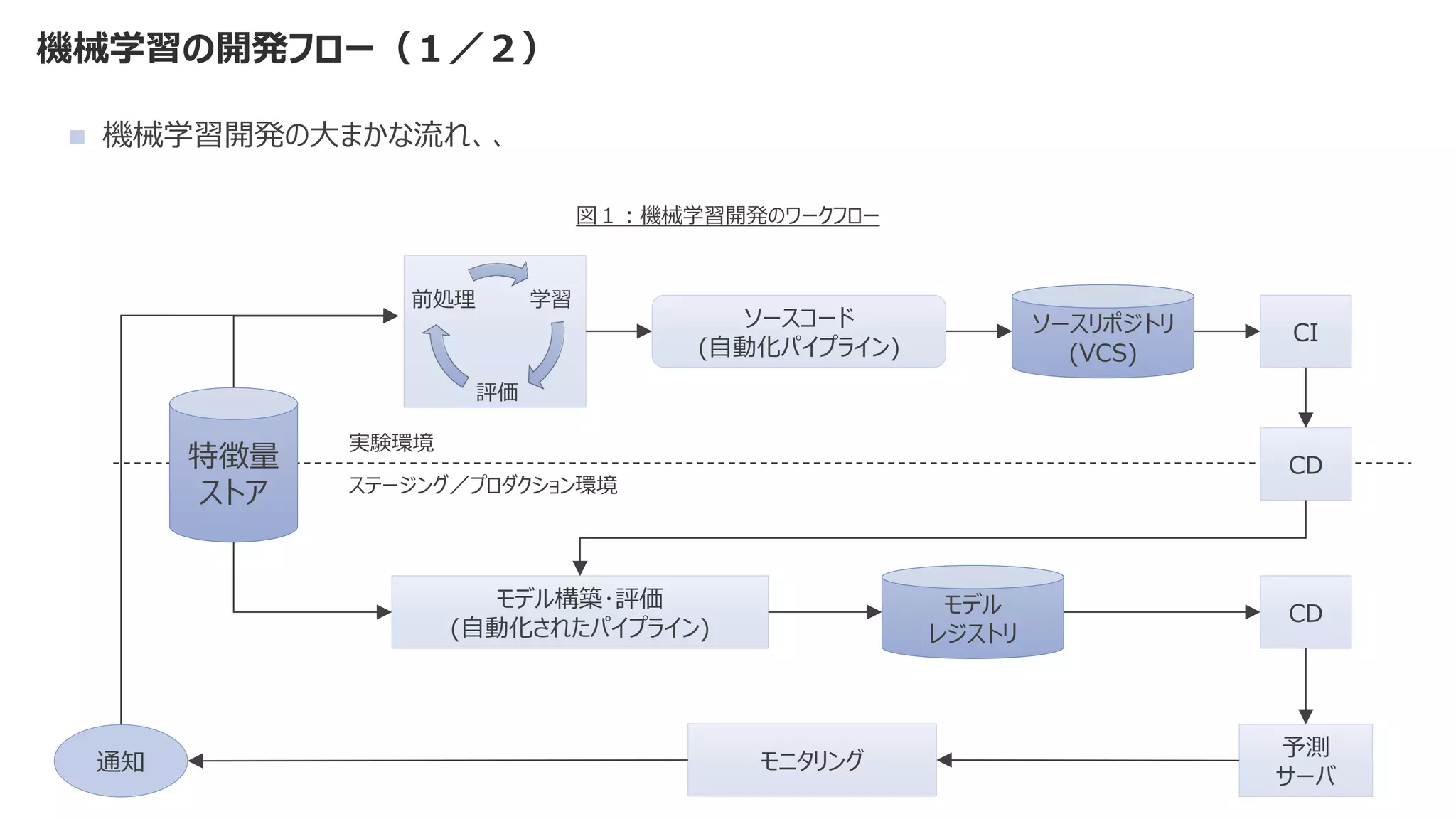
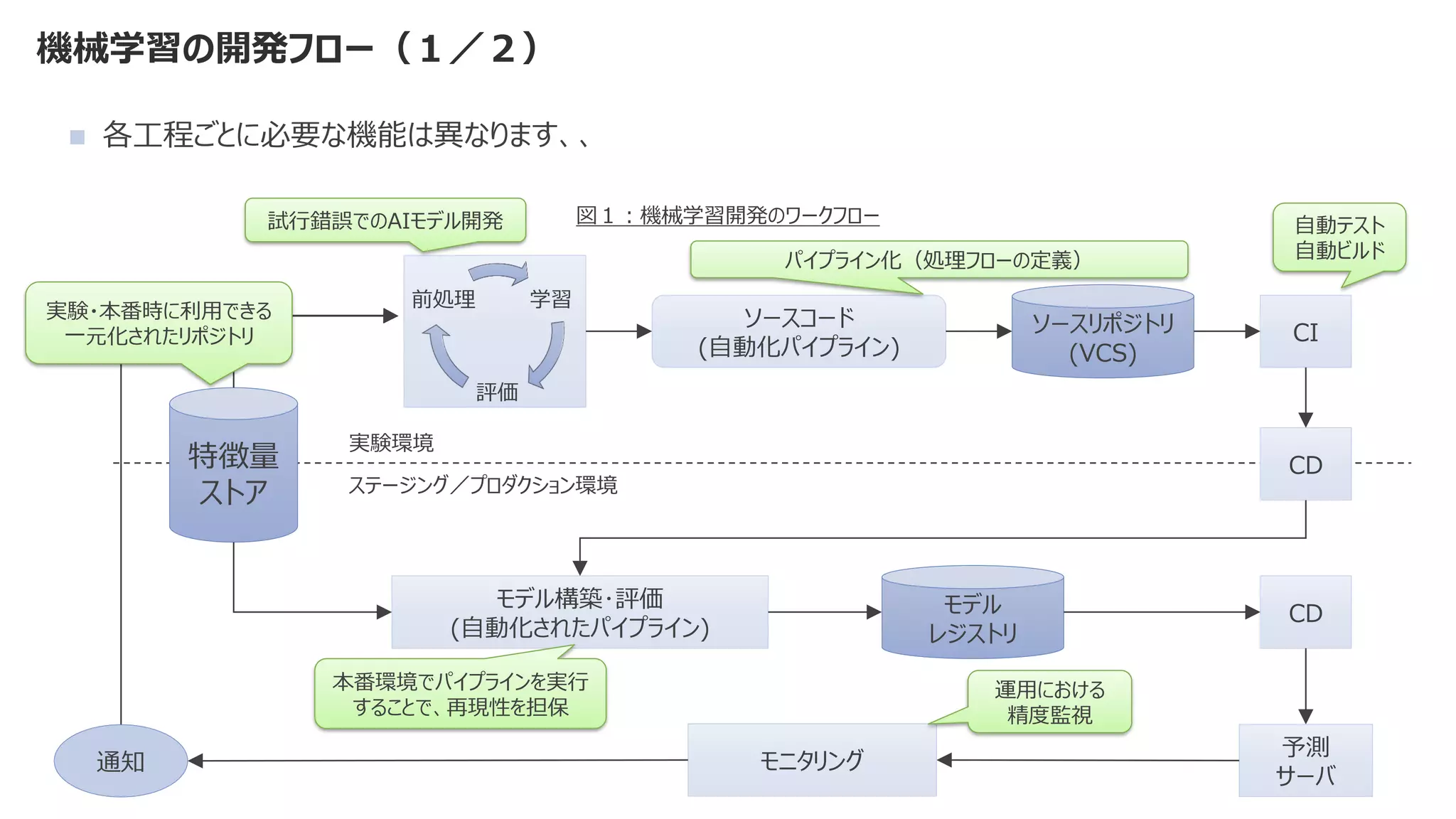
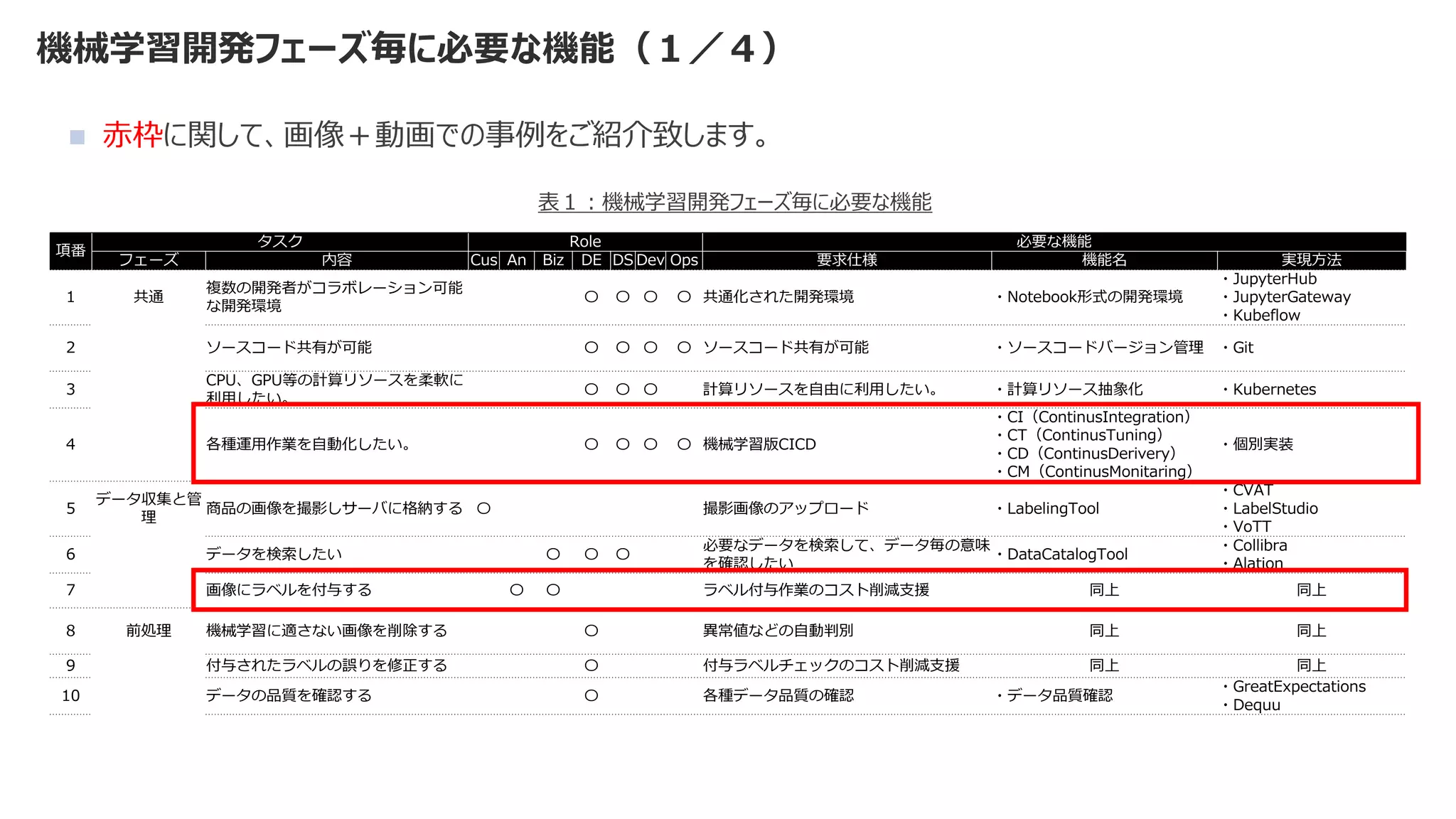
◼ 機械学習モデルを作成するコード部分は、機械学習システム全体の一部分
◼ 比重はとても小さく、それ以外の検討事項が多すぎる](https://image.slidesharecdn.com/2021mlopsaimlmlops-220112135038/75/MLOps-AI-ML-MLOps-2021-9-2048.jpg)








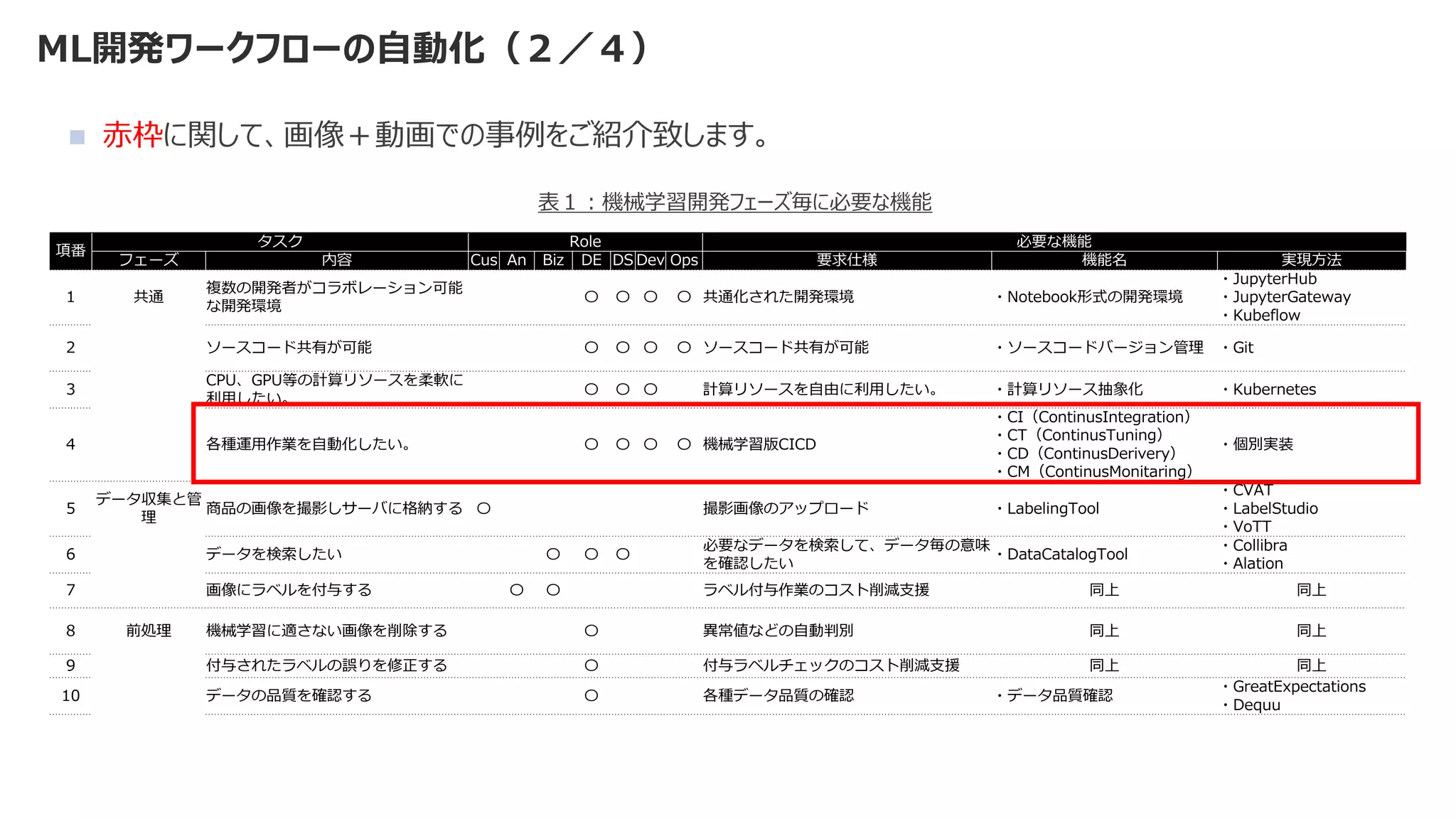
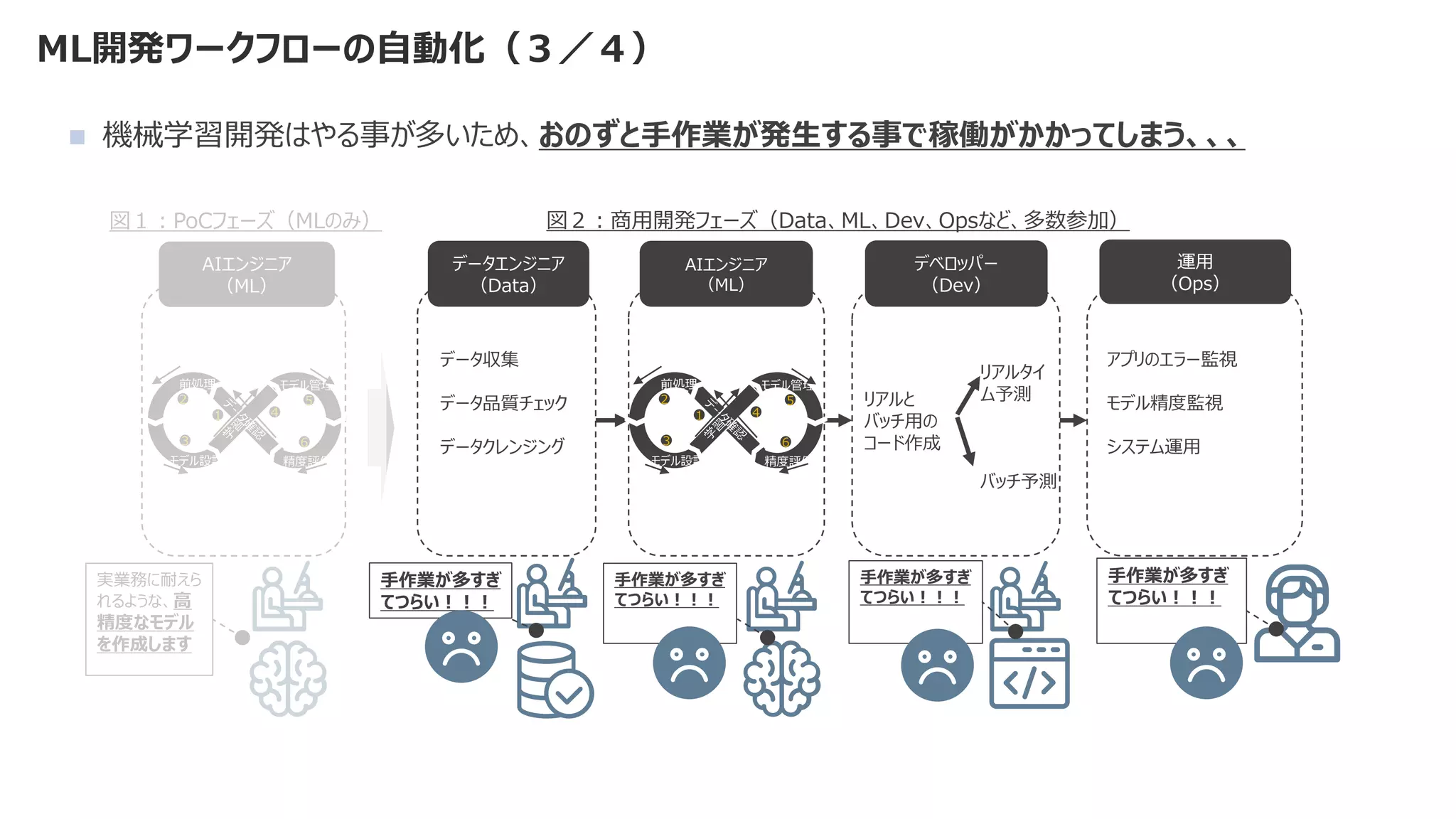
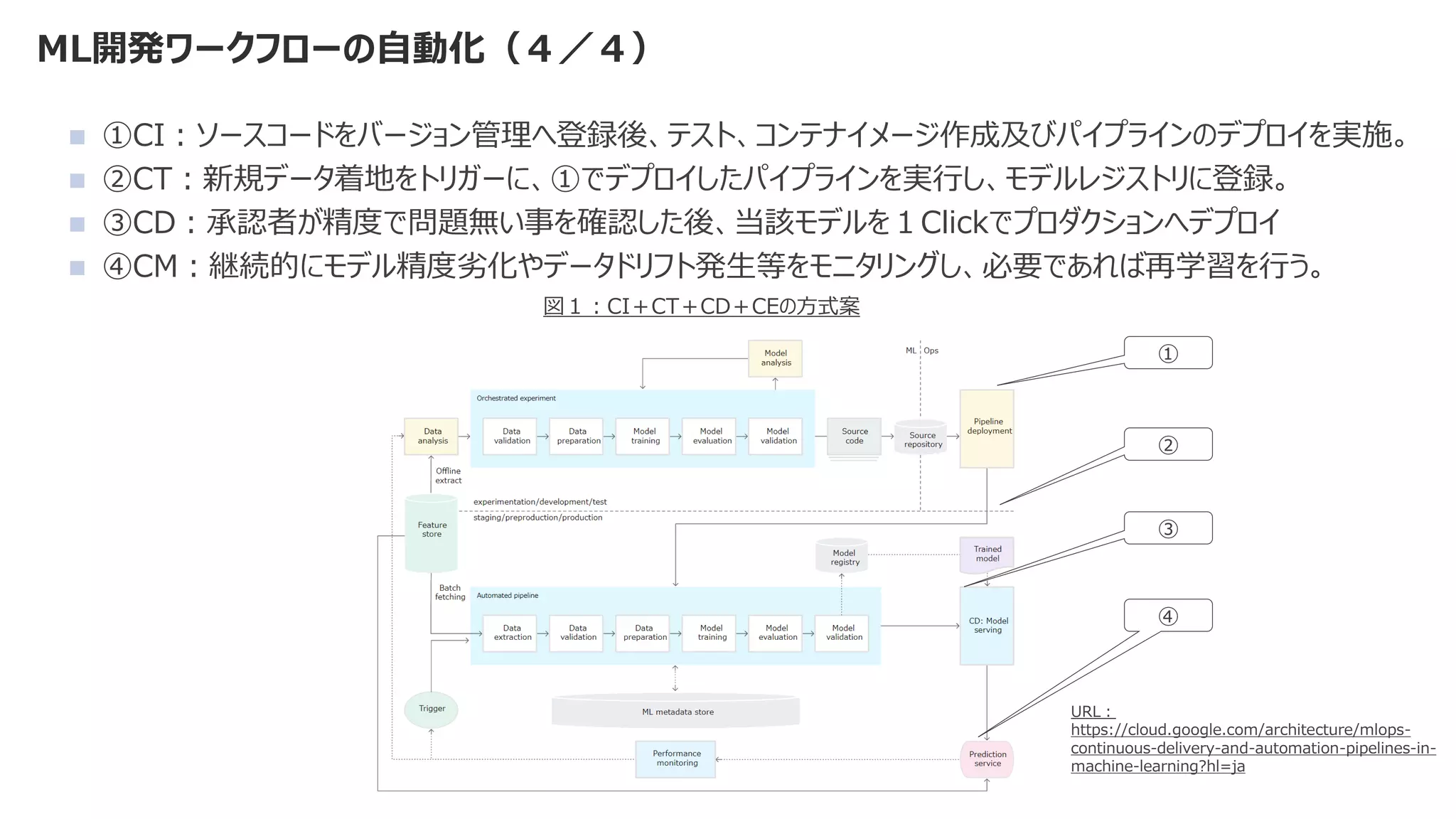






















![SSII2022 [OS3-02] Federated Learningの基礎と応用](https://cdn.slidesharecdn.com/ss_thumbnails/ssii2022-os3-02-220607020834-2b5f93ff-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]NVAE: A Deep Hierarchical Variational Autoencoder](https://cdn.slidesharecdn.com/ss_thumbnails/nvaeadeephierarchicalvariationalautoencoder-201113004930-thumbnail.jpg?width=640&height=640&fit=bounds)

![SSII2022 [SS2] 少ないデータやラベルを効率的に活用する機械学習技術 〜 足りない情報をどのように補うか?〜](https://cdn.slidesharecdn.com/ss_thumbnails/ss2ssii2022-220607054716-2760bd30-thumbnail.jpg?width=640&height=640&fit=bounds)






















![[Developers Summit 2018] Microsoft AIプラットフォームによるインテリジェント アプリケーションの構築](https://cdn.slidesharecdn.com/ss_thumbnails/20180215developerssummitmicrosoftaiplatform-180218215607-thumbnail.jpg?width=640&height=640&fit=bounds)






































