Nakayama Lab.
Machine PerceptionGroup
The University of Tokyo
氏名: 中山英樹
2012年8月 より 東京大学大学院情報理工学系研究科
◦ 創造情報学専攻 講師
◦ 研究室を立ち上げ現在に至る
大規模一般画像認識および関連分野の研究に興味
3.
Nakayama Lab.
Machine PerceptionGroup
The University of Tokyo
3
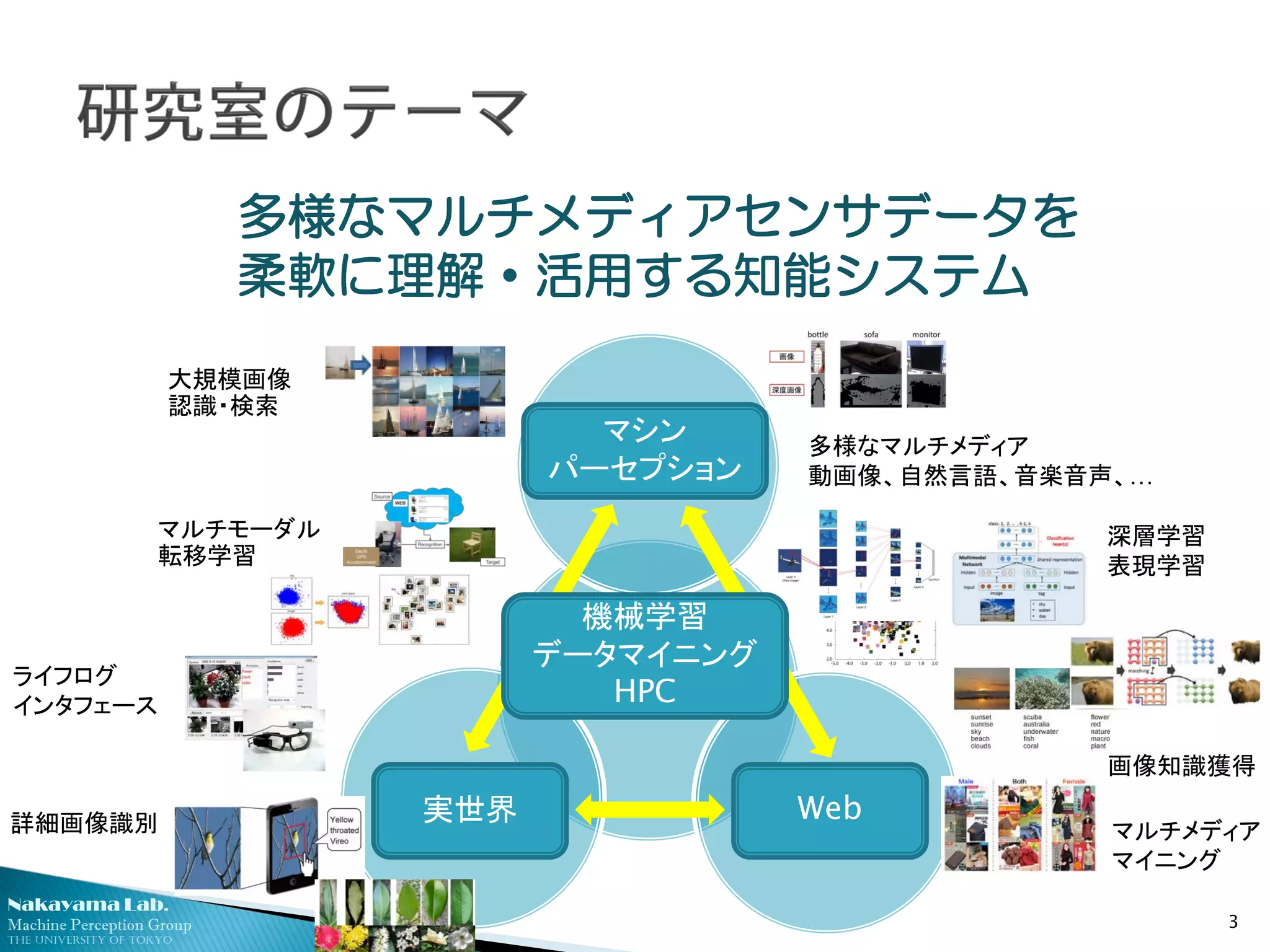
多様なマルチメディアセンサデータを
柔軟に理解・活用する知能システム
実世界 Web
ライフログ
インタフェース
詳細画像識別
マシン
パーセプション
深層学習
表現学習
マルチモーダル
転移学習
大規模画像
認識・検索
多様なマルチメディア
動画像、自然言語、音楽音声、…
マルチメディア
マイニング
画像知識獲得
機械学習
データマイニング
HPC
4.
Nakayama Lab.
Machine PerceptionGroup
The University of Tokyo
1.画像認識分野におけるdeep learningの歴史
2.一般画像認識:Deep learning 以前と以後で何が変わったか
◦ Bag-of-visual-words
◦ 畳み込みニューラルネット (CNN)
3.Deep learningの数理
◦ なぜ優れた性能が実現できるのか?
◦ ブレークスルーを生んだ要素技術
4.実践するにあたって
◦ 適切に利用するために必要な知識
◦ チューニングの勘所
5.最新の研究動向
4
5.
Nakayama Lab.
Machine PerceptionGroup
The University of Tokyo
1.画像認識分野におけるdeep learningの歴史
2.一般画像認識:Deep learning 以前と以後で何が変わったか
◦ Bag-of-visual-words
◦ 畳み込みニューラルネット (CNN)
3.Deep learningの数理
◦ なぜ優れた性能が実現できるのか?
◦ ブレークスルーを生んだ要素技術
4.実践するにあたって
◦ 適切に利用するために必要な知識
◦ チューニングの勘所
5.最新の研究動向
5
6.
Nakayama Lab.
Machine PerceptionGroup
The University of Tokyo
制約をおかない実世界環境の画像を単語で記述
◦ 一般的な物体やシーン、形容詞、印象語
◦ 2000年代以降急速に発展(コンピュータビジョンの人気分野)
◦ 幅広い応用先
デジタルカメラ、ウェアラブルデバイス、画像検索、ロボット、…
7.
Nakayama Lab.
Machine PerceptionGroup
The University of Tokyo
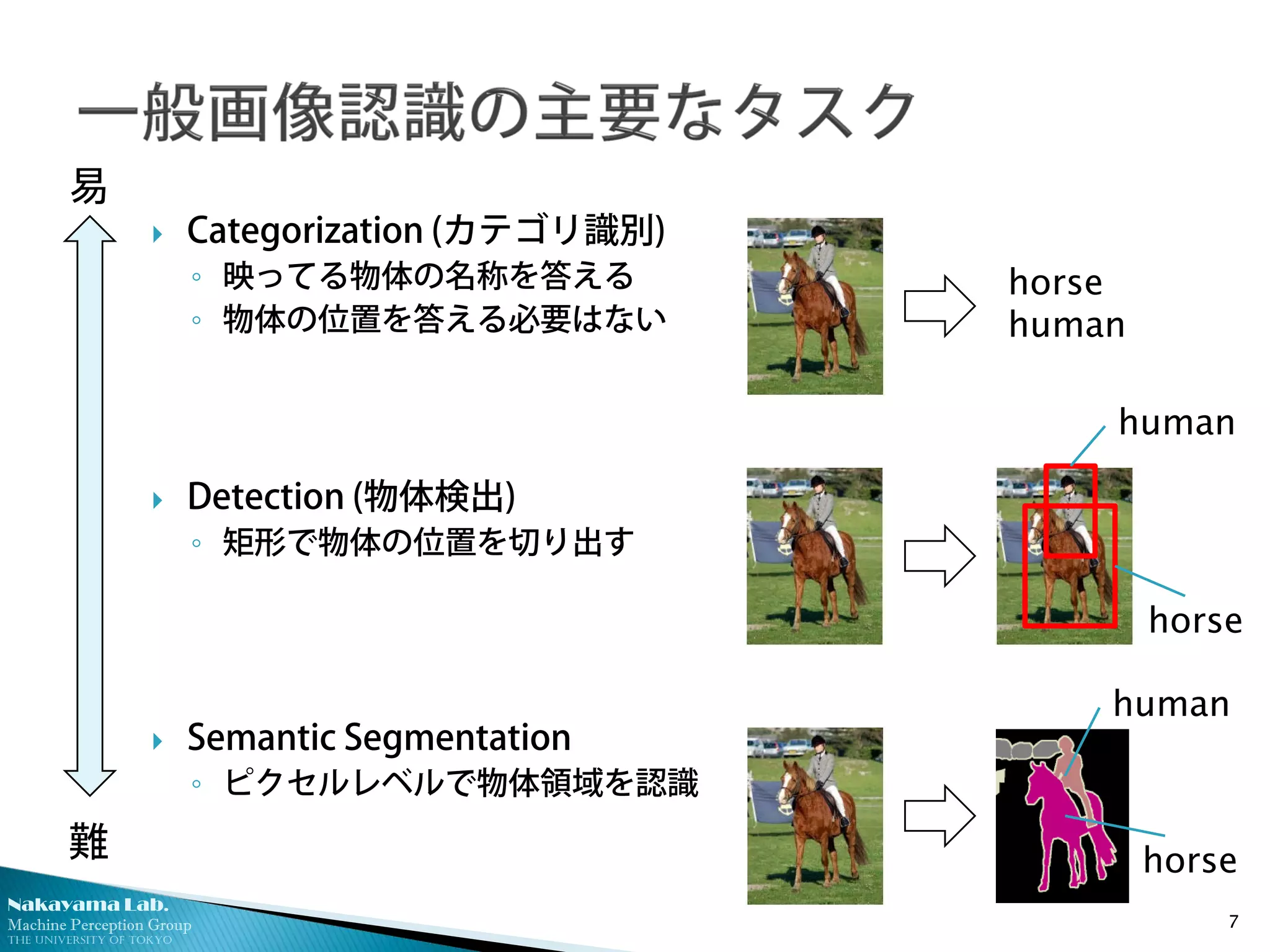
Categorization (カテゴリ識別)
◦ 映ってる物体の名称を答える
◦ 物体の位置を答える必要はない
Detection (物体検出)
◦ 矩形で物体の位置を切り出す
Semantic Segmentation
◦ ピクセルレベルで物体領域を認識
7
horse
human
horse
human
horse
human
易
難
8.
Nakayama Lab.
Machine PerceptionGroup
The University of Tokyo
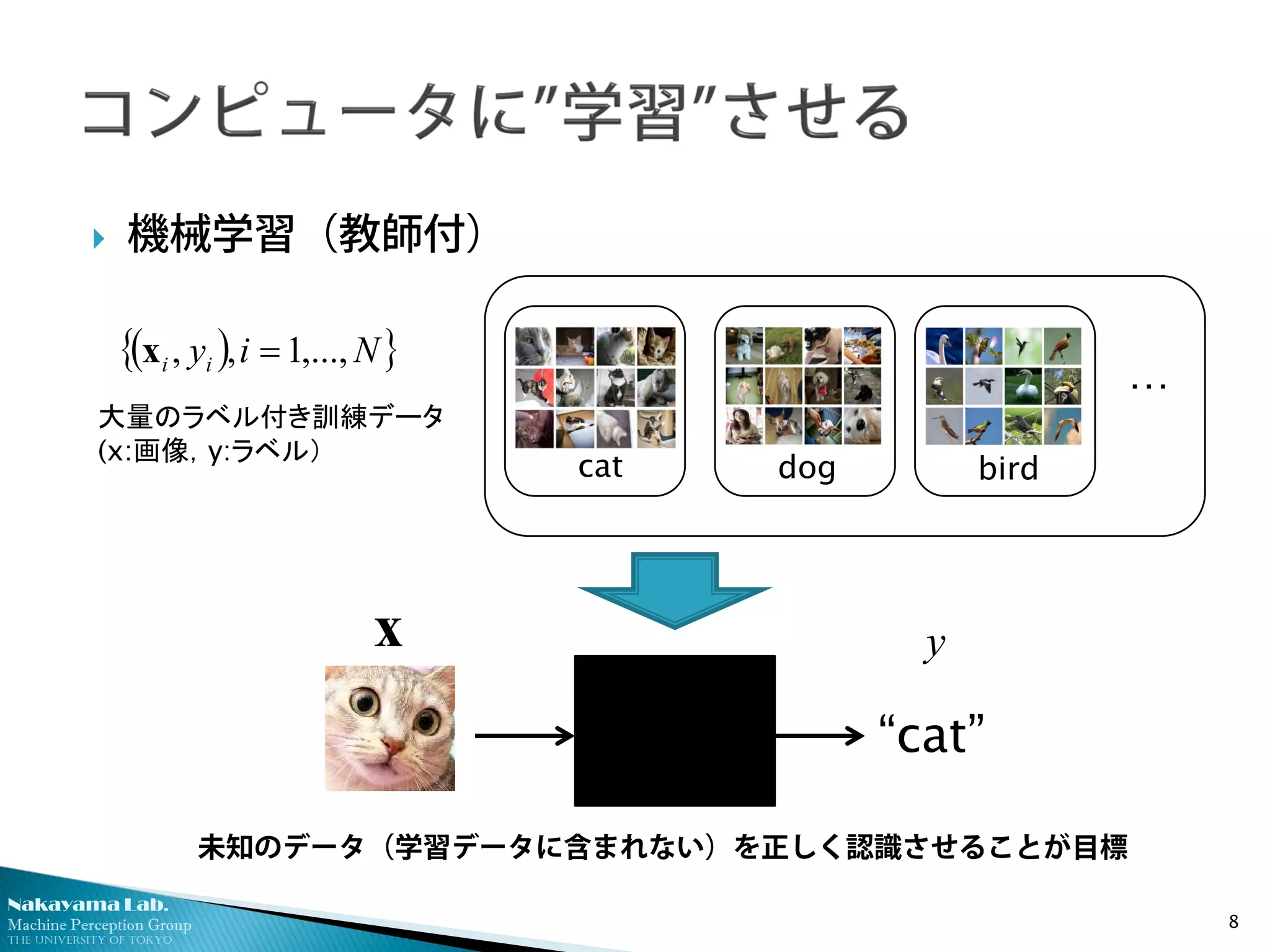
機械学習(教師付)
8
“cat”
( ){ }Niyii ,...,1,, =x
x y
未知のデータ(学習データに含まれない)を正しく認識させることが目標
大量のラベル付き訓練データ
(x:画像,y:ラベル)
…
cat dog bird
9.
Nakayama Lab.
Machine PerceptionGroup
The University of Tokyo
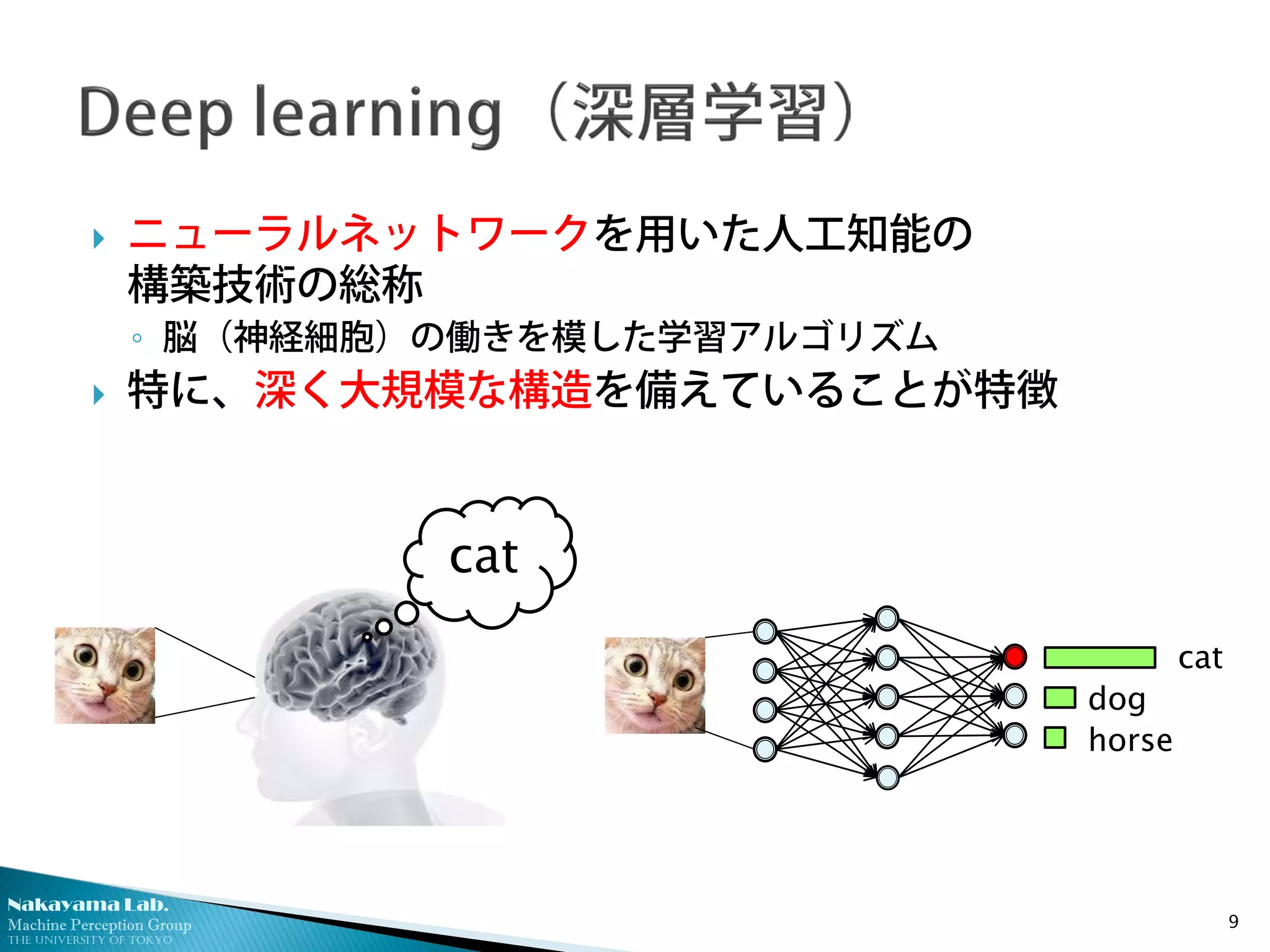
ニューラルネットワークを用いた人工知能の
構築技術の総称
◦ 脳(神経細胞)の働きを模した学習アルゴリズム
特に、深く大規模な構造を備えていることが特徴
9
cat
cat
dog
horse
10.
Nakayama Lab.
Machine PerceptionGroup
The University of Tokyo
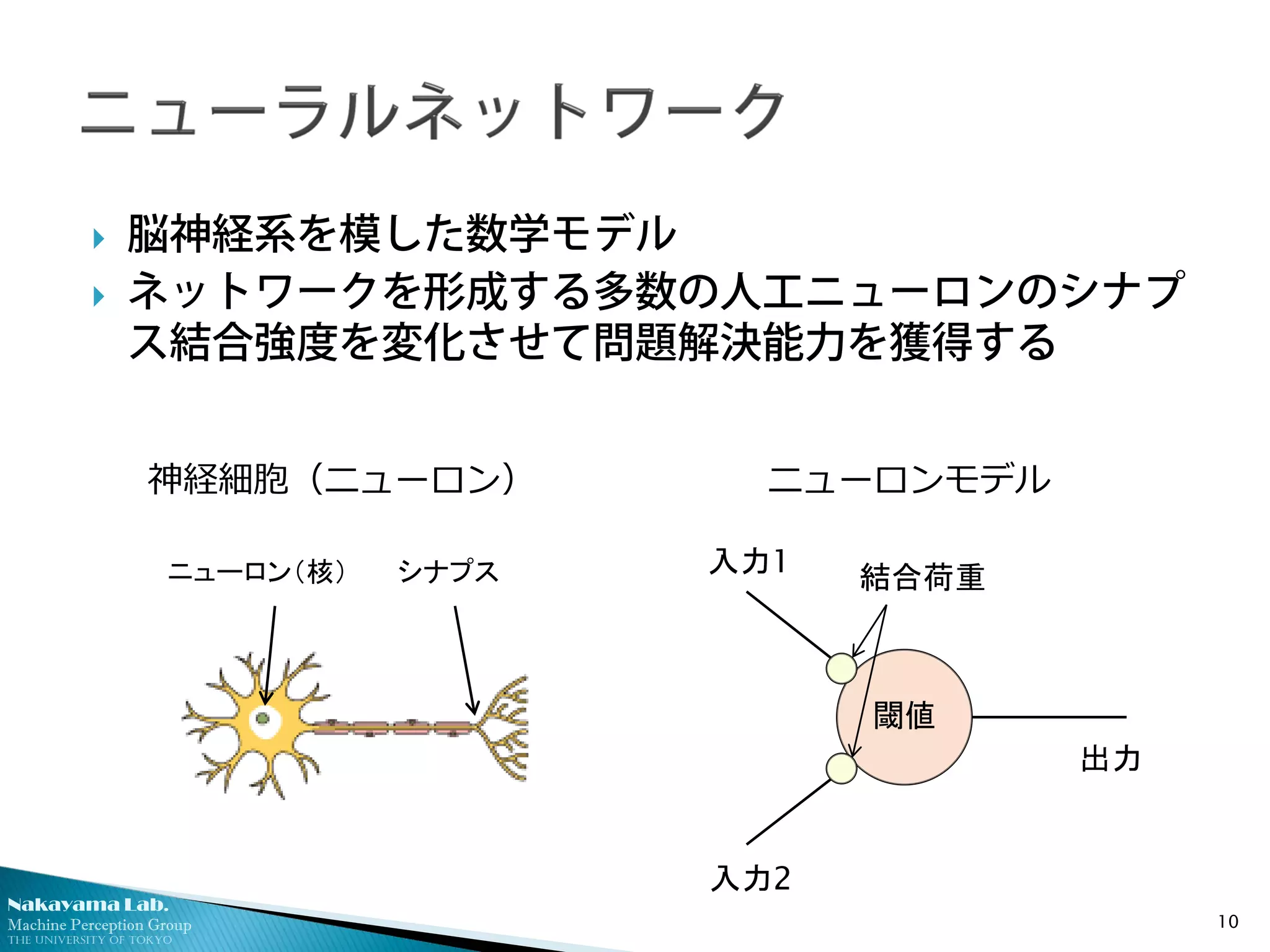
脳神経系を模した数学モデル
ネットワークを形成する多数の人工ニューロンのシナプ
ス結合強度を変化させて問題解決能力を獲得する
10
ニューロンモデル神経細胞(ニューロン)
閾値
入力2
入力1
出力
結合荷重ニューロン(核) シナプス
11.
Nakayama Lab.
Machine PerceptionGroup
The University of Tokyo
小さな画像を用いた基礎研究が主流
◦ MNISTデータセット [LeCun]
文字認識、28 x 28ピクセル、6万枚
◦ CIFAR-10/100 データセット [Krizhevsky]
物体認識、32 x 32ピクセル、5万枚
機械学習のコミュニティで地道に発達
◦ ビジョン系ではあまり受け入れられず…
11
12.
Nakayama Lab.
Machine PerceptionGroup
The University of Tokyo
ある論文の冒頭 [Simard et al., ICDAR 2003]
“After being extremely popular in the early 1990s, neural
networks have fallen out of favor in research in the last 5
years. In 2000, it was even pointed out by the organizers of
the Neural Information Processing System (NIPS) conference
that the term “neural networks” in the submission title
was negatively correlated with acceptance. In contrast,
positive correlations were made with support vector machines
(SVMs), Bayesian networks, and variational methods.”
12
13.
Nakayama Lab.
Machine PerceptionGroup
The University of Tokyo
ImageNetのデータの一部を用いたフラッグシップコンペティ
ション (2010年より開催)
◦ ImageNet [Deng et al., 2009]
クラウドソーシングにより構築中の大規模画像データセット
1400万枚、2万2千カテゴリ(WordNetに従って構築)
コンペでのタスク
◦ 1000クラスの物体カテゴリ分類
学習データ120万枚、検証用データ5万枚、テストデータ10万枚
◦ 200クラスの物体検出
学習データ45万枚、検証用データ2万枚、テストデータ4万枚
13
Russakovsky et al., “ImageNet Large Scale Visual
Recognition Challenge”, 2014.
14.
Nakayama Lab.
Machine PerceptionGroup
The University of Tokyo
1000クラス識別タスクで、deep learning を用いたシステムが圧勝
◦ トロント大学Hinton先生のチーム (AlexNet)
14
[A. Krizhevsky et al., NIPS’12]
エラー率が一気に10%以上減少!
(※過去数年間での向上は1~2%)
15.
Nakayama Lab.
Machine PerceptionGroup
The University of Tokyo
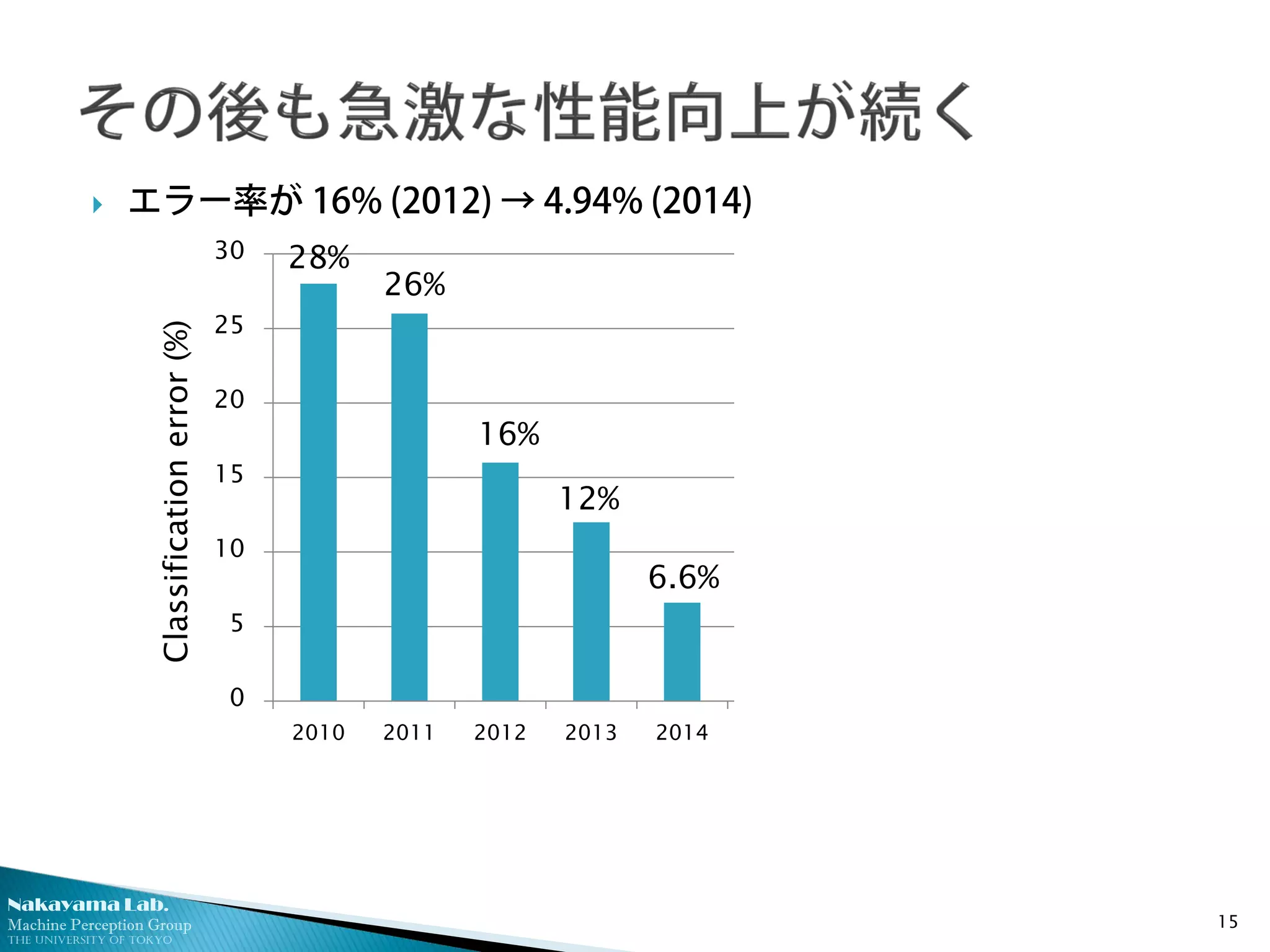
エラー率が 16% (2012) → 4.94% (2014)
15
0
5
10
15
20
25
30
2010 2011 2012 2013 2014 2015
(Baidu)
Human 2015
(MS)
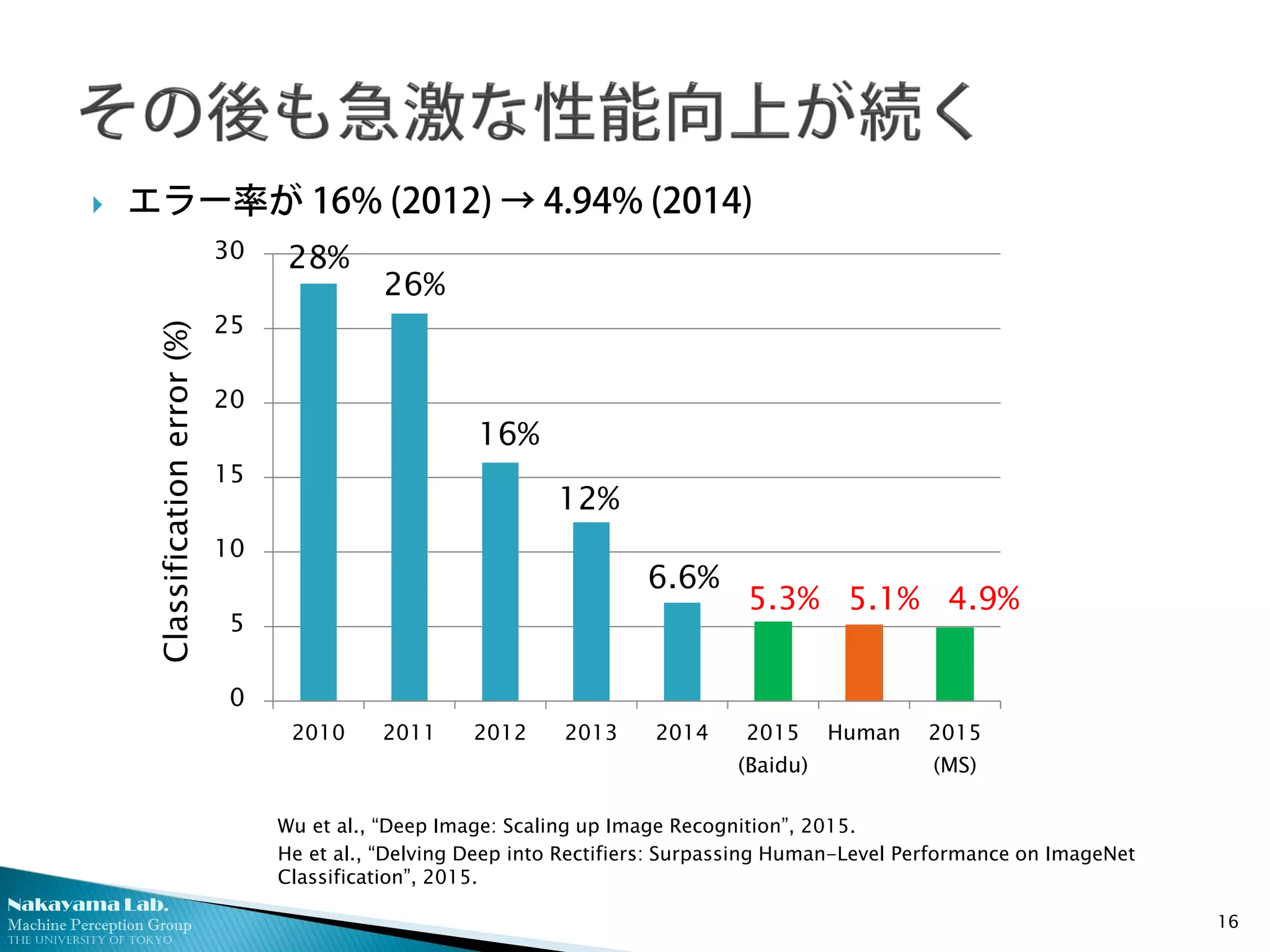
Wu et al., “Deep Image: Scaling up Image Recognition”, 2015.
He et al., “Delving Deep into Rectifiers: Surpassing Human-Level Performance on ImageNet
Classification”, 2015.
Classificationerror(%)
28%
26%
16%
6.6%
12%
5.3% 5.1% 4.9%
16.
Nakayama Lab.
Machine PerceptionGroup
The University of Tokyo
エラー率が 16% (2012) → 4.94% (2014)
16
0
5
10
15
20
25
30
2010 2011 2012 2013 2014 2015
(Baidu)
Human 2015
(MS)
Wu et al., “Deep Image: Scaling up Image Recognition”, 2015.
He et al., “Delving Deep into Rectifiers: Surpassing Human-Level Performance on ImageNet
Classification”, 2015.
Classificationerror(%)
28%
26%
16%
6.6%
12%
5.3% 5.1% 4.9%
17.
Nakayama Lab.
Machine PerceptionGroup
The University of Tokyo
映像 認識
◦ 487クラスの
スポーツカテゴリ認識
[Karpathy., CVPR’14]
RGB-D物体認識
◦ [Socher et la., NIPS’13]
17
18.
Nakayama Lab.
Machine PerceptionGroup
The University of Tokyo
領域分割 (シーンラベリング)
◦ ピクセルレベルで物体領域を認識
◦ [Long et al., 2014]
RGB-Dシーンラベリング
◦ [Wang et al., ECCV’14]
18
19.
Nakayama Lab.
Machine PerceptionGroup
The University of Tokyo
デノイジング・インペインティング [Xie et al., NIPS’12]
◦ 画像のノイズ除去
◦ Stacked denoising auto-encoder
超解像 [Dong et al., ECCV’14]
◦ 低解像度画像から
高解像度画像を復元(推定)
ボケ補正 [Xu et al., NIPS’14]
19
20.
Nakayama Lab.
Machine PerceptionGroup
The University of Tokyo
1.画像認識分野におけるdeep learningの歴史
2.一般画像認識:Deep learning 以前と以後で何が変わったか
◦ Bag-of-visual-words
◦ 畳み込みニューラルネット (CNN)
3.Deep learningの数理
◦ なぜ優れた性能が実現できるのか?
◦ ブレークスルーを生んだ要素技術
4.実践するにあたって
◦ 適切に利用するために必要な知識
◦ チューニングの勘所
5.最新の研究動向
20
21.
Nakayama Lab.
Machine PerceptionGroup
The University of Tokyo
21
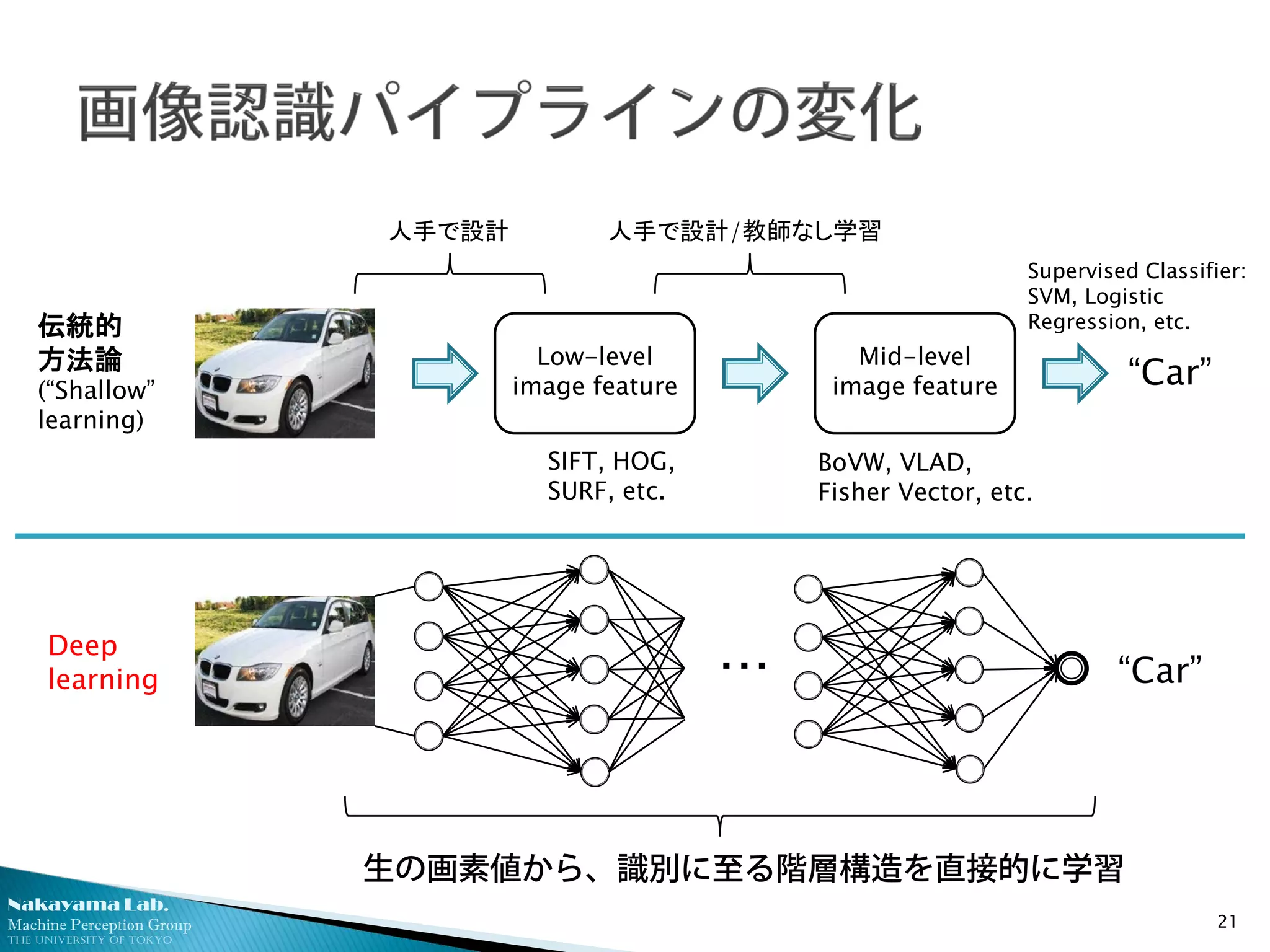
Low-level
image feature
Mid-level
image feature “Car”
SIFT, HOG,
SURF, etc.
BoVW, VLAD,
Fisher Vector, etc.
Supervised Classifier:
SVM, Logistic
Regression, etc.
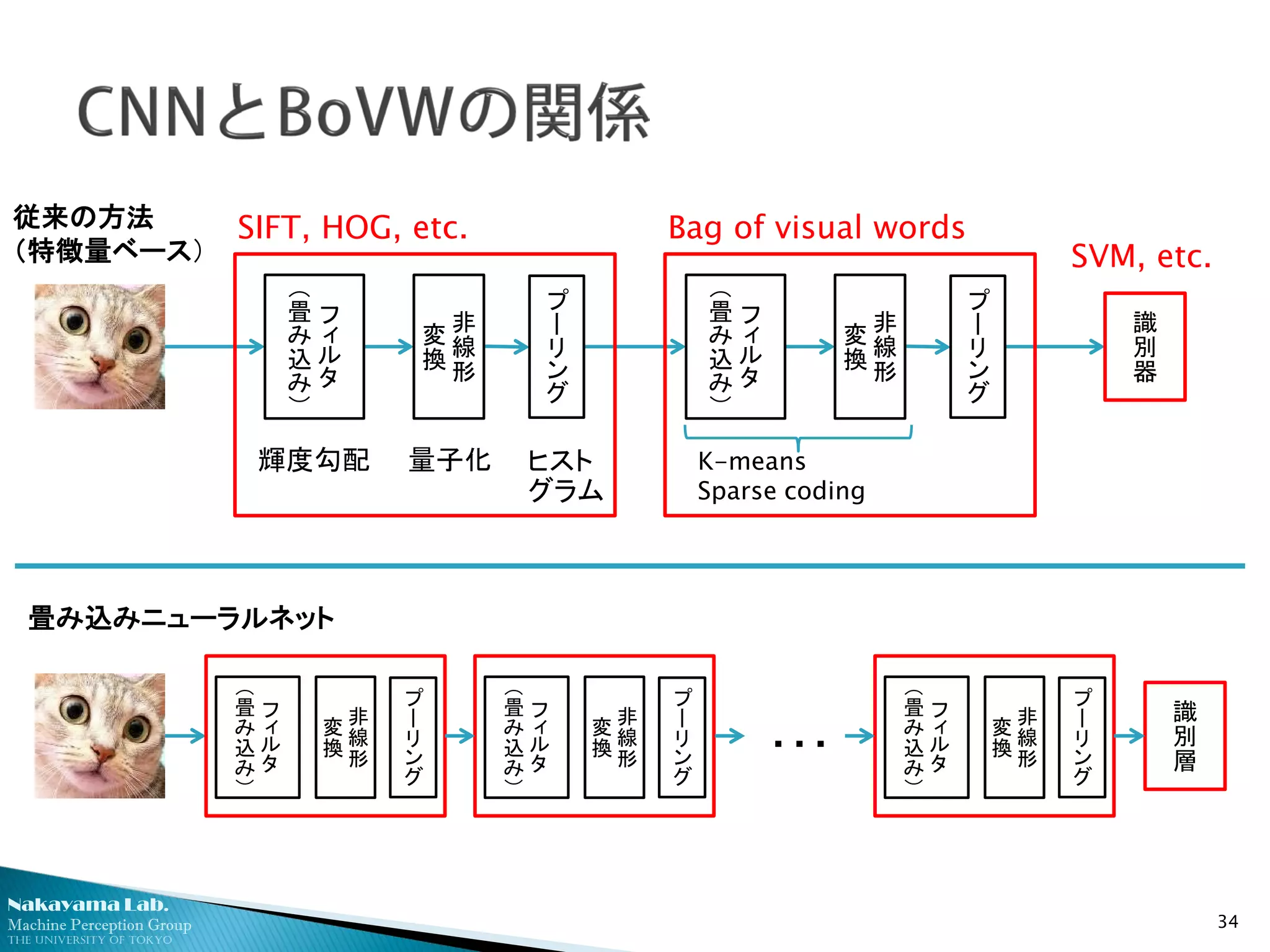
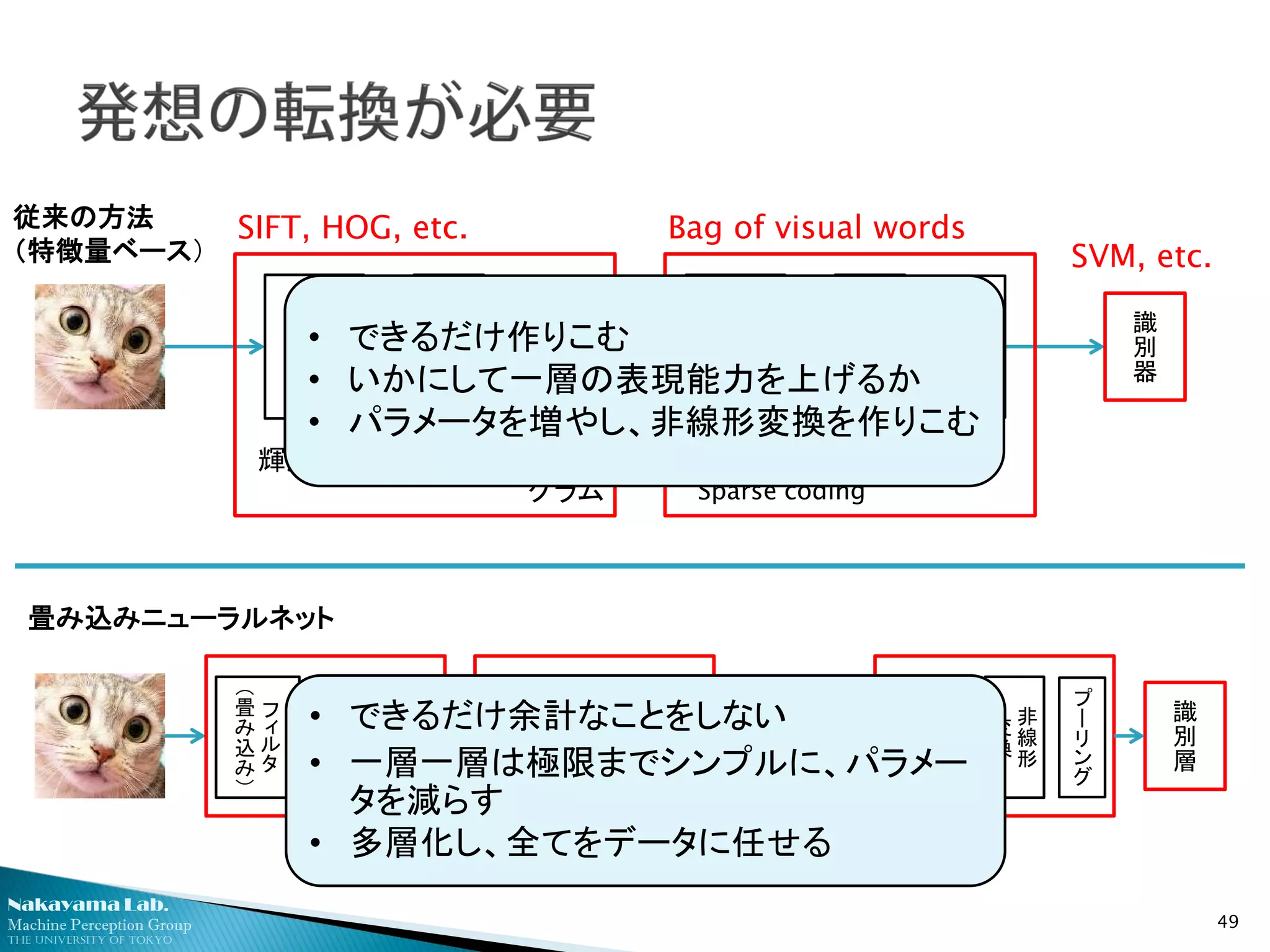
生の画素値から、識別に至る階層構造を直接的に学習
伝統的
方法論
(“Shallow”
learning)
Deep
learning “Car”・・・
人手で設計 人手で設計/教師なし学習
22.
Nakayama Lab.
Machine PerceptionGroup
The University of Tokyo
22
Low-level
image feature
Mid-level
image feature “Car”
SIFT, HOG,
SURF, etc.
BoVW, VLAD,
Fisher Vector, etc.
Supervised Classifier:
SVM, Logistic
Regression, etc.
生の画素値から、識別に至る階層構造を直接的に学習
従来の特徴量に相当する構造が中間層に自然に出現
伝統的
方法論
(“Shallow”
learning)
Deep
learning “Car”・・・
人手で設計 人手で設計/教師なし学習
[Zeiler and Fergus, 2013]
Nakayama Lab.
Machine PerceptionGroup
The University of Tokyo
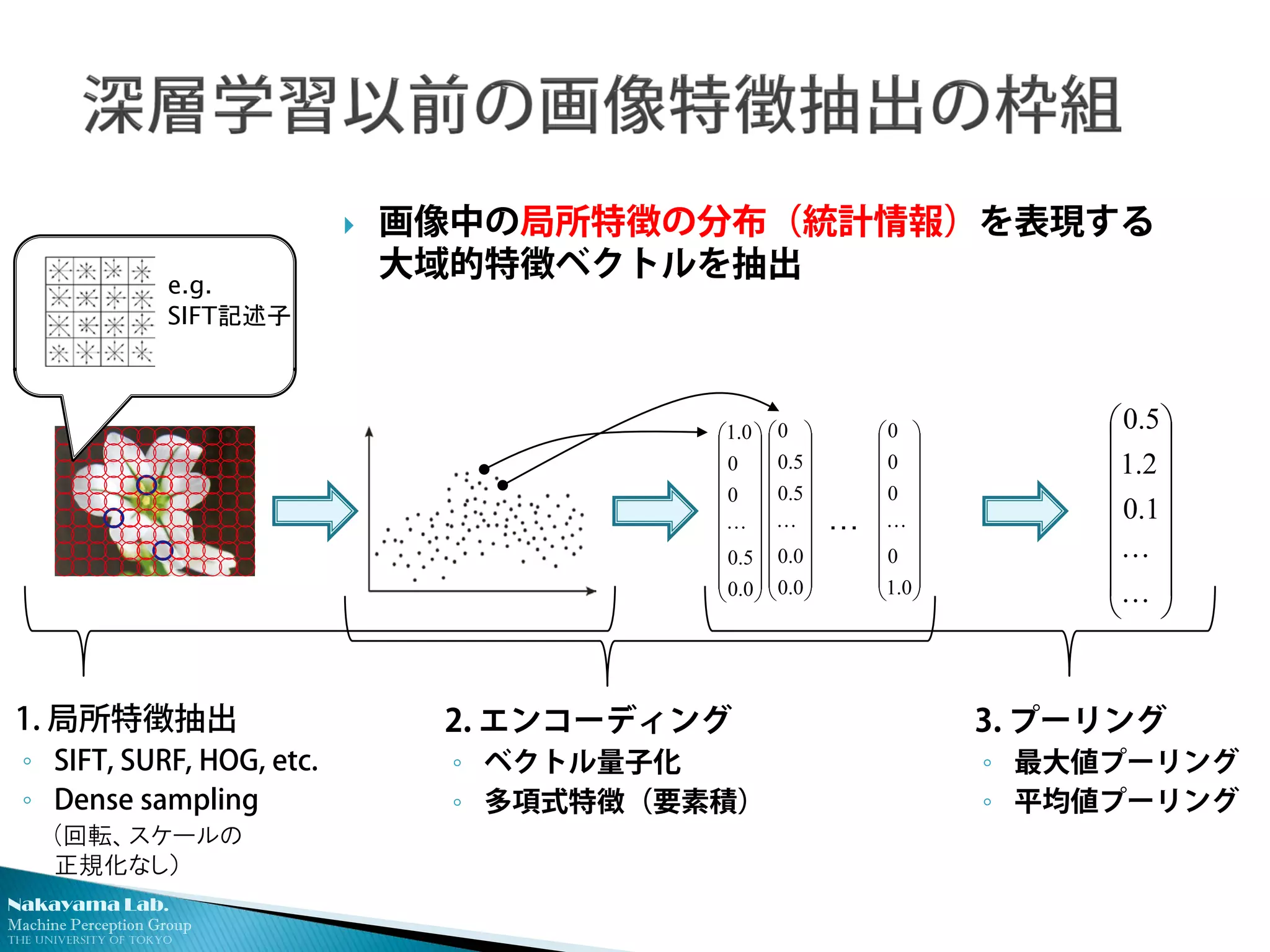
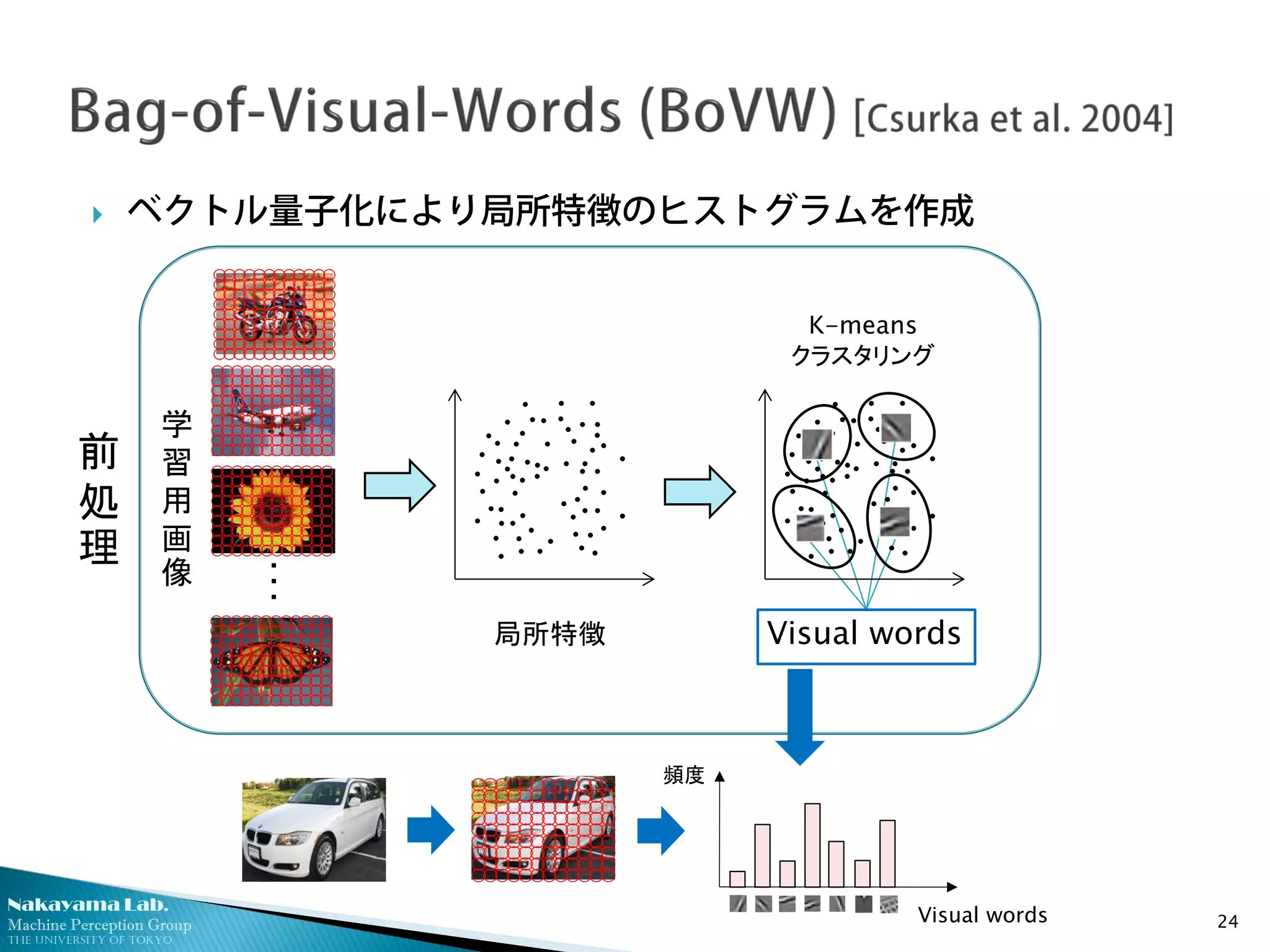
ベクトル量子化により局所特徴のヒストグラムを作成
24
学
習
用
画
像
局所特徴
前
処
理
K-means
クラスタリング
・
・
・
Visual words
Visual words
頻度
Nakayama Lab.
Machine PerceptionGroup
The University of Tokyo
畳み込みニューラルネットワーク (CNN)
◦ 脳の視覚野の構造を模倣した多層パーセプトロン
◦ ニューロン間の結合を局所に限定(パラメータ数の大幅な削減)
最初に基本構造が提案されたのは実はかなり昔
◦ ネオコグニトロン (福島邦彦先生、1980年代前後)
26
[A. Krizhevsky et al., NIPS’12]
Kunihiko Fukushima, “Neocognitron: A Self-organizing Neural
Network Model for a Mechanism of Pattern Recognition
Unaffected by Shift in Position“, Biological Cybernetics, 36(4):
93-202, 1980.
27.
Nakayama Lab.
Machine PerceptionGroup
The University of Tokyo
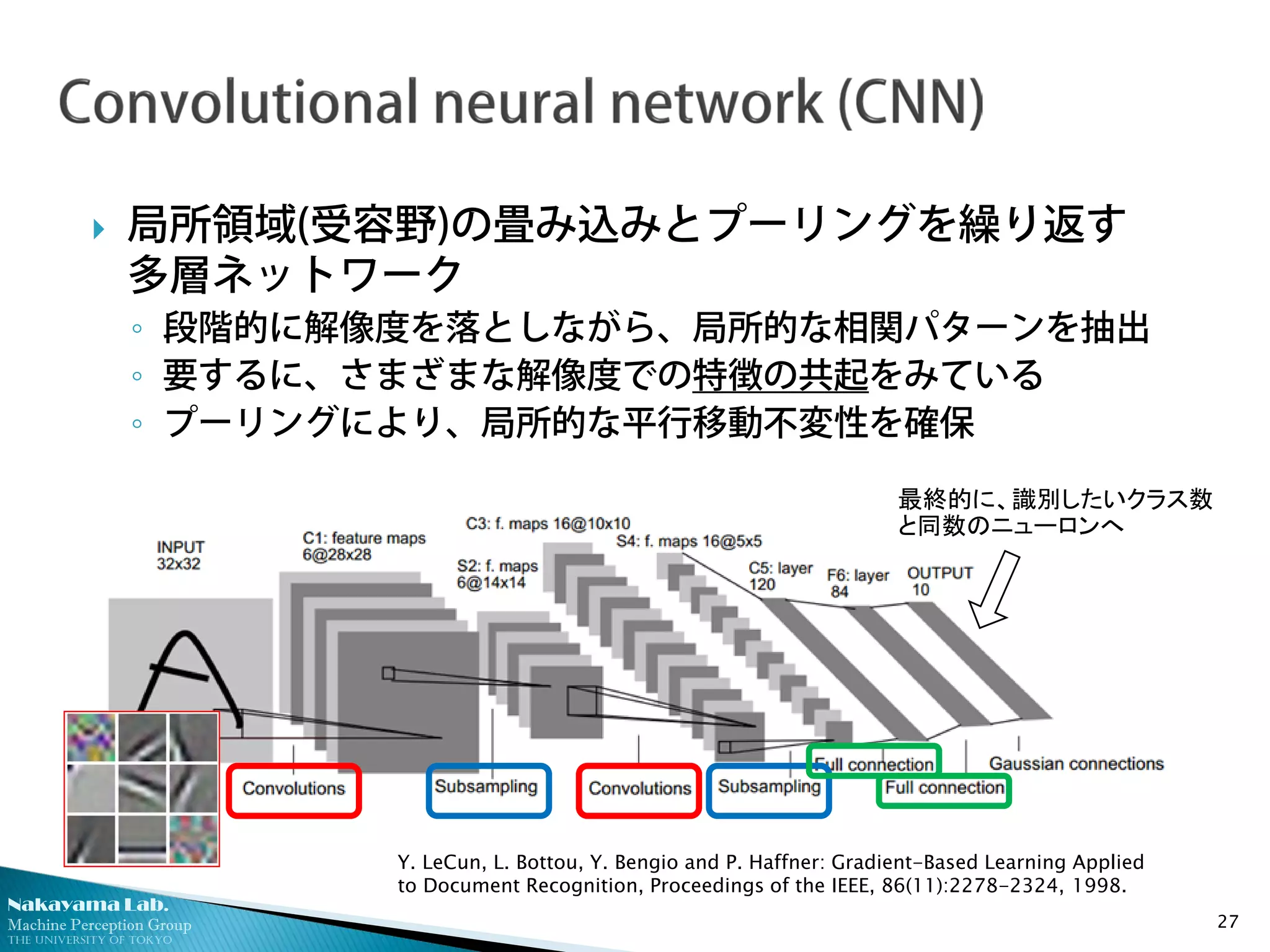
局所領域(受容野)の畳み込みとプーリングを繰り返す
多層ネットワーク
◦ 段階的に解像度を落としながら、局所的な相関パターンを抽出
◦ 要するに、さまざまな解像度での特徴の共起をみている
◦ プーリングにより、局所的な平行移動不変性を確保
27
Y. LeCun, L. Bottou, Y. Bengio and P. Haffner: Gradient-Based Learning Applied
to Document Recognition, Proceedings of the IEEE, 86(11):2278-2324, 1998.
最終的に、識別したいクラス数
と同数のニューロンへ
28.
Nakayama Lab.
Machine PerceptionGroup
The University of Tokyo
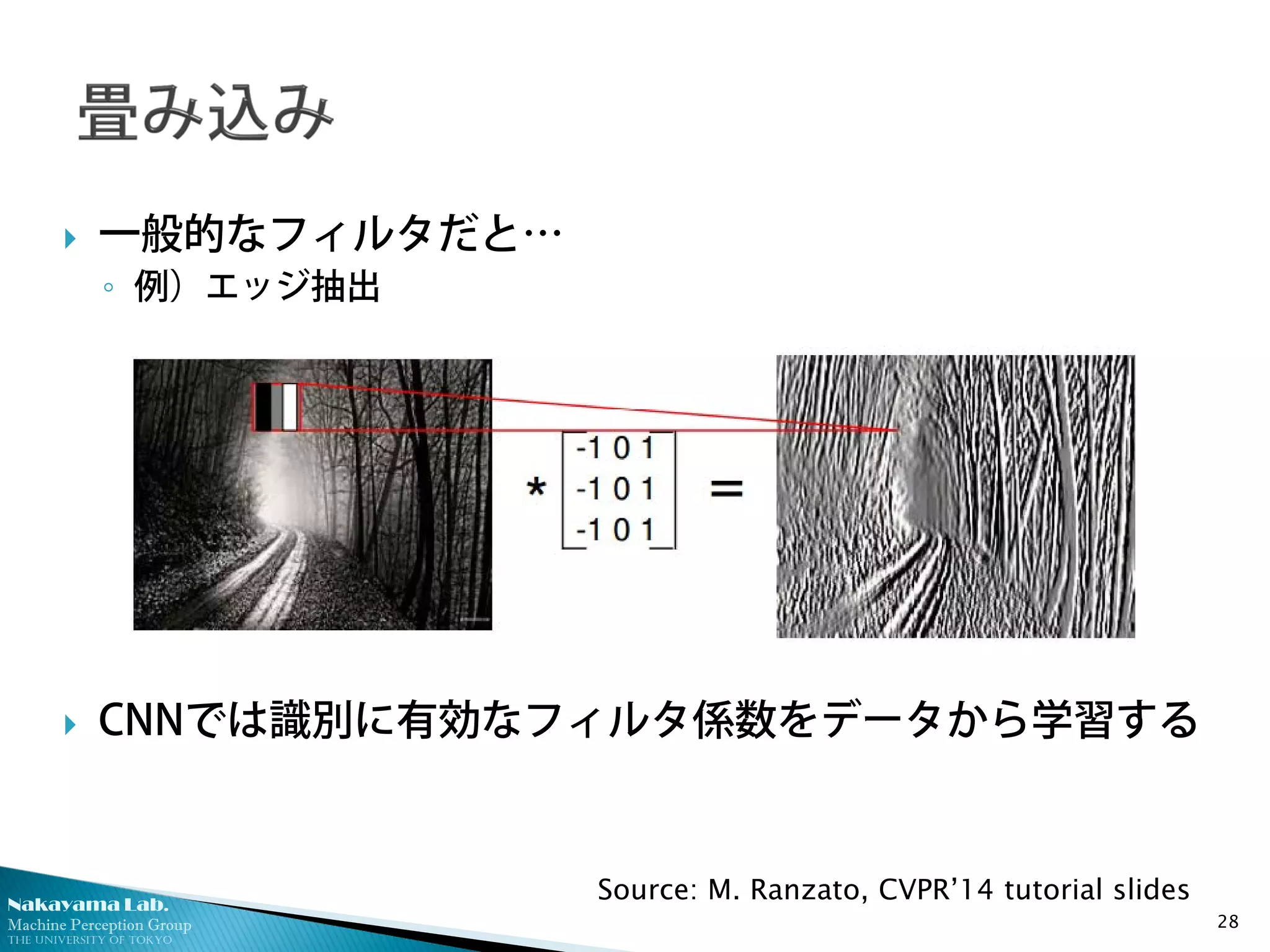
一般的なフィルタだと…
◦ 例)エッジ抽出
CNNでは識別に有効なフィルタ係数をデータから学習する
28
Source: M. Ranzato, CVPR’14 tutorial slides
29.
Nakayama Lab.
Machine PerceptionGroup
The University of Tokyo
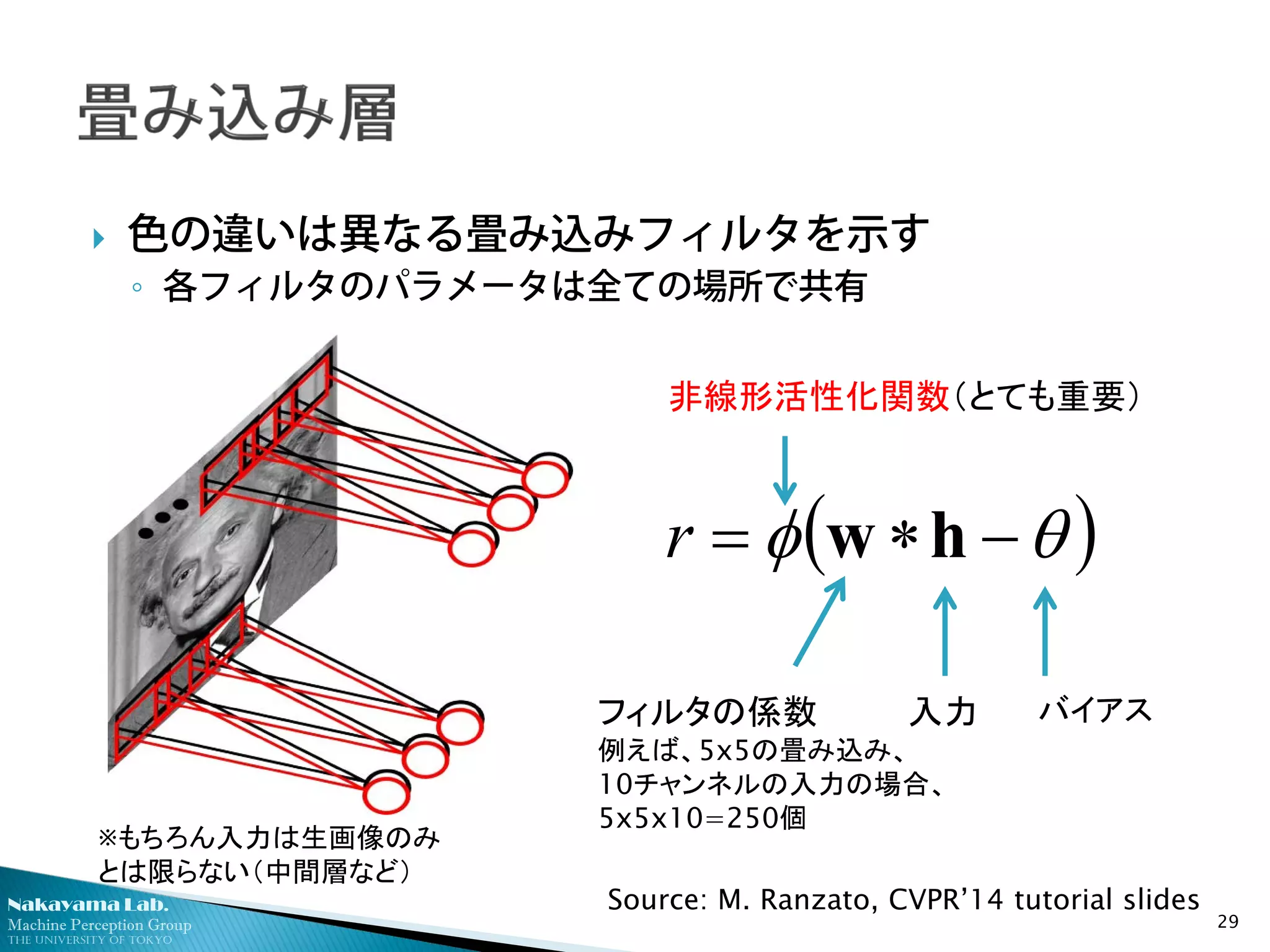
色の違いは異なる畳み込みフィルタを示す
◦ 各フィルタのパラメータは全ての場所で共有
29
※もちろん入力は生画像のみ
とは限らない(中間層など)
( )θφ −∗= hwr
非線形活性化関数(とても重要)
フィルタの係数
例えば、5x5の畳み込み、
10チャンネルの入力の場合、
5x5x10=250個
入力 バイアス
Source: M. Ranzato, CVPR’14 tutorial slides
30.
Nakayama Lab.
Machine PerceptionGroup
The University of Tokyo
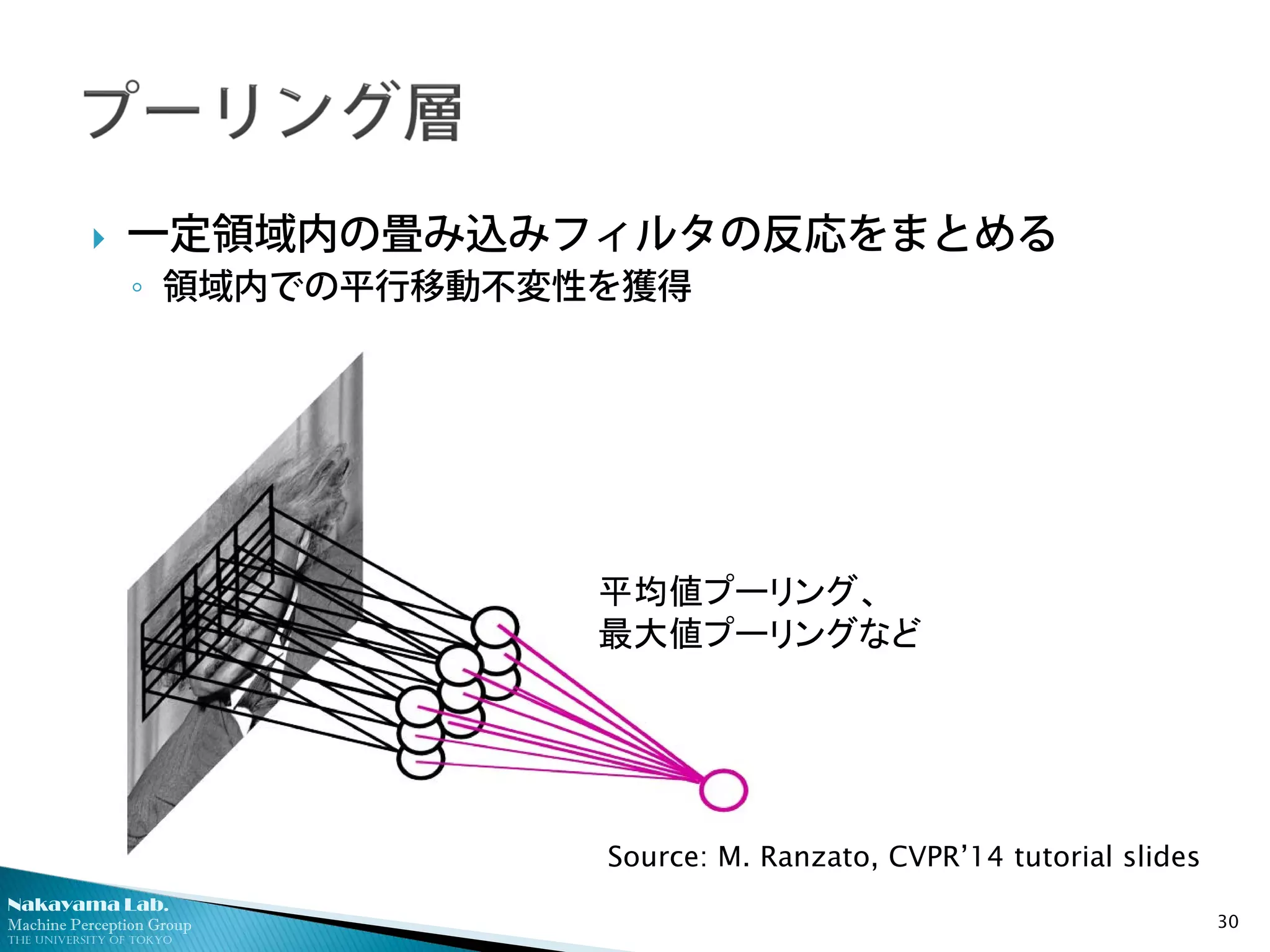
一定領域内の畳み込みフィルタの反応をまとめる
◦ 領域内での平行移動不変性を獲得
30
Source: M. Ranzato, CVPR’14 tutorial slides
平均値プーリング、
最大値プーリングなど
31.
Nakayama Lab.
Machine PerceptionGroup
The University of Tokyo
層を上るにつれ、クラスの分離性能が上がる
31
第1層 第6層
ILSVRC’12 の
validation data
(色は各クラスを示す)
J. Donahue et al., “DeCAF: A Deep Convolutional Activation Feature for Generic
Visual Recognition”, In Proc. ICML, 2014.
32.
Nakayama Lab.
Machine PerceptionGroup
The University of Tokyo
32
Matthew D. Zeiler and Rob Fergus, “Visualizing and Understanding
Convolutional Networks”, In Proc. ECCV, 2014.
33.
Nakayama Lab.
Machine PerceptionGroup
The University of Tokyo
33
Matthew D. Zeiler and Rob Fergus, “Visualizing and Understanding
Convolutional Networks”, In Proc. ECCV, 2014.
Nakayama Lab.
Machine PerceptionGroup
The University of Tokyo
1.画像認識分野におけるdeep learningの歴史
2.一般画像認識:Deep learning 以前と以後で何が変わったか
◦ Bag-of-visual-words
◦ 畳み込みニューラルネット (CNN)
3.Deep learningの数理
◦ なぜ優れた性能が実現できるのか?
◦ ブレークスルーを生んだ要素技術
4.実践するにあたって
◦ 適切に利用するために必要な知識
◦ チューニングの勘所
5.最新の研究動向
42
37.
Nakayama Lab.
Machine PerceptionGroup
The University of Tokyo
ある一定の表現能力を得ようとした場合に…
深いモデルの方が必要なパラメータ数が少なくて済むと考
えられている [Larochelle et al., 2007] [Bengio, 2009] [Delalleau and Bengio, 2011]
(※単純なケース以外では完全に証明されていない)
43
(ちゃんと学習
できれば) 汎化性能
計算効率
スケーラビリティ
反論もある:
“Do Deep Nets Really
Need to be Deep?”
[Ba & Caruana, 2014]
38.
Nakayama Lab.
Machine PerceptionGroup
The University of Tokyo
Sum-product network [Poon and Domingos, UAI’11]
◦ 各ノード(ニューロン)が入力の和か積を出力するネットワーク
同じ多項式関数を表現するために必要なノード数の増加が
◦ 浅いネットワークでは指数的
◦ 深いネットワークでは線形
44
[Delalleau & Bengio, NIPS’11]
39.
Nakayama Lab.
Machine PerceptionGroup
The University of Tokyo
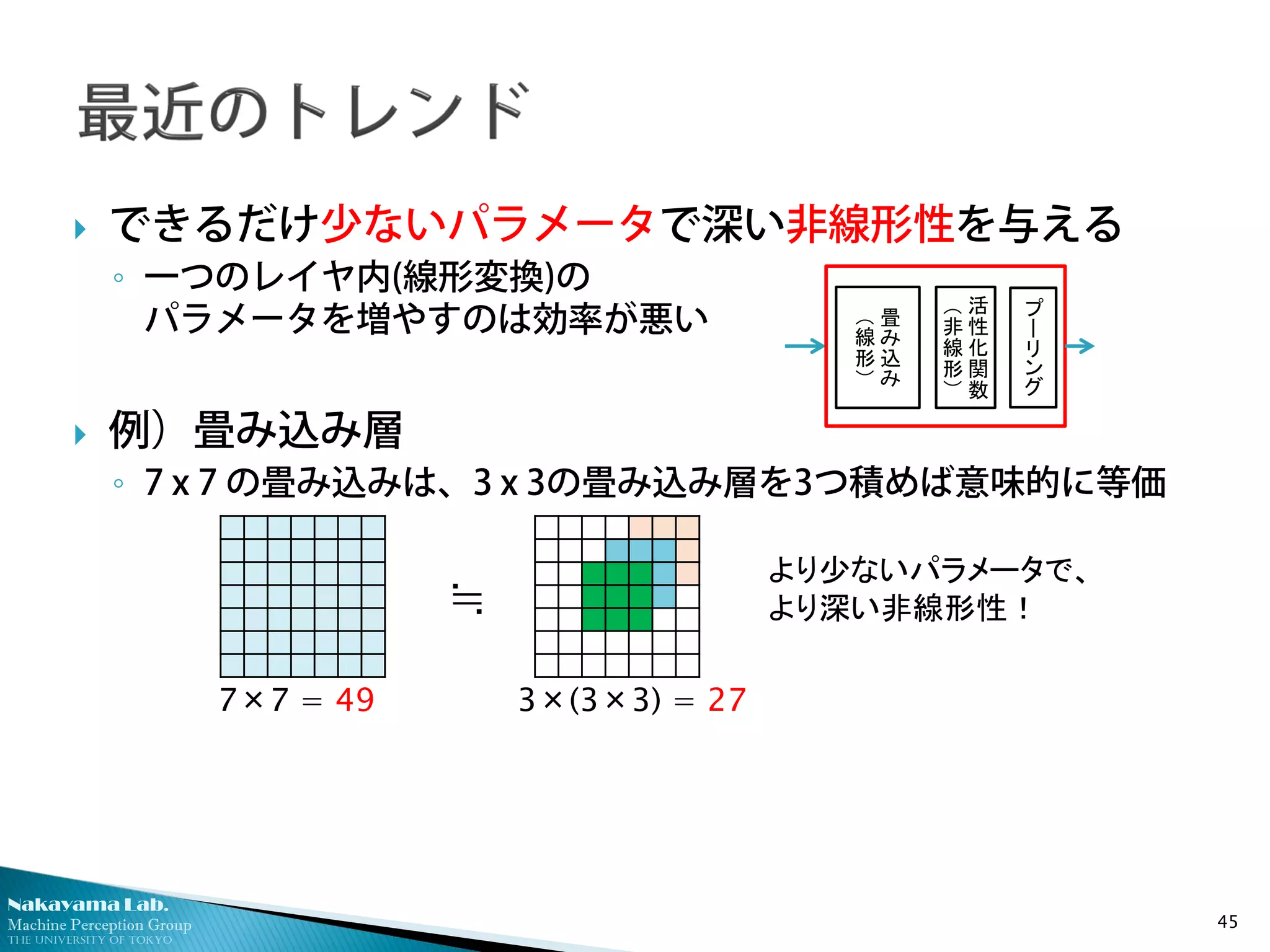
できるだけ少ないパラメータで深い非線形性を与える
◦ 一つのレイヤ内(線形変換)の
パラメータを増やすのは効率が悪い
例)畳み込み層
◦ 7 x 7 の畳み込みは、3 x 3の畳み込み層を3つ積めば意味的に等価
45
≒
活
性
化
関
数
(
非
線
形
)
畳
み
込
み
(
線
形
)
プ
ー
リ
ン
グ
7×7 = 49 3×(3×3) = 27
より少ないパラメータで、
より深い非線形性!
40.
Nakayama Lab.
Machine PerceptionGroup
The University of Tokyo
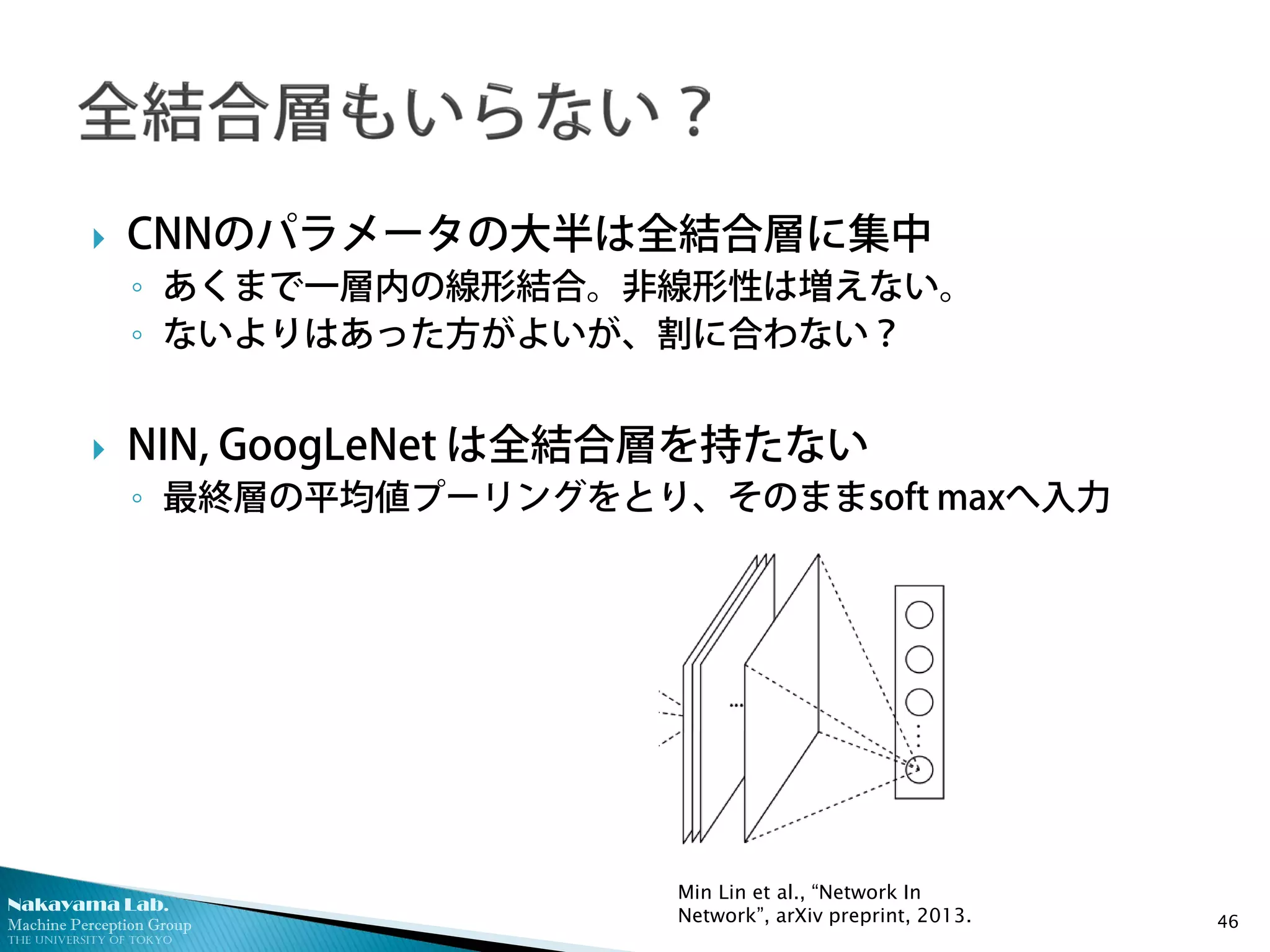
CNNのパラメータの大半は全結合層に集中
◦ あくまで一層内の線形結合。非線形性は増えない。
◦ ないよりはあった方がよいが、割に合わない?
NIN, GoogLeNet は全結合層を持たない
◦ 最終層の平均値プーリングをとり、そのままsoft maxへ入力
46
Min Lin et al., “Network In
Network”, arXiv preprint, 2013.
41.
Nakayama Lab.
Machine PerceptionGroup
The University of Tokyo
GoogLeNetのパラメータ数は、AlexNet (2012) の 1/10以下
全結合層を省略したことが大きい
47
Convolution
Pooling
Softmax
Other
http://www.image-net.org/challenges/LSVRC/2014/slides/GoogLeNet.pptx
GoogLeNet (22層)
42.
Nakayama Lab.
Machine PerceptionGroup
The University of Tokyo
Fisher vector (ILSVRC’11)
◦ 26万次元 × 1000クラス = 約2億6000万
AlexNet (ILSVRC’12)
◦ 約6000万
Network in Network (ILSVRC’13)
◦ 約750万
Deep model の計算コストは“相対的には軽い”!
◦ 同じレベルのパフォーマンスをshallowなアーキテクチャで達成
しようとしたらもっと大変になる(はず)
48
Nakayama Lab.
Machine PerceptionGroup
The University of Tokyo
根本的に昔と何かが変わったわけではない
◦ 地道に問題を潰していった結果
昔、多層パーセプトロンが失敗した主な理由
◦ Vanishing gradient:層を遡る過程で誤差が多数のニューロンへ
拡散されてしまい、パラメータがほとんど更新されない
◦ Overfitting (過学習):訓練データのみに過度に適応する現象
50
×
× ×
×
×
×
×
×
45.
Nakayama Lab.
Machine PerceptionGroup
The University of Tokyo
個人的に重要と思う順番
◦ 0.データの増加、計算機の高速化
◦ 1.活性化関数:Rectified linear units (ReLU)の発明
◦ 2.過学習回避手法:Dropoutの発明
◦ 3.その他、最適化に関する手法・ノウハウの発達
既に時代遅れなりつつある技術も多い
◦ 教師なし事前学習手法
◦ 局所コントラスト正規化
◦ 全結合層、プーリング層もいらないかも?
51
46.
Nakayama Lab.
Machine PerceptionGroup
The University of Tokyo
個人的に重要と思う順番
◦ 0.データの増加、計算機の高速化
◦ 1.活性化関数:Rectified linear units (ReLU)の発明
◦ 2.過学習回避手法:Dropoutの発明
◦ 3.その他、最適化に関する手法・ノウハウの発達
52
47.
Nakayama Lab.
Machine PerceptionGroup
The University of Tokyo
53
シグモイド関数
( )x,0max
( )x−+ exp1
1
サチると勾配が
出ない!
Rectified linear units (ReLU)
[Nair & Hinton, 2010]
( ) ( ) ioldi
T
oldiioldnew fyy xxwww θη −′−+= ˆ
(プラスなら)どこでも
一定の勾配
例)単純パーセプトロン
の更新式
48.
Nakayama Lab.
Machine PerceptionGroup
The University of Tokyo
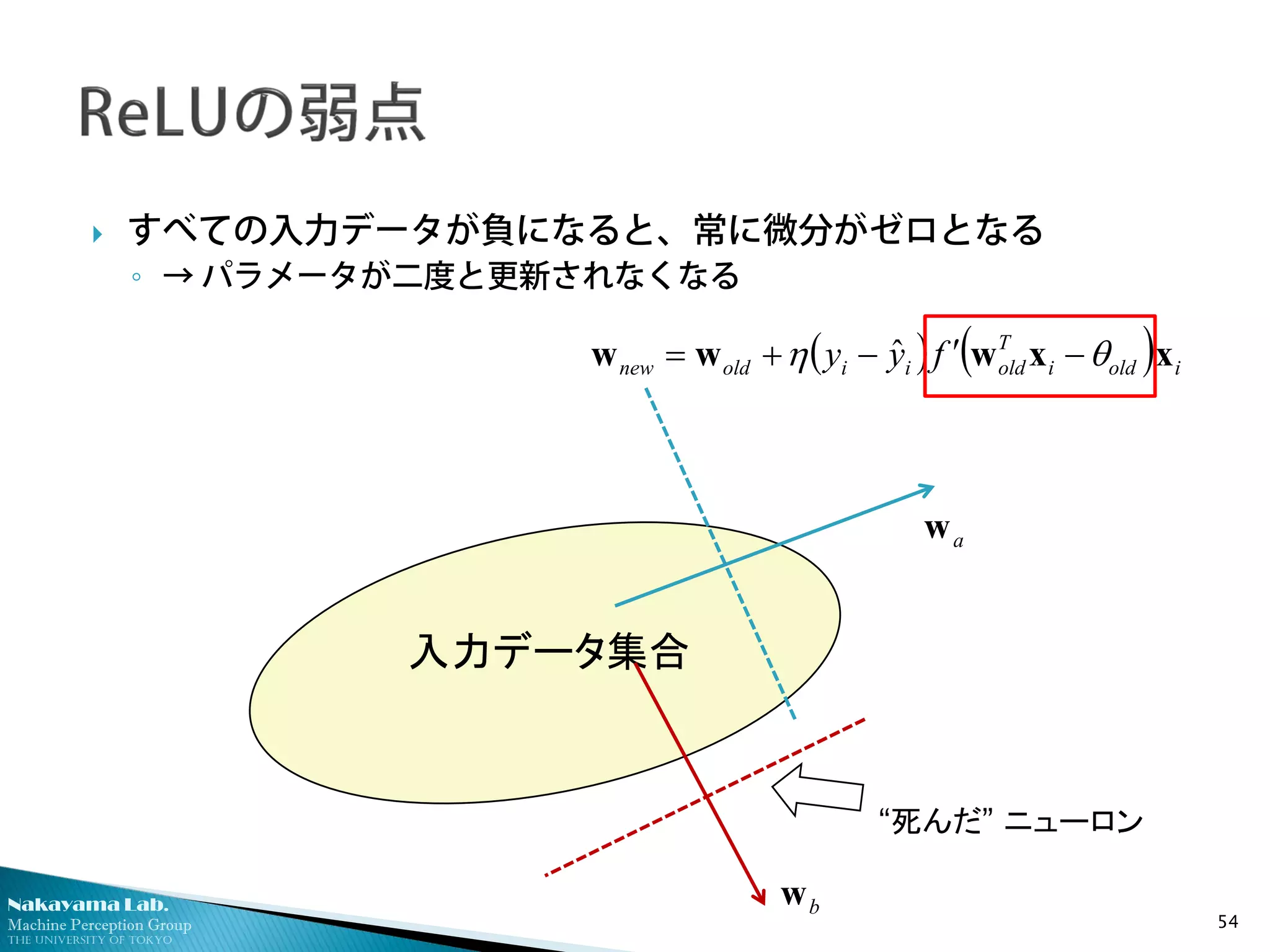
すべての入力データが負になると、常に微分がゼロとなる
◦ → パラメータが二度と更新されなくなる
54
( ) ( ) ioldi
T
oldiioldnew fyy xxwww θη −′−+= ˆ
入力データ集合
“死んだ” ニューロン
aw
bw
49.
Nakayama Lab.
Machine PerceptionGroup
The University of Tokyo
負の側にも少し勾配を与えたReLU
MSR (2015)
◦ 負側の勾配係数もパラメータの一つとしてチューニング
◦ ILSVRC’2014 のデータセットで 4.94% error
55
He et al., “Delving Deep into Rectifiers: Surpassing Human-Level Performance
on ImageNet Classification”, arXiv preprint, 2015.
Xu et al., “Empirical Evaluation of Rectied Activations in Convolution”, arXiv
preprint, 2015.
50.
Nakayama Lab.
Machine PerceptionGroup
The University of Tokyo
各訓練データ(バッチ)のフィードバックの際に、
一定確率(0.5)で中間ニューロンを無視
認識時は全ニューロンを使うが、結合重みを半分にする
多数のネットワークを混ぜた構造
◦ 訓練データが各ニューロンで異なるため、
バギングと同様の効果
(ただしパラメータは共有)
L2正規化に近い効果
◦ [Wager et al., NIPS’13]
以前と比較して大幅な精度向上
◦ ほぼ必須のテクニック
56
L∇ ( )iiL yx ,
51.
Nakayama Lab.
Machine PerceptionGroup
The University of Tokyo
Drop connect [Wan et al., ICML’13]
◦ ニューロンではなく、結合をランダムに落とす
Adaptive dropout [Ba et al., NIPS’13]
◦ Dropoutで落とすニューロンをランダムでなく適応的に選択する
57
52.
Nakayama Lab.
Machine PerceptionGroup
The University of Tokyo
実際に学習を実行するのは非常に困難
◦ 設定すべきハイパーパラメータが極めて多い!
Y. Bengio (2012), “Practical recommendations for
Gradient-based training of deep architectures”
◦ 学習率の設定・スケジューリング、early stopping
◦ ミニバッチサイズ
◦ ドロップアウトのパラメータ
◦ Early stopping
◦ パラメータ初期化方法
◦ 隠れ層のニューロン数
◦ L1/L2 weight decay
◦ Sparsity regularization
…などなど
58
最重要!
どれか一つチューニング
するとしたらこれ
53.
Nakayama Lab.
Machine PerceptionGroup
The University of Tokyo
1.画像認識分野におけるdeep learningの歴史
2.一般画像認識:Deep learning 以前と以後で何が変わったか
◦ Bag-of-visual-words
◦ 畳み込みニューラルネット (CNN)
3.Deep learningの数理
◦ なぜ優れた性能が実現できるのか?
◦ ブレークスルーを生んだ要素技術
4.実践するにあたって
◦ 適切に利用するために必要な知識
◦ チューニングの勘所
5.最新の研究動向
59
54.
Nakayama Lab.
Machine PerceptionGroup
The University of Tokyo
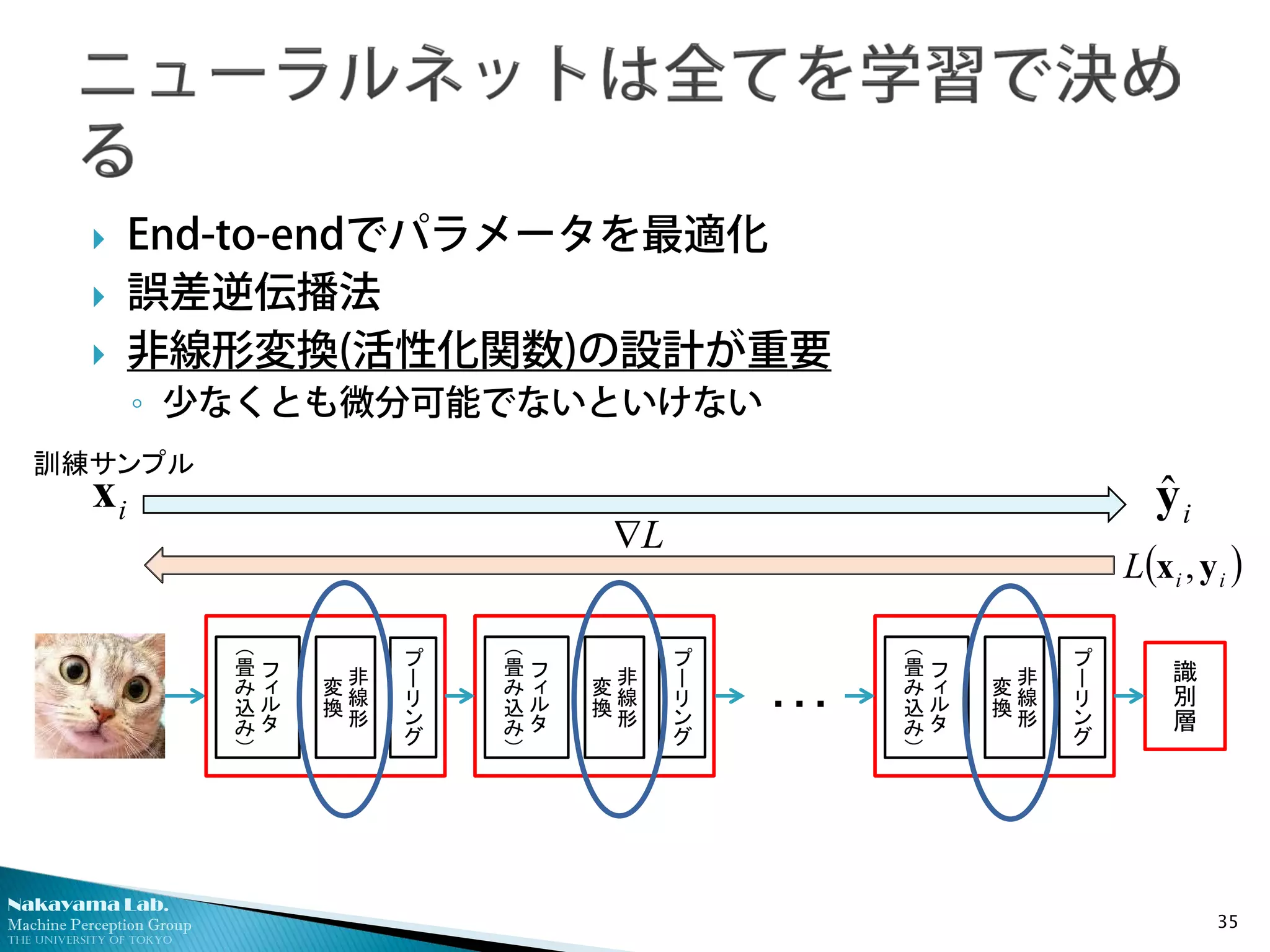
自分の解きたい問題に対して、
どのようにdeep learningを使うべきか?
◦ 十分な効果を得るには、かなり多くの教師付訓練データが必要
◦ 必ずしもフルスクラッチから学習することが賢いとは限らない
そもそもdeep learningを利用可能な問題か?
◦ 使わない方が幸せになれることも多い…
60
55.
Nakayama Lab.
Machine PerceptionGroup
The University of Tokyo
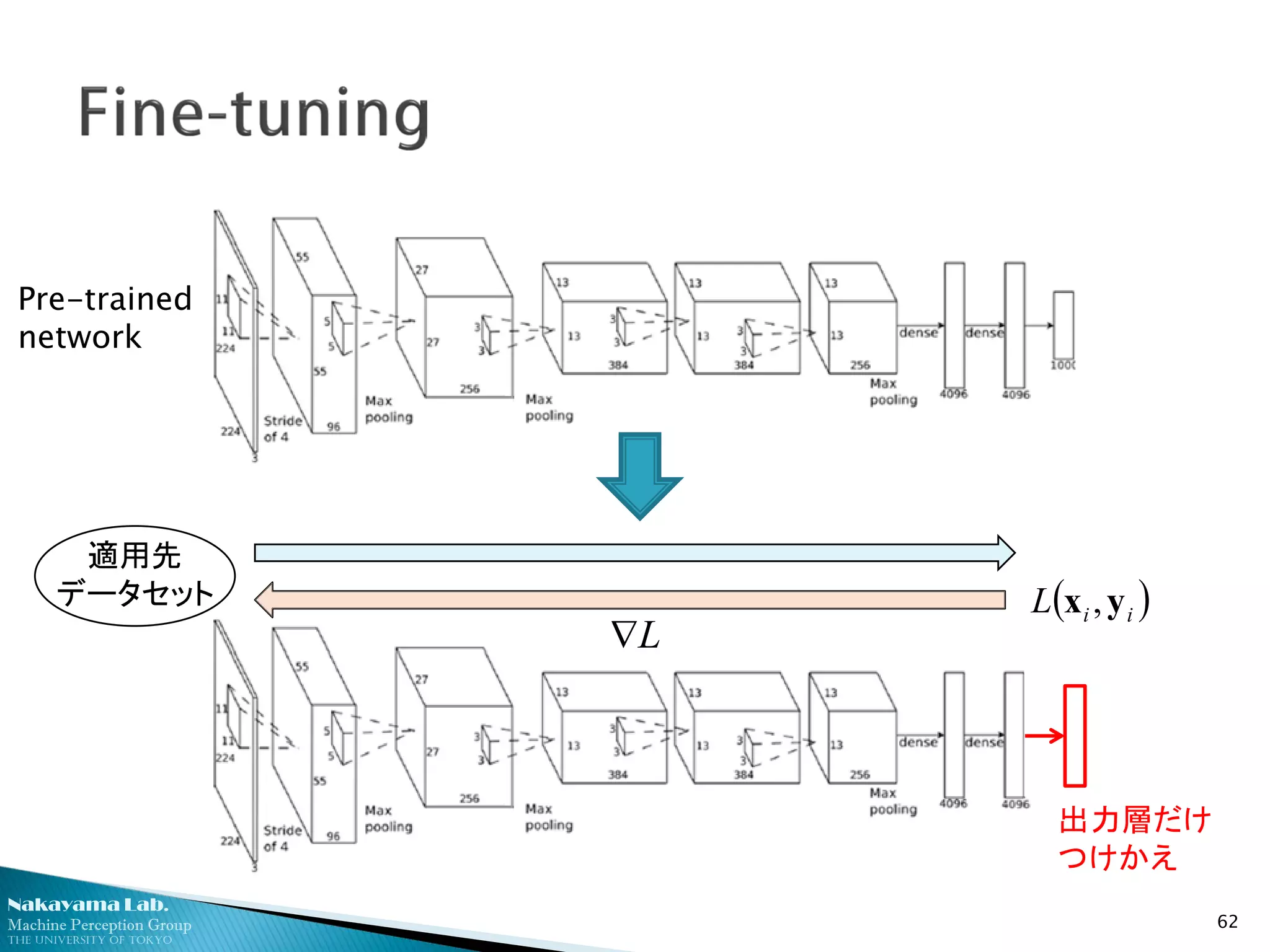
あらかじめ汎用性の高い大規模教師付データセットでネット
ワークを学習しておき、これを初期値としてターゲットタスク
の学習データでさらに細かい学習を進める(=Fine-tuning)
(教師なし事前学習とは違う概念であることに注意)
例えば…
61
ImageNet ILSVRC’12
130万枚、1000クラス
PASCAL VOC 2007
5千枚、20クラス
Nakayama Lab.
Machine PerceptionGroup
The University of Tokyo
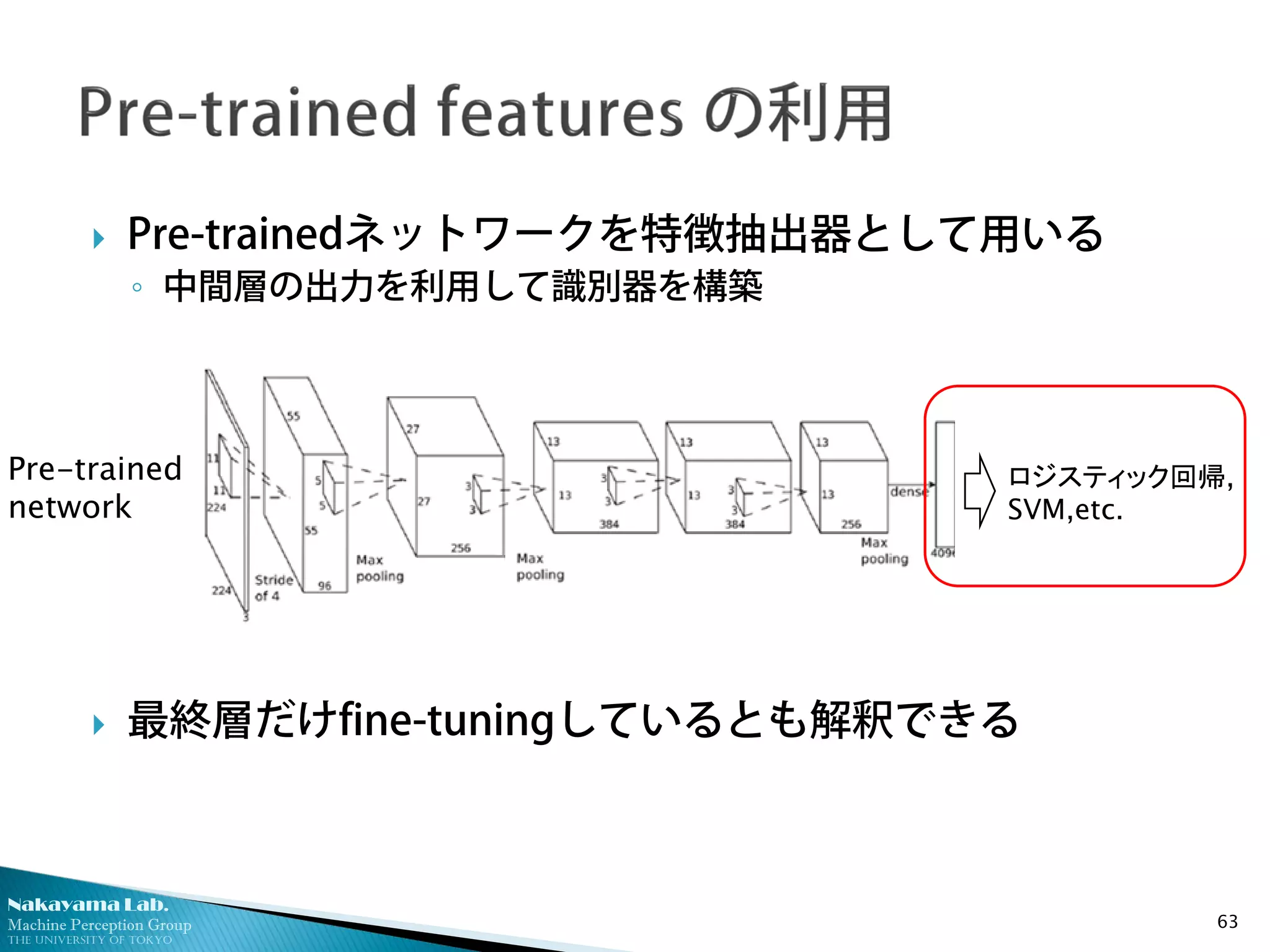
Pre-trainedネットワークを特徴抽出器として用いる
◦ 中間層の出力を利用して識別器を構築
最終層だけfine-tuningしているとも解釈できる
63
Pre-trained
network
ロジスティック回帰,
SVM,etc.
58.
Nakayama Lab.
Machine PerceptionGroup
The University of Tokyo
ILSVRC 2012 → VOC 2007 の例 (検出成功率、mAP%)
◦ フルスクラッチCNN: 40.7
◦ Pre-trained feature: 45.5
◦ Fine tuning: 54.1
64
Agrawal et al., “Analyzing the Performance of Multilayer Neural
Networks for Object Recognition”, In Proc. ECCV, 2014.
ImageNet ILSVRC’12
130万枚、1000クラス
PASCAL VOC 2007
5千枚、20クラス
59.
Nakayama Lab.
Machine PerceptionGroup
The University of Tokyo
Pre-trainingに用いる外部データセットが、所望のタス
クを内包するものでなければ効果が薄い(むしろ悪化)
◦ ImageNetはあくまで物体認識のデータセット
参考:Fine-grained competition 2013
65
https://sites.google.com/site/fgcomp2013/
Fisher
vector
CNN
(fine-
tuning)
飛行機、車、靴データセットなど、ImageNet上にあまりデータが
存在しないドメインに関してはターゲットの学習データのみ用いた
Fisher vector (BoVW) の方が良かった
60.
Nakayama Lab.
Machine PerceptionGroup
The University of Tokyo
66
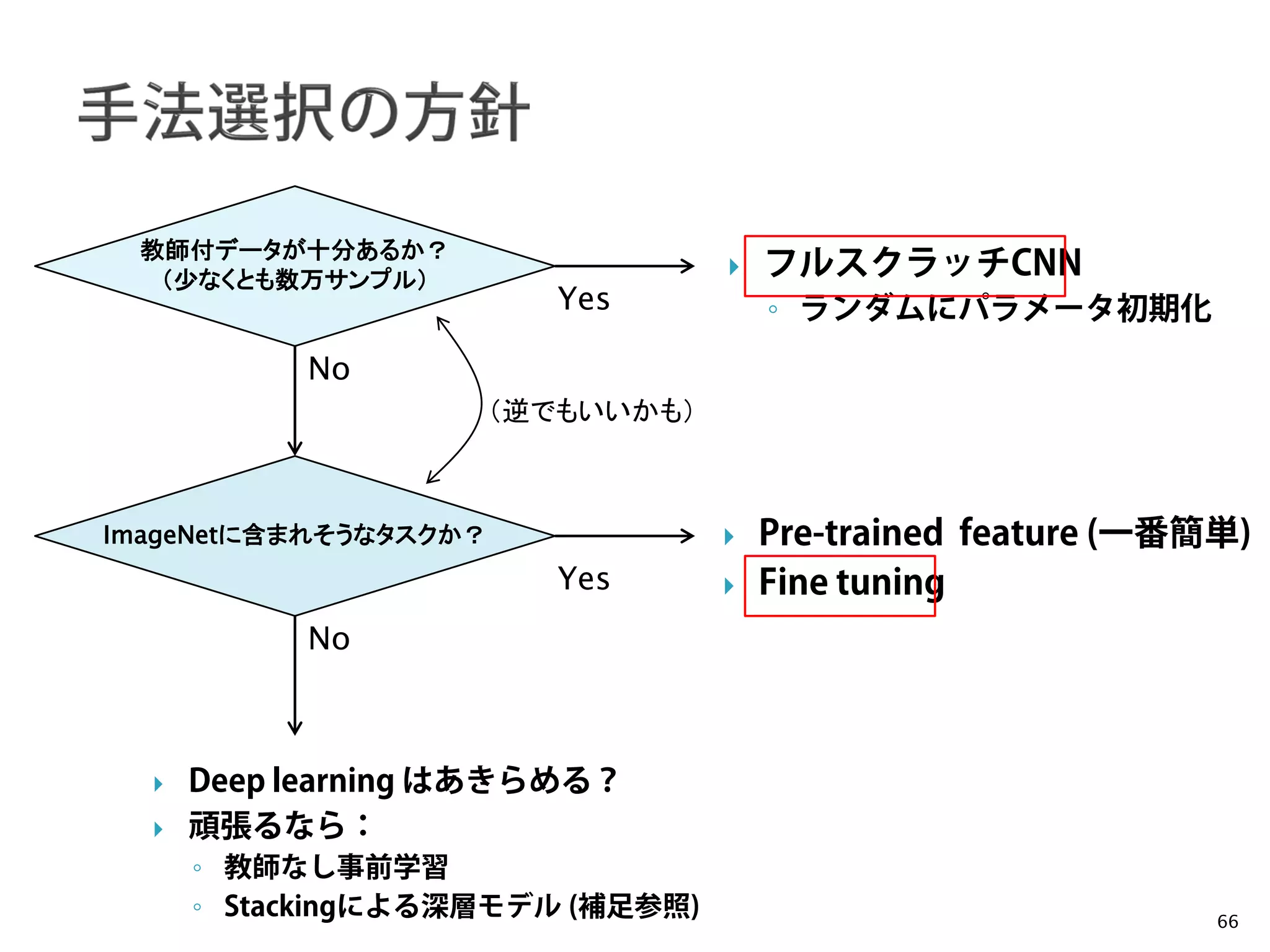
教師付データが十分あるか?
(少なくとも数万サンプル)
ImageNetに含まれそうなタスクか?
Yes
No
No
Yes
Deep learning はあきらめる?
頑張るなら:
◦ 教師なし事前学習
◦ Stackingによる深層モデル (補足参照)
フルスクラッチCNN
◦ ランダムにパラメータ初期化
Pre-trained feature (一番簡単)
Fine tuning
(逆でもいいかも)
61.
Nakayama Lab.
Machine PerceptionGroup
The University of Tokyo
ハードウェア
◦ 学習にはGPU計算機が必要 (CUDAを利用)
◦ ビデオメモリの容量がボトルネックになる場合が多い
メインメモリとの通信は遅い
ネットワークのパラメータはもちろん、できるだけ多くの学習
サンプルをビデオメモリに積みたい
Titan Black (約15万円)
◦ コストパフォーマンス的にお薦め
◦ 当研究室では、これを積んだPCが6台ほど
Tesla K20 (約40万円), K40 (約80万円)
◦ より信頼性が高い
67
62.
Nakayama Lab.
Machine PerceptionGroup
The University of Tokyo
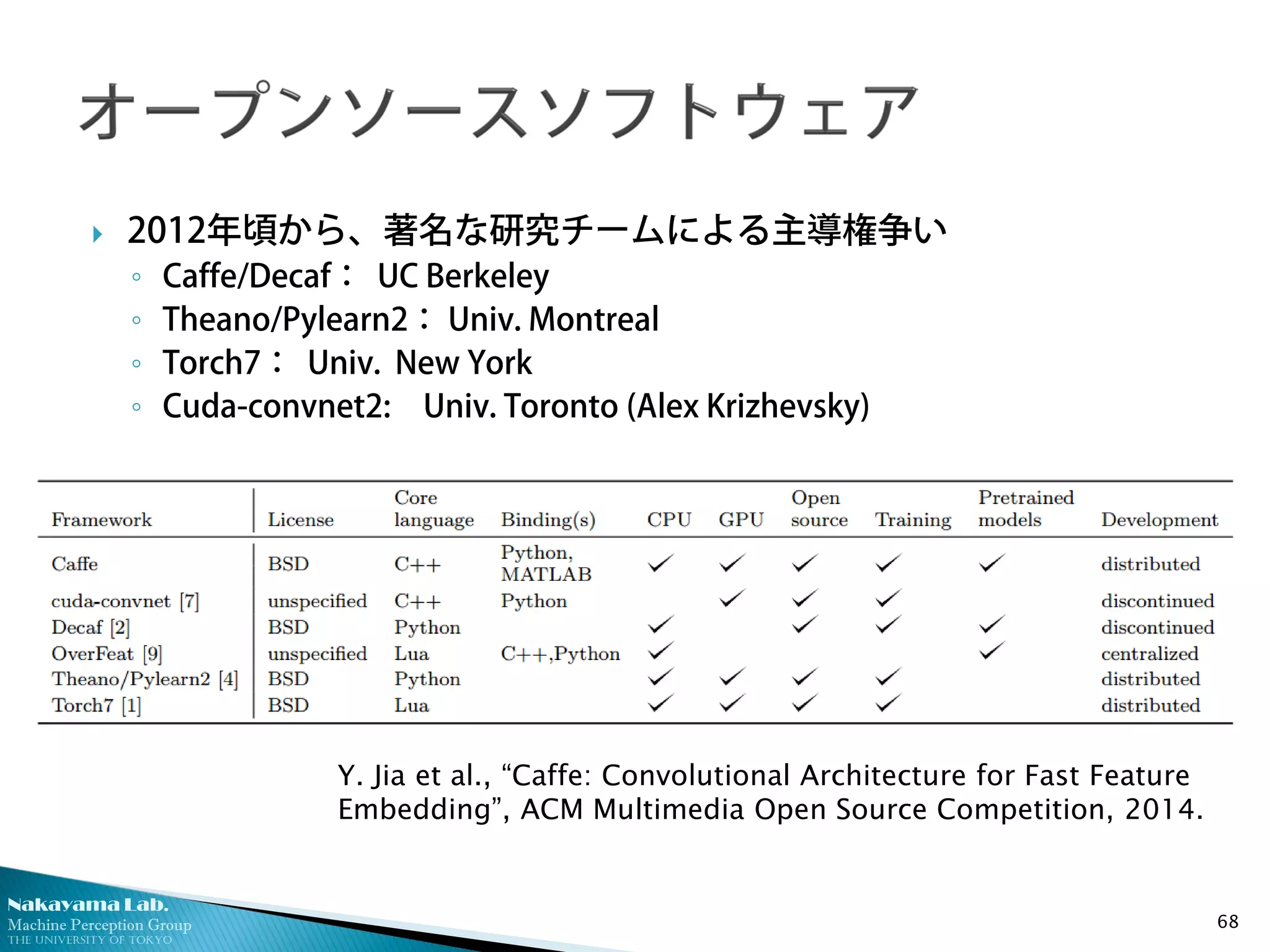
2012年頃から、著名な研究チームによる主導権争い
◦ Caffe/Decaf: UC Berkeley
◦ Theano/Pylearn2: Univ. Montreal
◦ Torch7: Univ. New York
◦ Cuda-convnet2: Univ. Toronto (Alex Krizhevsky)
いずれも、複数の便利な環境を提供
◦ C++, Python, Matlabインタフェース
◦ CPUとGPUの切り替えによる開発効率化
◦ ネットワークパラメータの設定・探索フレームワーク
68
Y. Jia et al., “Caffe: Convolutional Architecture for Fast Feature
Embedding”, ACM Multimedia Open Source Competition, 2014.
63.
Nakayama Lab.
Machine PerceptionGroup
The University of Tokyo
画像系ではデファクトスタンダード
◦ トップクラスに高速
◦ オープンソースコミュニティとして確立しつつある
多くの研究者が既に自分の研究に利用
◦ Oxford visual geometry group など
Model Zoo
◦ 各研究者の学習済みネットワークを共有
◦ AlexNetはもちろん、Network-in-network、GoogLeNet モデルなども
◦ 最新の成果を極めて容易に試せる
69
64.
Nakayama Lab.
Machine PerceptionGroup
The University of Tokyo
Webドキュメントが充実 http://caffe.berkeleyvision.org/
◦ ImageNet等の結果を再現可能
◦ IPython notebookによる
コード実例多数
ECCV 2014でのチュートリアル
◦ http://tutorial.caffe.berkeleyvision.org/
70
65.
Nakayama Lab.
Machine PerceptionGroup
The University of Tokyo
71
ECCV’14 チュートリアルスライド「DIY Deep Learning for Vision:
a Hands-On Tutorial with Caffe」より引用
66.
Nakayama Lab.
Machine PerceptionGroup
The University of Tokyo
ネットワークの初期値をランダムに与える
誤差逆伝播法でパラメータ更新
◦ 適当な大きさのミニバッチでフィードフォワード・フィード
バックを繰り返す(100枚単位など)
◦ データをあらかじめシャッフルしておくこと
72
L∇
ミニバッチ
X Yˆ
Source: [Smirnov et al., 2014]
$ build/tools/convert_imageset --backend leveldb --shuffle 101_ObjectCategories/ ・・・
67.
Nakayama Lab.
Machine PerceptionGroup
The University of Tokyo
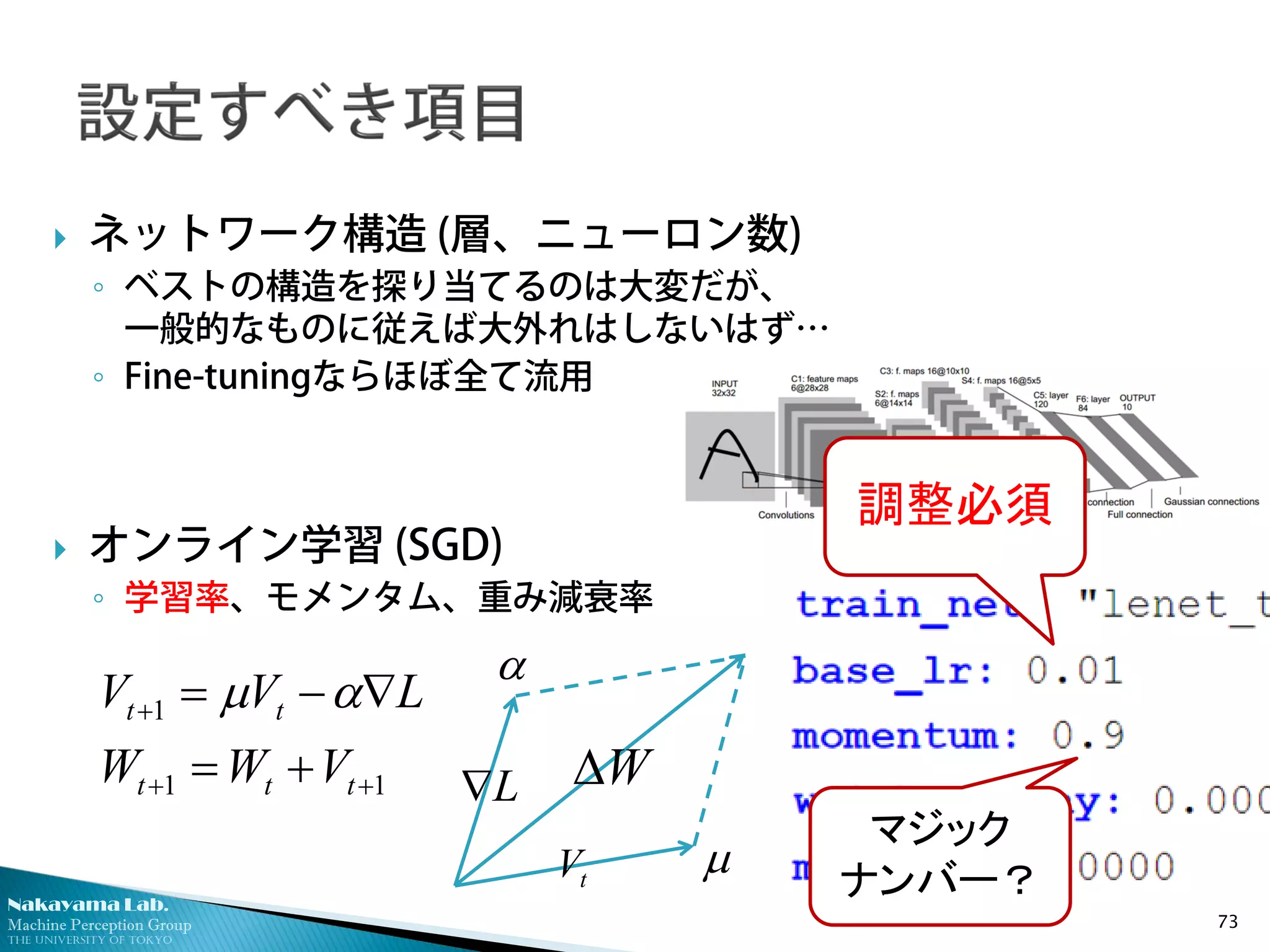
ネットワーク構造 (層、ニューロン数)
◦ ベストの構造を探り当てるのは大変だが、
一般的なものに従えば大外れはしないはず…
◦ Fine-tuningならほぼ全て流用
オンライン学習 (SGD)
◦ 学習率、モメンタム、重み減衰率
73
11
1
++
+
+=
∇−=
ttt
tt
VWW
LVV αµ
W∆
tV
L∇
α
µ
調整必須
マジック
ナンバー?
68.
Nakayama Lab.
Machine PerceptionGroup
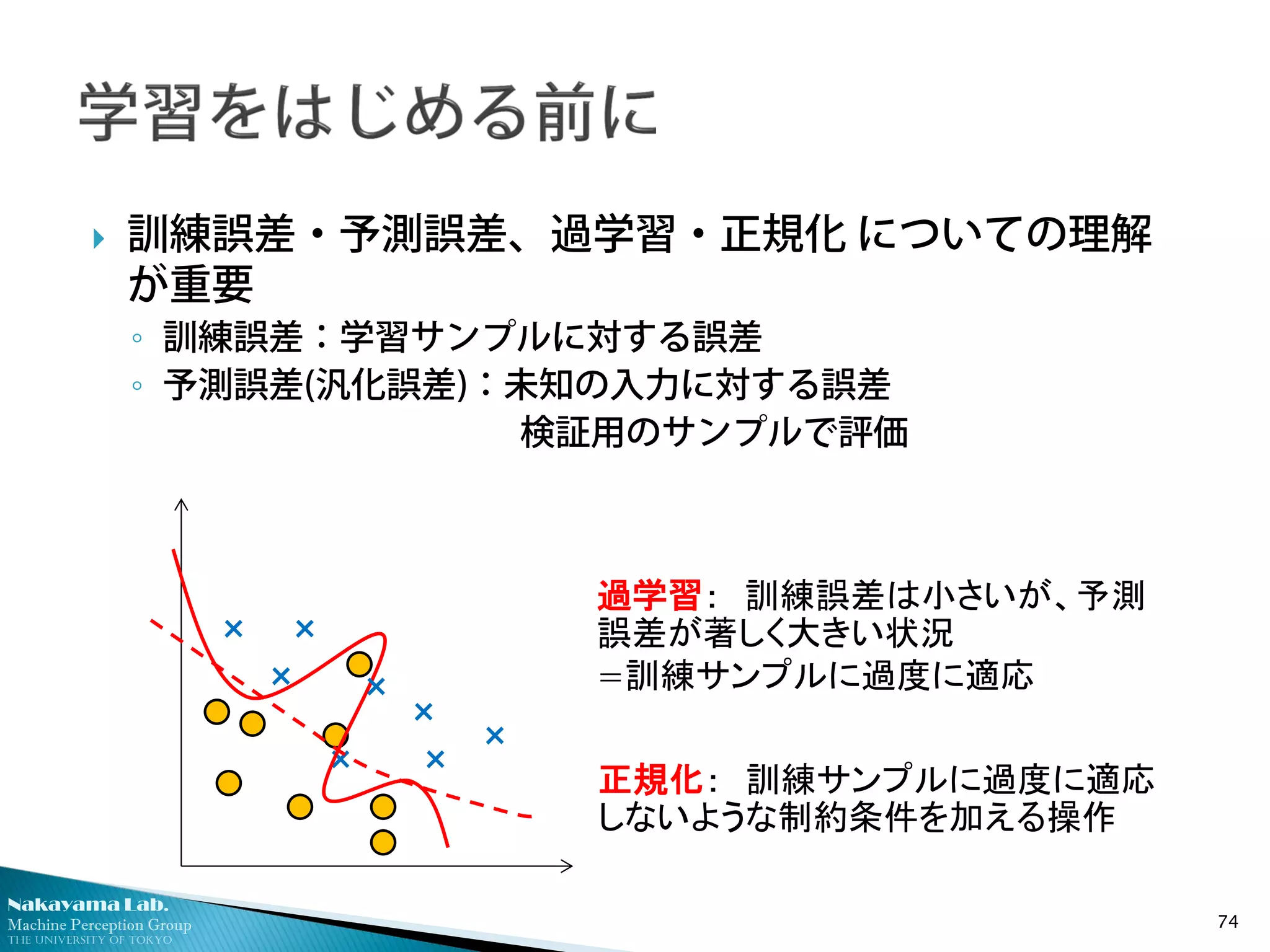
The University of Tokyo
訓練誤差・予測誤差、過学習・正規化 についての理解
が重要
◦ 訓練誤差:学習サンプルに対する誤差
◦ 予測誤差(汎化誤差):未知の入力に対する誤差
検証用のサンプルで評価
74
×
× ×
×
×
×
×
×
過学習: 訓練誤差は小さいが、予測
誤差が著しく大きい状況
=訓練サンプルに過度に適応
正規化: 訓練サンプルに過度に適応
しないような制約条件を加える操作
69.
Nakayama Lab.
Machine PerceptionGroup
The University of Tokyo
I1120 11:27:09.007803 537 solver.cpp:160] Solving CaffeNet
I1120 11:27:09.007859 537 solver.cpp:247] Iteration 0, Testing net (#0)
I1120 11:27:17.979998 537 solver.cpp:298] Test net output #0: accuracy = 0.0048
I1120 11:27:17.980051 537 solver.cpp:298] Test net output #1: loss = 5.01857 (* 1 = 5.01857 loss)
I1120 11:27:18.068891 537 solver.cpp:191] Iteration 0, loss = 5.38866
I1120 11:27:18.068940 537 solver.cpp:206] Train net output #0: loss = 5.38866 (* 1 = 5.38866 loss)
I1120 11:27:18.068958 537 solver.cpp:403] Iteration 0, lr = 0.001
I1120 11:27:19.620609 537 solver.cpp:247] Iteration 10, Testing net (#0)
I1120 11:27:28.556694 537 solver.cpp:298] Test net output #0: accuracy = 0.1096
I1120 11:27:28.556756 537 solver.cpp:298] Test net output #1: loss = 4.34054 (* 1 = 4.34054 loss)
I1120 11:27:28.634579 537 solver.cpp:191] Iteration 10, loss = 5.02612
I1120 11:27:28.634629 537 solver.cpp:206] Train net output #0: loss = 5.02612 (* 1 = 5.02612 loss)
I1120 11:27:28.634642 537 solver.cpp:403] Iteration 10, lr = 0.001
I1120 11:27:30.183964 537 solver.cpp:247] Iteration 20, Testing net (#0)
I1120 11:27:39.118187 537 solver.cpp:298] Test net output #0: accuracy = 0.2762
I1120 11:27:39.118242 537 solver.cpp:298] Test net output #1: loss = 3.7547 (* 1 = 3.7547 loss)
I1120 11:27:39.196316 537 solver.cpp:191] Iteration 20, loss = 3.64996
I1120 11:27:39.196364 537 solver.cpp:206] Train net output #0: loss = 3.64996 (* 1 = 3.64996 loss)
I1120 11:27:39.196377 537 solver.cpp:403] Iteration 20, lr = 0.001
I1120 11:27:40.746333 537 solver.cpp:247] Iteration 30, Testing net (#0)
I1120 11:27:49.677788 537 solver.cpp:298] Test net output #0: accuracy = 0.4078
I1120 11:27:49.677836 537 solver.cpp:298] Test net output #1: loss = 2.97932 (* 1 = 2.97932 loss)
I1120 11:27:49.755615 537 solver.cpp:191] Iteration 30, loss = 3.5529
I1120 11:27:49.755662 537 solver.cpp:206] Train net output #0: loss = 3.5529 (* 1 = 3.5529 loss)
I1120 11:27:49.755676 537 solver.cpp:403] Iteration 30, lr = 0.001
I1120 11:27:51.304983 537 solver.cpp:247] Iteration 40, Testing net (#0)
I1120 11:28:00.235947 537 solver.cpp:298] Test net output #0: accuracy = 0.5382
I1120 11:28:00.236030 537 solver.cpp:298] Test net output #1: loss = 2.32026 (* 1 = 2.32026 loss)
I1120 11:28:00.313851 537 solver.cpp:191] Iteration 40, loss = 2.67447
I1120 11:28:00.313899 537 solver.cpp:206] Train net output #0: loss = 2.67447 (* 1 = 2.67447 loss)
)
75
予測誤差
訓練誤差
70.
Nakayama Lab.
Machine PerceptionGroup
The University of Tokyo
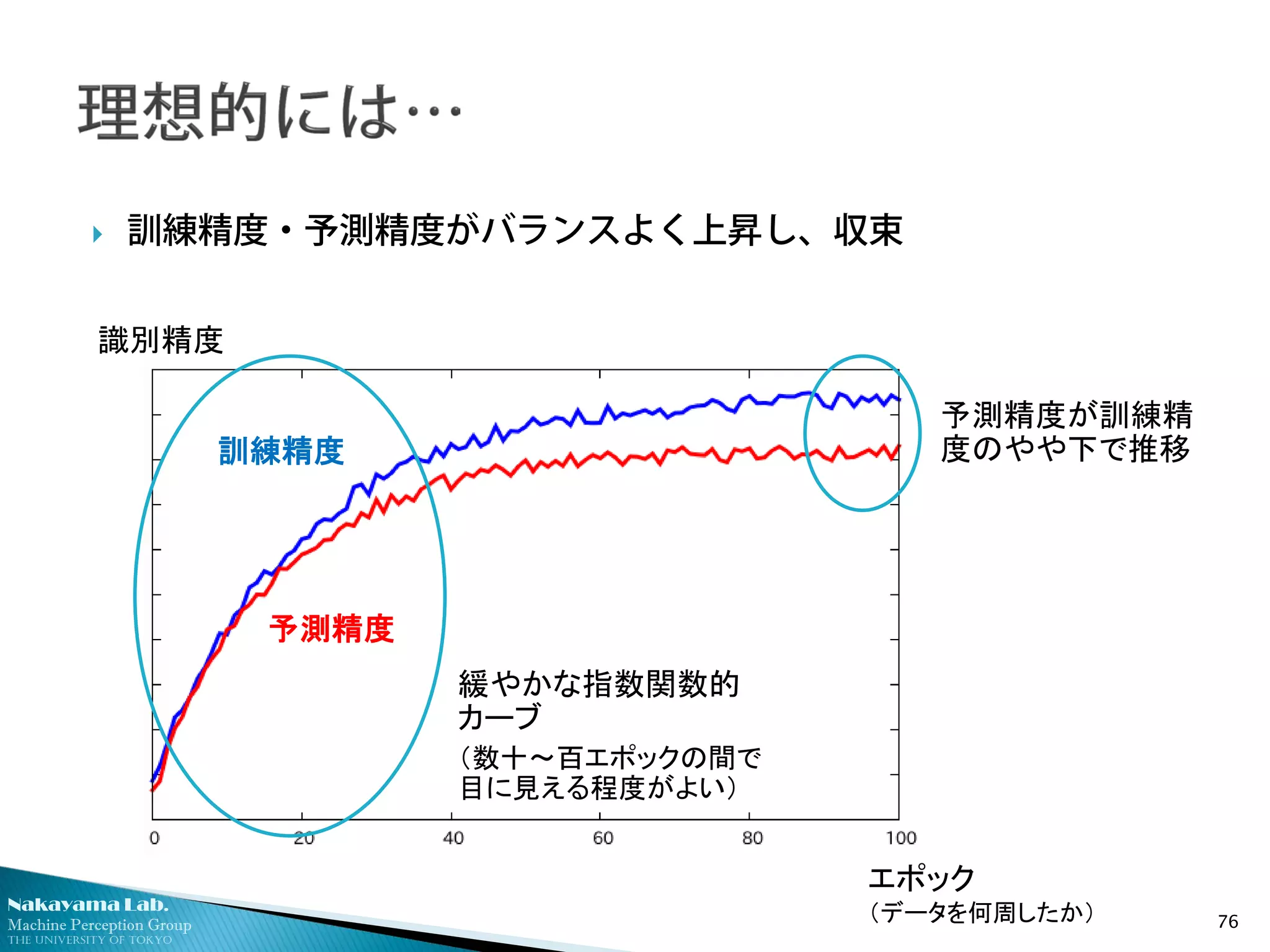
訓練精度・予測精度がバランスよく上昇し、収束
76
エポック
(データを何周したか)
識別精度
予測精度
訓練精度
緩やかな指数関数的
カーブ
(数十~百エポックの間で
目に見える程度がよい)
予測精度が訓練精
度のやや下で推移
71.
Nakayama Lab.
Machine PerceptionGroup
The University of Tokyo
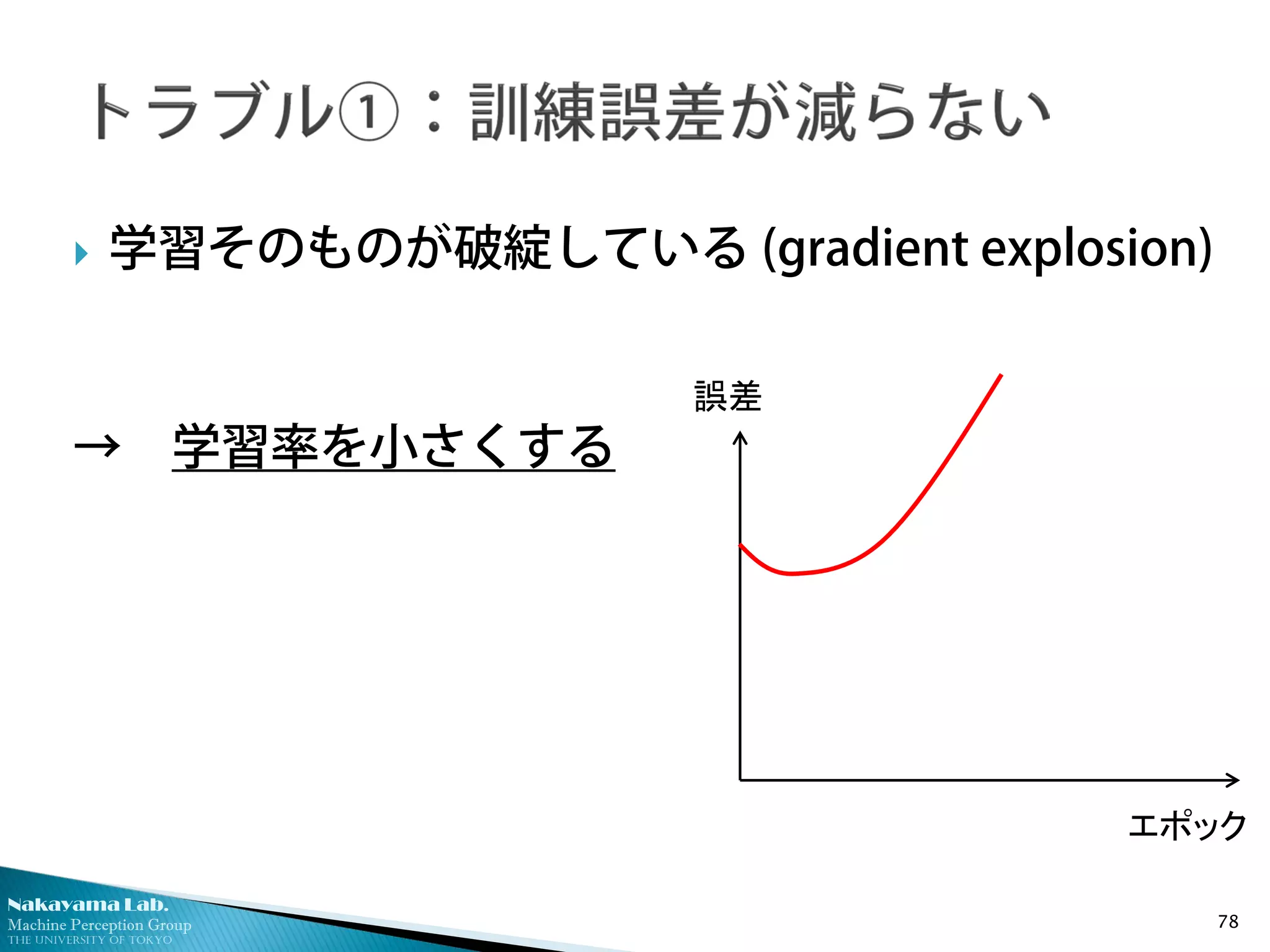
① 訓練誤差が減っていない
◦ 学習そのものが破綻
② 訓練誤差は減っているが、予測誤差が非常に大きい
◦ 過学習(オーバーフィッティング)
③ 訓練誤差と予測誤差がほとんど変わらない
◦ アンダーフィッティング
◦ 致命的ではないが、もったいない(もっと精度を上げられる)
77
Nakayama Lab.
Machine PerceptionGroup
The University of Tokyo
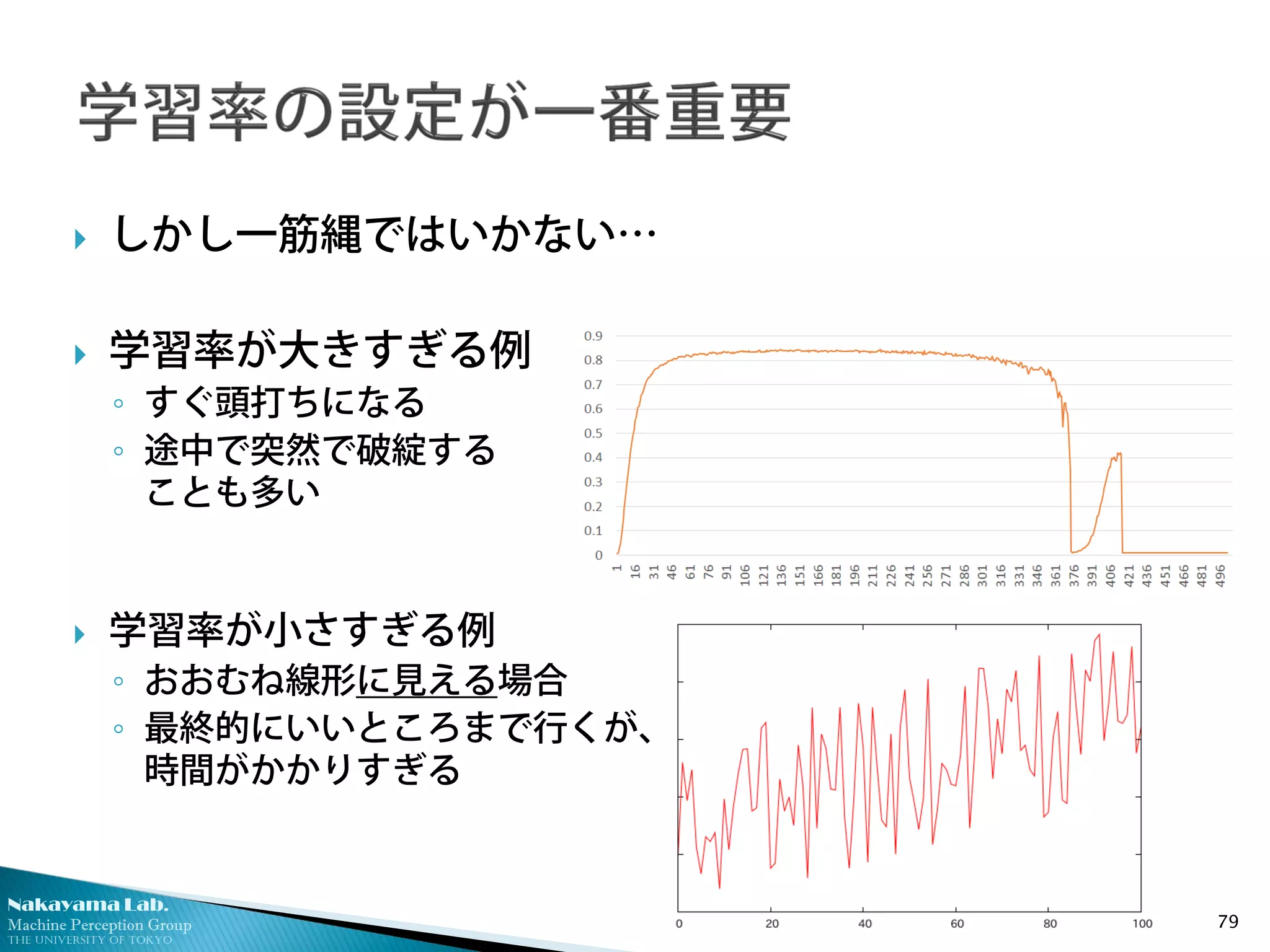
しかし一筋縄ではいかない…
学習率が大きすぎる例
◦ すぐ頭打ちになる
◦ 途中で突然で破綻する
ことも多い
学習率が小さすぎる例
◦ おおむね線形に見える場合
◦ 最終的にいいところまで行くが、
時間がかかりすぎる
79
74.
Nakayama Lab.
Machine PerceptionGroup
The University of Tokyo
時間の経過(=学習の進行)に伴い、
学習率を小さくしていく操作
例)cuda-convnet チュートリアル (Krizhevsky)
◦ 0.001 (150エポック) → 0.0001 (10エポック) → 0.00001 (10エポック)
◦ 精度向上が頭打ちになったら下げてみる?
単純に時間減衰させてもよい
◦ 1/t, exp(-t) など
(参考)
◦ 学習率を自動設定する研究も進みつつある
80
Leslie N. Smith, “No More Pesky Learning Rate Guessing Games”, arXiv preprint, 2015.
75.
Nakayama Lab.
Machine PerceptionGroup
The University of Tokyo
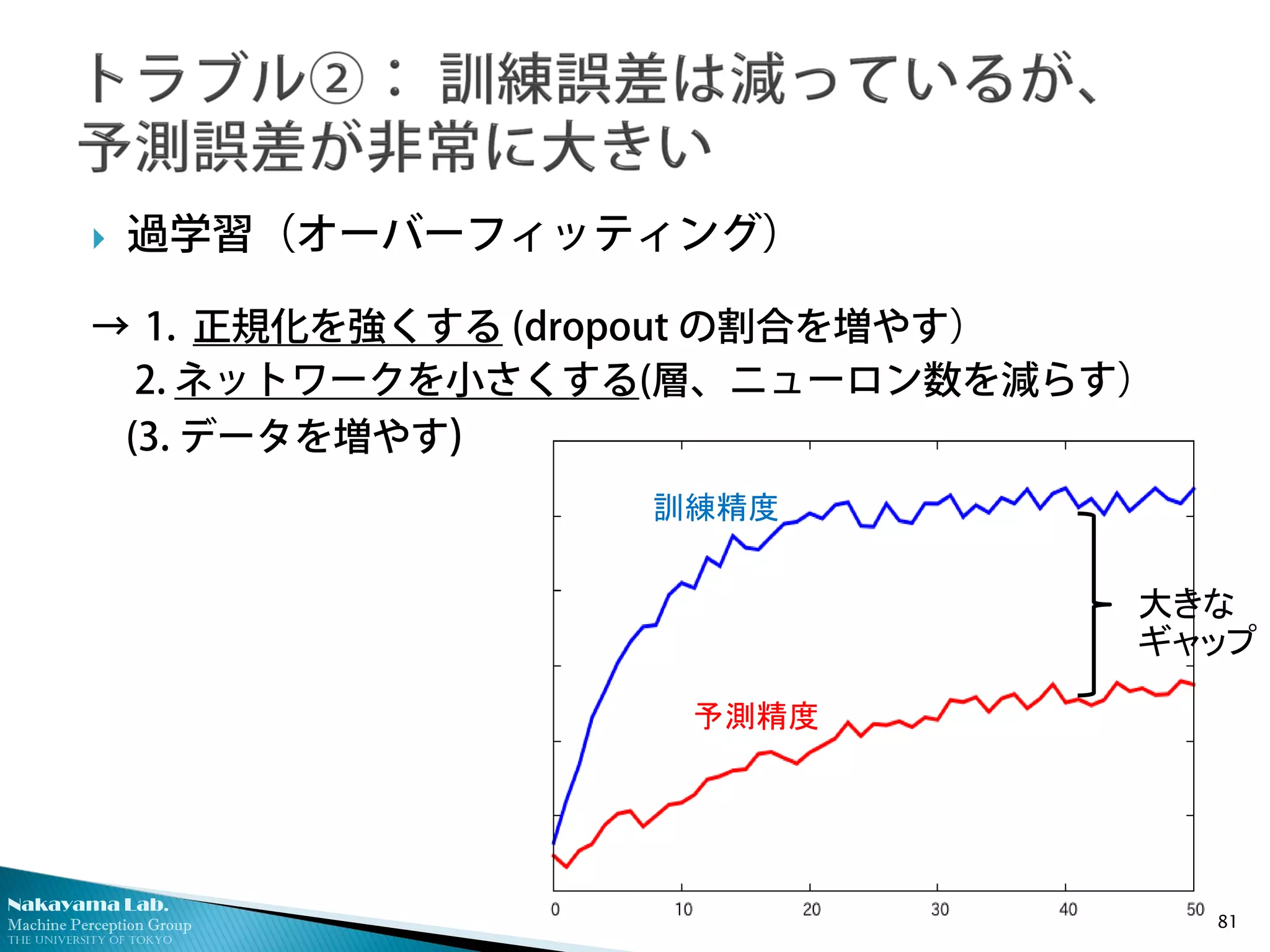
過学習(オーバーフィッティング)
→ 1. 正規化を強くする (dropout の割合を増やす)
2. ネットワークを小さくする(層、ニューロン数を減らす)
(3. データを増やす)
81
予測精度
訓練精度
大きな
ギャップ
76.
Nakayama Lab.
Machine PerceptionGroup
The University of Tokyo
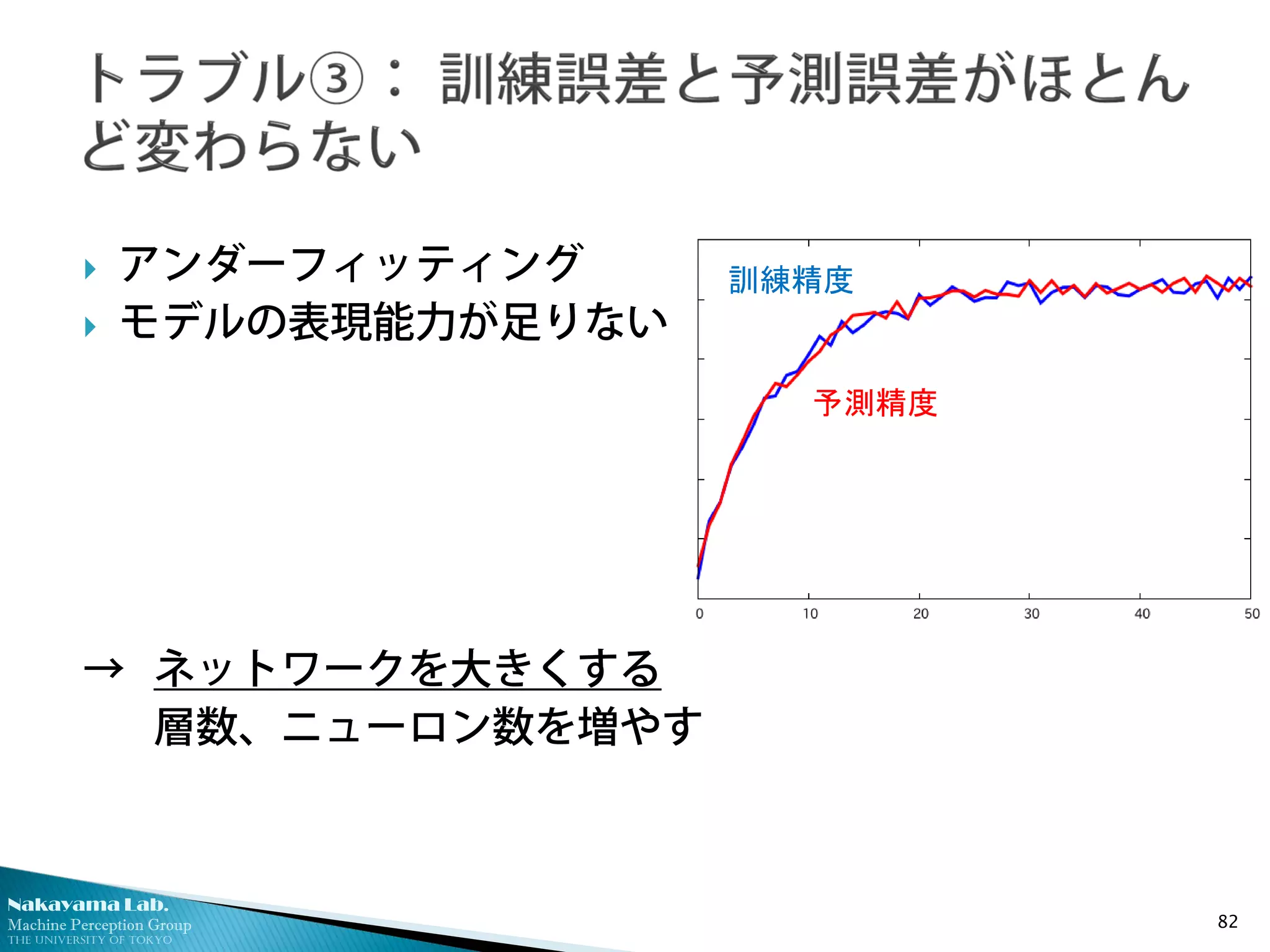
アンダーフィッティング
モデルの表現能力が足りない
→ ネットワークを大きくする
層数、ニューロン数を増やす
82
予測精度
訓練精度
77.
Nakayama Lab.
Machine PerceptionGroup
The University of Tokyo
データの前処理 (かなり重要)
◦ ZCA whitening (白色化)
コントラスト正規化など
◦ 最終的な識別性能に大きく影響する
Data augmentation
◦ アフィン変換、クロップなど、人工的に
さまざまな変換を学習データに加える
◦ 平行移動以外の不変性を学習させる
◦ GoogLeNetでは144倍にデータ拡張
83
[Zeiler and Fergus, 2013]
[Dosovitskiy et al., 2014]
78.
Nakayama Lab.
Machine PerceptionGroup
The University of Tokyo
1.画像認識分野におけるdeep learningの歴史
2.一般画像認識:Deep learning 以前と以後で何が変わったか
◦ Bag-of-visual-words
◦ 畳み込みニューラルネット (CNN)
3.Deep learningの数理
◦ なぜ優れた性能が実現できるのか?
◦ ブレークスルーを生んだ要素技術
4.実践するにあたって
◦ 適切に利用するために必要な知識
◦ チューニングの勘所
5.最新の研究動向
84
79.
Nakayama Lab.
Machine PerceptionGroup
The University of Tokyo
より難しい画像認識タスクへ
◦ 物体検出
◦ セマンティック・セグメンテーション
◦ 画像・動画像の文章による説明
◦ 画像内容に対するQ&A
マルチモーダル学習
計画・行動へ
◦ 強化学習とのコラボレーション
弱点の理解・可視化
パターン生成
85
80.
Nakayama Lab.
Machine PerceptionGroup
The University of Tokyo
R-CNN [Girshick et al., CVPR’2014]
◦ 物体の領域候補を多数抽出(これ自体は別手法)
◦ 無理やり領域を正規化し、CNNで特徴抽出
◦ SVMで各領域を識別
86
R-CNNもCaffeと同じチームが開発・提供
(比較的簡単に試せます)
81.
Nakayama Lab.
Machine PerceptionGroup
The University of Tokyo
87
ランダムに選んだテスト画像の認識結果
(いいところだけ見せているのではない!)
Girshick et al., “Rich feature hierarchies for
accurate object detection and semantic
segmentation”, In arXiv, 2014.
82.
Nakayama Lab.
Machine PerceptionGroup
The University of Tokyo
基本構造はR-CNNと同じで、
CNN部分をGoogLeNetに置き換え
検出率(mAP、200クラス)
◦ ILSVRC 2013 winner: 22.6%
◦ R-CNN: 31.4%
◦ GoogLeNet: 43.9%
◦ Googleチームの続報(12月): 55.7%
88
Szegedy et al., “Scalable, High-Quality Object Detection”,
In arXiv, 2014.
83.
Nakayama Lab.
Machine PerceptionGroup
The University of Tokyo
Fully-connected CNN
◦ ピクセルレベルで物体領域を認識
◦ [Long et al., 2014]
Segmentation + Detection (同時最適化)
◦ [Hariharan et al., ECCV’14]
89
84.
Nakayama Lab.
Machine PerceptionGroup
The University of Tokyo
2014年11月、同時多発的にいろんなグループが発表
◦ arXivで公開 (CVPR 2015へ投稿)
◦ Recurrent Neural Network (RNN) が言語モデルとして大人気
Google
◦ O. Vinyals et al., “Show and Tell: A Neural Image Caption Generator”, 2014.
Microsoft
◦ H. Fang et al., “From Captions to Visual Concepts and Back”, 2014.
Stanford
◦ A. Karpathy and L. Fei-Fei, “Deep Visual-Semantic Alignments for Generating
Image Descriptions”, 2014.
UC Berkeley
◦ J. Donahue et al., “Long-term Recurrent Convolutional Networks for Visual
Recognition and Description”, 2014.
Univ. Toronto
◦ R. Kiros et al., “Unifying Visual-Semantic Embeddings with Multimodal Neural
Language Models”, 2014
90
85.
Nakayama Lab.
Machine PerceptionGroup
The University of Tokyo
Microsoft COCO [Lin et al., 2014] 30万枚~
SBU Captioned Photo Dataset [Ordonez et al., 2011] 100万枚
91
86.
Nakayama Lab.
Machine PerceptionGroup
The University of Tokyo
CNN (画像側)の出力をRNN(言語側)へ接続
◦ RNN側の誤差をCNN側までフィードバック
92
O. Vinyals et al., “Show and Tell: A Neural Image Caption Generator”, 2014
87.
Nakayama Lab.
Machine PerceptionGroup
The University of Tokyo
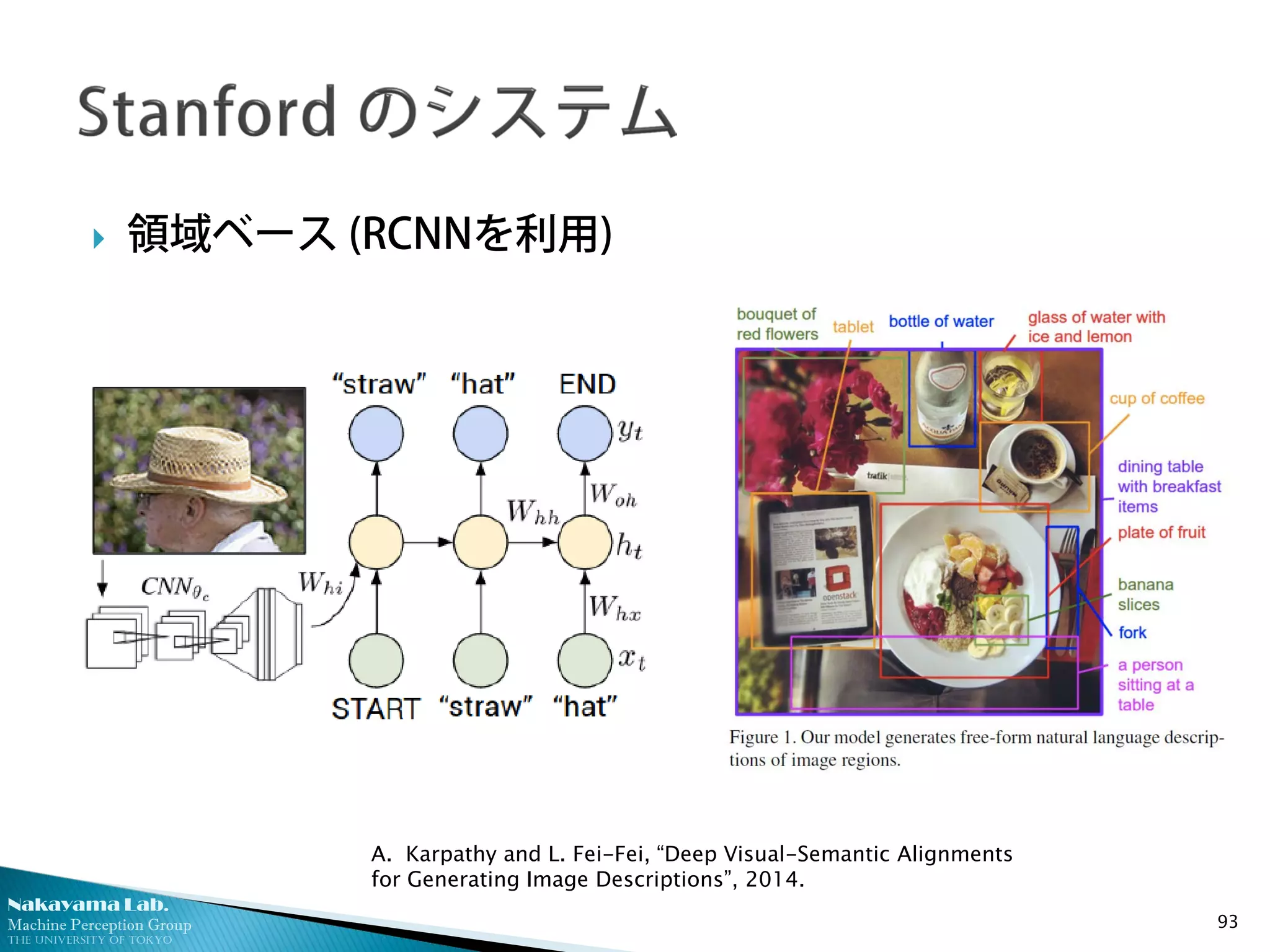
領域ベース (RCNNを利用)
93
A. Karpathy and L. Fei-Fei, “Deep Visual-Semantic Alignments
for Generating Image Descriptions”, 2014.
88.
Nakayama Lab.
Machine PerceptionGroup
The University of Tokyo
LSTMを用いた質問入力と回答の対応関係学習
94
H. Gao et al., “Are You Talking to a Machine? Dataset and Methods for
Multilingual Image Question Answering”, 2015.
M. Ren et al., “Image Question Answering:
A Visual Semantic Embedding Model and
a New Dataset”, 2015.
89.
Nakayama Lab.
Machine PerceptionGroup
The University of Tokyo
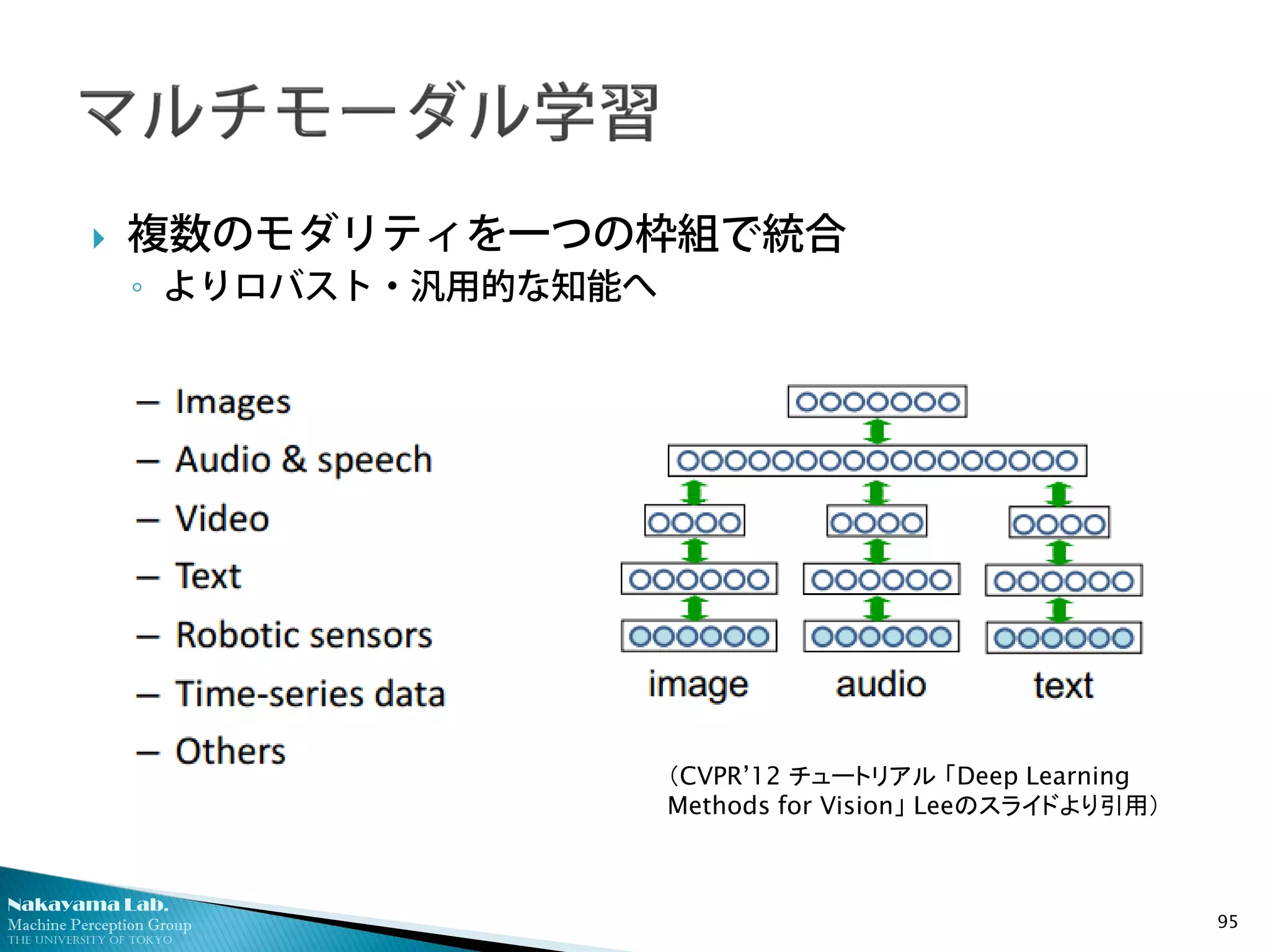
複数のモダリティを一つの枠組で統合
◦ よりロバスト・汎用的な知能へ
95
(CVPR’12 チュートリアル 「Deep Learning
Methods for Vision」 Leeのスライドより引用)
90.
Nakayama Lab.
Machine PerceptionGroup
The University of Tokyo
96
共通の上位レイヤ(潜在空間)へマッピング [Kiros et al., 2014]
◦ 異なるモダリティ間での“演算”が可能
R. Kiros et al., “Unifying Visual-Semantic Embeddings with
Multimodal Neural Language Models”, 2014
Nakayama Lab.
Machine PerceptionGroup
The University of Tokyo
Bimodal Deep Autoencoder [Ngiam et al., ICML’11]
◦ 音声 + 画像(唇)による発話音認識
◦ 音声側にノイズが大きい時にもロバスト
99
94.
Nakayama Lab.
Machine PerceptionGroup
The University of Tokyo
Deep Q-learning [Mnih et al, NIPS’13, Nature’15]
◦ DeepMind (Googleに買収されたベンチャー)の発表
◦ 強化学習の報酬系に畳み込みネットワークを接続(生画像を入力)
◦ アタリのクラッシックゲームで人間を超える腕前
100
95.
Nakayama Lab.
Machine PerceptionGroup
The University of Tokyo
人工的に生成した、各カテゴリに強い反応を示す画像の例
学習した知識の隙を突くことでたやすく騙せる?
101
Nguyen et al., “Deep Neural Networks are Easily Fooled: High Confidence
Predictions for Unrecognizable Images”, 2014.
≧ 99.6%
certainty
96.
Nakayama Lab.
Machine PerceptionGroup
The University of Tokyo
画像をわずかに変化させることで、CNNの認識結果を変化させる
ことができる
◦ ワーストケースの方向へ引っ張る
102
Goodfellow et al., “Explaining and harnessing adversarial examples”,
In Proc. of ICLR, 2015.
97.
Nakayama Lab.
Machine PerceptionGroup
The University of Tokyo
103
Szegedy et al., “Intriguing properties of neural networks”, 2014.
Correct “Ostrich”Perturbation Correct “Ostrich”Perturbation
98.
Nakayama Lab.
Machine PerceptionGroup
The University of Tokyo
生成モデルの構築にDNNを利用 [Kingma et al., NIPS’14]
104
クエリ 自動生成された画像
Kingma et al., “Semi-supervised Learning with
Deep Generative Models”, In Proc. of NIPS, 2014.
99.
Nakayama Lab.
Machine PerceptionGroup
The University of Tokyo
生成的CNNを使った補間画像生成 [Dosovitskiy et al., 2015]
105
モデル1 モデル2生成された補間画像
Dosovitskiy et al., “Learning to Generate Chairs with
Convolutional Neural Networks”, In arXiv, 2015.
100.
Nakayama Lab.
Machine PerceptionGroup
The University of Tokyo
画像認識分野で deep learning がもたらした変化
◦ Bag-of-words → CNN
◦ 一層ごとの基本的な構造は同じ
◦ “作りこみ”から”データ任せ”へ
Deep learning の本質
◦ 構造を深くすることにより、少ないパラメータで強い非線形変換を表現
できる
◦ 一層一層はできるだけシンプルにして、積み重ねるのが結局近道
実践方法
◦ フルスクラッチ vs fine-tuning & pre-trained feature
◦ 訓練誤差・予測誤差の挙動をみながら、
学習率に特に気を付けてチューニング
106
活
性
化
関
数
(
非
線
形
)
畳
み
込
み
(
線
形
)
プ
ー
リ
ン
グ
101.
Nakayama Lab.
Machine PerceptionGroup
The University of Tokyo
CNNの巨大化による性能向上・新タスク応用はまだ続きそう
◦ 入出力がきっちり定義されるタスクは基本的に得意
ただし学習データの有無がボトルネック
◦ 物体検出、動画像認識ではまだ発展途上(データが足りない?)
本質的には、依然としてCNNの構造に依存している
◦ 全結合ネットワークなどは今後成功するか?
◦ 真の意味でブラックボックスになるか?
より汎用的な人工知能へ近づくことはできるか?
◦ 深い意味構造の理解、記憶、思考、計画、創造…
107
Nakayama Lab.
Machine PerceptionGroup
The University of Tokyo
110
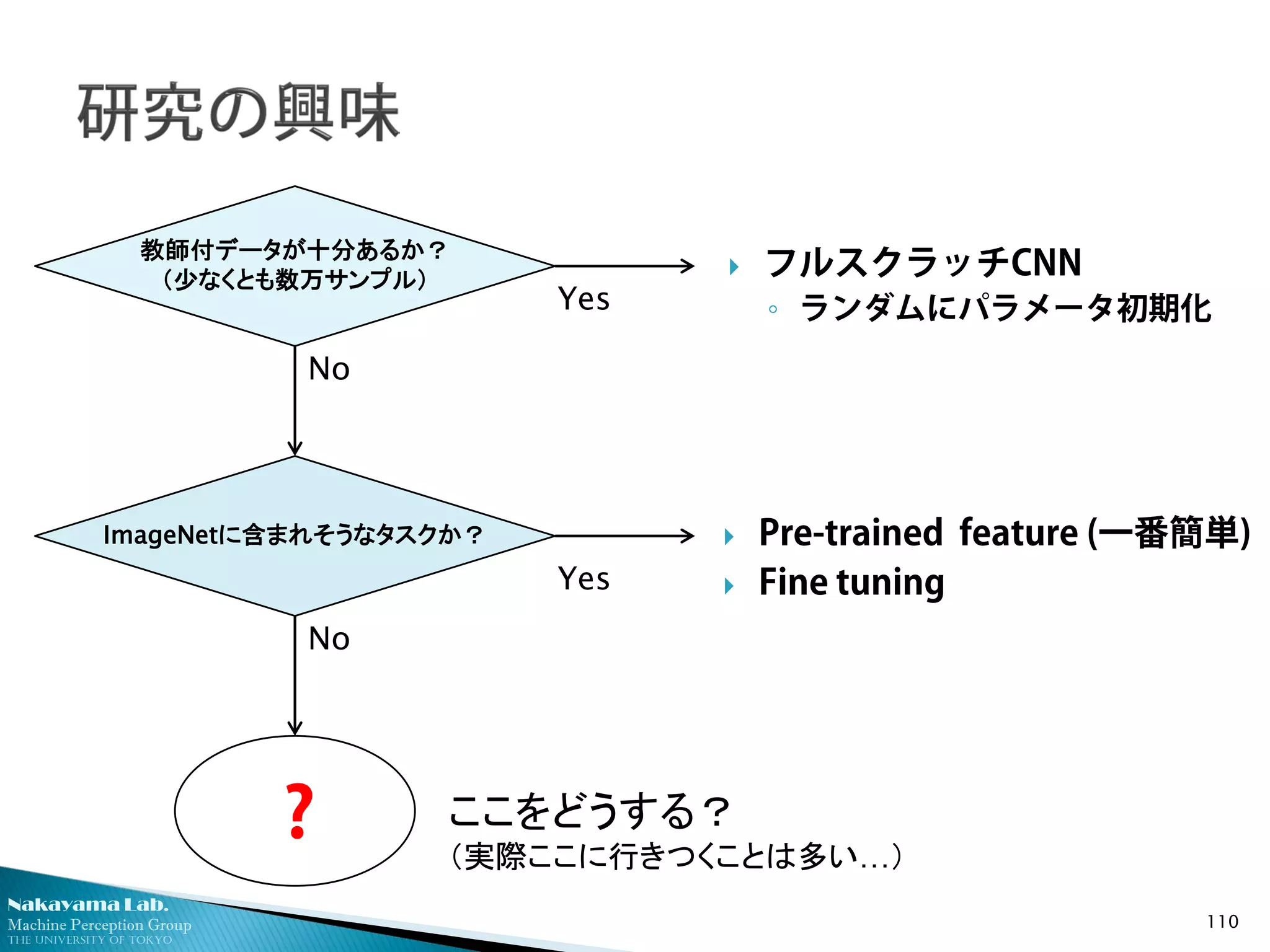
教師付データが十分あるか?
(少なくとも数万サンプル)
ImageNetに含まれそうなタスクか?
Yes
No
No
Yes
フルスクラッチCNN
◦ ランダムにパラメータ初期化
Pre-trained feature (一番簡単)
Fine tuning
? ここをどうする?
(実際ここに行きつくことは多い…)
105.
Nakayama Lab.
Machine PerceptionGroup
The University of Tokyo
限られた学習データからいかにして深い構造を得るか
◦ ディープラーニングの適用領域を大きく広げる可能性
◦ 一般的な学習アプローチでは困難(極めて不安定)
◦ できるだけ安定・高速に、“そこそこよい“ネットワークを
事前学習したい
解析的かつ識別的なlayer-wiseネットワーク構築
111
106.
Nakayama Lab.
Machine PerceptionGroup
The University of Tokyo
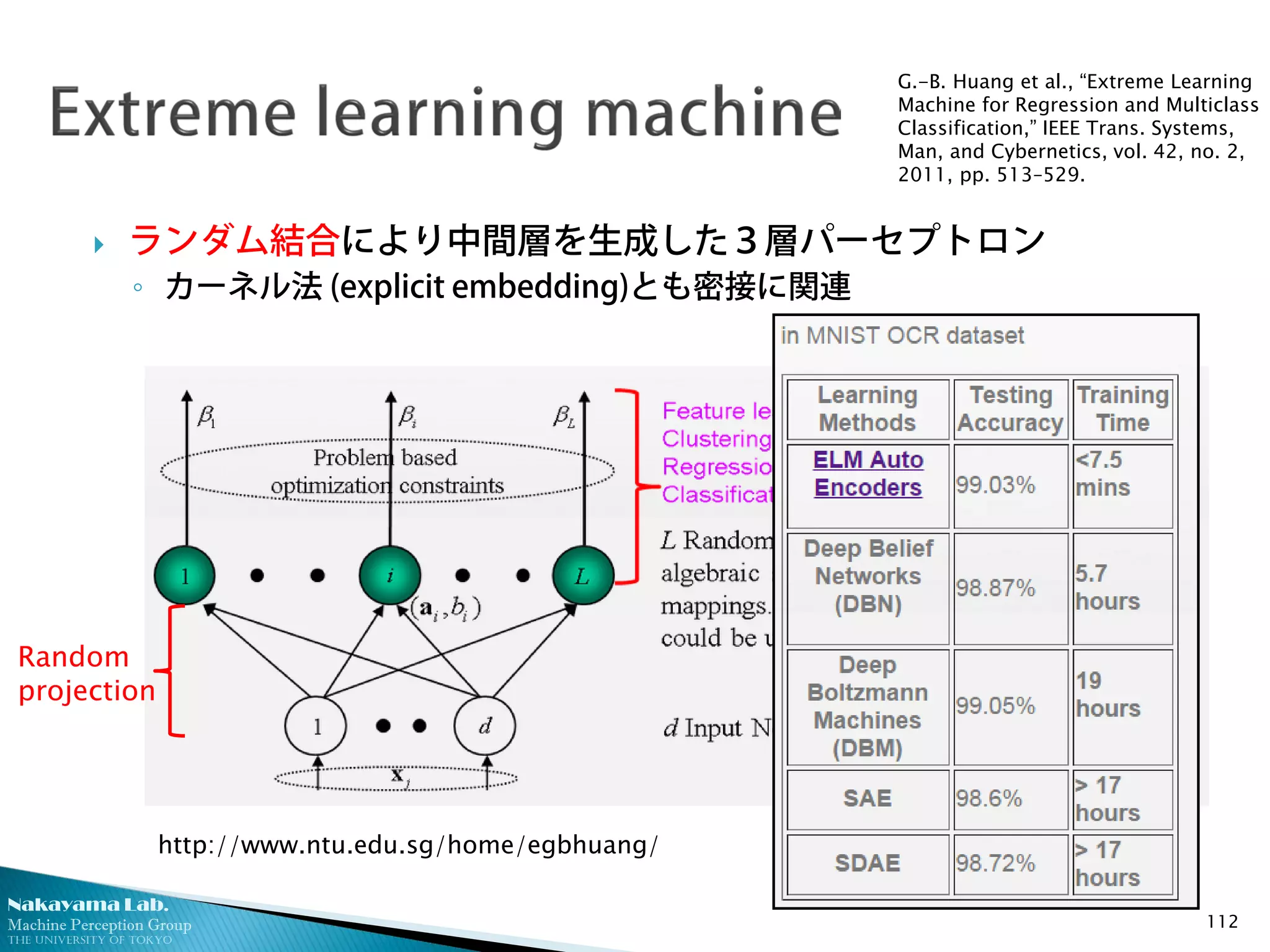
ランダム結合により中間層を生成した3層パーセプトロン
◦ カーネル法 (explicit embedding)とも密接に関連
112
http://www.ntu.edu.sg/home/egbhuang/
Random
projection
G.-B. Huang et al., “Extreme Learning
Machine for Regression and Multiclass
Classification,” IEEE Trans. Systems,
Man, and Cybernetics, vol. 42, no. 2,
2011, pp. 513–529.
Task-specific
analytical solution
107.
Nakayama Lab.
Machine PerceptionGroup
The University of Tokyo
113
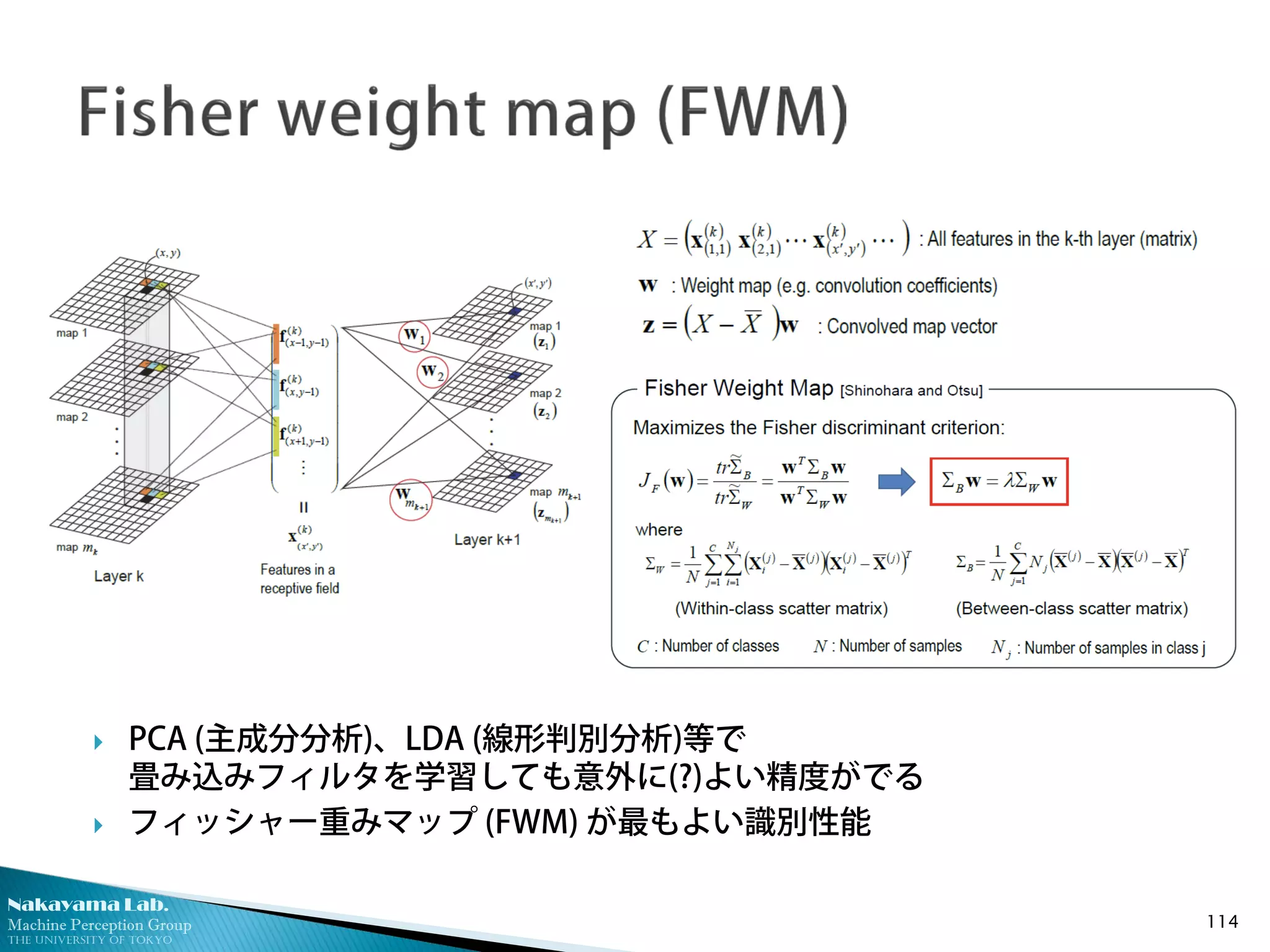
フィッシャー重みマップ
(空間構造の制約を
加えた線形判別分析)
識別的解析解を用いたlayer-wiseな
畳み込みニューラルネットワーク
[Nakayama, BMVC’13, SSII’14]
誤差逆伝播法を用いないアプローチ
先行研究に匹敵する性能
◦ 特に、学習データ少ない場合に
state-of-the-artを達成
108.
Nakayama Lab.
Machine PerceptionGroup
The University of Tokyo
114
PCA (主成分分析)、LDA (線形判別分析)等で
畳み込みフィルタを学習しても意外に(?)よい精度がでる
フィッシャー重みマップ (FWM) が最もよい識別性能
109.
Nakayama Lab.
Machine PerceptionGroup
The University of Tokyo
115
input
Random projection
or k-means filter
ReLU
Convolution with FWM
Average pooling
Convolution with FWM
Convolution with FWM
ReLU
ReLU
ReLU
Average pooling
Average pooling
(Global)
Average pooling
(Global)
Average pooling
(Global)
Output
Output
Output
Logistic
regression
Logistic
regression
Logistic
regression
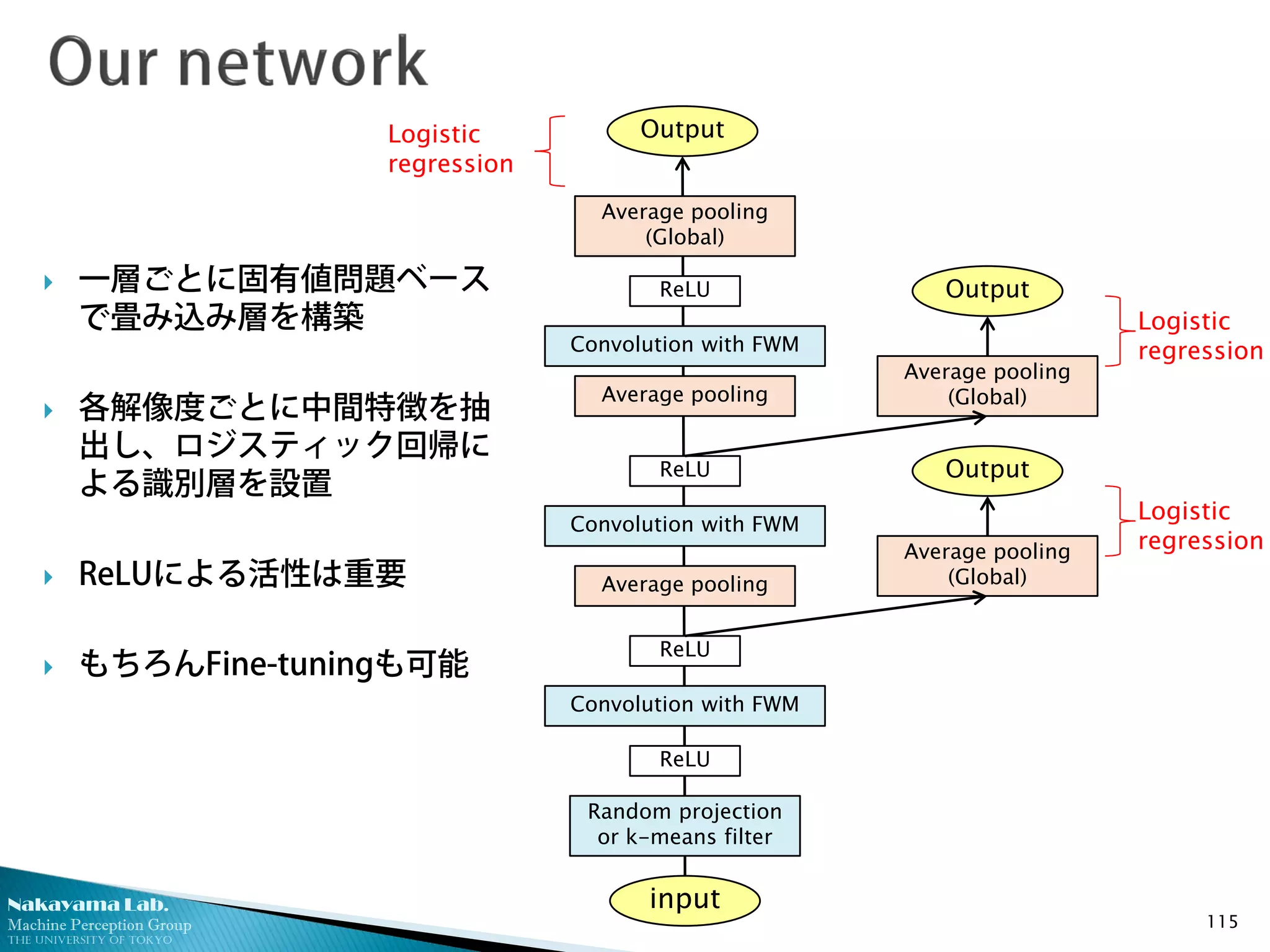
一層ごとに固有値問題ベース
で畳み込み層を構築
各解像度ごとに中間特徴を抽
出し、ロジスティック回帰に
よる識別層を設置
ReLUによる活性は重要
もちろんFine-tuningも可能
110.
Nakayama Lab.
Machine PerceptionGroup
The University of Tokyo
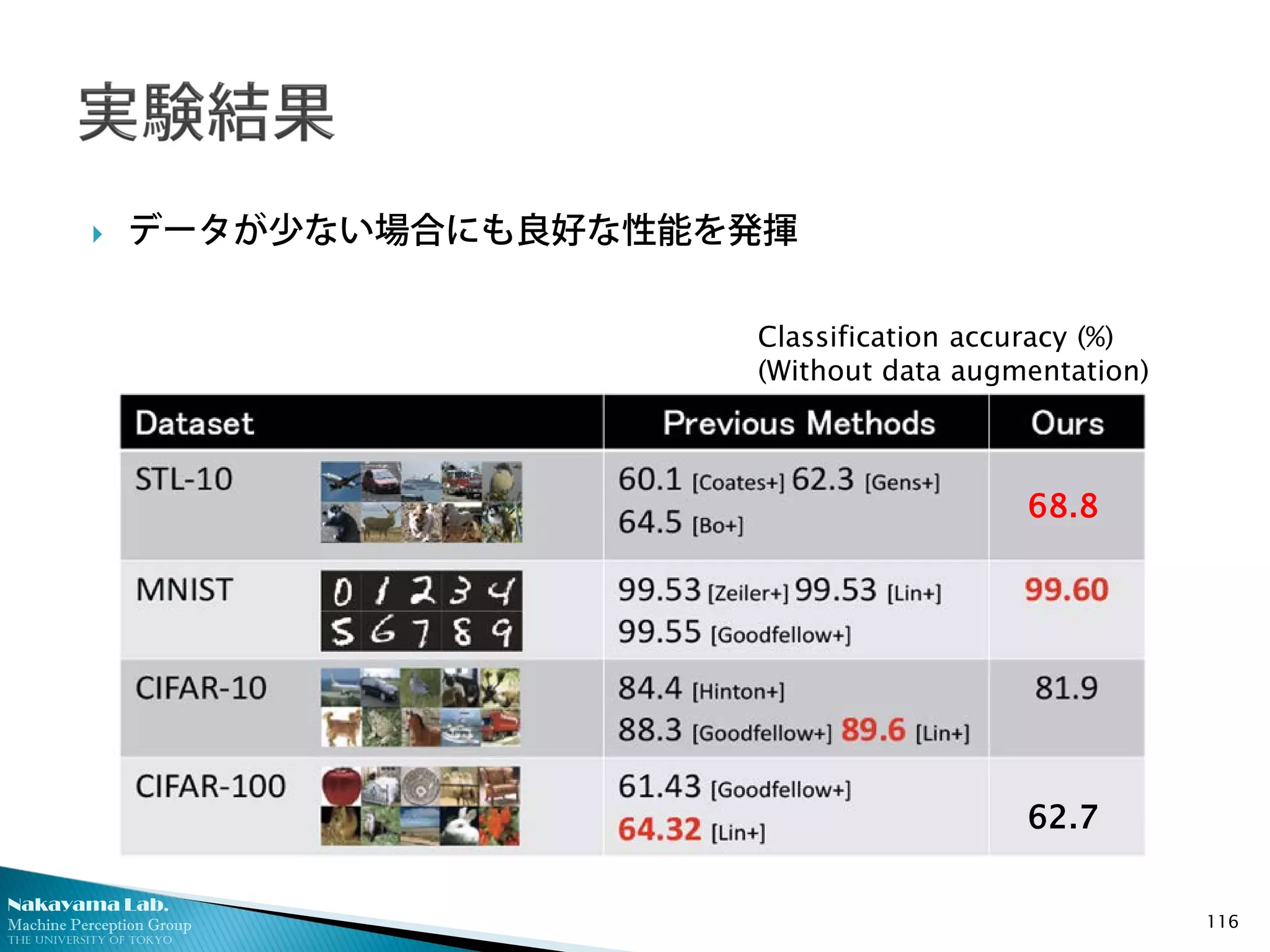
データが少ない場合にも良好な性能を発揮
116
62.7
68.8
Classification accuracy (%)
(Without data augmentation)
111.
Nakayama Lab.
Machine PerceptionGroup
The University of Tokyo
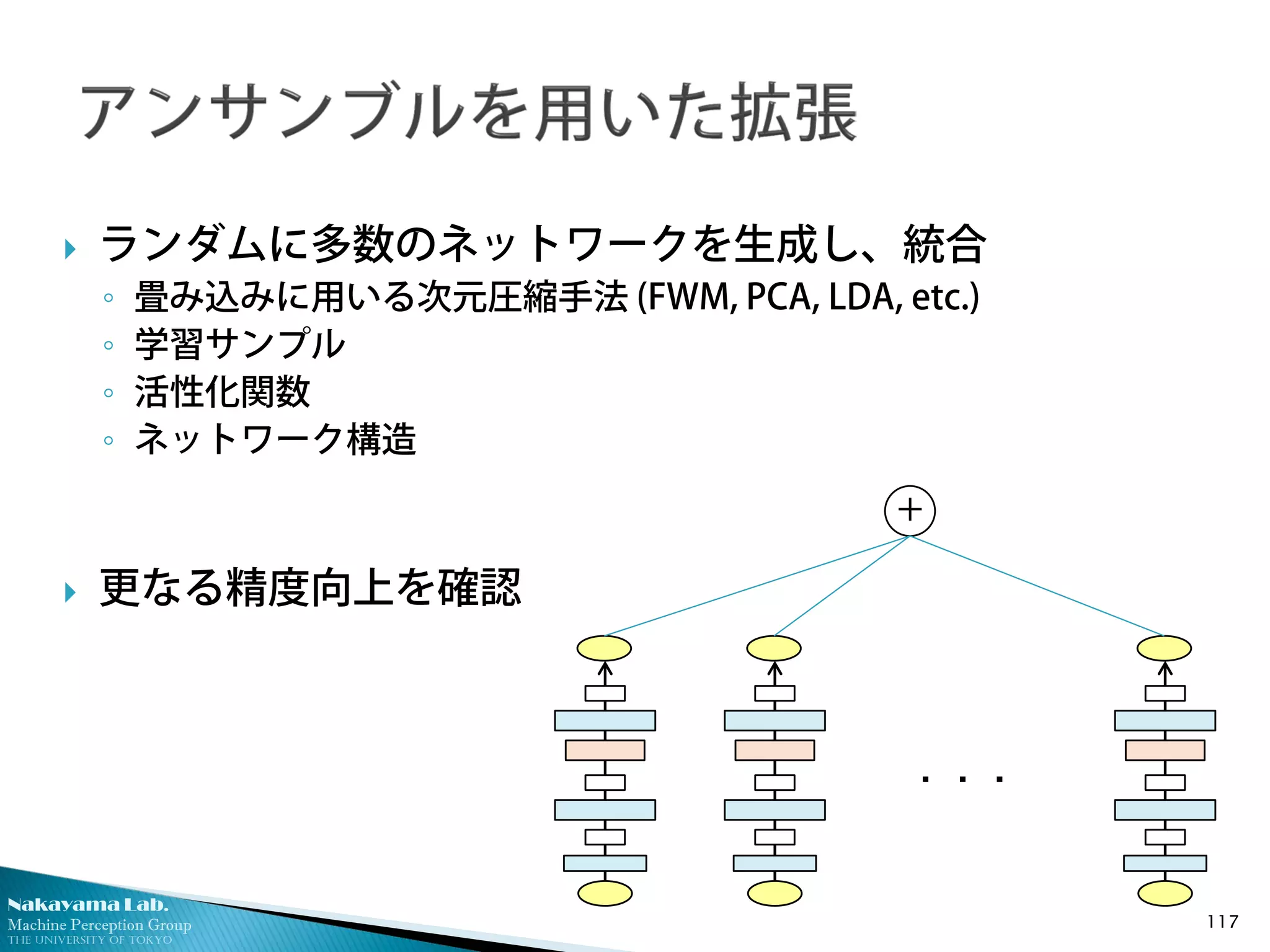
ランダムに多数のネットワークを生成し、統合
◦ 畳み込みに用いる次元圧縮手法 (FWM, PCA, LDA, etc.)
◦ 学習サンプル
◦ 活性化関数
◦ ネットワーク構造
更なる精度向上を確認
117
・ ・ ・
+
112.
Nakayama Lab.
Machine PerceptionGroup
The University of Tokyo
Random forest + deep learning
◦ 二分木の分割関数をELMによる
autoencoderを用いて多層化
[岩本, SSII’15]
Multimodal deep learning の高速化
◦ クロスモーダルの学習に
ELMと解析的アプローチを導入
118





![Nakayama Lab.
Machine Perception Group
The University of Tokyo
小さな画像を用いた基礎研究が主流
◦ MNISTデータセット [LeCun]
文字認識、28 x 28ピクセル、6万枚
◦ CIFAR-10/100 データセット [Krizhevsky]
物体認識、32 x 32ピクセル、5万枚
機械学習のコミュニティで地道に発達
◦ ビジョン系ではあまり受け入れられず…
11](https://image.slidesharecdn.com/ssiinakayamafinal-150609163610-lva1-app6891/75/Deep-Learning-11-2048.jpg)
![Nakayama Lab.
Machine Perception Group
The University of Tokyo
ある論文の冒頭 [Simard et al., ICDAR 2003]
“After being extremely popular in the early 1990s, neural
networks have fallen out of favor in research in the last 5
years. In 2000, it was even pointed out by the organizers of
the Neural Information Processing System (NIPS) conference
that the term “neural networks” in the submission title
was negatively correlated with acceptance. In contrast,
positive correlations were made with support vector machines
(SVMs), Bayesian networks, and variational methods.”
12](https://image.slidesharecdn.com/ssiinakayamafinal-150609163610-lva1-app6891/75/Deep-Learning-12-2048.jpg)
![Nakayama Lab.
Machine Perception Group
The University of Tokyo
ImageNetのデータの一部を用いたフラッグシップコンペティ
ション (2010年より開催)
◦ ImageNet [Deng et al., 2009]
クラウドソーシングにより構築中の大規模画像データセット
1400万枚、2万2千カテゴリ(WordNetに従って構築)
コンペでのタスク
◦ 1000クラスの物体カテゴリ分類
学習データ120万枚、検証用データ5万枚、テストデータ10万枚
◦ 200クラスの物体検出
学習データ45万枚、検証用データ2万枚、テストデータ4万枚
13
Russakovsky et al., “ImageNet Large Scale Visual
Recognition Challenge”, 2014.](https://image.slidesharecdn.com/ssiinakayamafinal-150609163610-lva1-app6891/75/Deep-Learning-13-2048.jpg)
![Nakayama Lab.
Machine Perception Group
The University of Tokyo
1000クラス識別タスクで、deep learning を用いたシステムが圧勝
◦ トロント大学Hinton先生のチーム (AlexNet)
14
[A. Krizhevsky et al., NIPS’12]
エラー率が一気に10%以上減少!
(※過去数年間での向上は1~2%)](https://image.slidesharecdn.com/ssiinakayamafinal-150609163610-lva1-app6891/75/Deep-Learning-14-2048.jpg)
![Nakayama Lab.
Machine Perception Group
The University of Tokyo
映像 認識
◦ 487クラスの
スポーツカテゴリ認識
[Karpathy., CVPR’14]
RGB-D物体認識
◦ [Socher et la., NIPS’13]
17](https://image.slidesharecdn.com/ssiinakayamafinal-150609163610-lva1-app6891/75/Deep-Learning-17-2048.jpg)
![Nakayama Lab.
Machine Perception Group
The University of Tokyo
領域分割 (シーンラベリング)
◦ ピクセルレベルで物体領域を認識
◦ [Long et al., 2014]
RGB-Dシーンラベリング
◦ [Wang et al., ECCV’14]
18](https://image.slidesharecdn.com/ssiinakayamafinal-150609163610-lva1-app6891/75/Deep-Learning-18-2048.jpg)
![Nakayama Lab.
Machine Perception Group
The University of Tokyo
デノイジング・インペインティング [Xie et al., NIPS’12]
◦ 画像のノイズ除去
◦ Stacked denoising auto-encoder
超解像 [Dong et al., ECCV’14]
◦ 低解像度画像から
高解像度画像を復元(推定)
ボケ補正 [Xu et al., NIPS’14]
19](https://image.slidesharecdn.com/ssiinakayamafinal-150609163610-lva1-app6891/75/Deep-Learning-19-2048.jpg)

![Nakayama Lab.
Machine Perception Group
The University of Tokyo
22
Low-level
image feature
Mid-level
image feature “Car”
SIFT, HOG,
SURF, etc.
BoVW, VLAD,
Fisher Vector, etc.
Supervised Classifier:
SVM, Logistic
Regression, etc.
生の画素値から、識別に至る階層構造を直接的に学習
従来の特徴量に相当する構造が中間層に自然に出現
伝統的
方法論
(“Shallow”
learning)
Deep
learning “Car”・・・
人手で設計 人手で設計/教師なし学習
[Zeiler and Fergus, 2013]](https://image.slidesharecdn.com/ssiinakayamafinal-150609163610-lva1-app6891/75/Deep-Learning-22-2048.jpg)
![Nakayama Lab.
Machine Perception Group
The University of Tokyo
つまり…
◦ 最近傍のvisual wordに対応するコードに対してのみ1を、
それ以外に0を埋める最も単純な局所特徴エンコーディング
◦ 平均値プーリング
25
0
0
0
0
1
0
0
1
0
0
0
1
0
0
0
…
M次元
(visual wordsの数)
3.0
9.0
1.0
5.0
2.0
画像中の全局所特徴
平均ベクトル
[Wang et al., CVPR’10]](https://image.slidesharecdn.com/ssiinakayamafinal-150609163610-lva1-app6891/75/Deep-Learning-25-2048.jpg)
![Nakayama Lab.
Machine Perception Group
The University of Tokyo
畳み込みニューラルネットワーク (CNN)
◦ 脳の視覚野の構造を模倣した多層パーセプトロン
◦ ニューロン間の結合を局所に限定(パラメータ数の大幅な削減)
最初に基本構造が提案されたのは実はかなり昔
◦ ネオコグニトロン (福島邦彦先生、1980年代前後)
26
[A. Krizhevsky et al., NIPS’12]
Kunihiko Fukushima, “Neocognitron: A Self-organizing Neural
Network Model for a Mechanism of Pattern Recognition
Unaffected by Shift in Position“, Biological Cybernetics, 36(4):
93-202, 1980.](https://image.slidesharecdn.com/ssiinakayamafinal-150609163610-lva1-app6891/75/Deep-Learning-26-2048.jpg)




![Nakayama Lab.
Machine Perception Group
The University of Tokyo
ある一定の表現能力を得ようとした場合に…
深いモデルの方が必要なパラメータ数が少なくて済むと考
えられている [Larochelle et al., 2007] [Bengio, 2009] [Delalleau and Bengio, 2011]
(※単純なケース以外では完全に証明されていない)
43
(ちゃんと学習
できれば) 汎化性能
計算効率
スケーラビリティ
反論もある:
“Do Deep Nets Really
Need to be Deep?”
[Ba & Caruana, 2014]](https://image.slidesharecdn.com/ssiinakayamafinal-150609163610-lva1-app6891/75/Deep-Learning-37-2048.jpg)
![Nakayama Lab.
Machine Perception Group
The University of Tokyo
Sum-product network [Poon and Domingos, UAI’11]
◦ 各ノード(ニューロン)が入力の和か積を出力するネットワーク
同じ多項式関数を表現するために必要なノード数の増加が
◦ 浅いネットワークでは指数的
◦ 深いネットワークでは線形
44
[Delalleau & Bengio, NIPS’11]](https://image.slidesharecdn.com/ssiinakayamafinal-150609163610-lva1-app6891/75/Deep-Learning-38-2048.jpg)




![Nakayama Lab.
Machine Perception Group
The University of Tokyo
53
シグモイド関数
( )x,0max
( )x−+ exp1
1
サチると勾配が
出ない!
Rectified linear units (ReLU)
[Nair & Hinton, 2010]
( ) ( ) ioldi
T
oldiioldnew fyy xxwww θη −′−+= ˆ
(プラスなら)どこでも
一定の勾配
例)単純パーセプトロン
の更新式](https://image.slidesharecdn.com/ssiinakayamafinal-150609163610-lva1-app6891/75/Deep-Learning-47-2048.jpg)

![Nakayama Lab.
Machine Perception Group
The University of Tokyo
各訓練データ(バッチ)のフィードバックの際に、
一定確率(0.5)で中間ニューロンを無視
認識時は全ニューロンを使うが、結合重みを半分にする
多数のネットワークを混ぜた構造
◦ 訓練データが各ニューロンで異なるため、
バギングと同様の効果
(ただしパラメータは共有)
L2正規化に近い効果
◦ [Wager et al., NIPS’13]
以前と比較して大幅な精度向上
◦ ほぼ必須のテクニック
56
L∇ ( )iiL yx ,](https://image.slidesharecdn.com/ssiinakayamafinal-150609163610-lva1-app6891/75/Deep-Learning-50-2048.jpg)
![Nakayama Lab.
Machine Perception Group
The University of Tokyo
Drop connect [Wan et al., ICML’13]
◦ ニューロンではなく、結合をランダムに落とす
Adaptive dropout [Ba et al., NIPS’13]
◦ Dropoutで落とすニューロンをランダムでなく適応的に選択する
57](https://image.slidesharecdn.com/ssiinakayamafinal-150609163610-lva1-app6891/75/Deep-Learning-51-2048.jpg)










![Nakayama Lab.
Machine Perception Group
The University of Tokyo
ネットワークの初期値をランダムに与える
誤差逆伝播法でパラメータ更新
◦ 適当な大きさのミニバッチでフィードフォワード・フィード
バックを繰り返す(100枚単位など)
◦ データをあらかじめシャッフルしておくこと
72
L∇
ミニバッチ
X Yˆ
Source: [Smirnov et al., 2014]
$ build/tools/convert_imageset --backend leveldb --shuffle 101_ObjectCategories/ ・・・](https://image.slidesharecdn.com/ssiinakayamafinal-150609163610-lva1-app6891/75/Deep-Learning-66-2048.jpg)
![Nakayama Lab.
Machine Perception Group
The University of Tokyo
I1120 11:27:09.007803 537 solver.cpp:160] Solving CaffeNet
I1120 11:27:09.007859 537 solver.cpp:247] Iteration 0, Testing net (#0)
I1120 11:27:17.979998 537 solver.cpp:298] Test net output #0: accuracy = 0.0048
I1120 11:27:17.980051 537 solver.cpp:298] Test net output #1: loss = 5.01857 (* 1 = 5.01857 loss)
I1120 11:27:18.068891 537 solver.cpp:191] Iteration 0, loss = 5.38866
I1120 11:27:18.068940 537 solver.cpp:206] Train net output #0: loss = 5.38866 (* 1 = 5.38866 loss)
I1120 11:27:18.068958 537 solver.cpp:403] Iteration 0, lr = 0.001
I1120 11:27:19.620609 537 solver.cpp:247] Iteration 10, Testing net (#0)
I1120 11:27:28.556694 537 solver.cpp:298] Test net output #0: accuracy = 0.1096
I1120 11:27:28.556756 537 solver.cpp:298] Test net output #1: loss = 4.34054 (* 1 = 4.34054 loss)
I1120 11:27:28.634579 537 solver.cpp:191] Iteration 10, loss = 5.02612
I1120 11:27:28.634629 537 solver.cpp:206] Train net output #0: loss = 5.02612 (* 1 = 5.02612 loss)
I1120 11:27:28.634642 537 solver.cpp:403] Iteration 10, lr = 0.001
I1120 11:27:30.183964 537 solver.cpp:247] Iteration 20, Testing net (#0)
I1120 11:27:39.118187 537 solver.cpp:298] Test net output #0: accuracy = 0.2762
I1120 11:27:39.118242 537 solver.cpp:298] Test net output #1: loss = 3.7547 (* 1 = 3.7547 loss)
I1120 11:27:39.196316 537 solver.cpp:191] Iteration 20, loss = 3.64996
I1120 11:27:39.196364 537 solver.cpp:206] Train net output #0: loss = 3.64996 (* 1 = 3.64996 loss)
I1120 11:27:39.196377 537 solver.cpp:403] Iteration 20, lr = 0.001
I1120 11:27:40.746333 537 solver.cpp:247] Iteration 30, Testing net (#0)
I1120 11:27:49.677788 537 solver.cpp:298] Test net output #0: accuracy = 0.4078
I1120 11:27:49.677836 537 solver.cpp:298] Test net output #1: loss = 2.97932 (* 1 = 2.97932 loss)
I1120 11:27:49.755615 537 solver.cpp:191] Iteration 30, loss = 3.5529
I1120 11:27:49.755662 537 solver.cpp:206] Train net output #0: loss = 3.5529 (* 1 = 3.5529 loss)
I1120 11:27:49.755676 537 solver.cpp:403] Iteration 30, lr = 0.001
I1120 11:27:51.304983 537 solver.cpp:247] Iteration 40, Testing net (#0)
I1120 11:28:00.235947 537 solver.cpp:298] Test net output #0: accuracy = 0.5382
I1120 11:28:00.236030 537 solver.cpp:298] Test net output #1: loss = 2.32026 (* 1 = 2.32026 loss)
I1120 11:28:00.313851 537 solver.cpp:191] Iteration 40, loss = 2.67447
I1120 11:28:00.313899 537 solver.cpp:206] Train net output #0: loss = 2.67447 (* 1 = 2.67447 loss)
)
75
予測誤差
訓練誤差](https://image.slidesharecdn.com/ssiinakayamafinal-150609163610-lva1-app6891/75/Deep-Learning-69-2048.jpg)


![Nakayama Lab.
Machine Perception Group
The University of Tokyo
データの前処理 (かなり重要)
◦ ZCA whitening (白色化)
コントラスト正規化など
◦ 最終的な識別性能に大きく影響する
Data augmentation
◦ アフィン変換、クロップなど、人工的に
さまざまな変換を学習データに加える
◦ 平行移動以外の不変性を学習させる
◦ GoogLeNetでは144倍にデータ拡張
83
[Zeiler and Fergus, 2013]
[Dosovitskiy et al., 2014]](https://image.slidesharecdn.com/ssiinakayamafinal-150609163610-lva1-app6891/75/Deep-Learning-77-2048.jpg)


![Nakayama Lab.
Machine Perception Group
The University of Tokyo
R-CNN [Girshick et al., CVPR’2014]
◦ 物体の領域候補を多数抽出(これ自体は別手法)
◦ 無理やり領域を正規化し、CNNで特徴抽出
◦ SVMで各領域を識別
86
R-CNNもCaffeと同じチームが開発・提供
(比較的簡単に試せます)](https://image.slidesharecdn.com/ssiinakayamafinal-150609163610-lva1-app6891/75/Deep-Learning-80-2048.jpg)


![Nakayama Lab.
Machine Perception Group
The University of Tokyo
Fully-connected CNN
◦ ピクセルレベルで物体領域を認識
◦ [Long et al., 2014]
Segmentation + Detection (同時最適化)
◦ [Hariharan et al., ECCV’14]
89](https://image.slidesharecdn.com/ssiinakayamafinal-150609163610-lva1-app6891/75/Deep-Learning-83-2048.jpg)

![Nakayama Lab.
Machine Perception Group
The University of Tokyo
Microsoft COCO [Lin et al., 2014] 30万枚~
SBU Captioned Photo Dataset [Ordonez et al., 2011] 100万枚
91](https://image.slidesharecdn.com/ssiinakayamafinal-150609163610-lva1-app6891/75/Deep-Learning-85-2048.jpg)


![Nakayama Lab.
Machine Perception Group
The University of Tokyo
96
共通の上位レイヤ(潜在空間)へマッピング [Kiros et al., 2014]
◦ 異なるモダリティ間での“演算”が可能
R. Kiros et al., “Unifying Visual-Semantic Embeddings with
Multimodal Neural Language Models”, 2014](https://image.slidesharecdn.com/ssiinakayamafinal-150609163610-lva1-app6891/75/Deep-Learning-90-2048.jpg)
![Nakayama Lab.
Machine Perception Group
The University of Tokyo
97
[Kiros et al., 2014]](https://image.slidesharecdn.com/ssiinakayamafinal-150609163610-lva1-app6891/75/Deep-Learning-91-2048.jpg)
![Nakayama Lab.
Machine Perception Group
The University of Tokyo
98
[Kiros et al., 2014]](https://image.slidesharecdn.com/ssiinakayamafinal-150609163610-lva1-app6891/75/Deep-Learning-92-2048.jpg)
![Nakayama Lab.
Machine Perception Group
The University of Tokyo
Bimodal Deep Autoencoder [Ngiam et al., ICML’11]
◦ 音声 + 画像(唇)による発話音認識
◦ 音声側にノイズが大きい時にもロバスト
99](https://image.slidesharecdn.com/ssiinakayamafinal-150609163610-lva1-app6891/75/Deep-Learning-93-2048.jpg)
![Nakayama Lab.
Machine Perception Group
The University of Tokyo
Deep Q-learning [Mnih et al, NIPS’13, Nature’15]
◦ DeepMind (Googleに買収されたベンチャー)の発表
◦ 強化学習の報酬系に畳み込みネットワークを接続(生画像を入力)
◦ アタリのクラッシックゲームで人間を超える腕前
100](https://image.slidesharecdn.com/ssiinakayamafinal-150609163610-lva1-app6891/75/Deep-Learning-94-2048.jpg)



![Nakayama Lab.
Machine Perception Group
The University of Tokyo
生成モデルの構築にDNNを利用 [Kingma et al., NIPS’14]
104
クエリ 自動生成された画像
Kingma et al., “Semi-supervised Learning with
Deep Generative Models”, In Proc. of NIPS, 2014.](https://image.slidesharecdn.com/ssiinakayamafinal-150609163610-lva1-app6891/75/Deep-Learning-98-2048.jpg)
![Nakayama Lab.
Machine Perception Group
The University of Tokyo
生成的CNNを使った補間画像生成 [Dosovitskiy et al., 2015]
105
モデル1 モデル2生成された補間画像
Dosovitskiy et al., “Learning to Generate Chairs with
Convolutional Neural Networks”, In arXiv, 2015.](https://image.slidesharecdn.com/ssiinakayamafinal-150609163610-lva1-app6891/75/Deep-Learning-99-2048.jpg)





![Nakayama Lab.
Machine Perception Group
The University of Tokyo
113
フィッシャー重みマップ
(空間構造の制約を
加えた線形判別分析)
識別的解析解を用いたlayer-wiseな
畳み込みニューラルネットワーク
[Nakayama, BMVC’13, SSII’14]
誤差逆伝播法を用いないアプローチ
先行研究に匹敵する性能
◦ 特に、学習データ少ない場合に
state-of-the-artを達成](https://image.slidesharecdn.com/ssiinakayamafinal-150609163610-lva1-app6891/75/Deep-Learning-107-2048.jpg)
![Nakayama Lab.
Machine Perception Group
The University of Tokyo
Random forest + deep learning
◦ 二分木の分割関数をELMによる
autoencoderを用いて多層化
[岩本, SSII’15]
Multimodal deep learning の高速化
◦ クロスモーダルの学習に
ELMと解析的アプローチを導入
118](https://image.slidesharecdn.com/ssiinakayamafinal-150609163610-lva1-app6891/75/Deep-Learning-112-2048.jpg)

![[DL輪読会]MetaFormer is Actually What You Need for Vision](https://cdn.slidesharecdn.com/ss_thumbnails/20220121metaformer-220121085750-thumbnail.jpg?width=640&height=640&fit=bounds)






![SSII2021 [SS1] Transformer x Computer Visionの 実活用可能性と展望 〜 TransformerのCompute...](https://cdn.slidesharecdn.com/ss_thumbnails/ss1-01-210607043349-thumbnail.jpg?width=640&height=640&fit=bounds)






![[DL輪読会]Graph R-CNN for Scene Graph Generation](https://cdn.slidesharecdn.com/ss_thumbnails/graphr-cnnforscenegraphgenerationkobayashi1130-181130001547-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis](https://cdn.slidesharecdn.com/ss_thumbnails/nerfdlseminar1-200327021512-thumbnail.jpg?width=640&height=640&fit=bounds)

![[解説スライド] NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis](https://cdn.slidesharecdn.com/ss_thumbnails/nerf20200327slideshare-200326131430-thumbnail.jpg?width=640&height=640&fit=bounds)
![SSII2022 [SS2] 少ないデータやラベルを効率的に活用する機械学習技術 〜 足りない情報をどのように補うか?〜](https://cdn.slidesharecdn.com/ss_thumbnails/ss2ssii2022-220607054716-2760bd30-thumbnail.jpg?width=640&height=640&fit=bounds)










![[DL輪読会]A Bayesian Perspective on Generalization and Stochastic Gradient Descent](https://cdn.slidesharecdn.com/ss_thumbnails/20171106dl2-171108033614-thumbnail.jpg?width=640&height=640&fit=bounds)













































