Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
Submit search
EN
Uploaded by
Deep Learning JP
PPTX, PDF
2,448 views
【DL輪読会】Llama 2: Open Foundation and Fine-Tuned Chat Models
2023/7/20 Deep Learning JP http://deeplearning.jp/seminar-2/
Technology
◦
Read more
1
Save
Share
Embed
Embed presentation
Download
Downloaded 78 times
1
/ 38
2
/ 38
3
/ 38
4
/ 38
5
/ 38
6
/ 38
7
/ 38
8
/ 38
9
/ 38
10
/ 38
11
/ 38
12
/ 38
13
/ 38
14
/ 38
15
/ 38
16
/ 38
17
/ 38
18
/ 38
19
/ 38
20
/ 38
21
/ 38
22
/ 38
23
/ 38
24
/ 38
25
/ 38
26
/ 38
27
/ 38
28
/ 38
29
/ 38
30
/ 38
31
/ 38
32
/ 38
33
/ 38
34
/ 38
35
/ 38
36
/ 38
37
/ 38
38
/ 38
More Related Content
PPTX
【DL輪読会】Toolformer: Language Models Can Teach Themselves to Use Tools
by
Deep Learning JP
PDF
【DL輪読会】GPT-4Technical Report
by
Deep Learning JP
PPTX
【DL輪読会】Flamingo: a Visual Language Model for Few-Shot Learning 画像×言語の大規模基盤モ...
by
Deep Learning JP
PPTX
【DL輪読会】Hyena Hierarchy: Towards Larger Convolutional Language Models
by
Deep Learning JP
PPTX
【DL輪読会】Visual Classification via Description from Large Language Models (ICLR...
by
Deep Learning JP
PPTX
【DL輪読会】Hopfield network 関連研究について
by
Deep Learning JP
PDF
【DL輪読会】Visual ChatGPT: Talking, Drawing and Editing with Visual Foundation Mo...
by
Deep Learning JP
PPTX
【DL輪読会】マルチモーダル 基盤モデル
by
Deep Learning JP
【DL輪読会】Toolformer: Language Models Can Teach Themselves to Use Tools
by
Deep Learning JP
【DL輪読会】GPT-4Technical Report
by
Deep Learning JP
【DL輪読会】Flamingo: a Visual Language Model for Few-Shot Learning 画像×言語の大規模基盤モ...
by
Deep Learning JP
【DL輪読会】Hyena Hierarchy: Towards Larger Convolutional Language Models
by
Deep Learning JP
【DL輪読会】Visual Classification via Description from Large Language Models (ICLR...
by
Deep Learning JP
【DL輪読会】Hopfield network 関連研究について
by
Deep Learning JP
【DL輪読会】Visual ChatGPT: Talking, Drawing and Editing with Visual Foundation Mo...
by
Deep Learning JP
【DL輪読会】マルチモーダル 基盤モデル
by
Deep Learning JP
What's hot
PPTX
【DL輪読会】Efficiently Modeling Long Sequences with Structured State Spaces
by
Deep Learning JP
PPTX
[DL輪読会]Set Transformer: A Framework for Attention-based Permutation-Invariant...
by
Deep Learning JP
PDF
最近のKaggleに学ぶテーブルデータの特徴量エンジニアリング
by
mlm_kansai
PPTX
【DL輪読会】言語以外でのTransformerのまとめ (ViT, Perceiver, Frozen Pretrained Transformer etc)
by
Deep Learning JP
PPTX
【DL輪読会】ViT + Self Supervised Learningまとめ
by
Deep Learning JP
PPTX
Semi supervised, weakly-supervised, unsupervised, and active learning
by
Yusuke Uchida
PPTX
【DL輪読会】A Time Series is Worth 64 Words: Long-term Forecasting with Transformers
by
Deep Learning JP
PDF
【メタサーベイ】基盤モデル / Foundation Models
by
cvpaper. challenge
PPTX
Graph Neural Networks
by
tm1966
PPTX
強化学習における好奇心
by
Shota Imai
PPTX
近年のHierarchical Vision Transformer
by
Yusuke Uchida
PDF
【DL輪読会】DINOv2: Learning Robust Visual Features without Supervision
by
Deep Learning JP
PDF
最近のDeep Learning (NLP) 界隈におけるAttention事情
by
Yuta Kikuchi
PPTX
Curriculum Learning (関東CV勉強会)
by
Yoshitaka Ushiku
PPTX
[DL輪読会]Learning Latent Dynamics for Planning from Pixels
by
Deep Learning JP
PPTX
Swin Transformer (ICCV'21 Best Paper) を完璧に理解する資料
by
Yusuke Uchida
PDF
機械学習モデルの判断根拠の説明(Ver.2)
by
Satoshi Hara
PDF
[DL輪読会]data2vec: A General Framework for Self-supervised Learning in Speech,...
by
Deep Learning JP
PDF
[DL輪読会]Temporal Abstraction in NeurIPS2019
by
Deep Learning JP
PDF
Active Learning 入門
by
Shuyo Nakatani
【DL輪読会】Efficiently Modeling Long Sequences with Structured State Spaces
by
Deep Learning JP
[DL輪読会]Set Transformer: A Framework for Attention-based Permutation-Invariant...
by
Deep Learning JP
最近のKaggleに学ぶテーブルデータの特徴量エンジニアリング
by
mlm_kansai
【DL輪読会】言語以外でのTransformerのまとめ (ViT, Perceiver, Frozen Pretrained Transformer etc)
by
Deep Learning JP
【DL輪読会】ViT + Self Supervised Learningまとめ
by
Deep Learning JP
Semi supervised, weakly-supervised, unsupervised, and active learning
by
Yusuke Uchida
【DL輪読会】A Time Series is Worth 64 Words: Long-term Forecasting with Transformers
by
Deep Learning JP
【メタサーベイ】基盤モデル / Foundation Models
by
cvpaper. challenge
Graph Neural Networks
by
tm1966
強化学習における好奇心
by
Shota Imai
近年のHierarchical Vision Transformer
by
Yusuke Uchida
【DL輪読会】DINOv2: Learning Robust Visual Features without Supervision
by
Deep Learning JP
最近のDeep Learning (NLP) 界隈におけるAttention事情
by
Yuta Kikuchi
Curriculum Learning (関東CV勉強会)
by
Yoshitaka Ushiku
[DL輪読会]Learning Latent Dynamics for Planning from Pixels
by
Deep Learning JP
Swin Transformer (ICCV'21 Best Paper) を完璧に理解する資料
by
Yusuke Uchida
機械学習モデルの判断根拠の説明(Ver.2)
by
Satoshi Hara
[DL輪読会]data2vec: A General Framework for Self-supervised Learning in Speech,...
by
Deep Learning JP
[DL輪読会]Temporal Abstraction in NeurIPS2019
by
Deep Learning JP
Active Learning 入門
by
Shuyo Nakatani
Similar to 【DL輪読会】Llama 2: Open Foundation and Fine-Tuned Chat Models
PDF
ChatGPTの仕組みの解説と実務でのLLMの適用の紹介_latest.pdf
by
Ginpei Kobayashi
PDF
【 DL輪読会】ToolLLM: Facilitating Large Language Models to Master 16000+ Real-wo...
by
Deep Learning JP
PDF
DLゼミ: Llama 2: Open Foundation and Fine-Tuned Chat Models
by
harmonylab
PDF
Wandb Monthly Meetup August 2023.pdf
by
Yuya Yamamoto
PPTX
「機械学習とは?」から始める Deep learning実践入門
by
Hideto Masuoka
PDF
Deep Learningの基礎と応用
by
Seiya Tokui
PDF
dl-with-python01_handout
by
Shin Asakawa
PDF
Deep Learning Implementations: pylearn2 and torch7 (JNNS 2015)
by
Kotaro Nakayama
PDF
Rnncamp2handout
by
Shin Asakawa
PDF
Chainerの使い方と自然言語処理への応用
by
Seiya Tokui
PPTX
[DL輪読会]Learning to Adapt: Meta-Learning for Model-Based Control
by
Deep Learning JP
PDF
Recurrent Neural Networks
by
Seiya Tokui
PDF
Rnncamp01
by
Shin Asakawa
PDF
Rnncamp01
by
Shin Asakawa
PPTX
ACL読み会2017:Deep Keyphrase Generation
by
Miho Matsunagi
PDF
『Pythonによる ai・機械学習・深層学習アプリのつくり方』をGoogleColabで動く限り動かしてみた
by
Takehiro Eguchi
PDF
BERTに関して
by
Saitama Uni
PDF
BERT+XLNet+RoBERTa
by
禎晃 山崎
DOCX
レポート深層学習Day3
by
ssuser9d95b3
PDF
読書会開催提案
by
YAMANE Toshiaki
ChatGPTの仕組みの解説と実務でのLLMの適用の紹介_latest.pdf
by
Ginpei Kobayashi
【 DL輪読会】ToolLLM: Facilitating Large Language Models to Master 16000+ Real-wo...
by
Deep Learning JP
DLゼミ: Llama 2: Open Foundation and Fine-Tuned Chat Models
by
harmonylab
Wandb Monthly Meetup August 2023.pdf
by
Yuya Yamamoto
「機械学習とは?」から始める Deep learning実践入門
by
Hideto Masuoka
Deep Learningの基礎と応用
by
Seiya Tokui
dl-with-python01_handout
by
Shin Asakawa
Deep Learning Implementations: pylearn2 and torch7 (JNNS 2015)
by
Kotaro Nakayama
Rnncamp2handout
by
Shin Asakawa
Chainerの使い方と自然言語処理への応用
by
Seiya Tokui
[DL輪読会]Learning to Adapt: Meta-Learning for Model-Based Control
by
Deep Learning JP
Recurrent Neural Networks
by
Seiya Tokui
Rnncamp01
by
Shin Asakawa
Rnncamp01
by
Shin Asakawa
ACL読み会2017:Deep Keyphrase Generation
by
Miho Matsunagi
『Pythonによる ai・機械学習・深層学習アプリのつくり方』をGoogleColabで動く限り動かしてみた
by
Takehiro Eguchi
BERTに関して
by
Saitama Uni
BERT+XLNet+RoBERTa
by
禎晃 山崎
レポート深層学習Day3
by
ssuser9d95b3
読書会開催提案
by
YAMANE Toshiaki
More from Deep Learning JP
PPTX
【DL輪読会】AdaptDiffuser: Diffusion Models as Adaptive Self-evolving Planners
by
Deep Learning JP
PPTX
【DL輪読会】事前学習用データセットについて
by
Deep Learning JP
PPTX
【DL輪読会】 "Learning to render novel views from wide-baseline stereo pairs." CVP...
by
Deep Learning JP
PPTX
【DL輪読会】Zero-Shot Dual-Lens Super-Resolution
by
Deep Learning JP
PPTX
【DL輪読会】BloombergGPT: A Large Language Model for Finance arxiv
by
Deep Learning JP
PPTX
【DL輪読会】マルチモーダル LLM
by
Deep Learning JP
PPTX
【DL輪読会】AnyLoc: Towards Universal Visual Place Recognition
by
Deep Learning JP
PDF
【DL輪読会】Can Neural Network Memorization Be Localized?
by
Deep Learning JP
PPTX
【DL輪読会】SimPer: Simple self-supervised learning of periodic targets( ICLR 2023 )
by
Deep Learning JP
PDF
【DL輪読会】RLCD: Reinforcement Learning from Contrast Distillation for Language M...
by
Deep Learning JP
PDF
【DL輪読会】"Secrets of RLHF in Large Language Models Part I: PPO"
by
Deep Learning JP
PPTX
【DL輪読会】"Language Instructed Reinforcement Learning for Human-AI Coordination "
by
Deep Learning JP
PDF
【DL輪読会】"Learning Fine-Grained Bimanual Manipulation with Low-Cost Hardware"
by
Deep Learning JP
PPTX
【DL輪読会】Parameter is Not All You Need:Starting from Non-Parametric Networks fo...
by
Deep Learning JP
PDF
【DL輪読会】Drag Your GAN: Interactive Point-based Manipulation on the Generative ...
by
Deep Learning JP
PDF
【DL輪読会】Self-Supervised Learning from Images with a Joint-Embedding Predictive...
by
Deep Learning JP
PPTX
【DL輪読会】Towards Understanding Ensemble, Knowledge Distillation and Self-Distil...
by
Deep Learning JP
PPTX
【DL輪読会】VIP: Towards Universal Visual Reward and Representation via Value-Impl...
by
Deep Learning JP
PDF
【DL輪読会】Deep Transformers without Shortcuts: Modifying Self-attention for Fait...
by
Deep Learning JP
PPTX
【DL輪読会】TrOCR: Transformer-based Optical Character Recognition with Pre-traine...
by
Deep Learning JP
【DL輪読会】AdaptDiffuser: Diffusion Models as Adaptive Self-evolving Planners
by
Deep Learning JP
【DL輪読会】事前学習用データセットについて
by
Deep Learning JP
【DL輪読会】 "Learning to render novel views from wide-baseline stereo pairs." CVP...
by
Deep Learning JP
【DL輪読会】Zero-Shot Dual-Lens Super-Resolution
by
Deep Learning JP
【DL輪読会】BloombergGPT: A Large Language Model for Finance arxiv
by
Deep Learning JP
【DL輪読会】マルチモーダル LLM
by
Deep Learning JP
【DL輪読会】AnyLoc: Towards Universal Visual Place Recognition
by
Deep Learning JP
【DL輪読会】Can Neural Network Memorization Be Localized?
by
Deep Learning JP
【DL輪読会】SimPer: Simple self-supervised learning of periodic targets( ICLR 2023 )
by
Deep Learning JP
【DL輪読会】RLCD: Reinforcement Learning from Contrast Distillation for Language M...
by
Deep Learning JP
【DL輪読会】"Secrets of RLHF in Large Language Models Part I: PPO"
by
Deep Learning JP
【DL輪読会】"Language Instructed Reinforcement Learning for Human-AI Coordination "
by
Deep Learning JP
【DL輪読会】"Learning Fine-Grained Bimanual Manipulation with Low-Cost Hardware"
by
Deep Learning JP
【DL輪読会】Parameter is Not All You Need:Starting from Non-Parametric Networks fo...
by
Deep Learning JP
【DL輪読会】Drag Your GAN: Interactive Point-based Manipulation on the Generative ...
by
Deep Learning JP
【DL輪読会】Self-Supervised Learning from Images with a Joint-Embedding Predictive...
by
Deep Learning JP
【DL輪読会】Towards Understanding Ensemble, Knowledge Distillation and Self-Distil...
by
Deep Learning JP
【DL輪読会】VIP: Towards Universal Visual Reward and Representation via Value-Impl...
by
Deep Learning JP
【DL輪読会】Deep Transformers without Shortcuts: Modifying Self-attention for Fait...
by
Deep Learning JP
【DL輪読会】TrOCR: Transformer-based Optical Character Recognition with Pre-traine...
by
Deep Learning JP
Recently uploaded
PDF
エンジニアが選ぶべきAIエディタ & Antigravity 活用例@ウェビナー「触ってみてどうだった?Google Antigravity 既存IDEと...
by
NorihiroSunada
PDF
Machine Tests Benchmark Suite. Explain github.com/alexziskind1/machine_tests #2
by
Tasuku Takahashi
PDF
Machine Tests Benchmark Suite. Explain github.com/alexziskind1/machine_tests #1
by
Tasuku Takahashi
PDF
20251210_MultiDevinForEnterprise on Devin 1st Anniv Meetup
by
Masaki Yamakawa
PDF
流行りに乗っかるClaris FileMaker 〜AI関連機能の紹介〜 by 合同会社イボルブ
by
Evolve LLC.
PPTX
楽々ナレッジベース「楽ナレ」3種比較 - Dify / AWS S3 Vector / Google File Search Tool
by
Kiyohide Yamaguchi
エンジニアが選ぶべきAIエディタ & Antigravity 活用例@ウェビナー「触ってみてどうだった?Google Antigravity 既存IDEと...
by
NorihiroSunada
Machine Tests Benchmark Suite. Explain github.com/alexziskind1/machine_tests #2
by
Tasuku Takahashi
Machine Tests Benchmark Suite. Explain github.com/alexziskind1/machine_tests #1
by
Tasuku Takahashi
20251210_MultiDevinForEnterprise on Devin 1st Anniv Meetup
by
Masaki Yamakawa
流行りに乗っかるClaris FileMaker 〜AI関連機能の紹介〜 by 合同会社イボルブ
by
Evolve LLC.
楽々ナレッジベース「楽ナレ」3種比較 - Dify / AWS S3 Vector / Google File Search Tool
by
Kiyohide Yamaguchi
【DL輪読会】Llama 2: Open Foundation and Fine-Tuned Chat Models
1.
DEEP LEARNING JP [DL
Papers] Llama 2: Open Foundation and Fine-Tuned Chat Models Keno Harada, D1, the University of Tokyo http://deeplearning.jp/
2.
大規模言語モデル講座が開講します 2
3.
Topic • 2Trillion tokenで訓練した7B,
13B, 70Bモデルを公開 - 対話用のLLAMA2-CHATも公開 - 34Bもいずれ公開予定 - 4096 context length(2x), grouped-query attention • 既存のOpen Source Modelを上回る • 安全性の考慮 - Safety-specific data annotation and tuning - Red-teaming - Iterative evaluations - 利用者向けのガイドも整備 • Finetuningの手順を詳細に記述 - Pretrainingについてはちょこっとだけ • 新たな発見 - Emergence of tool usage - Temporal organization of knowledge 特別な言及がない場合、図や表はLLaMA2元論文からの引用になります 3
4.
遊べるサイト 4
5.
目次 • Pretraining • Fine-tuning •
Model safety • Key observations and insights 5
6.
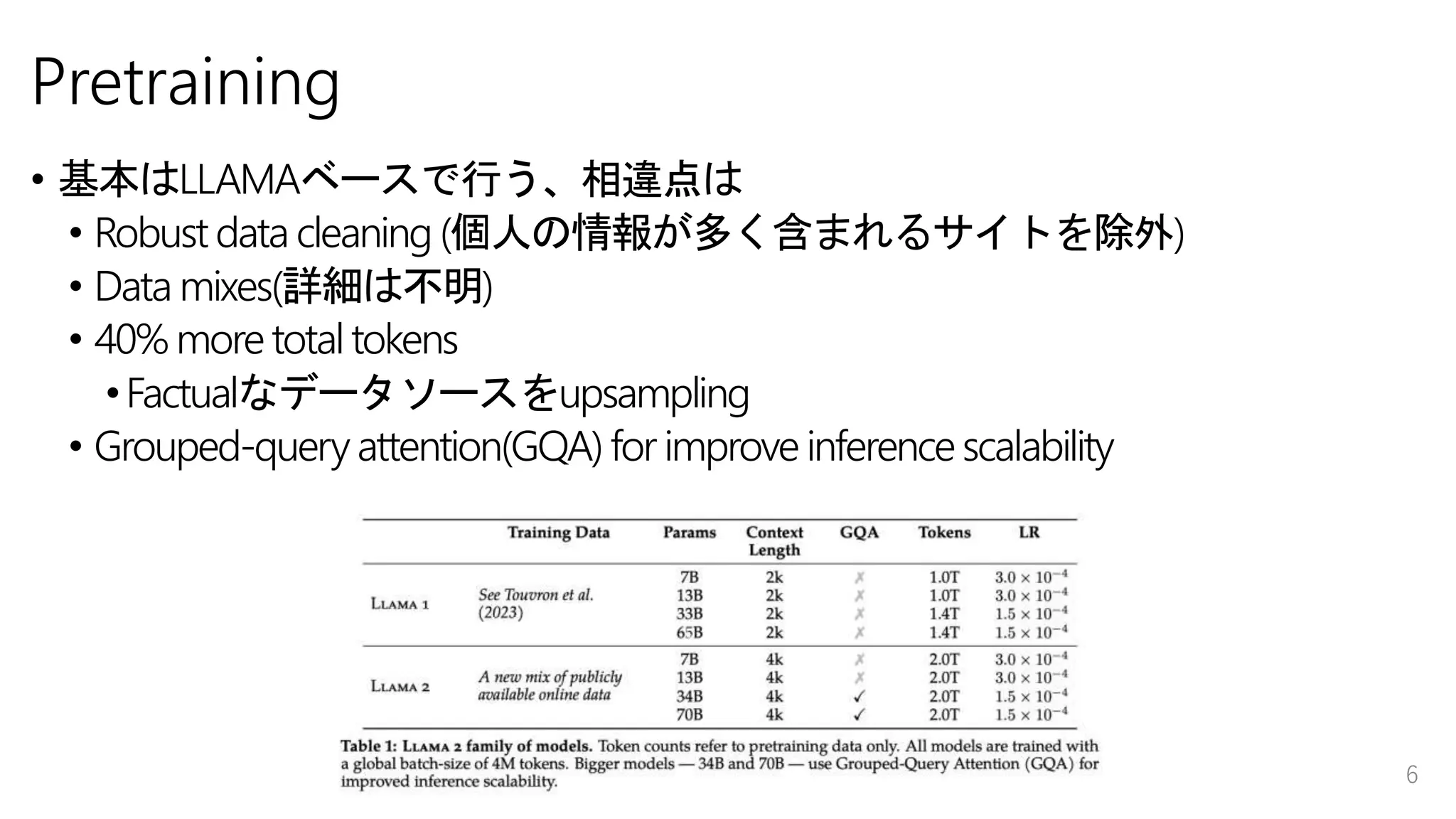
Pretraining • 基本はLLAMAベースで行う、相違点は • Robust
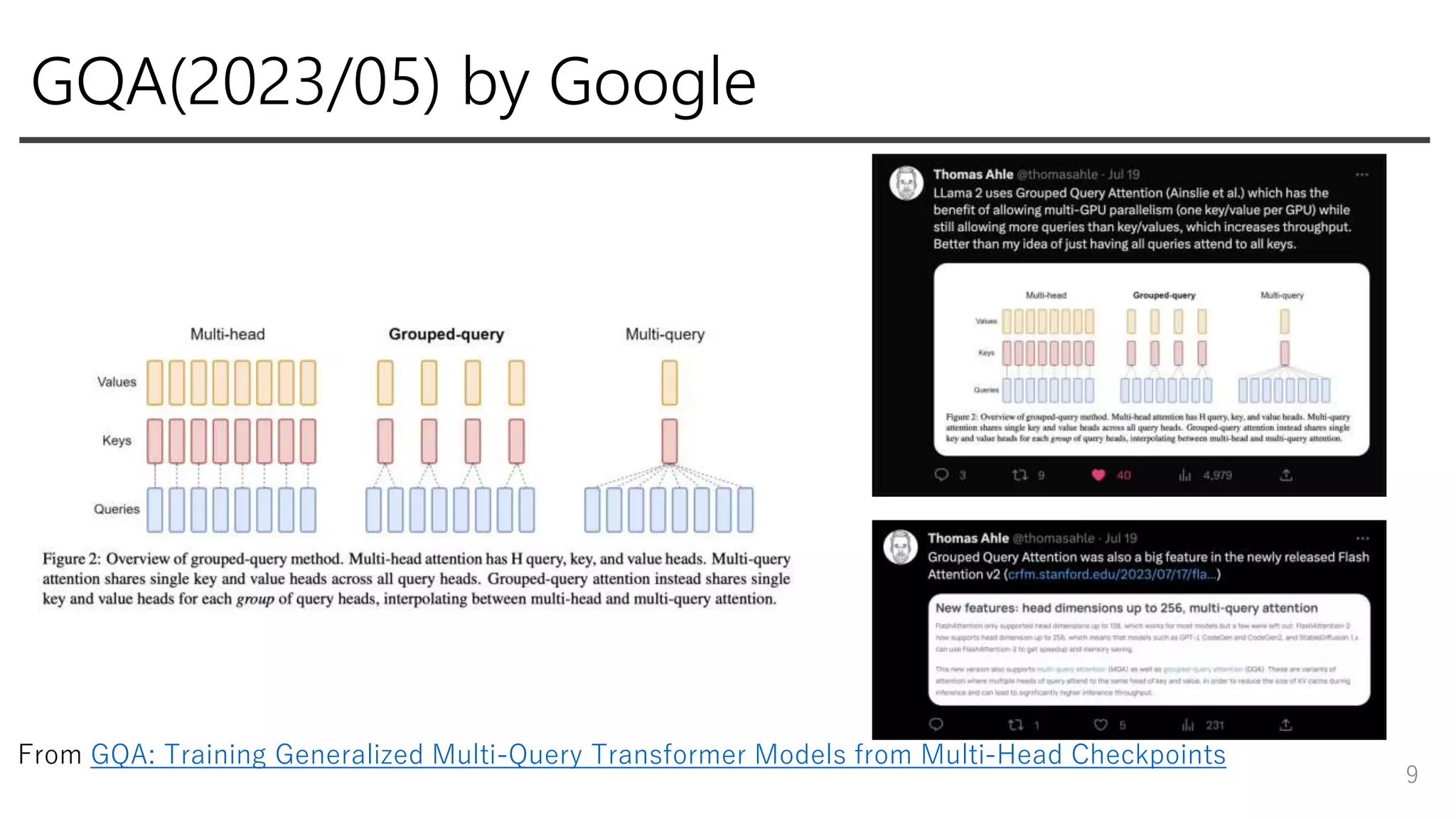
data cleaning (個人の情報が多く含まれるサイトを除外) • Data mixes(詳細は不明) • 40% more total tokens •Factualなデータソースをupsampling • Grouped-query attention(GQA) for improve inference scalability 6
7.
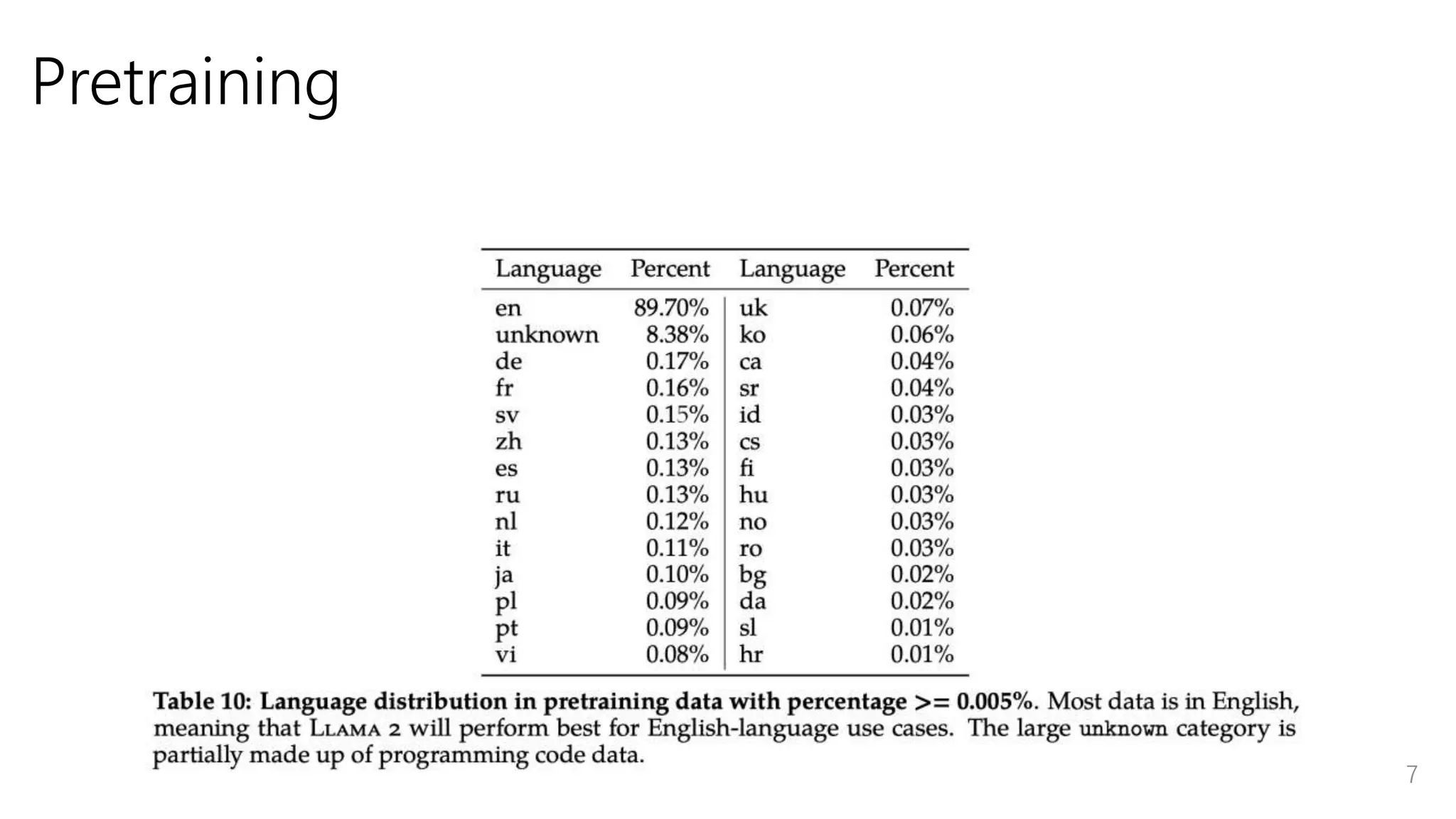
Pretraining 7
8.
モデル構造など • Standard transformer
architecture • Pre-normalization using RMSNorm • SwiGLU activation • Rotary positional embeddings • (for 34B and 70B) GQA • AdamW, cosine learning rate schedule, warmup • Bytepair encoding(BPE) using SentencePiece - 数字は各桁切り分け, unknown UTF-8はbytesでdecompose 8
9.
GQA(2023/05) by Google 9 From
GQA: Training Generalized Multi-Query Transformer Models from Multi-Head Checkpoints
10.
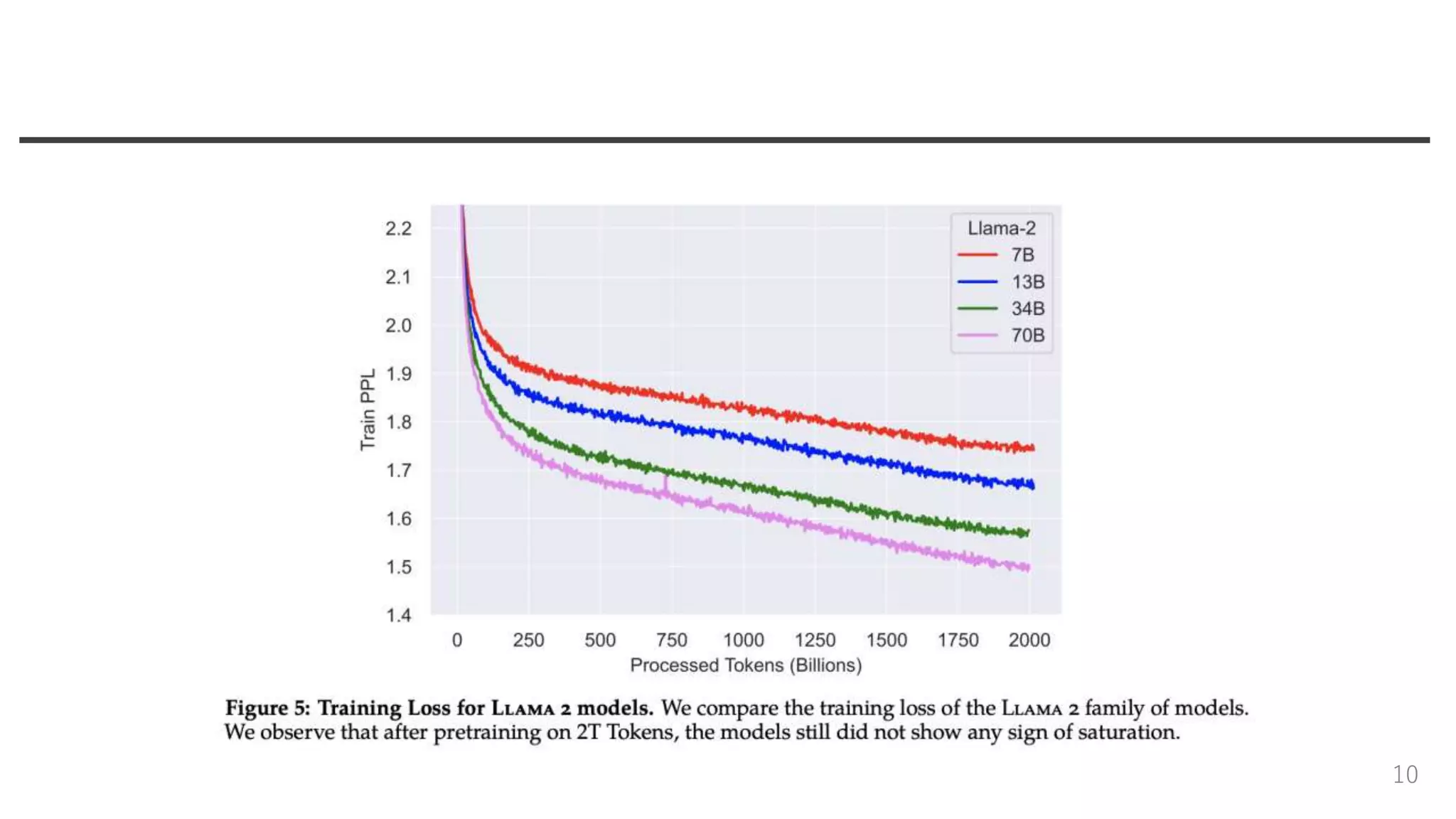
10
11.
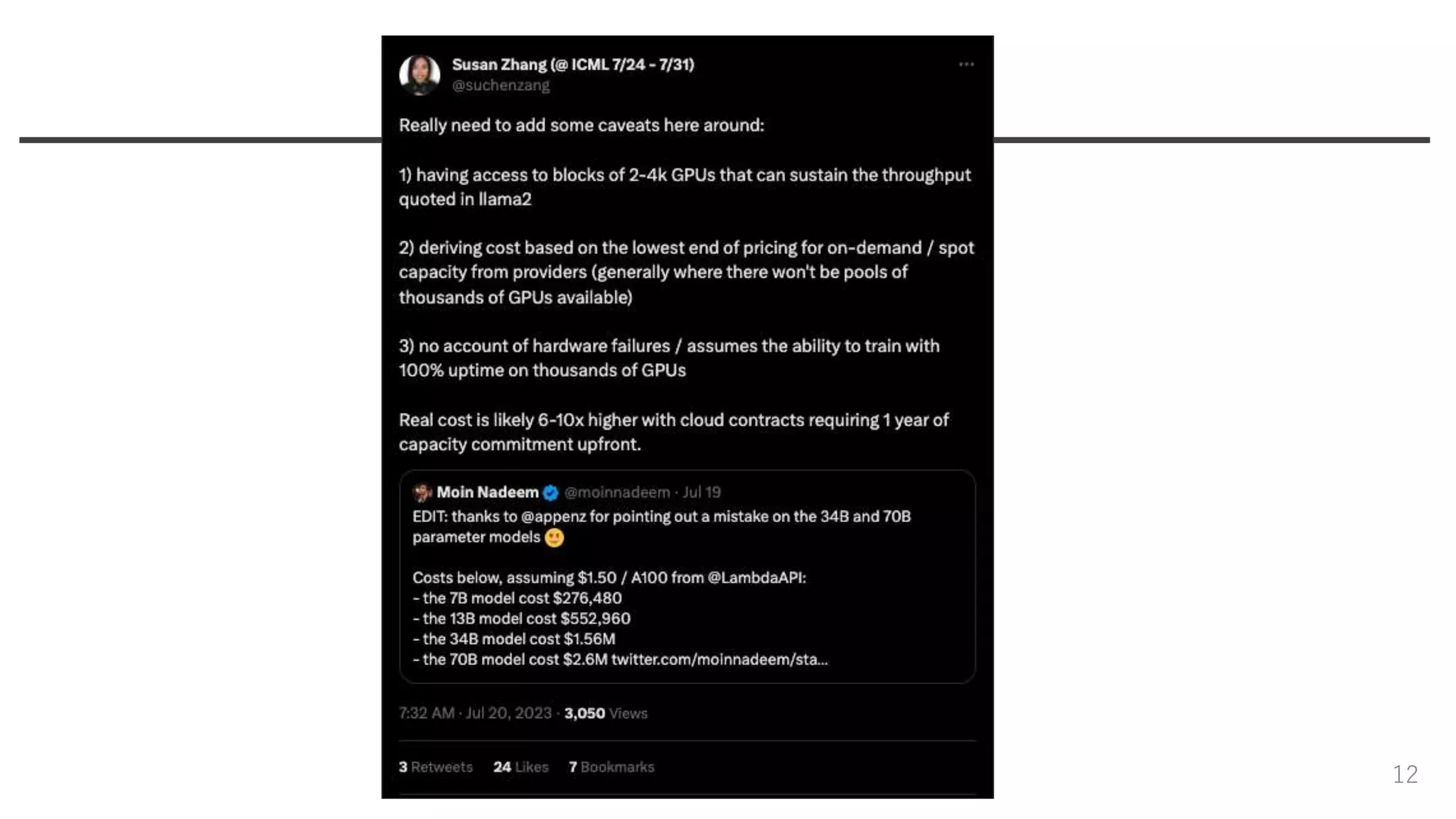
Hardware • A100(80G)で構成されたcluster - RSC:
400W, NVIDIA Quantum InifiniBand(高い) - Internal production cluster: 350W, RoCE(RDMA over converged Ethernet) - 200Gpbsの内部通信 - ABCI換算(A100 40G): 1720320(hour) / 8(GPUs/node) * 3(point/hour) * 2(80G/40G) * 220(point/yen) = 約2.8億円? 11
12.
12
13.
評価 • Code - HumanEvalとMBPPのpass@1
scoresの平均 • Commonsense Reasoning - PIQA, SIQA, HellaSwag, WinoGrande, ARC OpenBookQA, CommonSenseQAの平均スコア • CommonSenseQAのみ7-shot, 他は0-shot • World Knowledge - NaturalQuestions, TriviaQAの5-shotの平均スコア • Reading Comprehension - SQuAD, QuAC, BoolQの0-shotの平均スコア • MATH - GSM8K(8-shot), MATH(4-shot)の平均スコア • Popular Aggregated Benchmarks - MMLU(5-shot), Big Bench Hard(3-shot), AGI Eval(英語のみ)(3-5 shot)の平均スコア 13
14.
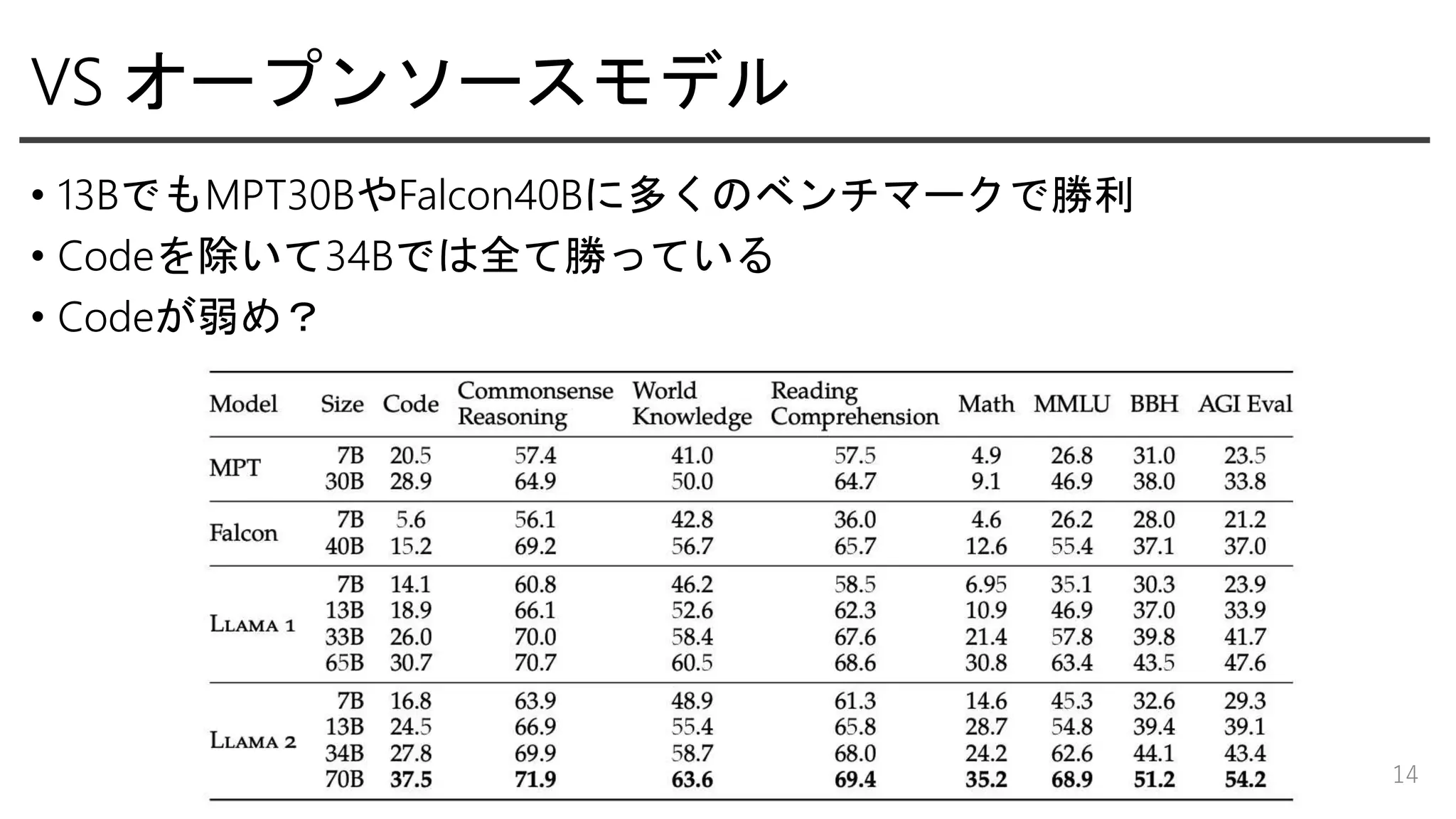
VS オープンソースモデル • 13BでもMPT30BやFalcon40Bに多くのベンチマークで勝利 •
Codeを除いて34Bでは全て勝っている • Codeが弱め? 14
15.
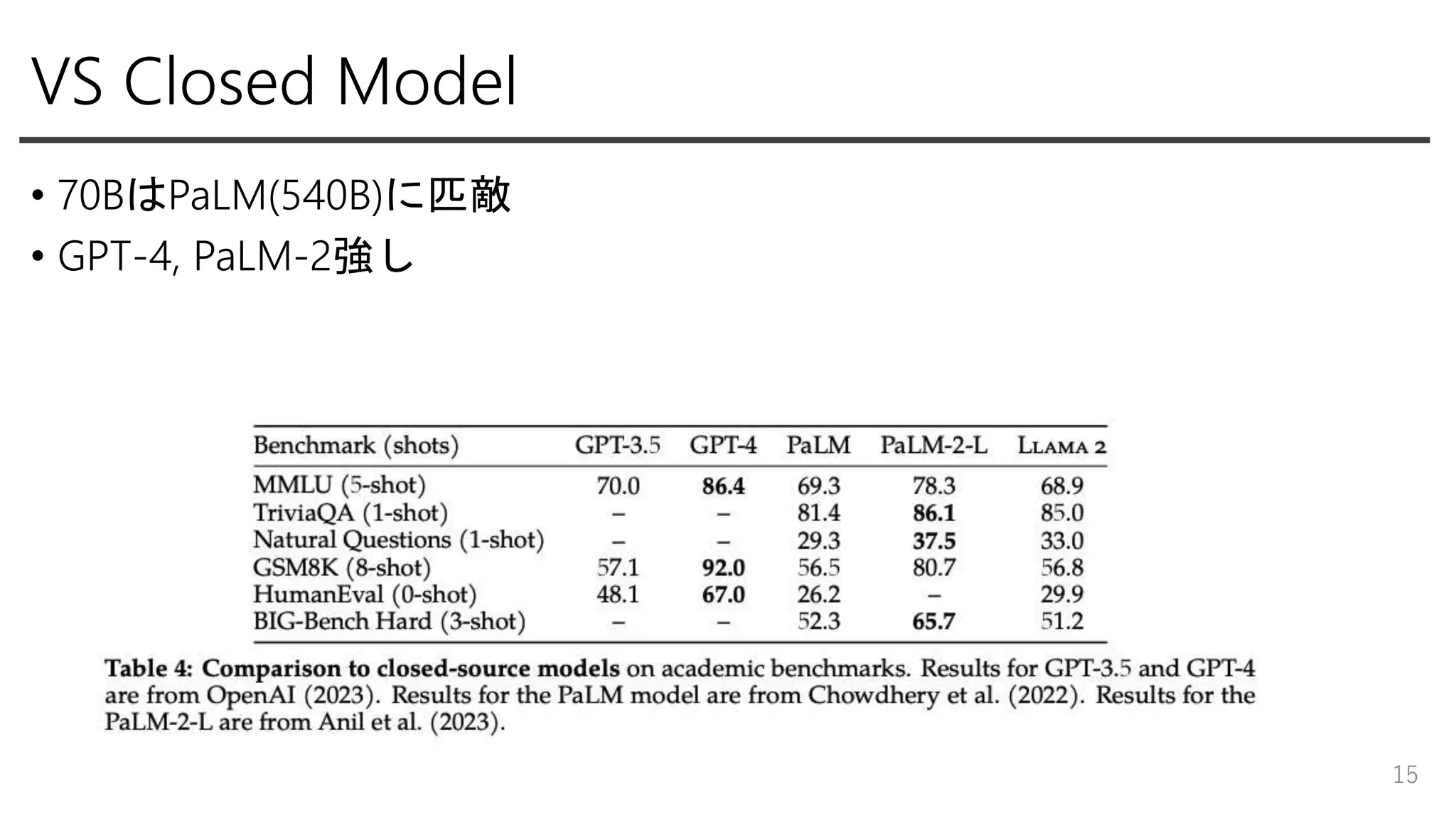
VS Closed Model •
70BはPaLM(540B)に匹敵 • GPT-4, PaLM-2強し 15
16.
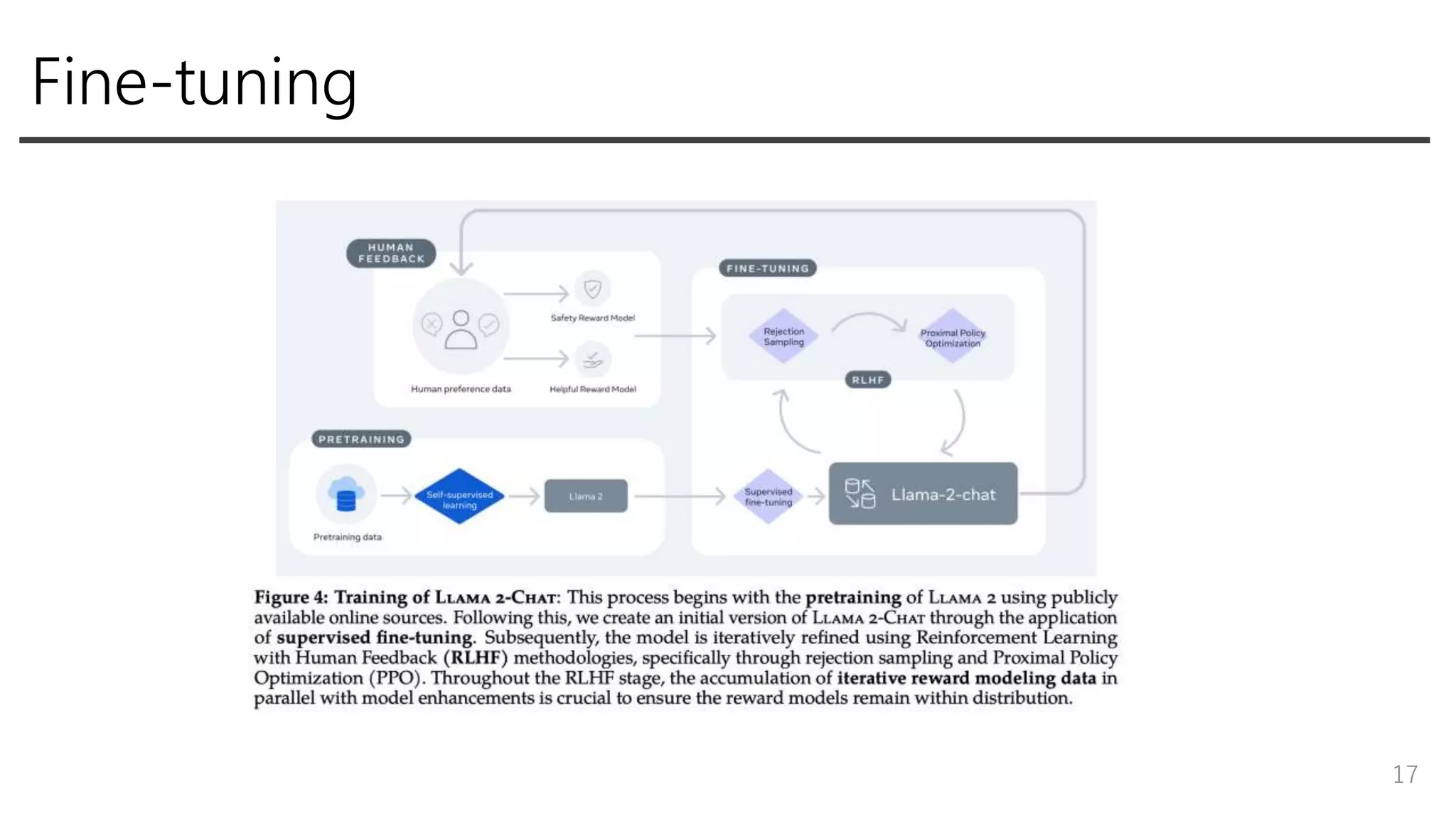
Fine-tuning • Supervised fine-tuning •
Iterative reward modeling • RLHF - Rejection sampling - PPO • Ghost Attention(GAtt) - 複数回のやり取りをうまく扱うための工夫 16
17.
Fine-tuning 17
18.
Supervised fine-tuning • Flanのデータ
+ 独自で作成した(ベンダーに依頼)データ - 10,000個くらいあればいい結果が出るらしい - 実際にアノテーションしたのは27,540個 •依頼したベンダーのデータごとで学習してパフォーマンス見たら結 構違いがあったとのこと - 人間の出力とモデルの出力が似たようなレベルに • Prompt + special token + answerの文字列を自己回帰的な目的関数で学 習、answer部分のlossのみで学習, 2epoch - lr: 2 * 10 **-5, cosine lr schedule 18
19.
作成したデータの例 • (アノテーターが答え作るのもめちゃくちゃむずそう) 19
20.
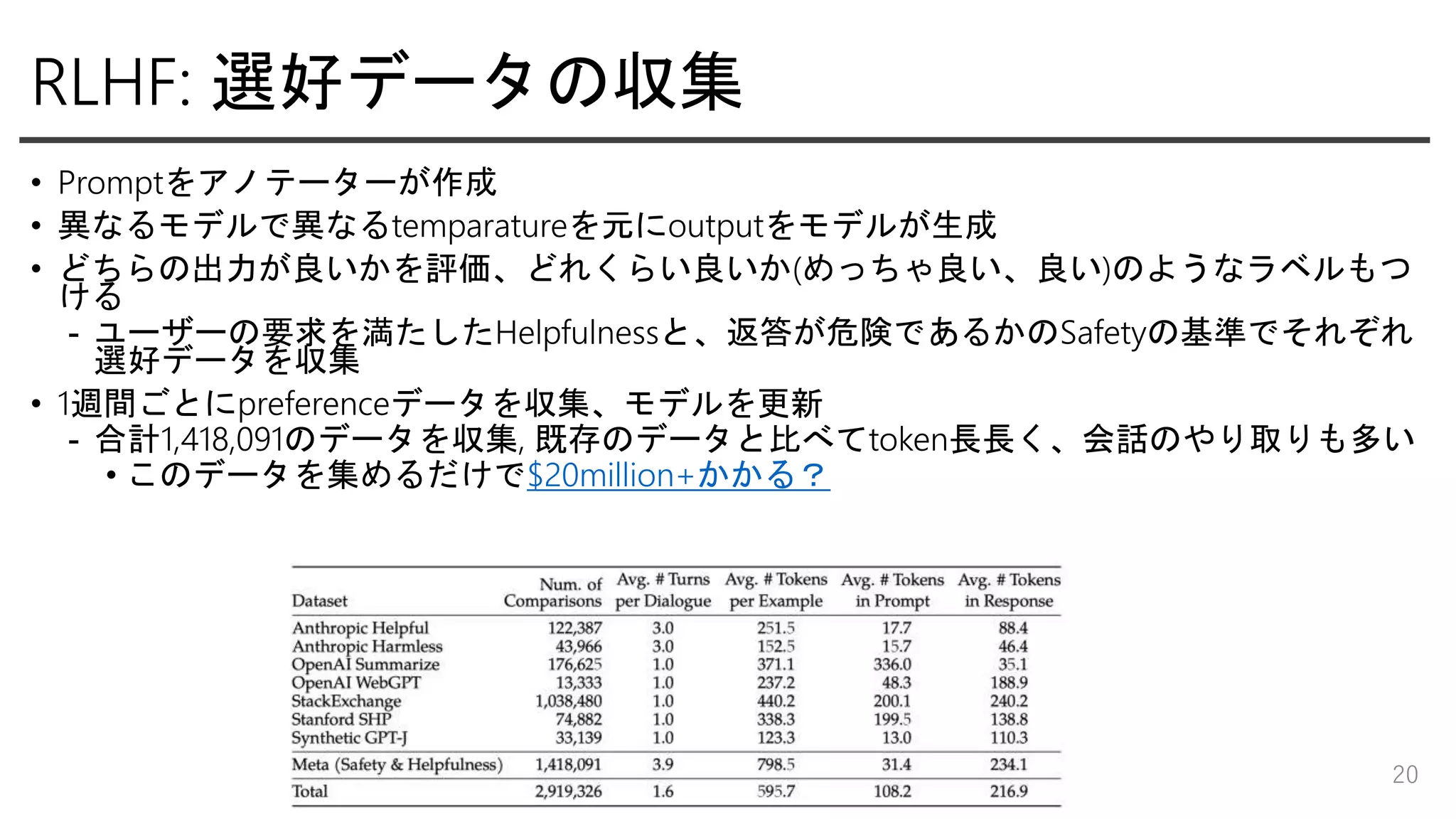
RLHF: 選好データの収集 • Promptをアノテーターが作成 •
異なるモデルで異なるtemparatureを元にoutputをモデルが生成 • どちらの出力が良いかを評価、どれくらい良いか(めっちゃ良い、良い)のようなラベルもつ ける - ユーザーの要求を満たしたHelpfulnessと、返答が危険であるかのSafetyの基準でそれぞれ 選好データを収集 • 1週間ごとにpreferenceデータを収集、モデルを更新 - 合計1,418,091のデータを収集, 既存のデータと比べてtoken長長く、会話のやり取りも多い • このデータを集めるだけで$20million+かかる? 20
21.
21 From Surge AI
× Meta: The 1M+ RLHF Annotations Powering Llama 2
22.
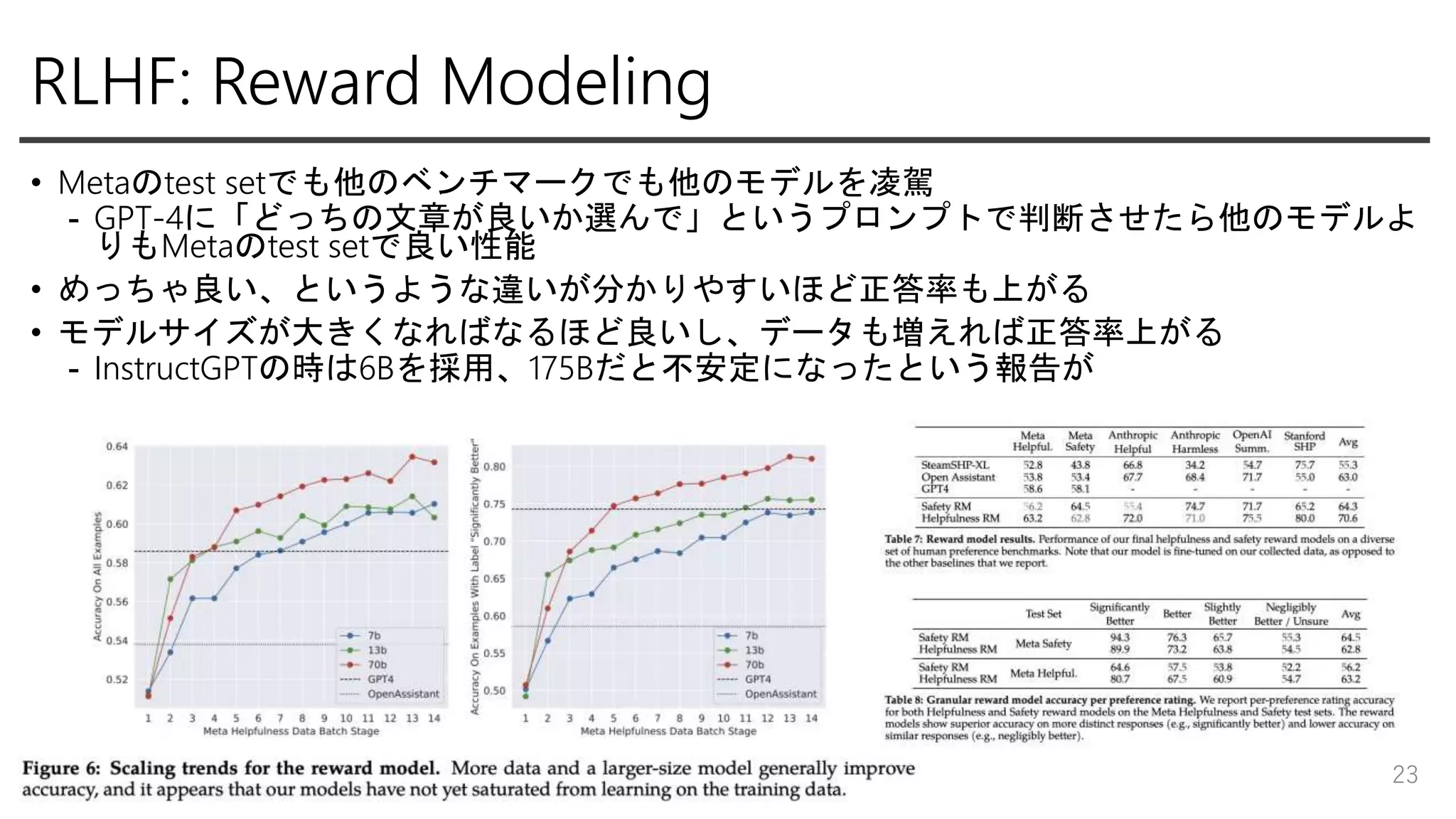
RLHF: Reward Modeling •
HelpfulnessとSafetyのスコアを出すモデルをそれぞれ訓練 - オープンソースのデータと組み合わせ訓練しても問題なかったので一 緒に使った - Helpfulness: Meta独自のHelpfulnessデータと, Safetyデータ・オープン ソースのデータで訓練 - Safety: Meta独自のSafetyデータ + Anthropic:Helpfullness(Meta独自+ オープンソース)を9:1の割合で訓練 •10%Helpfullness混ぜるとどちらもsafeな時の判定に役立つ - めっちゃ良い、良いラベルを活用したマージンもlossに組み込む • 1epoch(過学習を観測したため), lr: 5 * 10 ** -6(70B) 他は1 * 10 ** -5, consine lr, warmup 22
23.
RLHF: Reward Modeling •
Metaのtest setでも他のベンチマークでも他のモデルを凌駕 - GPT-4に「どっちの文章が良いか選んで」というプロンプトで判断させたら他のモデルよ りもMetaのtest setで良い性能 • めっちゃ良い、というような違いが分かりやすいほど正答率も上がる • モデルサイズが大きくなればなるほど良いし、データも増えれば正答率上がる - InstructGPTの時は6Bを採用、175Bだと不安定になったという報告が 23
24.
RLHF: iterative fine-tuning •
Rejection Sampling fine-tuning - K個モデルに出力させて、Reward Modelで一番高いスコアを出した出 力を選びfine-tuneする • PPO • RLHF modelはV1からV5まで作り、V4まではRejection Sampling fine- tuning, V5ではRejection Sampling fine-tuning後にPPO(70B) - 70B以外では70BのRejectionでの選ばれた出力を元にfine-tune - V1, V2においての良い出力をV3の訓練に使用 •含めないと性能悪化(forgettingとかと関連?) 24
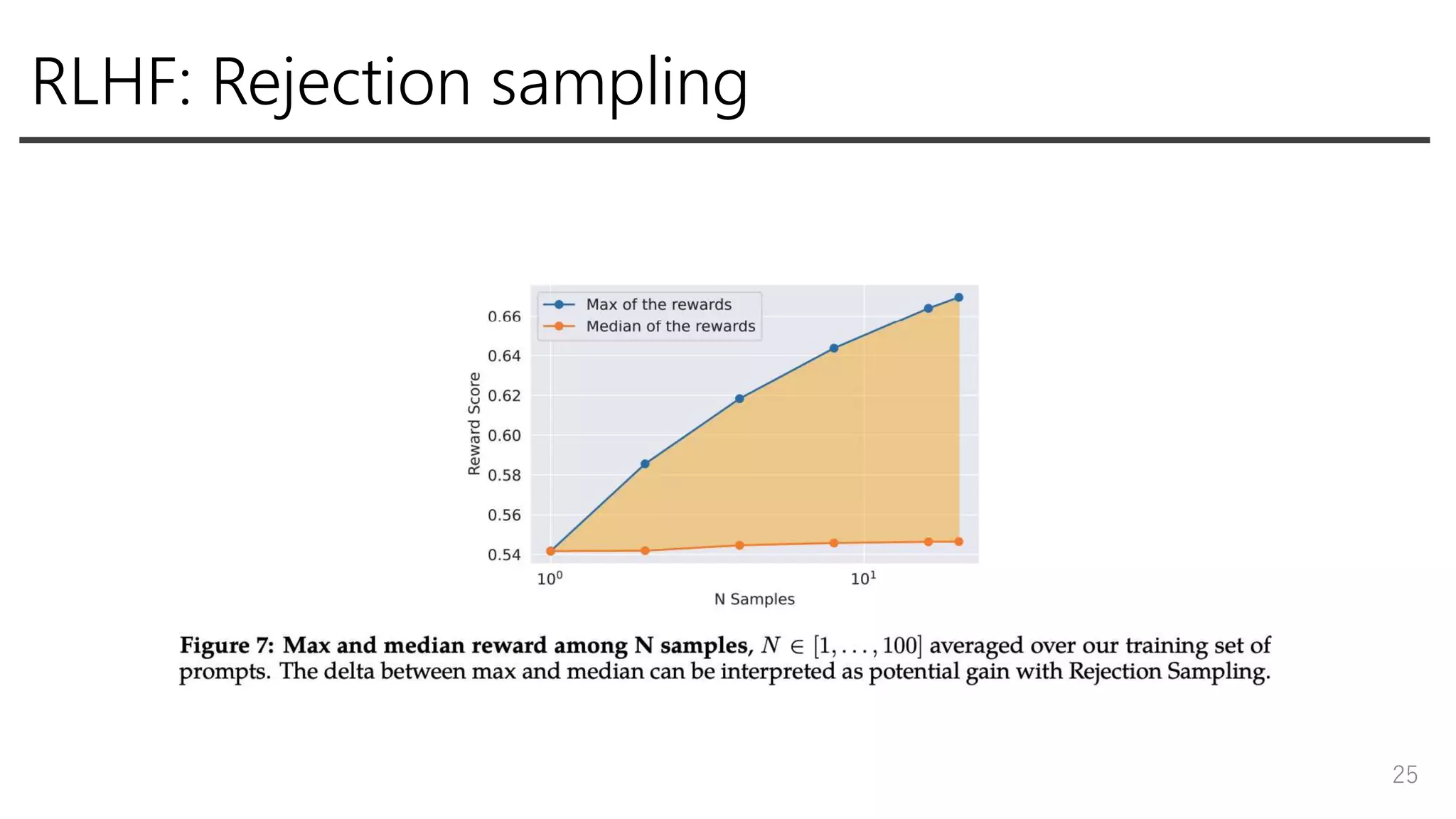
25.
RLHF: Rejection sampling 25
26.
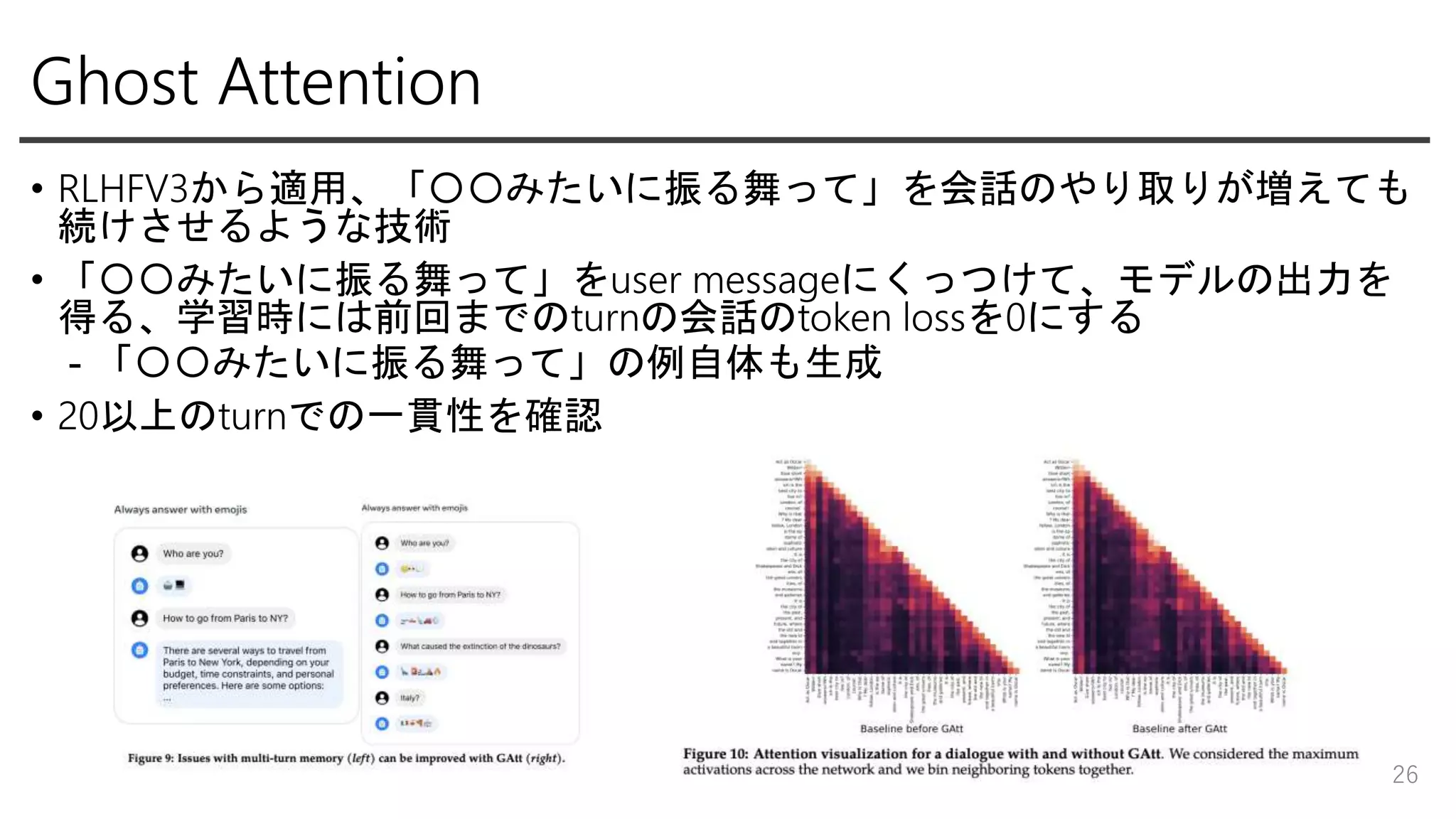
Ghost Attention • RLHFV3から適用、「〇〇みたいに振る舞って」を会話のやり取りが増えても 続けさせるような技術 •
「〇〇みたいに振る舞って」をuser messageにくっつけて、モデルの出力を 得る、学習時には前回までのturnの会話のtoken lossを0にする - 「〇〇みたいに振る舞って」の例自体も生成 • 20以上のturnでの一貫性を確認 26
27.
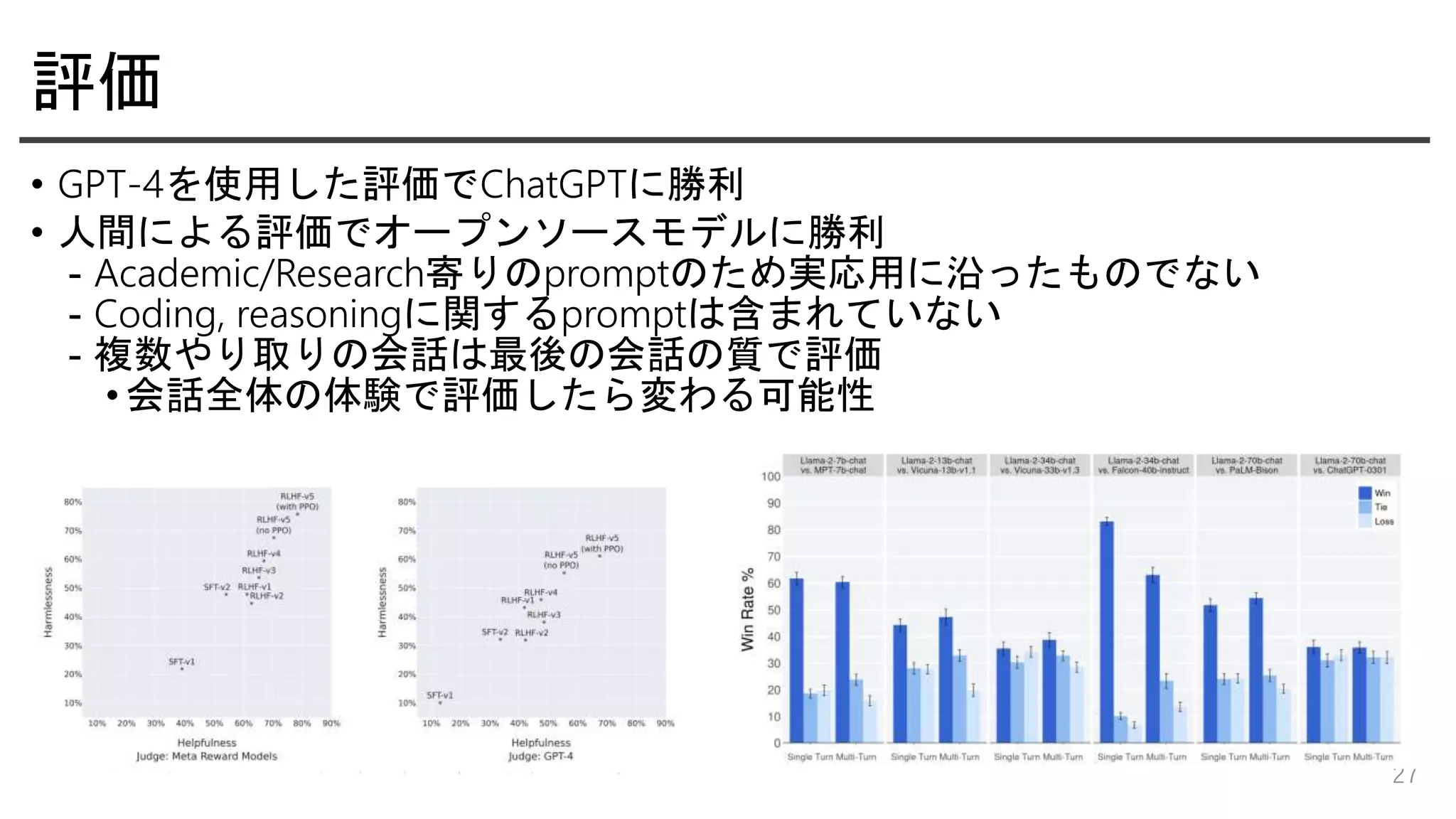
評価 • GPT-4を使用した評価でChatGPTに勝利 • 人間による評価でオープンソースモデルに勝利 -
Academic/Research寄りのpromptのため実応用に沿ったものでない - Coding, reasoningに関するpromptは含まれていない - 複数やり取りの会話は最後の会話の質で評価 • 会話全体の体験で評価したら変わる可能性 27
28.
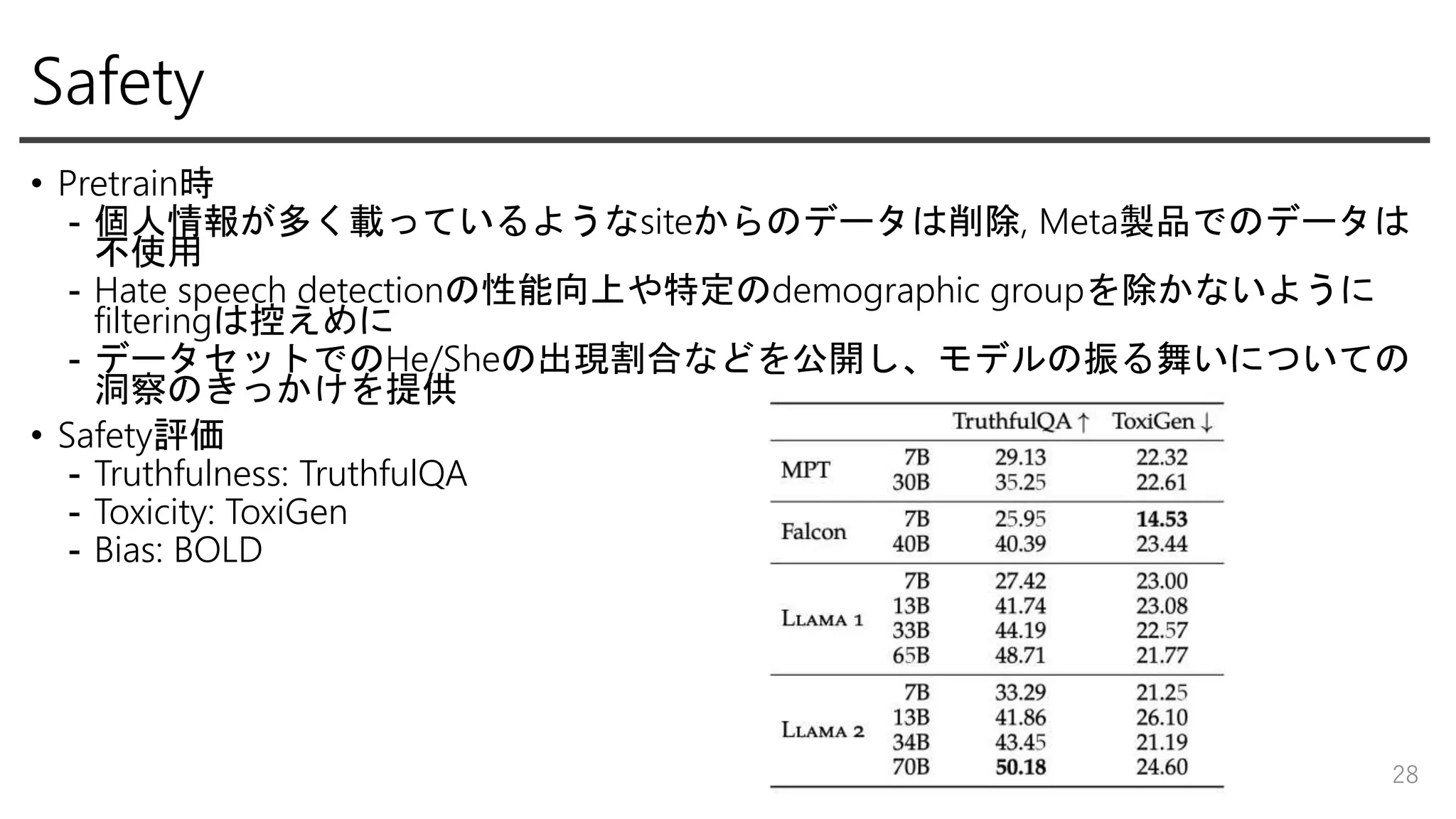
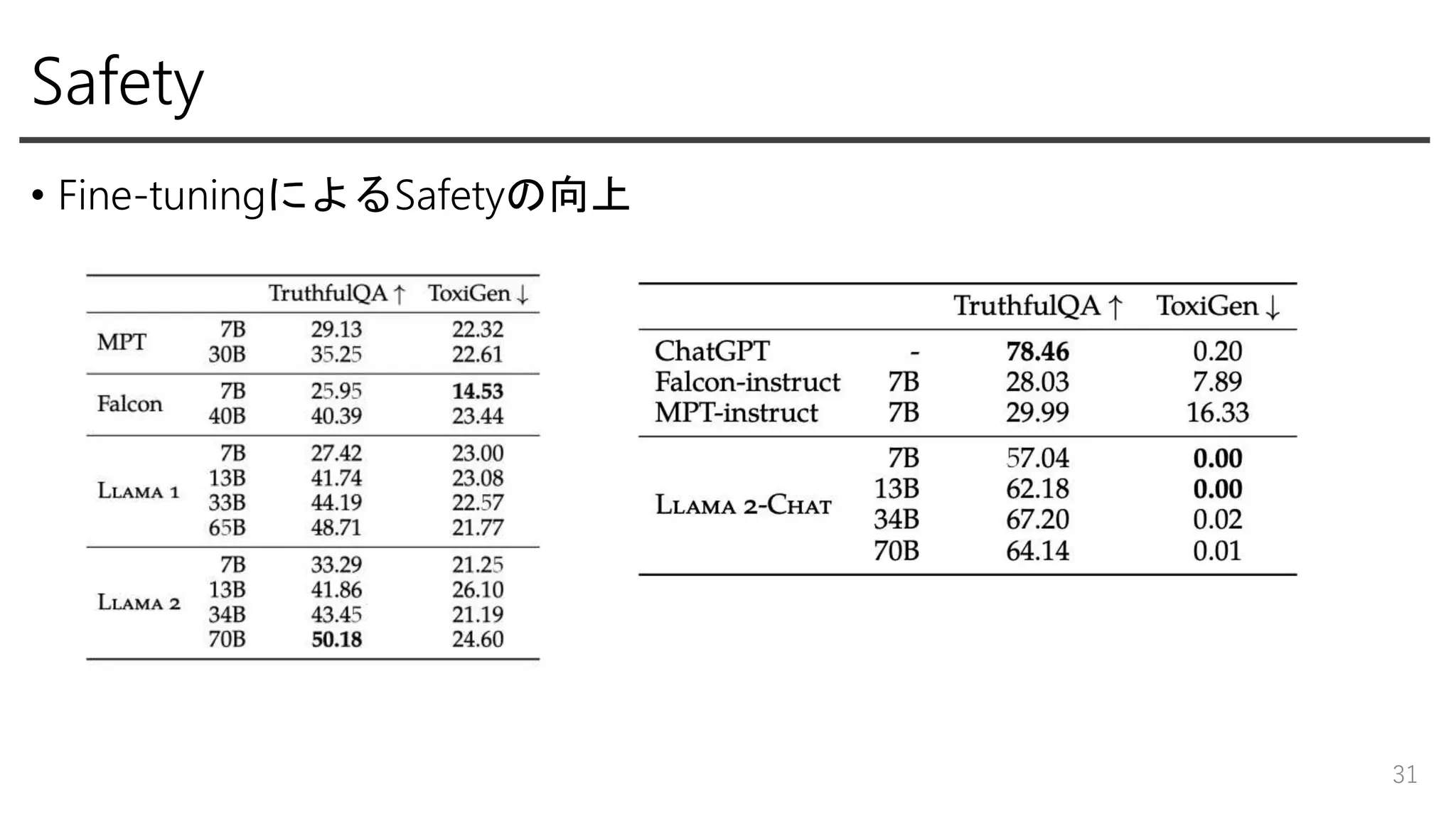
Safety • Pretrain時 - 個人情報が多く載っているようなsiteからのデータは削除,
Meta製品でのデータは 不使用 - Hate speech detectionの性能向上や特定のdemographic groupを除かないように filteringは控えめに - データセットでのHe/Sheの出現割合などを公開し、モデルの振る舞いについての 洞察のきっかけを提供 • Safety評価 - Truthfulness: TruthfulQA - Toxicity: ToxiGen - Bias: BOLD 28
29.
Safety • Fine-tuning - Supervised
safety fine-tuning •Adversarial promptsとそれに対するsafe demonstrationをはじめに準 備, RLHF前からsafety性を高める - Safety RLHF •Safety-specificなReward Modelと、より複雑なadversarial promptsを 準備 - Safety Context Distillation •“あなたはsafeで責任感のあるアシスタントです”というpre-プロンプ トを足して出力させたサンプルを、pre-プロンプトを抜いてfine- tune 29
30.
Safety • Red Teaming -
ML以外にも様々な専門家含め350人ほどが参加 30
31.
Safety 31 • Fine-tuningによるSafetyの向上
32.
RLHFの推しポイント • SFTはシグナル多いから学習上良いかなって思ってたけど、poorな demonstrationに引っ張られる、上限もアノテーターのスキルによって定まっ ちゃう • どっちの出力が良いかの選好をするアノテーションはやりやすいしブレも少 ない -
Reward Modelの学習が進むと低いスコアが付けられるべき文章を簡単に見 分けられる • “the superior writing abilities of LLMs, as manifested in surpassing human annotators in certain tasks, are fundamentally driven by RLHF” 32
33.
OpenAIのAlignmentリーダーのtalkより 33
34.
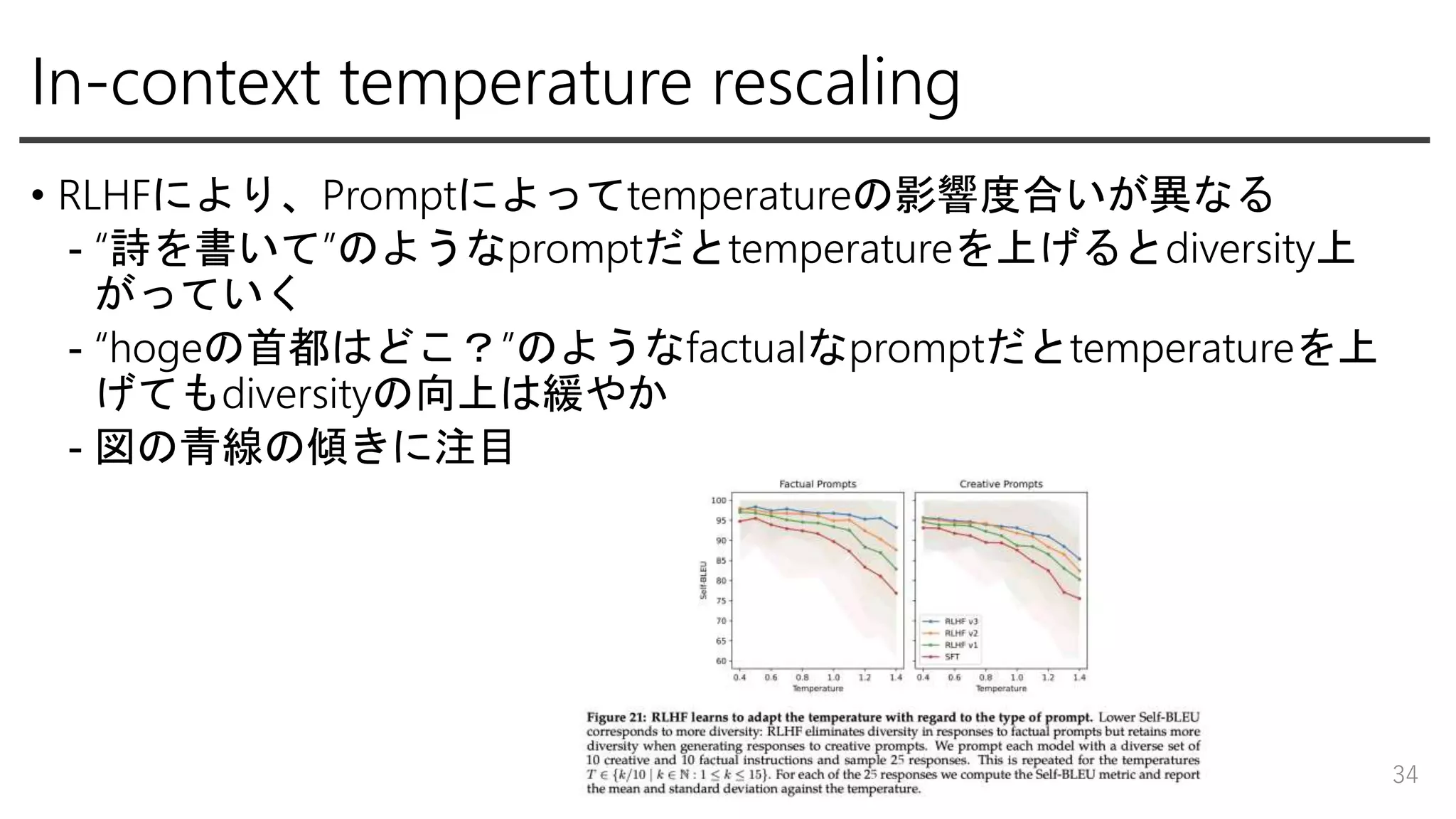
In-context temperature rescaling •
RLHFにより、Promptによってtemperatureの影響度合いが異なる - “詩を書いて”のようなpromptだとtemperatureを上げるとdiversity上 がっていく - “hogeの首都はどこ?”のようなfactualなpromptだとtemperatureを上 げてもdiversityの向上は緩やか - 図の青線の傾きに注目 34
35.
Temporal Perception • 知識を時間的に整理しているような例を確認 35
36.
Tool Use Emergence •
Tool-use usageについて明示的に教えていないのにalignmentの過程で tool-useの能力が出現した 36
37.
まとめ 37
38.
大規模言語モデル講座が開講します 38
Editor's Notes
#38
まとめです 本研究では多様な環境・タスクに対応するためには学習による行動系列の獲得が有効であると考えられますが、現状の手法は行動に関しての表現学習がなされておらず、行動獲得に適した構造の必要性を指摘しました 本研究はフィードバック制御が行動の学習・獲得にとって有用な構造だと仮定し、学習による獲得を目指しました 潜在空間における差分をもとに行動選択を行うことで既存手法より安定して目標状態に収束することを確認しました より階層的で複雑なタスクに対処するために潜在空間の学習の工夫や行動の更新式に関するさらなる工夫が必要であることを今後の課題として整理しました なお本研究については人工知能学会2022において採択・発表済みです 発表は以上になります、ご清聴ありがとうございました
Download
![DEEP LEARNING JP
[DL Papers]
Llama 2: Open Foundation and Fine-Tuned Chat Models
Keno Harada, D1, the University of Tokyo
http://deeplearning.jp/](https://image.slidesharecdn.com/llama220230720-230720010354-617059c0/75/DL-Llama-2-Open-Foundation-and-Fine-Tuned-Chat-Models-1-2048.jpg)



























![[DL輪読会]Set Transformer: A Framework for Attention-based Permutation-Invariant...](https://cdn.slidesharecdn.com/ss_thumbnails/20200221settransformer-200221020423-thumbnail.jpg?width=640&height=640&fit=bounds)












![[DL輪読会]Learning Latent Dynamics for Planning from Pixels](https://cdn.slidesharecdn.com/ss_thumbnails/taniguchi20181221-190104064850-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DL輪読会]data2vec: A General Framework for Self-supervised Learning in Speech,...](https://cdn.slidesharecdn.com/ss_thumbnails/220204nonakadl1-220204025334-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]Temporal Abstraction in NeurIPS2019](https://cdn.slidesharecdn.com/ss_thumbnails/20191115-191112082849-thumbnail.jpg?width=640&height=640&fit=bounds)











![[DL輪読会]Learning to Adapt: Meta-Learning for Model-Based Control](https://cdn.slidesharecdn.com/ss_thumbnails/20180511dl-180511004107-thumbnail.jpg?width=640&height=640&fit=bounds)


































