書誌情報
RLCD: Reinforcement Learningfrom Contrast Distillation for Language Model
Alignment
https://arxiv.org/abs/2307.12950
タイトル:
著者:
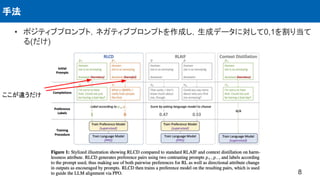
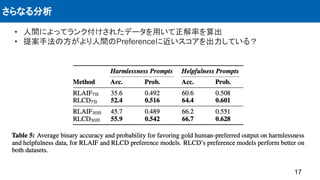
人間のフィードバックデータを使用せずに人間の好みに合わせて言語モデルを調整する方法である,コ
ントラスト蒸留による強化学習 (RLCD) という手法を提案
概要:
2
Kevin Yang, Dan Klein, Asli Celikyilmaz, Nanyun Peng, Yuandong Tian
UC Berkeley, Meta AI, UCLA
3.
• Reinforcement Learningwith Human Feedback (RLHF) は,人間の好みに合わせて
調整(Alignment)するために用いられる(無害性,有用性,真実性など)
背景
3
![http://deeplearning.jp/
RLCD: Reinforcement Learning from Contrast Distillation for
Language Model Alignment
〜 Human Feedbackを使用しないRLHF 〜
高城 頌太(東京大学 工学系研究科 松尾研 M2)
DEEP LEARNING JP
[DL Papers]
1](https://image.slidesharecdn.com/llm20230727-230727050623-b9d22fa4/85/DL-RLCD-Reinforcement-Learning-from-Contrast-Distillation-for-Language-Model-Alignment-Human-Feedback-RLHF-1-320.jpg)



















![[DL輪読会]逆強化学習とGANs](https://cdn.slidesharecdn.com/ss_thumbnails/irlgans-171128063119-thumbnail.jpg?width=640&height=640&fit=bounds)





![[DL輪読会]Decision Transformer: Reinforcement Learning via Sequence Modeling](https://cdn.slidesharecdn.com/ss_thumbnails/decisiontransformer20210709zhangxin-210709021501-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]近年のオフライン強化学習のまとめ —Offline Reinforcement Learning: Tutorial, Review, an...](https://cdn.slidesharecdn.com/ss_thumbnails/20200626journalclubpub-200630064755-thumbnail.jpg?width=640&height=640&fit=bounds)





![[DL輪読会]Inverse Constrained Reinforcement Learning](https://cdn.slidesharecdn.com/ss_thumbnails/20210709icrl-210709021811-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DL輪読会]Model-Based Reinforcement Learning via Meta-Policy Optimization](https://cdn.slidesharecdn.com/ss_thumbnails/model-basedreinforcementlearningviameta-policyoptimization-190705000247-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]Dense Captioning分野のまとめ](https://cdn.slidesharecdn.com/ss_thumbnails/dlseminar-201202012355-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DL輪読会]Dream to Control: Learning Behaviors by Latent Imagination](https://cdn.slidesharecdn.com/ss_thumbnails/20200313furutav2-200313025657-thumbnail.jpg?width=640&height=640&fit=bounds)




















