2012: Deep Learningブームの幕開け
●物体画像認識のコンペで、Deep Learningを用いたチームが圧勝
○ エラー率を一気に10%近く改善(25.8->16.4%)
○ 画像認識コミュニティに衝撃走る
“ImageNet Classification with Deep Convolutional Neural Networks ”, A. Krizhevsky, et. al.
5.
2012: Deep Learningブームの幕開け
●化合物の活性予測コンペでDeep Learningベースの手法が勝利
○ ドメイン知識を使わず、活性予測の素人が優勝
● Youtubeの動画を元に、”猫に反応するニューロン”を獲得
○ 画像からの特徴抽出の自動化…従来は人間のドメイン知識に基づいて設計
○ 2000台のマシンで1週間かけて10億パラメータを学習
○ 猫、人といった概念を教えずに(!)それらの概念を獲得
人の顔 (左)、猫の顔(右)によく反応するニューロンの可視化
Merck Competition Challenge http://blog.kaggle.com/2012/10/31/merck-competition-results-deep-nn-and-gpus-come-out-to-play/
“Building High-level Features Using Large Scale Unsupervised Learning ”, Q. V. Le, et. al.
6.
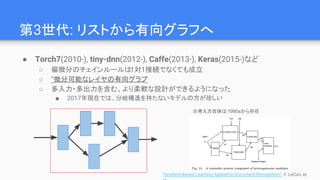
2013 - 2016
●ルールを教えずにAtari 2600をプレイ(2013)
○ コンピュータが自分で試行錯誤しながら、様々なゲームのプレイ方法を学習
○ ブロック崩しなどの単純なゲームでは人間以上のスコア
“Playing Atari with Deep Reinforcement Learning”, V. Mnih, et. al.
7.
2013 - 2016
●物体画像認識タスクで人間のエラー率を超える(2015)
○ Human:5.1% Deep Learning: 4.94% (by Microsoft Research)
○ さらに2016/8には3.08%まで改善 (by Google)
● 画像拡大(超解像)で従来を大幅に超える精度を達成(2015)
○ パッチ型超解像と呼ばれていた技術を応用、汎用的なDeep Learningで実現
“Delving Deep into Rectifiers: Surpassing Human-Level Performance on ImageNet Classification”, K. He, et. al.
“Inception-v4, Inception-ResNet and the Impact of Residual Connections on Learning”, C. Szegedy, et. al.
“Learning a Deep Convolutional Network for Image Super-Resolution”, C. Dong, et. al.
8.
2013 - 2016
●画風の変換(2015)
○ 画像から”画風”の特徴だけを抽出して別の画像に適用
○ のちに動画にも適用: https://www.youtube.com/watch?v=Uxax5EKg0zA
“A Neural Algorithm of Artistic Style”, L. A. Gatys He, et. al.
“Artistic style transfer for videos”, M. Ruder, et. al.
9.
2013 - 2016
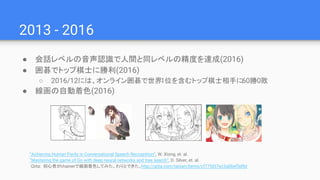
●会話レベルの音声認識で人間と同レベルの精度を達成(2016)
● 囲碁でトップ棋士に勝利(2016)
○ 2016/12には、オンライン囲碁で世界1位を含むトップ棋士相手に60勝0敗
● 線画の自動着色(2016)
“Achieving Human Parity in Conversational Speech Recognition”, W. Xiong, et. al.
“Mastering the game of Go with deep neural networks and tree search”, D. Silver, et. al.
Qiita: 初心者がchainerで線画着色してみた。わりとできた。http://qiita.com/taizan/items/cf77fd37ec3a0bef5d9d
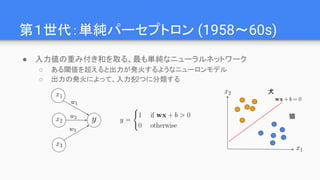
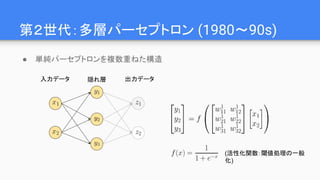
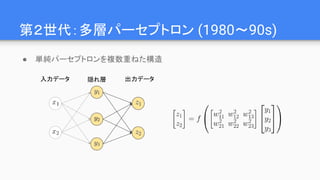
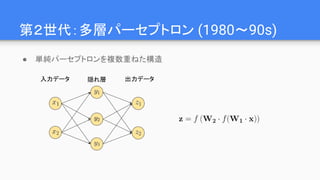
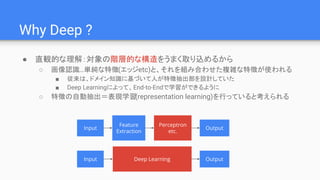
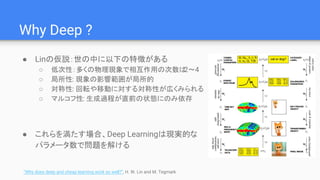
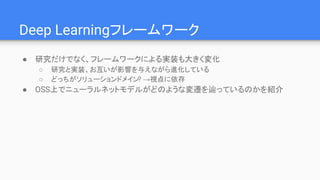
Why Deep ?
●Linの仮説:世の中に以下の特徴がある
○ 低次性:多くの物理現象で相互作用の次数は2~4
○ 局所性: 現象の影響範囲が局所的
○ 対称性: 回転や移動に対する対称性が広くみられる
○ マルコフ性: 生成過程が直前の状態にのみ依存
● これらを満たす場合、Deep Learningは現実的な
パラメータ数で問題を解ける
“Why does deep and cheap learning work so well?”, H. W. Lin and M. Tegmark
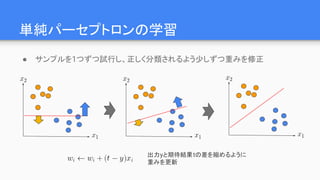
CNNによって学習された特徴
“Convolutional Deep BeliefNetworks for Scalable Unsupervised Learning of Hierarchical Representations”, H. Lee, et. al.
…
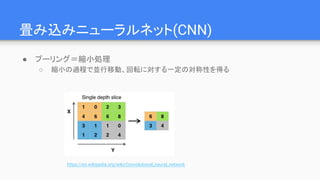
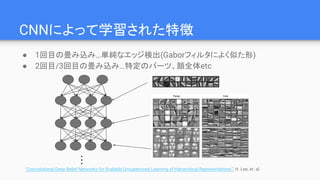
● 1回目の畳み込み…単純なエッジ検出(Gaborフィルタによく似た形)
● 2回目/3回目の畳み込み…特定のパーツ、顔全体etc
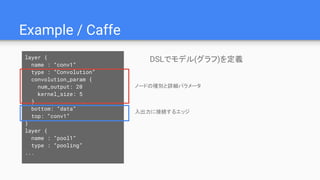
Example / Caffe
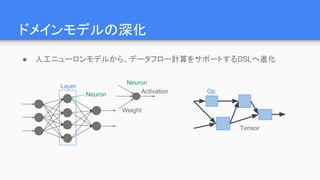
DSLでモデル(グラフ)を定義layer{
name : “conv1”
type : “Convolution”
convolution_param {
num_output: 20
kernel_size: 5
}
bottom: “data”
top: “conv1”
}
layer {
name : “pool1”
type : “pooling”
...
入出力に接続するエッジ
ノードの種別と詳細パラメータ
51.
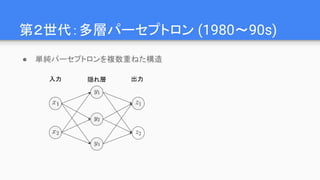
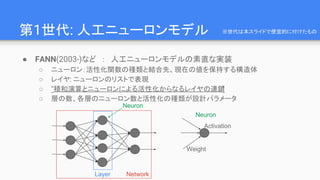
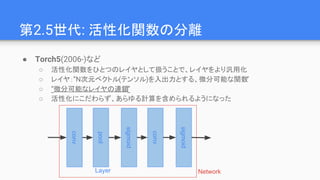
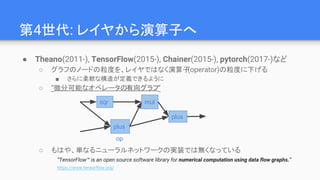
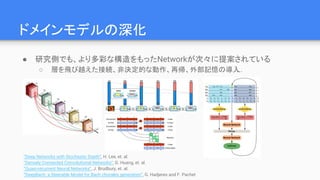
第4世代: レイヤから演算子へ
● Theano(2011-),TensorFlow(2015-), Chainer(2015-), pytorch(2017-)など
○ グラフのノードの粒度を、レイヤではなく演算子(operator)の粒度に下げる
■ さらに柔軟な構造が定義できるように
○ “微分可能なオペレータの有向グラフ”
mul
plus
sqr
plus
op
○ もはや、単なるニューラルネットワークの実装では無くなっている
“TensorFlow™ is an open source software library for numerical computation using data flow graphs.”
https://www.tensorflow.org/
52.
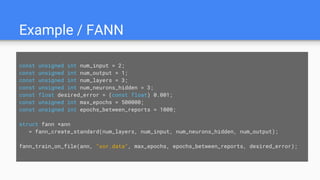
Example / TensorFlow
x_data= np.random.rand(100).astype(np.float32)
y_data = x_data * 0.1 + 0.3
W = tf.Variable(tf.random_uniform([1], -1.0, 1.0))
b = tf.Variable(tf.zeros([1]))
y = W * x_data + b
# Minimize the mean squared errors.
loss = tf.reduce_mean(tf.square(y - y_data))
optimizer = tf.train.GradientDescentOptimizer(0.5)
train = optimizer.minimize(loss)
53.
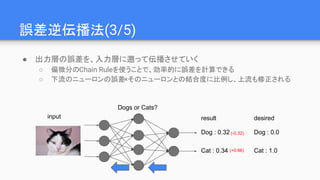
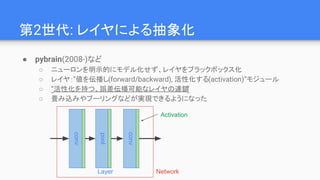
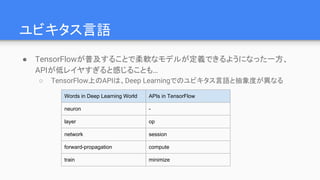
命令型(imperative) vs 記号型(symbolic)
●記号型:計算を即時に行わず、式自体を保持するモデル
○ TheanoやTensorFlowで採用
○ 学習の実行時にモデルをフレームワーク側で”コンパイル”し、グラフ構造を解析する
○ “コンパイラ”での最適化が(頑張れば)できるため、高速・高効率
■ 一時メモリの再利用、分散学習の効率化など
A = Variable('A')
B = Variable('B')
C = B * A
D = C + Constant(1)
# compiles the function
f = compile(D)
d = f(A=np.ones(10), B=np.ones(10)*2)
http://mxnet.io/architecture/program_model.html#symbolic-vs-imperative-programs
ここで初めてグラフが実行される
ここで計算対象のグラフが確定
54.
命令型(imperative) vs 記号型(symbolic)
●命令型:呼び出した時点で計算が実行されるモデル
○ Chainerやpytorchで採用
■ 実行時に演算グラフをバックエンドで記録しておき、後から自動微分で逆伝播する
○ 言語側の組み込み関数とMixしやすく、デバッグが容易
A = Variable(rand())
B = Variable(rand())
C = B * A
D = C + Constant(1)
D.backward()
裏で生成しておいたグラフから自動微分
この時点でCは計算されている















![Example / TensorFlow
x_data = np.random.rand(100).astype(np.float32)
y_data = x_data * 0.1 + 0.3
W = tf.Variable(tf.random_uniform([1], -1.0, 1.0))
b = tf.Variable(tf.zeros([1]))
y = W * x_data + b
# Minimize the mean squared errors.
loss = tf.reduce_mean(tf.square(y - y_data))
optimizer = tf.train.GradientDescentOptimizer(0.5)
train = optimizer.minimize(loss)](https://image.slidesharecdn.com/deeplearning-170122114941/85/Deep-learning-52-320.jpg)





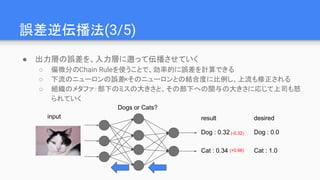
![API比較
network<sequential> net;
net << conv<>(28, 28, 5, 1, 32)
<< max_pool<relu>(24, 24, 2)
<< conv<>(12, 12, 5, 32, 64)
<< max_pool<relu>(8, 8, 64, 2)
<< fc<relu>(4*4*64, 1024)
<< dropout(1024, 0.5f)
<< fc<>(1024, 10);
x = tf.Variable(tf.random_normal([-1, 28, 28, 1]))
wc1 = tf.Variable(tf.random_normal([5, 5, 1, 32]))
wc2 = tf.Variable(tf.random_normal([5, 5, 32, 64]))
wd1 = tf.Variable(tf.random_normal([7*7*64, 1024]))
wout = tf.Variable(tf.random_normal([1024, n_classes]))
bc1 = tf.Variable(tf.random_normal([32]))
bc2 = tf.Variable(tf.random_normal([64]))
bd1 = tf.Variable(tf.random_normal([1024]))
bout = tf.Variable(tf.random_normal([n_classes]))
conv1 = conv2d(x, wc1, bc1)
conv1 = maxpool2d(conv1, k=2)
conv1 = tf.nn.relu(conv1)
conv2 = conv2d(conv1, wc2, bc2)
conv2 = maxpool2d(conv2, k=2)
conv2 = tf.nn.relu(conv2)
fc1 = tf.reshape(conv2, [-1, wd1.get_shape().as_list()[0]])
fc1 = tf.add(tf.matmul(fc1, wd1), bd1)
fc1 = tf.nn.relu(fc1)
fc1 = tf.nn.dropout(fc1, dropout)
out = tf.add(tf.matmul(fc1, wout), bout)
tiny-dnn (C++)TensorFlow (Python)](https://image.slidesharecdn.com/deeplearning-170122114941/85/Deep-learning-62-320.jpg)










![SSII2022 [OS3-03] スケーラブルなロボット学習システムに向けて](https://cdn.slidesharecdn.com/ss_thumbnails/ssii2022-os3-03-220607020929-1e2b15e8-thumbnail.jpg?width=640&height=640&fit=bounds)





![[DL輪読会]End-to-End Object Detection with Transformers](https://cdn.slidesharecdn.com/ss_thumbnails/200529dlseminardetr-200529061512-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DL輪読会]ICLR2020の分布外検知速報](https://cdn.slidesharecdn.com/ss_thumbnails/iclr2020ood-190927011524-thumbnail.jpg?width=640&height=640&fit=bounds)










































