背景
5
(1). Boosting: wherethe coeffcients associated with the combinations of the
single models are actually trained, instead of simply taking average;
(2). Bootstrapping/Bagging: the training data are different for each single model;
(3). Ensemble of models of different types and architectures;
(4). Ensemble of random features or decision trees.
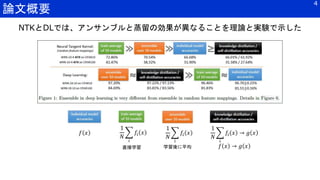
■アンサンブルの理論解析
• いくつかの状況設定で理論解析はあるが、単純平均のアンサンブルにおける理論解析がない
単純平均のアンサンブル学習の理論解析に着目
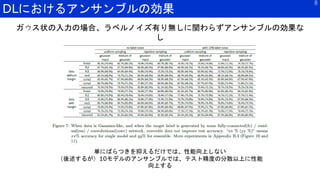
■単純平均のアンサンブル学習の理論解析
• 初期化乱数のみ異なるモデル(学習データ、学習率、アーキテクチャ固定)における以下の現
象を
理論的に説明することを試みる
Training average does not work: 学習前にモデルをアンサンブルしても効果
なし
Knowledge distillation works:単一モデルに複数モデルから蒸留できる
Self-distillation works:単一モデルから別の単一モデルへの蒸留でも性能が向上
![DEEP LEARNING JP
[DL Papers]
http://deeplearning.jp/
”Towards Understanding Ensemble, Knowledge Distillation
and Self-Distillation in Deep Learning” ICRL2023
Kensuke Wakasugi, Panasonic Holdings Corporation.
1](https://image.slidesharecdn.com/230630dlhdv2-230630030621-2ab756c1/85/DL-Towards-Understanding-Ensemble-Knowledge-Distillation-and-Self-Distillation-in-Deep-Learning-1-320.jpg)
![DEEP LEARNING JP
[DL Papers]
http://deeplearning.jp/
”Towards Understanding Ensemble, Knowledge Distillation
and Self-Distillation in Deep Learning” ICRL2023
Kensuke Wakasugi, Panasonic Holdings Corporation.
1](https://image.slidesharecdn.com/230630dlhdv2-230630030621-2ab756c1/75/DL-Towards-Understanding-Ensemble-Knowledge-Distillation-and-Self-Distillation-in-Deep-Learning-1-2048.jpg)



















![[DL輪読会]Neural Ordinary Differential Equations](https://cdn.slidesharecdn.com/ss_thumbnails/nnasode1-190111001755-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]GLIDE: Guided Language to Image Diffusion for Generation and Editing](https://cdn.slidesharecdn.com/ss_thumbnails/glide2-220107030326-thumbnail.jpg?width=640&height=640&fit=bounds)




![[DL輪読会] Spectral Norm Regularization for Improving the Generalizability of De...](https://cdn.slidesharecdn.com/ss_thumbnails/dlhackspectralnorm1-170907072536-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]Dream to Control: Learning Behaviors by Latent Imagination](https://cdn.slidesharecdn.com/ss_thumbnails/20200313furutav2-200313025657-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]ICLR2020の分布外検知速報](https://cdn.slidesharecdn.com/ss_thumbnails/iclr2020ood-190927011524-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]相互情報量最大化による表現学習](https://cdn.slidesharecdn.com/ss_thumbnails/20190913iwasawa-190913002312-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]Learning Latent Dynamics for Planning from Pixels](https://cdn.slidesharecdn.com/ss_thumbnails/taniguchi20181221-190104064850-thumbnail.jpg?width=640&height=640&fit=bounds)






![SSII2020 [OS2-02] 教師あり事前学習を凌駕する「弱」教師あり事前学習](https://cdn.slidesharecdn.com/ss_thumbnails/200611ssii2020os2weaksupervision-200609142553-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]MetaFormer is Actually What You Need for Vision](https://cdn.slidesharecdn.com/ss_thumbnails/20220121metaformer-220121085750-thumbnail.jpg?width=640&height=640&fit=bounds)







![[DL輪読会]Grokking: Generalization Beyond Overfitting on Small Algorithmic Datasets](https://cdn.slidesharecdn.com/ss_thumbnails/20220325okimura-220405024717-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]Ensemble Distribution Distillation](https://cdn.slidesharecdn.com/ss_thumbnails/ensembledistributiondistillation-200110020132-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DeepLearning論文読み会] Dataset Distillation](https://cdn.slidesharecdn.com/ss_thumbnails/datasetdistillation-181114165952-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会] “Asymmetric Tri-training for Unsupervised Domain Adaptation (ICML2017...](https://cdn.slidesharecdn.com/ss_thumbnails/dlhacks20170728-170728025901-thumbnail.jpg?width=640&height=640&fit=bounds)










![[DL輪読会]10分で10本の論⽂をざっくりと理解する (ICML2020)](https://cdn.slidesharecdn.com/ss_thumbnails/20200828-ant-200828025358-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]Life-Long Disentangled Representation Learning with Cross-Domain Laten...](https://cdn.slidesharecdn.com/ss_thumbnails/20180914iwasawa-180919025635-thumbnail.jpg?width=640&height=640&fit=bounds)




















