Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
EN
Uploaded by
Deep Learning JP
PPTX, PDF
773 views
【DL輪読会】事前学習用データセットについて
2023/8/24 Deep Learning JP http://deeplearning.jp/seminar-2/
Technology
◦
Read more
1
Save
Share
Embed
Embed presentation
Download
Downloaded 10 times
1
/ 20
2
/ 20
Most read
3
/ 20
4
/ 20
5
/ 20
6
/ 20
7
/ 20
8
/ 20
9
/ 20
10
/ 20
Most read
11
/ 20
12
/ 20
13
/ 20
14
/ 20
15
/ 20
16
/ 20
17
/ 20
18
/ 20
19
/ 20
20
/ 20
More Related Content
PDF
SSII2022 [TS1] Transformerの最前線〜 畳込みニューラルネットワークの先へ 〜
by
SSII
PPTX
[DL輪読会]ドメイン転移と不変表現に関するサーベイ
by
Deep Learning JP
PPTX
Curriculum Learning (関東CV勉強会)
by
Yoshitaka Ushiku
PPTX
[DL輪読会]Objects as Points
by
Deep Learning JP
PPTX
Swin Transformer (ICCV'21 Best Paper) を完璧に理解する資料
by
Yusuke Uchida
PPTX
【DL輪読会】Visual Classification via Description from Large Language Models (ICLR...
by
Deep Learning JP
PPTX
【DL輪読会】Dropout Reduces Underfitting
by
Deep Learning JP
PPTX
【DL輪読会】Scaling Laws for Neural Language Models
by
Deep Learning JP
SSII2022 [TS1] Transformerの最前線〜 畳込みニューラルネットワークの先へ 〜
by
SSII
[DL輪読会]ドメイン転移と不変表現に関するサーベイ
by
Deep Learning JP
Curriculum Learning (関東CV勉強会)
by
Yoshitaka Ushiku
[DL輪読会]Objects as Points
by
Deep Learning JP
Swin Transformer (ICCV'21 Best Paper) を完璧に理解する資料
by
Yusuke Uchida
【DL輪読会】Visual Classification via Description from Large Language Models (ICLR...
by
Deep Learning JP
【DL輪読会】Dropout Reduces Underfitting
by
Deep Learning JP
【DL輪読会】Scaling Laws for Neural Language Models
by
Deep Learning JP
What's hot
PDF
モデルではなく、データセットを蒸留する
by
Takahiro Kubo
PPTX
【DL輪読会】Flow Matching for Generative Modeling
by
Deep Learning JP
PDF
三次元点群を取り扱うニューラルネットワークのサーベイ
by
Naoya Chiba
PDF
画像の基盤モデルの変遷と研究動向
by
nlab_utokyo
PPTX
【DL輪読会】Towards Understanding Ensemble, Knowledge Distillation and Self-Distil...
by
Deep Learning JP
PDF
計算論的学習理論入門 -PAC学習とかVC次元とか-
by
sleepy_yoshi
PPTX
[DL輪読会]World Models
by
Deep Learning JP
PPTX
Transformerを雰囲気で理解する
by
AtsukiYamaguchi1
PPTX
畳み込みニューラルネットワークの高精度化と高速化
by
Yusuke Uchida
PDF
動画認識における代表的なモデル・データセット(メタサーベイ)
by
cvpaper. challenge
PDF
機械学習で泣かないためのコード設計
by
Takahiro Kubo
PDF
[DL輪読会]Learning Transferable Visual Models From Natural Language Supervision
by
Deep Learning JP
PPTX
[DL輪読会]Grokking: Generalization Beyond Overfitting on Small Algorithmic Datasets
by
Deep Learning JP
PDF
第11回 全日本コンピュータビジョン勉強会(前編)_TableFormer_carnavi.pdf
by
RyoKawanami
PDF
CVIM#11 3. 最小化のための数値計算
by
sleepy_yoshi
PPTX
【DL輪読会】言語以外でのTransformerのまとめ (ViT, Perceiver, Frozen Pretrained Transformer etc)
by
Deep Learning JP
PDF
数学で解き明かす深層学習の原理
by
Taiji Suzuki
PDF
【DL輪読会】Domain Generalization by Learning and Removing Domainspecific Features
by
Deep Learning JP
PPTX
Triplet Loss 徹底解説
by
tancoro
PDF
Transformer メタサーベイ
by
cvpaper. challenge
モデルではなく、データセットを蒸留する
by
Takahiro Kubo
【DL輪読会】Flow Matching for Generative Modeling
by
Deep Learning JP
三次元点群を取り扱うニューラルネットワークのサーベイ
by
Naoya Chiba
画像の基盤モデルの変遷と研究動向
by
nlab_utokyo
【DL輪読会】Towards Understanding Ensemble, Knowledge Distillation and Self-Distil...
by
Deep Learning JP
計算論的学習理論入門 -PAC学習とかVC次元とか-
by
sleepy_yoshi
[DL輪読会]World Models
by
Deep Learning JP
Transformerを雰囲気で理解する
by
AtsukiYamaguchi1
畳み込みニューラルネットワークの高精度化と高速化
by
Yusuke Uchida
動画認識における代表的なモデル・データセット(メタサーベイ)
by
cvpaper. challenge
機械学習で泣かないためのコード設計
by
Takahiro Kubo
[DL輪読会]Learning Transferable Visual Models From Natural Language Supervision
by
Deep Learning JP
[DL輪読会]Grokking: Generalization Beyond Overfitting on Small Algorithmic Datasets
by
Deep Learning JP
第11回 全日本コンピュータビジョン勉強会(前編)_TableFormer_carnavi.pdf
by
RyoKawanami
CVIM#11 3. 最小化のための数値計算
by
sleepy_yoshi
【DL輪読会】言語以外でのTransformerのまとめ (ViT, Perceiver, Frozen Pretrained Transformer etc)
by
Deep Learning JP
数学で解き明かす深層学習の原理
by
Taiji Suzuki
【DL輪読会】Domain Generalization by Learning and Removing Domainspecific Features
by
Deep Learning JP
Triplet Loss 徹底解説
by
tancoro
Transformer メタサーベイ
by
cvpaper. challenge
More from Deep Learning JP
PPTX
【DL輪読会】AdaptDiffuser: Diffusion Models as Adaptive Self-evolving Planners
by
Deep Learning JP
PPTX
【DL輪読会】 "Learning to render novel views from wide-baseline stereo pairs." CVP...
by
Deep Learning JP
PPTX
【DL輪読会】Zero-Shot Dual-Lens Super-Resolution
by
Deep Learning JP
PPTX
【DL輪読会】BloombergGPT: A Large Language Model for Finance arxiv
by
Deep Learning JP
PPTX
【DL輪読会】マルチモーダル LLM
by
Deep Learning JP
PDF
【 DL輪読会】ToolLLM: Facilitating Large Language Models to Master 16000+ Real-wo...
by
Deep Learning JP
PPTX
【DL輪読会】AnyLoc: Towards Universal Visual Place Recognition
by
Deep Learning JP
PDF
【DL輪読会】Can Neural Network Memorization Be Localized?
by
Deep Learning JP
PPTX
【DL輪読会】Hopfield network 関連研究について
by
Deep Learning JP
PPTX
【DL輪読会】SimPer: Simple self-supervised learning of periodic targets( ICLR 2023 )
by
Deep Learning JP
PDF
【DL輪読会】RLCD: Reinforcement Learning from Contrast Distillation for Language M...
by
Deep Learning JP
PDF
【DL輪読会】"Secrets of RLHF in Large Language Models Part I: PPO"
by
Deep Learning JP
PPTX
【DL輪読会】"Language Instructed Reinforcement Learning for Human-AI Coordination "
by
Deep Learning JP
PPTX
【DL輪読会】Llama 2: Open Foundation and Fine-Tuned Chat Models
by
Deep Learning JP
PDF
【DL輪読会】"Learning Fine-Grained Bimanual Manipulation with Low-Cost Hardware"
by
Deep Learning JP
PPTX
【DL輪読会】Parameter is Not All You Need:Starting from Non-Parametric Networks fo...
by
Deep Learning JP
PDF
【DL輪読会】Drag Your GAN: Interactive Point-based Manipulation on the Generative ...
by
Deep Learning JP
PDF
【DL輪読会】Self-Supervised Learning from Images with a Joint-Embedding Predictive...
by
Deep Learning JP
PPTX
【DL輪読会】VIP: Towards Universal Visual Reward and Representation via Value-Impl...
by
Deep Learning JP
PDF
【DL輪読会】Deep Transformers without Shortcuts: Modifying Self-attention for Fait...
by
Deep Learning JP
【DL輪読会】AdaptDiffuser: Diffusion Models as Adaptive Self-evolving Planners
by
Deep Learning JP
【DL輪読会】 "Learning to render novel views from wide-baseline stereo pairs." CVP...
by
Deep Learning JP
【DL輪読会】Zero-Shot Dual-Lens Super-Resolution
by
Deep Learning JP
【DL輪読会】BloombergGPT: A Large Language Model for Finance arxiv
by
Deep Learning JP
【DL輪読会】マルチモーダル LLM
by
Deep Learning JP
【 DL輪読会】ToolLLM: Facilitating Large Language Models to Master 16000+ Real-wo...
by
Deep Learning JP
【DL輪読会】AnyLoc: Towards Universal Visual Place Recognition
by
Deep Learning JP
【DL輪読会】Can Neural Network Memorization Be Localized?
by
Deep Learning JP
【DL輪読会】Hopfield network 関連研究について
by
Deep Learning JP
【DL輪読会】SimPer: Simple self-supervised learning of periodic targets( ICLR 2023 )
by
Deep Learning JP
【DL輪読会】RLCD: Reinforcement Learning from Contrast Distillation for Language M...
by
Deep Learning JP
【DL輪読会】"Secrets of RLHF in Large Language Models Part I: PPO"
by
Deep Learning JP
【DL輪読会】"Language Instructed Reinforcement Learning for Human-AI Coordination "
by
Deep Learning JP
【DL輪読会】Llama 2: Open Foundation and Fine-Tuned Chat Models
by
Deep Learning JP
【DL輪読会】"Learning Fine-Grained Bimanual Manipulation with Low-Cost Hardware"
by
Deep Learning JP
【DL輪読会】Parameter is Not All You Need:Starting from Non-Parametric Networks fo...
by
Deep Learning JP
【DL輪読会】Drag Your GAN: Interactive Point-based Manipulation on the Generative ...
by
Deep Learning JP
【DL輪読会】Self-Supervised Learning from Images with a Joint-Embedding Predictive...
by
Deep Learning JP
【DL輪読会】VIP: Towards Universal Visual Reward and Representation via Value-Impl...
by
Deep Learning JP
【DL輪読会】Deep Transformers without Shortcuts: Modifying Self-attention for Fait...
by
Deep Learning JP
【DL輪読会】事前学習用データセットについて
1.
事前学習用データセットについて Keno Harada, D1,
the University of Tokyo
3.
目次 主要なデータセットについて、どのような構成でどのくらいデー タ量があるか C4, mC4, MassiveText,
RefineWeb, Dolma
4.
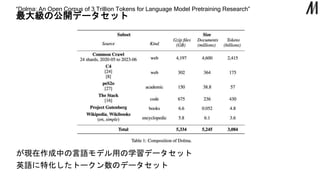
最大級の公開データセット “Dolma: An Open
Corpus of 3 Trillion Tokens for Language Model Pretraining Research” が現在作成中の言語モデル用の学習データセット 英語に特化したトークン数のデータセット
5.
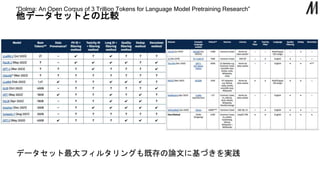
他データセットとの比較 “Dolma: An Open
Corpus of 3 Trillion Tokens for Language Model Pretraining Research” データセット最大フィルタリングも既存の論文に基づきを実践
6.
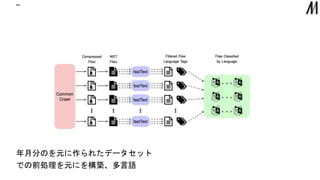
“” 年月分のを元に作られたデータセット での前処理を元にを構築、多言語
7.
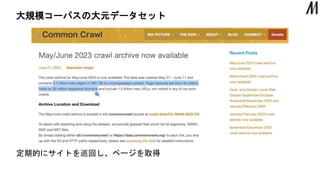
大規模コーパスの大元データセット 定期的にサイトを巡回し、ページを取得
8.
大規模データセットでの事前学習の始まり “” 年月のをもとに作られた英語データセット 前処理 「」「」「」「のような句読点で終わる行のみを採用 文以下のページを削除、単語以上ある行を残す 禁止単語リストの単語を含むページを削除 「」を含む行を削除 「」を含むページを削除 プログラミングにまつわる記号である「」を含むページを削除 文単位で重複判定し、重複分を削除 を使用し英語以外のページを削除
9.
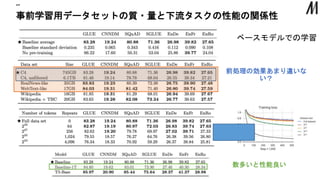
事前学習用データセットの質・量と下流タスクの性能の関係性 “” ベースモデルでの学習 前処理の効果あまり違いな い? 数多いと性能良い
10.
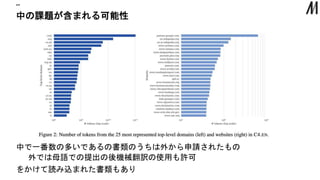
中の課題が含まれる可能性 “” 中で一番数の多いであるの書類のうちは外から申請されたもの 外では母語での提出の後機械翻訳の使用も許可 をかけて読み込まれた書類もあり
11.
中の課題性能を測るベンチマークのデータセットが含まれる “”
12.
中の課題フィルタリングによって除外されたデータセットが有用な 場合も “” フィルタで除外された文書で大部分がな文書は 残りの中には科学医学法律などにまつわる文書も 特定の性的指向をもつ人の文書も除外されている
13.
のパイプラインを参考に作成したマルチリンガルデータセット “” のから抽出、言語からなるデータセット 英語圏の句読点を元にしたフィルタを外す 新たに文字以上からなる文がつ以上ある場合ページを残すフィルタを追加 という言語判定機を用いて以上の閾値で言語判定
14.
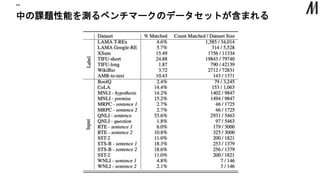
データセットの課題 “” 各言語のデータセットからランダムにサンプルして質を評価 は言語コードと異なるデータが文字として意味がないものが 日本語は良いデータが
15.
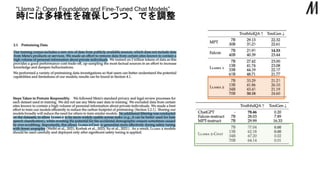
超えの巨大データセット非公開 “” によって性能向上を確認 はで学習
16.
のみからのデータセットを構築 “” 同じパイプラインを通せば、のみからの日本語データが手に入りそう
17.
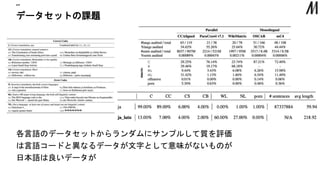
の効果をタスクや判定生成で検証が存在 “” に対して追加のダブり削除、施す どちらのも分類器から出力されるスコアをもとに実施 で検証
18.
時には多様性を確保しつつ、でを調整 “Llama 2: Open
Foundation and Fine-Tuned Chat Models”
19.
最大級の公開データセット “Dolma: An Open
Corpus of 3 Trillion Tokens for Language Model Pretraining Research” の実装も一部公開
20.
本発表のまとめ 事前学習データセットについてどのように集められ、より良い学習のための工夫の概 観を掴んだ 実際に前処理して学習させてみたくなってきましたよね??? そんなあなたへ: LLM講義の演習・課題で思う存分楽しめます
Editor's Notes
#4
基盤モデルの概要 (20P) 事例集 言語モデルにおける基盤モデル Prompting (20P ~ 25P) In Context Learning Demonstrations Instruction Trigger token td,lr 攻撃的なセンテンスを出させるToken 推論能力 Chain of though prompting Self Consistency Toolの利用,外部知識の参照 Instruction Tuning RLFH Contamination How LLM learn from context? Scaling Law 概要 1例で詳解 冪乗則とは:Scale Free 対数での線形性を満たすようなデータは存在する Discramer:Power Low Region Emergent Ability Grokking 研究から開発へ GPT4の例 モデルの選択 LSTM vs. Transformer 失敗する例もあることに注意 言語モデル以外でのスケール則 Vision Language Model Efficient Net Etc. スケールさせる試み モデルの巨大化 PaLM, MoE:Constrained Routed Language Modelsのスケール則 データを増やす Chinchilla The Pile Dataset, Falcon 40B データの不足 Scaling Law with Dataset Distillation 有効計算量を増やす これって何かある?(目的関数を変える系はあるけど) エポックを増やすとどうなるか?
Download












![SSII2022 [TS1] Transformerの最前線〜 畳込みニューラルネットワークの先へ 〜](https://cdn.slidesharecdn.com/ss_thumbnails/ts120220608ssiitransformerr2-220607054025-3adacf07-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]ドメイン転移と不変表現に関するサーベイ](https://cdn.slidesharecdn.com/ss_thumbnails/20190614iwasawa-190614005939-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]Objects as Points](https://cdn.slidesharecdn.com/ss_thumbnails/20190614centernetkuboshizuma-190614004246-thumbnail.jpg?width=640&height=640&fit=bounds)










![[DL輪読会]World Models](https://cdn.slidesharecdn.com/ss_thumbnails/20180427-180427003856-thumbnail.jpg?width=640&height=640&fit=bounds)




![[DL輪読会]Learning Transferable Visual Models From Natural Language Supervision](https://cdn.slidesharecdn.com/ss_thumbnails/dlkobayashi0115-210115012308-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]Grokking: Generalization Beyond Overfitting on Small Algorithmic Datasets](https://cdn.slidesharecdn.com/ss_thumbnails/20220325okimura-220405024717-thumbnail.jpg?width=640&height=640&fit=bounds)


























