[DL輪読会]data2vec: A General Framework for Self-supervised Learning in Speech, Vision and Language
1.
1
DEEP LEARNING JP
[DLPapers]
http://deeplearning.jp/
“data2vec: A General Framework for
Self-supervised Learning in Speech,Vision and Language ”
Naoki Nonaka
2022/2/2
背景: モダリティ非依存の自己教師あり学習
2022/2/2 4
p自己教師あり学習の手法の成功
p これまでの自己教師あり学習はモダリティ依存的
p モダリティ依存的である必然性はないはず
(人間の学習,Percieverの事例)
モダリティ非依存の自己教師あり学習手法の開発
5.
提案手法:data2vec
2022/2/2 5
p Maskedprediction + 潜在表現の学習
p TeacherとStudentの2つのモードを利用
n Teacher: 完全な入力データから表現を取得
n Student: マスクされた入力から完全なデータの表現を予測
p 先行研究との相違点:連続な潜在表現の学習 + 最終層以外の表現の利用
提案手法の概念図: data2vecは異なるモダリティのデータに対しても同一の学習過程で学習
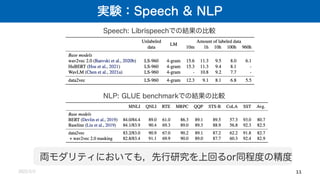
実験:Vision
2022/2/2 9
Vision taskの学習条件
p224 x 224 pixelを16 x 16のpatchに分割してEmbed
p 各patchを線形変換後,系列としてTransformerに入力
p MaskingはBEiTと同じ方法
p Random resize, horizontal flip, color jitteringを使用
p Adam optimizer + cosine scheduleで学習
![1
DEEP LEARNING JP
[DL Papers]
http://deeplearning.jp/
“data2vec: A General Framework for
Self-supervised Learning in Speech,Vision and Language ”
Naoki Nonaka
2022/2/2](https://image.slidesharecdn.com/220204nonakadl1-220204025334/85/DL-data2vec-A-General-Framework-for-Self-supervised-Learning-in-Speech-Vision-and-Language-1-320.jpg)
![1
DEEP LEARNING JP
[DL Papers]
http://deeplearning.jp/
“data2vec: A General Framework for
Self-supervised Learning in Speech,Vision and Language ”
Naoki Nonaka
2022/2/2](https://image.slidesharecdn.com/220204nonakadl1-220204025334/75/DL-data2vec-A-General-Framework-for-Self-supervised-Learning-in-Speech-Vision-and-Language-1-2048.jpg)




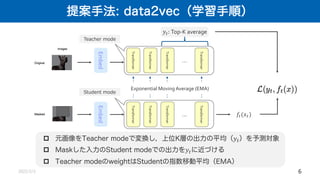
![提案手法: data2vec(学習手順)
2022/2/2 7
損失関数:Smooth L1 loss
L1, L2損失とSmooth L1損失の形状比較([2]より)](https://image.slidesharecdn.com/220204nonakadl1-220204025334/85/DL-data2vec-A-General-Framework-for-Self-supervised-Learning-in-Speech-Vision-and-Language-7-320.jpg)



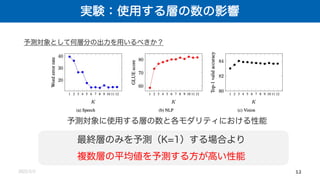
![実験:予測対象とする表現の比較
2022/2/2 13
FFNを予測対象とする場合の精度が最もよい Transformer encoder
([1]より改変)
①
②
③
④
①
②
③
④
Transformer内の表現のうち,どの表現を予測対象とすべきか?
Transformer内の表現と
LibrispeechにおけるWERの関係](https://image.slidesharecdn.com/220204nonakadl1-220204025334/85/DL-data2vec-A-General-Framework-for-Self-supervised-Learning-in-Speech-Vision-and-Language-13-320.jpg)



![[DL輪読会]Set Transformer: A Framework for Attention-based Permutation-Invariant...](https://cdn.slidesharecdn.com/ss_thumbnails/20200221settransformer-200221020423-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]Object-Centric Learning with Slot Attention](https://cdn.slidesharecdn.com/ss_thumbnails/dlkobayashi0717-200717023021-thumbnail.jpg?width=640&height=640&fit=bounds)





![[DL輪読会]GLIDE: Guided Language to Image Diffusion for Generation and Editing](https://cdn.slidesharecdn.com/ss_thumbnails/glide2-220107030326-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]Grokking: Generalization Beyond Overfitting on Small Algorithmic Datasets](https://cdn.slidesharecdn.com/ss_thumbnails/20220325okimura-220405024717-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]Life-Long Disentangled Representation Learning with Cross-Domain Laten...](https://cdn.slidesharecdn.com/ss_thumbnails/20180914iwasawa-180919025635-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]Learning Latent Dynamics for Planning from Pixels](https://cdn.slidesharecdn.com/ss_thumbnails/taniguchi20181221-190104064850-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]NVAE: A Deep Hierarchical Variational Autoencoder](https://cdn.slidesharecdn.com/ss_thumbnails/nvaeadeephierarchicalvariationalautoencoder-201113004930-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]“SimPLe”,“Improved Dynamics Model”,“PlaNet” 近年のVAEベース系列モデルの進展とそのモデルベース...](https://cdn.slidesharecdn.com/ss_thumbnails/20190426akuzawa-190426020057-thumbnail.jpg?width=640&height=640&fit=bounds)




















































