参考文献
• Hafner, Danijar,et al. "Dream to Control: Learning Behaviors by Latent Imagination."
International Conference on Learning Representations. 2020.
• Gelada, C., Kumar, S., Buckman, J., Nachum, O., and Belle- mare, M. G. Deepmdp:
Learning continuous latent space models for representation learning., International
Conference on Machine Learning, 2019.
• Zhang, A., Lyle, C., Sodhani, S., Filos, A., Kwiatkowska, M., Pineau, J., Gal, Y., and Precup,
D. Invariant causal prediction for block mdps. In International Conference on Machine
Learning, pp. 11214‒11224. PMLR, 2020
• Zhang, A., McAllister, R. T., Calandra, R., Gal, Y., and Levine, S. Learning invariant
representations for reinforcement learning without reconstruction. International
Conference on Learning Representations, 2021.
![DEEP LEARNING JP
[DL Papers]
http://deeplearning.jp/
Learning Task Informed Abstractions
発表者: 阿久澤圭 (松尾研D3)](https://image.slidesharecdn.com/20210709akuzawa-210709021836/85/DL-Learning-Task-Informed-Abstractions-1-320.jpg)
![DEEP LEARNING JP
[DL Papers]
http://deeplearning.jp/
Learning Task Informed Abstractions
発表者: 阿久澤圭 (松尾研D3)](https://image.slidesharecdn.com/20210709akuzawa-210709021836/75/DL-Learning-Task-Informed-Abstractions-1-2048.jpg)



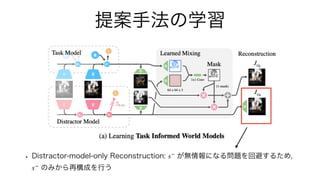
![関連研究: Dreamer [Hafner et. al. 2020]
• (a) 画像・観測予測によって表現(緑色の点)を学習
• (b) 表現を入力に取る価値関数・方策を訓練(データはモデル自身から生成)
• 欠点(発表論文での指摘): 表現は,タスク関連/非関連の情報を分離できていない](https://image.slidesharecdn.com/20210709akuzawa-210709021836/85/DL-Learning-Task-Informed-Abstractions-6-320.jpg)
![関連研究: DeepMDP [Gelada et. al. 2019]
• 二つの損失関数で表現学習
• 報酬の予測
• 次の時刻の表現(の分布)の予測
• メリット:
• 画像予測を用いないため,表現は
distractor-free
• デメリット(発表論文の指摘):
• 画像予測を用いないと,学習が難しい](https://image.slidesharecdn.com/20210709akuzawa-210709021836/85/DL-Learning-Task-Informed-Abstractions-7-320.jpg)
![関連研究: MISA [Zhang et. al. 2020]
• 提案:
• グラフィカルモデル上で状態を
タスク関連・非関連に分離する
ことを提案
• 欠点(紹介論文の指摘):
• アイデア自体は紹介論文と同じ
• practicalな手法の提案や,複雑
な画像観測を使った実験がない](https://image.slidesharecdn.com/20210709akuzawa-210709021836/85/DL-Learning-Task-Informed-Abstractions-8-320.jpg)
![関連研究: DBC [Zhang et. al. 2021]
• 提案:
• bisimulation metricsを用
いた,タスク関連・非関連
の特徴量の分離
• DeepMDPと似ている(画
像予測を学習に用いない)
• 欠点(発表論文の指摘):
• 画像予測を用いないと,学
習が難しい](https://image.slidesharecdn.com/20210709akuzawa-210709021836/85/DL-Learning-Task-Informed-Abstractions-9-320.jpg)







![[DL輪読会]“SimPLe”,“Improved Dynamics Model”,“PlaNet” 近年のVAEベース系列モデルの進展とそのモデルベース...](https://cdn.slidesharecdn.com/ss_thumbnails/20190426akuzawa-190426020057-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DL輪読会]Dream to Control: Learning Behaviors by Latent Imagination](https://cdn.slidesharecdn.com/ss_thumbnails/20200313furutav2-200313025657-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]近年のオフライン強化学習のまとめ —Offline Reinforcement Learning: Tutorial, Review, an...](https://cdn.slidesharecdn.com/ss_thumbnails/20200626journalclubpub-200630064755-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]World Models](https://cdn.slidesharecdn.com/ss_thumbnails/20180427-180427003856-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]Learning Latent Dynamics for Planning from Pixels](https://cdn.slidesharecdn.com/ss_thumbnails/taniguchi20181221-190104064850-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]`強化学習のための状態表現学習 -より良い「世界モデル」の獲得に向けて-](https://cdn.slidesharecdn.com/ss_thumbnails/20181026staterepresenration-181127055206-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]Temporal Abstraction in NeurIPS2019](https://cdn.slidesharecdn.com/ss_thumbnails/20191115-191112082849-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]A Bayesian Perspective on Generalization and Stochastic Gradient Descent](https://cdn.slidesharecdn.com/ss_thumbnails/20171106dl2-171108033614-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]逆強化学習とGANs](https://cdn.slidesharecdn.com/ss_thumbnails/irlgans-171128063119-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]Meta Reinforcement Learning](https://cdn.slidesharecdn.com/ss_thumbnails/metarl-190201005548-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DL輪読会]Focal Loss for Dense Object Detection](https://cdn.slidesharecdn.com/ss_thumbnails/focalloss-180208092846-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]Wasserstein GAN/Towards Principled Methods for Training Generative Adv...](https://cdn.slidesharecdn.com/ss_thumbnails/wgan-1-170224021826-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]Life-Long Disentangled Representation Learning with Cross-Domain Laten...](https://cdn.slidesharecdn.com/ss_thumbnails/20180914iwasawa-180919025635-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DL輪読会]Decision Transformer: Reinforcement Learning via Sequence Modeling](https://cdn.slidesharecdn.com/ss_thumbnails/decisiontransformer20210709zhangxin-210709021501-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]Imagination-Augmented Agents for Deep Reinforcement Learning / Learnin...](https://cdn.slidesharecdn.com/ss_thumbnails/dlhacksshioya201707281-170728054152-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]High-Fidelity Image Generation with Fewer Labels](https://cdn.slidesharecdn.com/ss_thumbnails/190315dlseminargan-190315004124-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]相互情報量最大化による表現学習](https://cdn.slidesharecdn.com/ss_thumbnails/20190913iwasawa-190913002312-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]Shaping Belief States with Generative Environment Models for RL](https://cdn.slidesharecdn.com/ss_thumbnails/20190705suzuki-191204061058-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DL輪読会]Temporal DifferenceVariationalAuto-Encoder](https://cdn.slidesharecdn.com/ss_thumbnails/20181130new-190205051636-thumbnail.jpg?width=640&height=640&fit=bounds)































