Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
EN
Uploaded by
Deep Learning JP
PDF, PPTX
19,636 views
[DL輪読会]Wasserstein GAN/Towards Principled Methods for Training Generative Adversarial Networks
2017/2/24 Deep Learning JP: http://deeplearning.jp/seminar-2/
Technology
◦
Related topics:
Deep Learning
•
Read more
35
Save
Share
Embed
Embed presentation
Download
Download as PDF, PPTX
1
/ 29
2
/ 29
3
/ 29
4
/ 29
5
/ 29
6
/ 29
7
/ 29
8
/ 29
9
/ 29
10
/ 29
11
/ 29
12
/ 29
13
/ 29
14
/ 29
15
/ 29
16
/ 29
17
/ 29
18
/ 29
19
/ 29
20
/ 29
21
/ 29
22
/ 29
23
/ 29
24
/ 29
25
/ 29
26
/ 29
27
/ 29
28
/ 29
29
/ 29
More Related Content
PDF
グラフィカル Lasso を用いた異常検知
by
Yuya Takashina
PPTX
[DL輪読会]相互情報量最大化による表現学習
by
Deep Learning JP
PDF
[DL輪読会]近年のエネルギーベースモデルの進展
by
Deep Learning JP
PDF
[DL輪読会]Understanding Black-box Predictions via Influence Functions
by
Deep Learning JP
PPTX
深層学習の数理:カーネル法, スパース推定との接点
by
Taiji Suzuki
PPTX
Graph convolution (スペクトルアプローチ)
by
yukihiro domae
PPTX
Curriculum Learning (関東CV勉強会)
by
Yoshitaka Ushiku
PDF
BERT入門
by
Ken'ichi Matsui
グラフィカル Lasso を用いた異常検知
by
Yuya Takashina
[DL輪読会]相互情報量最大化による表現学習
by
Deep Learning JP
[DL輪読会]近年のエネルギーベースモデルの進展
by
Deep Learning JP
[DL輪読会]Understanding Black-box Predictions via Influence Functions
by
Deep Learning JP
深層学習の数理:カーネル法, スパース推定との接点
by
Taiji Suzuki
Graph convolution (スペクトルアプローチ)
by
yukihiro domae
Curriculum Learning (関東CV勉強会)
by
Yoshitaka Ushiku
BERT入門
by
Ken'ichi Matsui
What's hot
PDF
Deeplearning輪読会
by
正志 坪坂
PDF
Optimizer入門&最新動向
by
Motokawa Tetsuya
PPTX
Swin Transformer (ICCV'21 Best Paper) を完璧に理解する資料
by
Yusuke Uchida
PDF
サポートベクターマシン(SVM)の数学をみんなに説明したいだけの会
by
Kenyu Uehara
PPTX
[Ridge-i 論文よみかい] Wasserstein auto encoder
by
Masanari Kimura
PDF
【DL輪読会】How Much Can CLIP Benefit Vision-and-Language Tasks?
by
Deep Learning JP
PDF
ドメイン適応の原理と応用
by
Yoshitaka Ushiku
PDF
PRML学習者から入る深層生成モデル入門
by
tmtm otm
PPTX
[DLHacks]StyleGANとBigGANのStyle mixing, morphing
by
Deep Learning JP
PDF
[DL輪読会] Spectral Norm Regularization for Improving the Generalizability of De...
by
Deep Learning JP
PDF
Active Learning 入門
by
Shuyo Nakatani
PDF
Transformerを多層にする際の勾配消失問題と解決法について
by
Sho Takase
PDF
実装レベルで学ぶVQVAE
by
ぱんいち すみもと
PDF
SSII2021 [OS2-02] 深層学習におけるデータ拡張の原理と最新動向
by
SSII
PDF
[DL Hacks]Variational Approaches For Auto-Encoding Generative Adversarial Ne...
by
Deep Learning JP
PDF
SSII2022 [TS1] Transformerの最前線〜 畳込みニューラルネットワークの先へ 〜
by
SSII
PDF
論文紹介 Pixel Recurrent Neural Networks
by
Seiya Tokui
PPTX
backbone としての timm 入門
by
Takuji Tahara
PDF
強化学習その2
by
nishio
PPTX
【DL輪読会】Flamingo: a Visual Language Model for Few-Shot Learning 画像×言語の大規模基盤モ...
by
Deep Learning JP
Deeplearning輪読会
by
正志 坪坂
Optimizer入門&最新動向
by
Motokawa Tetsuya
Swin Transformer (ICCV'21 Best Paper) を完璧に理解する資料
by
Yusuke Uchida
サポートベクターマシン(SVM)の数学をみんなに説明したいだけの会
by
Kenyu Uehara
[Ridge-i 論文よみかい] Wasserstein auto encoder
by
Masanari Kimura
【DL輪読会】How Much Can CLIP Benefit Vision-and-Language Tasks?
by
Deep Learning JP
ドメイン適応の原理と応用
by
Yoshitaka Ushiku
PRML学習者から入る深層生成モデル入門
by
tmtm otm
[DLHacks]StyleGANとBigGANのStyle mixing, morphing
by
Deep Learning JP
[DL輪読会] Spectral Norm Regularization for Improving the Generalizability of De...
by
Deep Learning JP
Active Learning 入門
by
Shuyo Nakatani
Transformerを多層にする際の勾配消失問題と解決法について
by
Sho Takase
実装レベルで学ぶVQVAE
by
ぱんいち すみもと
SSII2021 [OS2-02] 深層学習におけるデータ拡張の原理と最新動向
by
SSII
[DL Hacks]Variational Approaches For Auto-Encoding Generative Adversarial Ne...
by
Deep Learning JP
SSII2022 [TS1] Transformerの最前線〜 畳込みニューラルネットワークの先へ 〜
by
SSII
論文紹介 Pixel Recurrent Neural Networks
by
Seiya Tokui
backbone としての timm 入門
by
Takuji Tahara
強化学習その2
by
nishio
【DL輪読会】Flamingo: a Visual Language Model for Few-Shot Learning 画像×言語の大規模基盤モ...
by
Deep Learning JP
Viewers also liked
PDF
Generative Adversarial Networks (GAN) の学習方法進展・画像生成・教師なし画像変換
by
Koichi Hamada
PPTX
[DL輪読会]Exploiting Cyclic Symmetry in Convolutional Neural Networks
by
Deep Learning JP
PDF
[DL輪読会]Combining Fully Convolutional and Recurrent Neural Networks for 3D Bio...
by
Deep Learning JP
PDF
Language as a Latent Variable: Discrete Generative Models for Sentence Compre...
by
Toru Fujino
PDF
[DL輪読会]Generative Models of Visually Grounded Imagination
by
Deep Learning JP
PDF
[DL輪読会]StackGAN: Text to Photo-realistic Image Synthesis with Stacked Generat...
by
Deep Learning JP
PDF
形態素解析も辞書も言語モデルもいらないend-to-end音声認識
by
Tomoki Hayashi
PPTX
CNNの可視化手法Grad-CAMの紹介~CNNさん、あなたはどこを見ているの?~ | OHS勉強会#6
by
Toshinori Hanya
PPTX
強化学習を利用した自律型GameAIの取り組み ~高速自動プレイによるステージ設計支援~ #denatechcon
by
DeNA
PPTX
[DL輪読会] GAN系の研究まとめ (NIPS2016とICLR2016が中心)
by
Yusuke Iwasawa
PPTX
「人工知能」の表紙に関するTweetの分析・続報
by
Fujio Toriumi
PDF
[DL輪読会]Adversarial Feature Matching for Text Generation
by
Deep Learning JP
PPTX
Twitter炎上分析事例 2014年
by
Takeshi Sakaki
PPTX
第35回 強化学習勉強会・論文紹介 [Lantao Yu : 2016]
by
Takayuki Sekine
PDF
最先端NLP勉強会 “Learning Language Games through Interaction” Sida I. Wang, Percy L...
by
Yuya Unno
PDF
オープンソースを利用した新時代を生き抜くためのデータ解析
by
nakapara
PDF
Generative adversarial networks
by
Shuyo Nakatani
PPTX
Approximate Scalable Bounded Space Sketch for Large Data NLP
by
Koji Matsuda
PDF
Argmax Operations in NLP
by
Hitoshi Nishikawa
PDF
2016.03.11 「論文に書(け|か)ない自然言語処理」 ソーシャルメディア分析サービスにおけるNLPに関する諸問題について by ホットリンク 公開用
by
Takeshi Sakaki
Generative Adversarial Networks (GAN) の学習方法進展・画像生成・教師なし画像変換
by
Koichi Hamada
[DL輪読会]Exploiting Cyclic Symmetry in Convolutional Neural Networks
by
Deep Learning JP
[DL輪読会]Combining Fully Convolutional and Recurrent Neural Networks for 3D Bio...
by
Deep Learning JP
Language as a Latent Variable: Discrete Generative Models for Sentence Compre...
by
Toru Fujino
[DL輪読会]Generative Models of Visually Grounded Imagination
by
Deep Learning JP
[DL輪読会]StackGAN: Text to Photo-realistic Image Synthesis with Stacked Generat...
by
Deep Learning JP
形態素解析も辞書も言語モデルもいらないend-to-end音声認識
by
Tomoki Hayashi
CNNの可視化手法Grad-CAMの紹介~CNNさん、あなたはどこを見ているの?~ | OHS勉強会#6
by
Toshinori Hanya
強化学習を利用した自律型GameAIの取り組み ~高速自動プレイによるステージ設計支援~ #denatechcon
by
DeNA
[DL輪読会] GAN系の研究まとめ (NIPS2016とICLR2016が中心)
by
Yusuke Iwasawa
「人工知能」の表紙に関するTweetの分析・続報
by
Fujio Toriumi
[DL輪読会]Adversarial Feature Matching for Text Generation
by
Deep Learning JP
Twitter炎上分析事例 2014年
by
Takeshi Sakaki
第35回 強化学習勉強会・論文紹介 [Lantao Yu : 2016]
by
Takayuki Sekine
最先端NLP勉強会 “Learning Language Games through Interaction” Sida I. Wang, Percy L...
by
Yuya Unno
オープンソースを利用した新時代を生き抜くためのデータ解析
by
nakapara
Generative adversarial networks
by
Shuyo Nakatani
Approximate Scalable Bounded Space Sketch for Large Data NLP
by
Koji Matsuda
Argmax Operations in NLP
by
Hitoshi Nishikawa
2016.03.11 「論文に書(け|か)ない自然言語処理」 ソーシャルメディア分析サービスにおけるNLPに関する諸問題について by ホットリンク 公開用
by
Takeshi Sakaki
Similar to [DL輪読会]Wasserstein GAN/Towards Principled Methods for Training Generative Adversarial Networks
PPTX
0728 論文紹介第三回
by
Kohei Wakamatsu
PPTX
論文紹介:Generative Adversarial Networks
by
Wisteria
PDF
Unified Expectation Maximization
by
Koji Matsuda
PPTX
深層学習の数理
by
Taiji Suzuki
PDF
PRML輪講用資料10章(パターン認識と機械学習,近似推論法)
by
Toshiyuki Shimono
PDF
[DL輪読会]Scalable Training of Inference Networks for Gaussian-Process Models
by
Deep Learning JP
PDF
20170422 数学カフェ Part1
by
Kenta Oono
PPTX
PRML第6章「カーネル法」
by
Keisuke Sugawara
PDF
データサイエンス概論第一=8 パターン認識と深層学習
by
Seiichi Uchida
PDF
20170422 数学カフェ Part2
by
Kenta Oono
PDF
[DL輪読会]Convolutional Conditional Neural Processesと Neural Processes Familyの紹介
by
Deep Learning JP
PPTX
猫でも分かるVariational AutoEncoder
by
Sho Tatsuno
PDF
Deep Learningの基礎と応用
by
Seiya Tokui
PDF
PRML復々習レーン#9 前回までのあらすじ
by
sleepy_yoshi
PPTX
[DL輪読会]Temporal DifferenceVariationalAuto-Encoder
by
Deep Learning JP
PDF
Deep Learning 20章 輪講会 資料
by
sorashido
PDF
Up to GLOW
by
Shunsuke NAKATSUKA
PPTX
【招待講演】パラメータ制約付き行列分解のベイズ汎化誤差解析【StatsML若手シンポ2020】
by
Naoki Hayashi
PDF
行列およびテンソルデータに対する機械学習(数理助教の会 2011/11/28)
by
ryotat
PDF
How to study stat
by
Ak Ok
0728 論文紹介第三回
by
Kohei Wakamatsu
論文紹介:Generative Adversarial Networks
by
Wisteria
Unified Expectation Maximization
by
Koji Matsuda
深層学習の数理
by
Taiji Suzuki
PRML輪講用資料10章(パターン認識と機械学習,近似推論法)
by
Toshiyuki Shimono
[DL輪読会]Scalable Training of Inference Networks for Gaussian-Process Models
by
Deep Learning JP
20170422 数学カフェ Part1
by
Kenta Oono
PRML第6章「カーネル法」
by
Keisuke Sugawara
データサイエンス概論第一=8 パターン認識と深層学習
by
Seiichi Uchida
20170422 数学カフェ Part2
by
Kenta Oono
[DL輪読会]Convolutional Conditional Neural Processesと Neural Processes Familyの紹介
by
Deep Learning JP
猫でも分かるVariational AutoEncoder
by
Sho Tatsuno
Deep Learningの基礎と応用
by
Seiya Tokui
PRML復々習レーン#9 前回までのあらすじ
by
sleepy_yoshi
[DL輪読会]Temporal DifferenceVariationalAuto-Encoder
by
Deep Learning JP
Deep Learning 20章 輪講会 資料
by
sorashido
Up to GLOW
by
Shunsuke NAKATSUKA
【招待講演】パラメータ制約付き行列分解のベイズ汎化誤差解析【StatsML若手シンポ2020】
by
Naoki Hayashi
行列およびテンソルデータに対する機械学習(数理助教の会 2011/11/28)
by
ryotat
How to study stat
by
Ak Ok
More from Deep Learning JP
PPTX
【DL輪読会】AdaptDiffuser: Diffusion Models as Adaptive Self-evolving Planners
by
Deep Learning JP
PPTX
【DL輪読会】事前学習用データセットについて
by
Deep Learning JP
PPTX
【DL輪読会】 "Learning to render novel views from wide-baseline stereo pairs." CVP...
by
Deep Learning JP
PPTX
【DL輪読会】Zero-Shot Dual-Lens Super-Resolution
by
Deep Learning JP
PPTX
【DL輪読会】BloombergGPT: A Large Language Model for Finance arxiv
by
Deep Learning JP
PPTX
【DL輪読会】マルチモーダル LLM
by
Deep Learning JP
PDF
【 DL輪読会】ToolLLM: Facilitating Large Language Models to Master 16000+ Real-wo...
by
Deep Learning JP
PPTX
【DL輪読会】AnyLoc: Towards Universal Visual Place Recognition
by
Deep Learning JP
PDF
【DL輪読会】Can Neural Network Memorization Be Localized?
by
Deep Learning JP
PPTX
【DL輪読会】Hopfield network 関連研究について
by
Deep Learning JP
PPTX
【DL輪読会】SimPer: Simple self-supervised learning of periodic targets( ICLR 2023 )
by
Deep Learning JP
PDF
【DL輪読会】RLCD: Reinforcement Learning from Contrast Distillation for Language M...
by
Deep Learning JP
PDF
【DL輪読会】"Secrets of RLHF in Large Language Models Part I: PPO"
by
Deep Learning JP
PPTX
【DL輪読会】"Language Instructed Reinforcement Learning for Human-AI Coordination "
by
Deep Learning JP
PPTX
【DL輪読会】Llama 2: Open Foundation and Fine-Tuned Chat Models
by
Deep Learning JP
PDF
【DL輪読会】"Learning Fine-Grained Bimanual Manipulation with Low-Cost Hardware"
by
Deep Learning JP
PPTX
【DL輪読会】Parameter is Not All You Need:Starting from Non-Parametric Networks fo...
by
Deep Learning JP
PDF
【DL輪読会】Drag Your GAN: Interactive Point-based Manipulation on the Generative ...
by
Deep Learning JP
PDF
【DL輪読会】Self-Supervised Learning from Images with a Joint-Embedding Predictive...
by
Deep Learning JP
PPTX
【DL輪読会】Towards Understanding Ensemble, Knowledge Distillation and Self-Distil...
by
Deep Learning JP
【DL輪読会】AdaptDiffuser: Diffusion Models as Adaptive Self-evolving Planners
by
Deep Learning JP
【DL輪読会】事前学習用データセットについて
by
Deep Learning JP
【DL輪読会】 "Learning to render novel views from wide-baseline stereo pairs." CVP...
by
Deep Learning JP
【DL輪読会】Zero-Shot Dual-Lens Super-Resolution
by
Deep Learning JP
【DL輪読会】BloombergGPT: A Large Language Model for Finance arxiv
by
Deep Learning JP
【DL輪読会】マルチモーダル LLM
by
Deep Learning JP
【 DL輪読会】ToolLLM: Facilitating Large Language Models to Master 16000+ Real-wo...
by
Deep Learning JP
【DL輪読会】AnyLoc: Towards Universal Visual Place Recognition
by
Deep Learning JP
【DL輪読会】Can Neural Network Memorization Be Localized?
by
Deep Learning JP
【DL輪読会】Hopfield network 関連研究について
by
Deep Learning JP
【DL輪読会】SimPer: Simple self-supervised learning of periodic targets( ICLR 2023 )
by
Deep Learning JP
【DL輪読会】RLCD: Reinforcement Learning from Contrast Distillation for Language M...
by
Deep Learning JP
【DL輪読会】"Secrets of RLHF in Large Language Models Part I: PPO"
by
Deep Learning JP
【DL輪読会】"Language Instructed Reinforcement Learning for Human-AI Coordination "
by
Deep Learning JP
【DL輪読会】Llama 2: Open Foundation and Fine-Tuned Chat Models
by
Deep Learning JP
【DL輪読会】"Learning Fine-Grained Bimanual Manipulation with Low-Cost Hardware"
by
Deep Learning JP
【DL輪読会】Parameter is Not All You Need:Starting from Non-Parametric Networks fo...
by
Deep Learning JP
【DL輪読会】Drag Your GAN: Interactive Point-based Manipulation on the Generative ...
by
Deep Learning JP
【DL輪読会】Self-Supervised Learning from Images with a Joint-Embedding Predictive...
by
Deep Learning JP
【DL輪読会】Towards Understanding Ensemble, Knowledge Distillation and Self-Distil...
by
Deep Learning JP
[DL輪読会]Wasserstein GAN/Towards Principled Methods for Training Generative Adversarial Networks
1.
Towards Principled Methods for Training Generative Adversarial Networks Wasserstein GAN KEISUKE FUKUTA
2.
論文情報 Towards Principled Methods for Training Generative Adversarial Networks • ICLR 2017 採択論文 • 数学強者がGANを解析してみましたという論文 Wasserstein GAN •
3人中2人↑と同じ著者 • 解析した知見を利用して実用的なGANを提案
3.
生成モデル • 未知のデータ分布𝑃" 𝑥
と モデルの分布𝑃% 𝑥 を近づける • よくある方法では、尤度の最大化 ≅ Kullback-Leibler (KL) divergence の最小化 VAEではガウス分布を仮定しているのでKLが具体的に計算可能 GANでは分布を仮定していない
4.
Kullback-Leibler (KL) divergence 𝐾𝐿(𝑃"||𝑃%) = ∫
𝑃" 𝑥 𝑙𝑜𝑔 12 3 14(3) 𝑑𝑥3 = 𝔼3~12 [𝑙𝑜𝑔 12 3 14(3) ] (KLは非対称 ) 𝑃% 𝑥 > 0 𝑎𝑛𝑑 𝑃" 𝑥 → 0 • 真のデータにないようなデータを生成 • Fake looking • 𝐾𝐿 → 0 𝑃" 𝑥 > 0 𝑎𝑛𝑑 𝑃% 𝑥 → 0 • 真のデータを生成する確率が低い • Mode dropping • 𝐾𝐿 → ∞
5.
Jensen-Shannon Divergence 𝐽𝑆𝐷(𝑃"| 𝑃% = C D 𝐾𝐿 (𝑃"|
𝑃E + C D 𝐾𝐿(𝑃%||𝑃E) , (𝑃E= 14G12 D ) • KLが非対称で不便なので対称にしたもの • GANは実質これを最小化することで真のデータの分布を学習している
6.
GAN Original Loss 𝐿 𝐷, 𝑔I
= 𝔼3~12 [log 𝐷(𝑥)] + 𝔼3~14 [log(1 − 𝐷 𝑥 )] (1) Dは式(1)を最大化、Gは式(1)を最小化 明らかに、𝐷∗ 𝑥 = 12 3 12 3 G14(3) のとき最大 → 𝐿 𝐷∗ , 𝑔I = 2 𝐽𝑆𝐷(𝑃"| 𝑃% − 2log2 2 すなわち • Dは𝐽𝑆𝐷を近似するよう学習 • GはDによって近似された𝐽𝑆𝐷を最小化するように学習
7.
GANの問題 理想的には、 1. Dを精一杯学習させて精度よくJSDを近似する 2. Gを学習させる を繰り返すのが良いのでは? →
うまくいかない - log(D(x))にするという小手先のトリックもあるが、それでも不安定
8.
Question • なぜDiscriminatorを更新すればするほどGeneratorの更新が うまくいかなくなるのか • なぜGeneratorの更新式の-
log(D(x))トリックで多少うまくいくのか ◦ 実質何を最適化しているのか (JSDと似ているのか?) • なぜGANの学習はそんなに不安定なのか • どうにか回避できないのか
9.
Sources of Instability そもそも、Gを固定してDを学習させた場合 min − 𝐿 𝐷,
𝑔I = min − 𝔼3~12 [log 𝐷(𝑥)] + 𝔼3~14 [log(1 − 𝐷 𝑥 )] = − 2 𝐽𝑆𝐷(𝑃"| 𝑃% + 2log2 であってほしい → だが実際にはどこまでも小さくなり最終的には 0 に → なぜ??可能性としては、、 • 分布が不連続 • 互いに素な台(support)が存在する
10.
Sources of Instability • 真のデータ分布 𝑃"は低次元の多様体空間上に存在する • Ex. 256 ×
256の画像だったら、256*256次元空間すべてに配置されるというよりは 低次元な空間に集中しているはず • 生成分布𝑃%も同様 • 実際GANではランダムに生成された 𝑧 ~ 𝑃 𝑧 になんらかの関数を適用したもの 𝑔 𝑍 • 多くのケースでは𝑍の次元数 (≅ 100)はサンプル𝑋のそれよりはるかに小さい • すなわち低次元多様体空間上に存在
11.
Sources of Instability optimal discriminatorが存在するための条件に関する証明が続きます (全然追えませんでした) 最終的には、このどちらかが成り立てばよい 1. 二つの分布がdisjointなsupportを持つ場合 2. 二つの分布がそれぞれ低次元多様体に乗っている場合 ◦
低次元多様体の共有空間は、測度0になるから (たぶん) イメージ的には、例えば二次元空間では曲線は 基本的には点でしか交わらないので分離できるよって感じ (一点の確率密度は0)
12.
Sources of Instability 結局! • 二つの分布が互いに素なsupportを持つ、もしくは • 低次元多様体に存在している場合、 Optimal discriminatorが存在し、 そのとき x
∈ 𝑋に対し、 𝐽𝑆𝐷 = log 2 , 𝛻3 𝐷 𝑥 = 0 要は自由にD決めてよかったら最終的には完璧に分離できちゃうぜってこと つまりJSD自体に低次元多様体同士を近づける力はない
13.
Sources of Instability また、最適な𝐷∗ と学習途中の𝐷がどれだけ離れているかを𝜖とおいて、 𝛻I 𝐸~] log
1 − 𝐷 𝑔I 𝑧 D ≤ M 𝜖 1 − 𝜖 らしいです 結局! 𝐷∗ の近似精度が上がるほどgradientのnormは小さくなっていく つまり、 • 学習が不足していると、正確でない 𝐽𝑆𝐷を最小化することに • 学習しすぎると、Gradientがどんどん小さくなってしまう → それは難しいわけだ、という話
14.
− log(𝐷)トリックについて • Gのlossにlog(1
− 𝐷(𝑥)) ではなく− log(𝐷(𝑥))を使うトリック • 学習初期は超簡単にDiscriminatorによって分離できてしまうので、 さっき述べた問題から、log(1-D)の勾配がどんどん小さくなる (このトリック使わないと学習進まないらしい) • 式的にも、D(x)がほぼ0だったとき、 𝛻log(1 − 𝐷 𝑥 ) = − ` a(3) (C ba 3 ) よりも − 𝛻log(𝐷 𝑥 ) = − ` a(3) a 3 のほうが大きそう • これって何を最小化してることになるの?
15.
− log(𝐷)トリックについて 実は、、 𝔼~]
−𝛻I log 𝐷∗ 𝑔I 𝑧 |IcId = 𝛻I [ 𝐾𝐿 (𝑃%e | 𝑃" − 2 𝐽𝑆𝐷 (𝑃%e 𝑃" IcId ] • JSDの符号直感と逆じゃん。。 • もう一つはMaximum Likelihoodのときと逆のKL!! ◦ Fake looking -> high cost ◦ Mode drop -> low cost → クオリティは良くなる方向に動くが、mode dropに対してlossが働かない → practiceに合うね! また計算していくと、この勾配の分散は学習が進むに連れて発散することがわかった → 勾配法が不安定に!
16.
Kullback-Leibler (KL) divergence 復習 𝐾𝐿(𝑃"||𝑃%) = ∫
𝑃" 𝑥 𝑙𝑜𝑔 12 3 14(3) 𝑑𝑥3 = 𝔼3~12 [𝑙𝑜𝑔 12 3 14(3) ] (KLは非可換 ) 𝑃% 𝑥 > 0 𝑎𝑛𝑑 𝑃" 𝑥 → 0 • 真のデータにないようなデータを生成 • Fake looking • 𝐾𝐿 → 0 𝑃" 𝑥 > 0 𝑎𝑛𝑑 𝑃% 𝑥 → 0 • 真のデータを生成する確率が低い • Mode dropping • 𝐾𝐿 → ∞
17.
Solution • じゃあどうすればいいの?? • 解決策
1 ◦ Dを学習させるとき、二つの分布にノイズを加える • 解決策 2 ◦ JSDではなく他の分布間距離を測る指標を利用する
18.
解決策 1 • Dを学習させるとき、二つの分布にノイズを加える
→ 𝐷∗ 𝑥 = 12fg 3 12fg 3 G14fg(3) ◦ 色々証明がんばってました。謎でした。 ◦ そもそも問題として、VAEみたいに最終出力にノイズを仮定してないからsupportがoverlapしない • ノイズ加えない場合は、二つの分布が割と似てても (Ex. きれいな画像を生成できていても) 完全に識別できるDが学習できてしまっていた • ノイズをいい感じに加えれば、ほぼ完全に二つの分布がoverlapするので、 Dを学習させればさせるほど良い しかし、 → ノイズの大きさを調整するの面倒 → 実際は𝑃"Gh 𝑥 ,𝑃%Gh(𝑥)の距離じゃなくて𝑃" 𝑥 , 𝑃%(𝑥) の距離を小さくしたい (ぼやけちゃう)
19.
解決策 2 • JSDではなく他の分布間距離を測る指標を利用する •
ここでWasserstein Metrics (別名 Earth Mover Distance (EMD) ) 𝑊 𝑃, 𝑄 = inf l∈m n 𝑥 − 𝑦 D 3 × 3 𝑑𝛾(𝑥, 𝑦) • 元々、最適輸送問題に使われる計量らしい。よくわからないです。 • Pにある土を動かしてQにするコスト • Pのx地点の密度P(x)を𝛾(𝑥, 𝑦)分だけ𝑦地点に移して最終的に𝑦地点の密度がQ(𝑦)になるように配分 • |𝑥 − 𝑦| がx地点から𝑦地点に密度を移すコスト • 一番移動コストの低い配分𝛾でのコスト 的な感じらしい 嬉しいのは、supportが違ってもコストが連続的に定義できること! 低次元多様体同士の距離をいい感じに測れる!
20.
• 一つ目の論文はここで終わり • 結論は特になかったです •
ここからWasserstein GAN です
21.
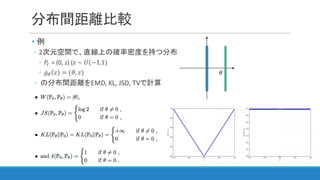
分布間距離比較 • 例 ◦ 2次元空間で、直線上の確率密度を持つ分布 ◦
𝑃" = (0, z) (𝑧 ~ 𝑈(−1,1) ◦ 𝑔I 𝑧 = (𝜃, 𝑧) ◦ の分布間距離をEMD, KL, JSD, TVで計算 𝜃
22.
WGAN • 低次元多様体にのる分布間距離を測るには、 JSDよりもEMDを利用するのが良いのでは? • 𝑊
𝑃, 𝑄 = inf l∈m ∫ 𝑥 − 𝑦 D3 × 3 𝑑𝛾(𝑥, 𝑦) ← これどうやって解くの?? • Kantorovich-Rubinstein duality 𝑊 𝑃",𝑃I = sup w xyC 𝔼3~12 𝑓 𝑥 − 𝔼3~1e 𝑓 𝑥 • 1-リプシッツを満たす関数𝑓{を選んだなら、 𝑊 𝑃", 𝑃I = max {∈} 𝔼3~12 𝑓} 𝑥 − 𝔼~]~ 𝑓{ 𝑔I(𝑧) よく見るとGANとほぼ同じ!!!!(logがない)
23.
WGAN • リプシッツ連続性 ◦ 関数の傾きが有界に収まる ◦
Feed-forward neural networkが1-リプシッツを満たすためには? ◦ Sigmoid, relu とかは大体リプシッツ連続 ◦ 各パラメータがコンパクト空間に収まっていれば良い つまり 各パラメータのnormが ある値c以下(論文中では0.01に設定)に収まっていれば良い
24.
WGAN 結局 𝑊 𝑃", 𝑃I
= 𝔼3~12 𝑓} 𝑥 − 𝔼~]~ 𝑓{ 𝑔I(𝑧) • Critic (元のDiscriminatorと区別するためにCriticと表現) ◦ 収束するまで学習させる (論文ではCritic 5回 G 1回) ◦ 生出力を利用 (softplusとかlogとか何もいらない) ◦ パラメータをc以下にclipping • Generator ◦ Criticと同じlossを利用する 従来のGAN loss ◦ 𝐿 𝑓{ 𝑔I = 𝔼3~12 [log 𝑓{(𝑥)] + 𝔼~]~ [log(1 − 𝑓{ 𝑔I (𝑧) )] ◦ (𝛻I 𝐿 𝑓{, 𝑔I = −𝛻I log 𝑓{ 𝑔I 𝑧 )
25.
WGAN • 特徴 ◦ 学習が安定 ◦
常に収束させるまで学習させても勾配が消えないのでDとGの学習スケジュールの調整が不要 ◦ BatchNormalizationがなくても動く。極端にはMLPでも学習可能 ◦ 意味のあるloss metrics ◦ 生成クオリティの向上とlossの減少が相関する ◦ 今までのGANはそもそもDとGで最適化するloss違ったうえに、各lossの値がめちゃくちゃ ◦ このlossが小さければ良いモデルとして良いのでハイパラ探索の基準にできる (BOとか) ◦ Mode Collapseは起こらない ◦ これはそもそもfixされたDに対して最適なGを学習してしまうことによるもの ◦ その時点でのGに対して収束するまでDを学習させるため大丈夫
26.
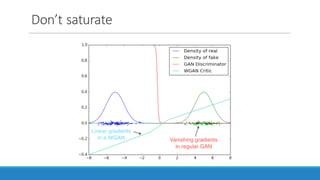
Don’t saturate
27.
Meaningful Loss Metrics
28.
WGAN • 実装上は、今までのに修正を加える程度 ◦ Dをclipping ◦
Dの出力の非線形関数を外す • 注意点 ◦ 学習率を高くしたり、初期化を間違えるとCriticが死ぬ(全パラメータ -0.01か0.01に) ◦ Clippingしているためか、Motentum項を加えると学習が壊れる ◦ 論文中ではRMSPropを推奨 ◦ 強めのWeight Decayでも良いらしい(結局抑えられればなんでもよい)
29.
結論 • 著者頭良い & WGANすごい •
一応実装してみたので興味あったら見てください ◦ https://github.com/fukuta0614/chainer-image-generation/tree/master/WassersteinGAN ◦ やってみた感じ、単純に[-0.01, 0.01]のclipだとだいぶモデルに制約加えてるので 従来と同じ構造だとやや表現力不足する感 ◦ Clipping parameterをannealさせたり、層深くして構造を複雑させたりする必要がありそう
Download




![Kullback-Leibler (KL) divergence
𝐾𝐿(𝑃"||𝑃%) = ∫ 𝑃" 𝑥 𝑙𝑜𝑔
12 3
14(3)
𝑑𝑥3
= 𝔼3~12
[𝑙𝑜𝑔
12 3
14(3)
]
(KLは非対称 )
𝑃% 𝑥 > 0 𝑎𝑛𝑑 𝑃" 𝑥 → 0
• 真のデータにないようなデータを生成
• Fake looking
• 𝐾𝐿 → 0
𝑃" 𝑥 > 0 𝑎𝑛𝑑 𝑃% 𝑥 → 0
• 真のデータを生成する確率が低い
• Mode dropping
• 𝐾𝐿 → ∞](https://image.slidesharecdn.com/wgan-1-170224021826/85/DL-Wasserstein-GAN-Towards-Principled-Methods-for-Training-Generative-Adversarial-Networks-4-320.jpg)

![GAN
Original Loss
𝐿 𝐷, 𝑔I = 𝔼3~12
[log 𝐷(𝑥)] + 𝔼3~14
[log(1 − 𝐷 𝑥 )] (1)
Dは式(1)を最大化、Gは式(1)を最小化
明らかに、𝐷∗ 𝑥 =
12 3
12 3 G14(3)
のとき最大
→ 𝐿 𝐷∗
, 𝑔I = 2 𝐽𝑆𝐷(𝑃"| 𝑃% − 2log2 2
すなわち
• Dは𝐽𝑆𝐷を近似するよう学習
• GはDによって近似された𝐽𝑆𝐷を最小化するように学習](https://image.slidesharecdn.com/wgan-1-170224021826/85/DL-Wasserstein-GAN-Towards-Principled-Methods-for-Training-Generative-Adversarial-Networks-6-320.jpg)


![Sources of Instability
そもそも、Gを固定してDを学習させた場合
min − 𝐿 𝐷, 𝑔I = min − 𝔼3~12
[log 𝐷(𝑥)] + 𝔼3~14
[log(1 − 𝐷 𝑥 )]
= − 2 𝐽𝑆𝐷(𝑃"| 𝑃% + 2log2 であってほしい
→ だが実際にはどこまでも小さくなり最終的には 0 に
→ なぜ??可能性としては、、
• 分布が不連続
• 互いに素な台(support)が存在する](https://image.slidesharecdn.com/wgan-1-170224021826/85/DL-Wasserstein-GAN-Towards-Principled-Methods-for-Training-Generative-Adversarial-Networks-9-320.jpg)



![Sources of Instability
また、最適な𝐷∗
と学習途中の𝐷がどれだけ離れているかを𝜖とおいて、
𝛻I 𝐸~] log 1 − 𝐷 𝑔I 𝑧
D
≤ M
𝜖
1 − 𝜖
らしいです
結局!
𝐷∗ の近似精度が上がるほどgradientのnormは小さくなっていく
つまり、
• 学習が不足していると、正確でない 𝐽𝑆𝐷を最小化することに
• 学習しすぎると、Gradientがどんどん小さくなってしまう
→ それは難しいわけだ、という話](https://image.slidesharecdn.com/wgan-1-170224021826/85/DL-Wasserstein-GAN-Towards-Principled-Methods-for-Training-Generative-Adversarial-Networks-13-320.jpg)

![− log(𝐷)トリックについて
実は、、
𝔼~] −𝛻I log 𝐷∗
𝑔I 𝑧 |IcId
= 𝛻I [ 𝐾𝐿 (𝑃%e
| 𝑃" − 2 𝐽𝑆𝐷 (𝑃%e
𝑃" IcId
]
• JSDの符号直感と逆じゃん。。
• もう一つはMaximum Likelihoodのときと逆のKL!!
◦ Fake looking -> high cost
◦ Mode drop -> low cost
→ クオリティは良くなる方向に動くが、mode dropに対してlossが働かない
→ practiceに合うね!
また計算していくと、この勾配の分散は学習が進むに連れて発散することがわかった
→ 勾配法が不安定に!](https://image.slidesharecdn.com/wgan-1-170224021826/85/DL-Wasserstein-GAN-Towards-Principled-Methods-for-Training-Generative-Adversarial-Networks-15-320.jpg)
![Kullback-Leibler (KL) divergence 復習
𝐾𝐿(𝑃"||𝑃%) = ∫ 𝑃" 𝑥 𝑙𝑜𝑔
12 3
14(3)
𝑑𝑥3
= 𝔼3~12
[𝑙𝑜𝑔
12 3
14(3)
]
(KLは非可換 )
𝑃% 𝑥 > 0 𝑎𝑛𝑑 𝑃" 𝑥 → 0
• 真のデータにないようなデータを生成
• Fake looking
• 𝐾𝐿 → 0
𝑃" 𝑥 > 0 𝑎𝑛𝑑 𝑃% 𝑥 → 0
• 真のデータを生成する確率が低い
• Mode dropping
• 𝐾𝐿 → ∞](https://image.slidesharecdn.com/wgan-1-170224021826/85/DL-Wasserstein-GAN-Towards-Principled-Methods-for-Training-Generative-Adversarial-Networks-16-320.jpg)




![WGAN
• 低次元多様体にのる分布間距離を測るには、
JSDよりもEMDを利用するのが良いのでは?
• 𝑊 𝑃, 𝑄 = inf
l∈m
∫ 𝑥 − 𝑦 D3 × 3
𝑑𝛾(𝑥, 𝑦) ← これどうやって解くの??
• Kantorovich-Rubinstein duality
𝑊 𝑃",𝑃I = sup
w xyC
𝔼3~12
𝑓 𝑥 − 𝔼3~1e
𝑓 𝑥
• 1-リプシッツを満たす関数𝑓{を選んだなら、
𝑊 𝑃", 𝑃I = max
{∈}
𝔼3~12
𝑓} 𝑥 − 𝔼~]~
𝑓{ 𝑔I(𝑧)
よく見るとGANとほぼ同じ!!!!(logがない)](https://image.slidesharecdn.com/wgan-1-170224021826/85/DL-Wasserstein-GAN-Towards-Principled-Methods-for-Training-Generative-Adversarial-Networks-22-320.jpg)

![WGAN
結局
𝑊 𝑃", 𝑃I = 𝔼3~12
𝑓} 𝑥 − 𝔼~]~
𝑓{ 𝑔I(𝑧)
• Critic (元のDiscriminatorと区別するためにCriticと表現)
◦ 収束するまで学習させる (論文ではCritic 5回 G 1回)
◦ 生出力を利用 (softplusとかlogとか何もいらない)
◦ パラメータをc以下にclipping
• Generator
◦ Criticと同じlossを利用する
従来のGAN loss
◦ 𝐿 𝑓{ 𝑔I = 𝔼3~12
[log 𝑓{(𝑥)] + 𝔼~]~
[log(1 − 𝑓{ 𝑔I (𝑧) )]
◦ (𝛻I 𝐿 𝑓{, 𝑔I = −𝛻I log 𝑓{ 𝑔I 𝑧 )](https://image.slidesharecdn.com/wgan-1-170224021826/85/DL-Wasserstein-GAN-Towards-Principled-Methods-for-Training-Generative-Adversarial-Networks-24-320.jpg)


![結論
• 著者頭良い & WGANすごい
• 一応実装してみたので興味あったら見てください
◦ https://github.com/fukuta0614/chainer-image-generation/tree/master/WassersteinGAN
◦ やってみた感じ、単純に[-0.01, 0.01]のclipだとだいぶモデルに制約加えてるので
従来と同じ構造だとやや表現力不足する感
◦ Clipping parameterをannealさせたり、層深くして構造を複雑させたりする必要がありそう](https://image.slidesharecdn.com/wgan-1-170224021826/85/DL-Wasserstein-GAN-Towards-Principled-Methods-for-Training-Generative-Adversarial-Networks-29-320.jpg)


![[DL輪読会]相互情報量最大化による表現学習](https://cdn.slidesharecdn.com/ss_thumbnails/20190913iwasawa-190913002312-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]近年のエネルギーベースモデルの進展](https://cdn.slidesharecdn.com/ss_thumbnails/energybasedmodel-200124020855-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]Understanding Black-box Predictions via Influence Functions](https://cdn.slidesharecdn.com/ss_thumbnails/dlhacksinffunc-170822055634-thumbnail.jpg?width=640&height=640&fit=bounds)








![[Ridge-i 論文よみかい] Wasserstein auto encoder](https://cdn.slidesharecdn.com/ss_thumbnails/wassersteinauto-encoder-181006055019-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DLHacks]StyleGANとBigGANのStyle mixing, morphing](https://cdn.slidesharecdn.com/ss_thumbnails/dlhacks0805-190815052222-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会] Spectral Norm Regularization for Improving the Generalizability of De...](https://cdn.slidesharecdn.com/ss_thumbnails/dlhackspectralnorm1-170907072536-thumbnail.jpg?width=640&height=640&fit=bounds)



![SSII2021 [OS2-02] 深層学習におけるデータ拡張の原理と最新動向](https://cdn.slidesharecdn.com/ss_thumbnails/os2-03latest-210610045610-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL Hacks]Variational Approaches For Auto-Encoding Generative Adversarial Ne...](https://cdn.slidesharecdn.com/ss_thumbnails/alpha-gan-inpl-180417074219-thumbnail.jpg?width=640&height=640&fit=bounds)
![SSII2022 [TS1] Transformerの最前線〜 畳込みニューラルネットワークの先へ 〜](https://cdn.slidesharecdn.com/ss_thumbnails/ts120220608ssiitransformerr2-220607054025-3adacf07-thumbnail.jpg?width=640&height=640&fit=bounds)




![[DL輪読会]Exploiting Cyclic Symmetry in Convolutional Neural Networks](https://cdn.slidesharecdn.com/ss_thumbnails/20170217-170228044623-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]Combining Fully Convolutional and Recurrent Neural Networks for 3D Bio...](https://cdn.slidesharecdn.com/ss_thumbnails/20170203dlhacks-170203004925-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]Generative Models of Visually Grounded Imagination](https://cdn.slidesharecdn.com/ss_thumbnails/20170602-170602005505-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]StackGAN: Text to Photo-realistic Image Synthesis with Stacked Generat...](https://cdn.slidesharecdn.com/ss_thumbnails/dlhacks170303-170308031242-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DL輪読会] GAN系の研究まとめ (NIPS2016とICLR2016が中心)](https://cdn.slidesharecdn.com/ss_thumbnails/dliwasawagansurvey-161220014753-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]Adversarial Feature Matching for Text Generation](https://cdn.slidesharecdn.com/ss_thumbnails/dljp170707-170707035929-thumbnail.jpg?width=640&height=640&fit=bounds)

![第35回 強化学習勉強会・論文紹介 [Lantao Yu : 2016]](https://cdn.slidesharecdn.com/ss_thumbnails/seqgan-161005155821-thumbnail.jpg?width=640&height=640&fit=bounds)











![[DL輪読会]Scalable Training of Inference Networks for Gaussian-Process Models](https://cdn.slidesharecdn.com/ss_thumbnails/mainslideshare1-190927025239-thumbnail.jpg?width=640&height=640&fit=bounds)




![[DL輪読会]Convolutional Conditional Neural Processesと Neural Processes Familyの紹介](https://cdn.slidesharecdn.com/ss_thumbnails/20191220readingpaperconvcnp-191220034420-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DL輪読会]Temporal DifferenceVariationalAuto-Encoder](https://cdn.slidesharecdn.com/ss_thumbnails/20181130new-190205051636-thumbnail.jpg?width=640&height=640&fit=bounds)
























