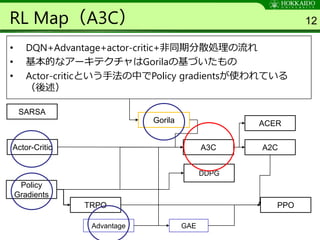
論文情報
• タイトル
– AsynchronousMethods for Deep Reinforcement Learning
– URL : https://arxiv.org/abs/1602.01783
• 発表学会
– ICML2016
• 著者
– Volodymyr Mnih, Adrià Puigdomènech Badia, Mehdi Mirz
• 所属
– Google DeepMind・Montreal Institute for Learning
Algorithms (MILA), University of Montreal
13
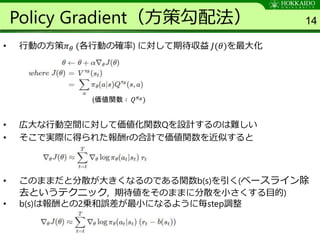
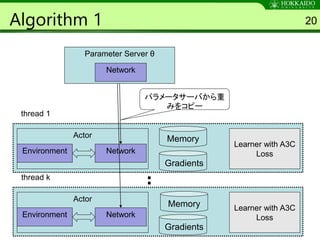
Algorithm 1 20
ParameterServer θ
thread 1
Environment Network
Gradients
Learner with A3C
Loss
Actor Memory
thread k
Environment Network
Gradients
Learner with A3C
Loss
Actor
Memory
パラメータサーバから重
みをコピー
Parameter Server θ
Network
21.
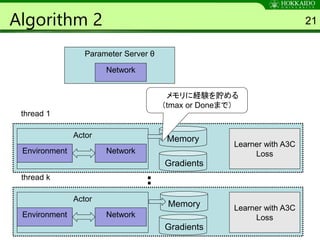
Algorithm 2 21
ParameterServer θ
thread 1
Environment Network
Gradients
Learner with A3C
Loss
Actor Memory
thread k
Environment Network
Gradients
Learner with A3C
Loss
Actor
Memory
メモリに経験を貯める
(tmax or Doneまで)
Parameter Server θ
Network
22.
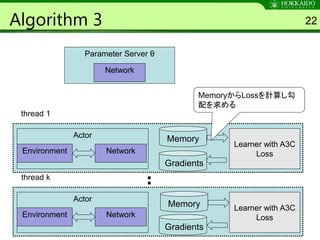
Algorithm 3 22
ParameterServer θ
thread 1
Environment Network
Gradients
Learner with A3C
Loss
Actor Memory
thread k
Environment Network
Gradients
Learner with A3C
Loss
Actor
Memory
MemoryからLossを計算し勾
配を求める
Network
23.
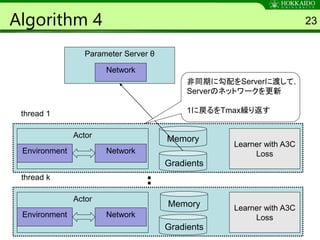
Algorithm 4 23
thread1
Environment Network
Gradients
Learner with A3C
Loss
Actor Memory
thread k
Environment Network
Gradients
Learner with A3C
Loss
Actor
Memory
Parameter Server θ
Network
非同期に勾配をServerに渡して,
Serverのネットワークを更新
1に戻るをTmax繰り返す
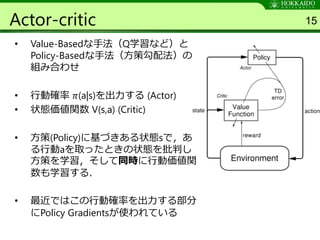
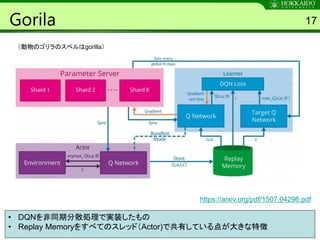
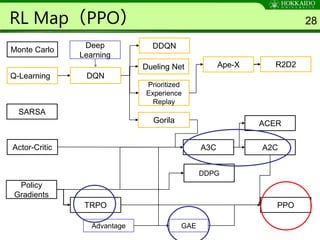
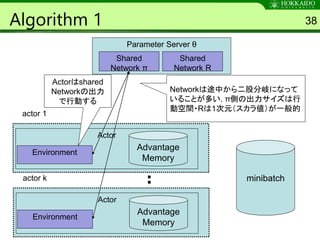
Algorithm 1 38
ParameterServer θ
Shared
Network π
actor 1
Environment
Actor
Advantage
Memory
Actorはshared
Networkの出力
で行動する
Shared
Network R
Networkは途中から二股分岐になって
いることが多い. π側の出力サイズは行
動空間・Rは1次元(スカラ値)が一般的
actor k
Environment
Actor
Advantage
Memory
minibatch
39.
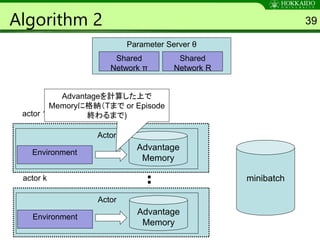
Algorithm 2 39
ParameterServer θ
Shared
Network π
actor 1
Environment
Actor
Advantage
Memory
Shared
Network R
actor k
Environment
Actor
Advantage
Memory
minibatch
Advantageを計算した上で
Memoryに格納(Tまで or Episode
終わるまで)
40.
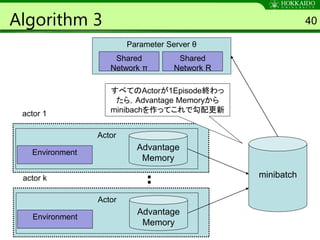
Algorithm 3 40
ParameterServer θ
Shared
Network π
actor 1
Environment
Actor
Advantage
Memory
Shared
Network R
actor k
Environment
Actor
Advantage
Memory
minibatch
すべてのActorが1Episode終わっ
たら,Advantage Memoryから
minibachを作ってこれで勾配更新


![論文情報
• タイトル
– Proximal Policy Optimization Algorithms
– URL : https://arxiv.org/abs/1602.01783
• JULY 20, 2017
• 著者
– John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford,
Oleg Klimov [OpenAI ]
2](https://image.slidesharecdn.com/20190802dlppo-200208084929/85/DQN-PPO-2-320.jpg)


![[おさらい] 強化学習とは
• s : 状態 (state)
• a : 行動 (action)
• r : 報酬 (reward)
• エージェントがある行動atを
行って,環境から次の状態
st+1と報酬rt+1を受け取る
• という枠組みが基本である
8
引用:Pythonではじめる強化学習](https://image.slidesharecdn.com/20190802dlppo-200208084929/85/DQN-PPO-8-320.jpg)









![論文情報
• タイトル
– Proximal Policy Optimization Algorithms
– URL : https://arxiv.org/abs/1602.01783
• JULY 20, 2017
• 著者
– John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford,
Oleg Klimov [OpenAI ]
29](https://image.slidesharecdn.com/20190802dlppo-200208084929/85/DQN-PPO-29-320.jpg)

![[再訪] Policy gradient(方策勾配法)
• Policy gradientとは以下の式に従って方策πを更新する方式
– πθは確率的方策
– Atはアドバンテージの推定量(状態を評価する関数)
– Etは期待値のサンプルの有限バッチ平均近似
• 同じエピソードを使用してこのloss関数の更新をすすめると,
破壊的な大幅なポリシーの更新をすることがある
• 複数エポックには向かない
31](https://image.slidesharecdn.com/20190802dlppo-200208084929/85/DQN-PPO-31-320.jpg)


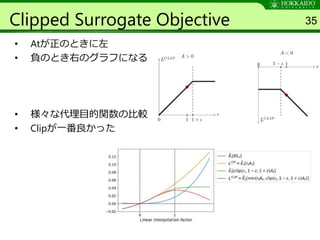
![Clipped Surrogate Objective
• new/oldこのように定義すると
• TRPOは以下代理目的関数を最大化する
– CPIとは目的であるconservative policy iteration(保守的な方
策反復)
– 制約がないとLCPIは過度に大きな方策更新が起こるので𝑟𝑡(𝜃)
に制約を設ける. [1-ε, 1+ε] ->PPOでの改善点
• PPOでは以下の代理目的関数を最大化する
34](https://image.slidesharecdn.com/20190802dlppo-200208084929/85/DQN-PPO-34-320.jpg)










![[DL輪読会] マルチエージェント強化学習と心の理論](https://cdn.slidesharecdn.com/ss_thumbnails/0917imai-211210044729-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]近年のオフライン強化学習のまとめ —Offline Reinforcement Learning: Tutorial, Review, an...](https://cdn.slidesharecdn.com/ss_thumbnails/20200626journalclubpub-200630064755-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]“SimPLe”,“Improved Dynamics Model”,“PlaNet” 近年のVAEベース系列モデルの進展とそのモデルベース...](https://cdn.slidesharecdn.com/ss_thumbnails/20190426akuzawa-190426020057-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]逆強化学習とGANs](https://cdn.slidesharecdn.com/ss_thumbnails/irlgans-171128063119-thumbnail.jpg?width=640&height=640&fit=bounds)




![[DL輪読会]Set Transformer: A Framework for Attention-based Permutation-Invariant...](https://cdn.slidesharecdn.com/ss_thumbnails/20200221settransformer-200221020423-thumbnail.jpg?width=640&height=640&fit=bounds)
![SSII2022 [SS1] ニューラル3D表現の最新動向〜 ニューラルネットでなんでも表せる?? 〜](https://cdn.slidesharecdn.com/ss_thumbnails/ss1ssii2022hkatoneural3drepresentationhiroharukato-220607054619-fadc6480-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DL輪読会]Decision Transformer: Reinforcement Learning via Sequence Modeling](https://cdn.slidesharecdn.com/ss_thumbnails/decisiontransformer20210709zhangxin-210709021501-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DL輪読会]Pay Attention to MLPs (gMLP)](https://cdn.slidesharecdn.com/ss_thumbnails/kobayashi-210528032327-thumbnail.jpg?width=640&height=640&fit=bounds)

![SSII2021 [TS2] 深層強化学習 〜 強化学習の基礎から応用まで 〜](https://cdn.slidesharecdn.com/ss_thumbnails/ts2-01-210607042910-thumbnail.jpg?width=640&height=640&fit=bounds)








![[DL輪読会] Learning Finite State Representations of Recurrent Policy Networks (I...](https://cdn.slidesharecdn.com/ss_thumbnails/20190830kaitosuzuki-190902060756-thumbnail.jpg?width=640&height=640&fit=bounds)






![[DL輪読会]Model-Based Reinforcement Learning via Meta-Policy Optimization](https://cdn.slidesharecdn.com/ss_thumbnails/model-basedreinforcementlearningviameta-policyoptimization-190705000247-thumbnail.jpg?width=640&height=640&fit=bounds)


![[Dl輪読会]introduction of reinforcement learning](https://cdn.slidesharecdn.com/ss_thumbnails/dlintroductionofreinforcementlearning-161121061444-thumbnail.jpg?width=640&height=640&fit=bounds)





















