Reference
P. Bachman, D.Precup. Data Generation as Sequential Decision Making. NIPS, 2015.
J. Bornschein, Y. Bengio. Reweighted Wake-Sleep. ICLR, 2015.
P. Dayan, G. E. Hinton, R. M. Neal, R. S. Zemel. The Helmholtz Machine. Neural Computation 7, 889-904,
1995.
I. J. Goodfellow, J. P.-Abadie, M. Mirza, B. Xu, D. W.-Farley, S. Ozair, A. Courville, Y. Bengio. Generative
Adversarial Nets. NIPS, 2014.
K. Gregor, I. Danihelka, A. Graves, D. Wierstra. DRAW: A Recurrent Neural Networks For Image
Generation. ICML, 2015.
G. E. Hinton, P. Dayan, B. J. Frey, R. M. Neal. The wake-sleep algorithm for unsupervised neural
networks. Science, vol. 268, pp. 1158-1161, 1995.
D. P. Kingma, M. Welling. Auto-Encoding Variational Bayes. ICLR, 2014.
A. Makhzani, J. Shlens, N. Jaitly, I. Goodfellow. Adversarial Autoencoders. ArXiv:1511.05644, 2015.
V. Mnih, N. Hees, A. Graves, K. Kavukcuoglu. Recurrent Models of Visual Attention. NIPS, 2014.
A. Radford, L. Metz, S. Chintala. Unsupervised Representation Learning with Deep Convolutional
Generative Adversarial Networks. ICLR, 2016.
D. J. Rezende, S. Mohamed, D. Wierstra. Stochastic Backpropagation and Approximate Inference in
Deep Generative Models. ICML, 2014.
38








![Helmholtz Machine [Dayan+, ’95]
Generator:潜在変数 から伝承サンプリングで を生成
逆向きの推論をする推論モデルを一緒に学習する
推論モデル 生成モデル](https://image.slidesharecdn.com/learning-generator-v2-160225050717/85/Deep-Learning-8-320.jpg)

![変分下界最大化 1:Wake-Sleep [Hinton+, ’95]
についてのこの量の最大化は、 を最小化するのと等価。
これを最小化する代わりに、分布をひっくり返した を最小
化する。
これは について を最大化するのと等価。
10
Wake phase
はデータセット
からサンプリング
(real data)
Sleep phase
はモデルから
サンプリング
(fantasy)](https://image.slidesharecdn.com/learning-generator-v2-160225050717/85/Deep-Learning-10-320.jpg)
![変分下界最大化 2:Reweighted Wake-Sleep [Bornschein+, ‘15]
を により正しく近づけたい。
これを使って勾配を近似。
11
Wake phase
はデータセット
からサンプリング
Sleep phase は
Wake-Sleep と同じ](https://image.slidesharecdn.com/learning-generator-v2-160225050717/85/Deep-Learning-11-320.jpg)
![変分下界最大化 3:変分 AutoEncoder [Kingma+, ‘14][Rezende+, ‘14]
変分下界を違う形に変形
12
訓練データ 復元
❷ 近づける:復元誤差
❶ 近づける:正則化
❶ ❷](https://image.slidesharecdn.com/learning-generator-v2-160225050717/85/Deep-Learning-12-320.jpg)







![GAN: Discriminator と Generator を交互に更新 [Goodfellow+, ‘14]
生成モデルを と定義
( は任意の分布)
識別モデルを とおく
GAN: さきほどの min-max 問題を、これらを交互に更新して解く
20](https://image.slidesharecdn.com/learning-generator-v2-160225050717/85/Deep-Learning-20-320.jpg)

![ぼやけない画像生成: Deep Convolutional GAN [Radford+, ’16]
22
LSUN bedroom データセットに対し、Generator に Deconv Net、
Discriminator に Conv Net を使って GAN を学習した例
Pooling を使わない (strided conv)、BatchNormalization を使うなどの工夫](https://image.slidesharecdn.com/learning-generator-v2-160225050717/85/Deep-Learning-22-320.jpg)

![Adversarial AutoEncoder [Makhzani+, ‘16 (arXiv)]
GAN は 以外の確率変数をマッ
チングするのにも使える
Adversarial AutoEncoder
— AutoEncoder の を所望の分
布 にマッチさせるのに使
う
— が単純な標準ガウス分布
であっても、KL ダイバージェ
ンスによるマッチングに比べ
て分布がきれいに合う
24](https://image.slidesharecdn.com/learning-generator-v2-160225050717/85/Deep-Learning-24-320.jpg)



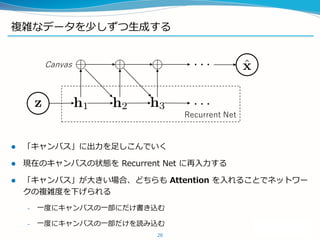

![Soft attention: DRAW [Gregor+, ‘15]
Soft Attention による reader / writer を変分 AutoEncoder と組み合わせる
30
(追試例)](https://image.slidesharecdn.com/learning-generator-v2-160225050717/85/Deep-Learning-30-320.jpg)
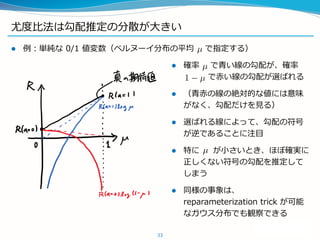
![Hard attention: Recurrent Attention Model [Mnih+, ‘14]
最近の attention + Recurrent Net のはしり
データ生成ではなく、分類問題に使っていた
Hard attention は微分できないので、単純な誤差逆伝播では attention の当て
方を学習できない
Attention の当て方を , 目的関数を と書く
Attention を確率的に決める: ( は attention を出力するのに使う
パラメータ)
すると、目的関数の に関する勾配は
31](https://image.slidesharecdn.com/learning-generator-v2-160225050717/85/Deep-Learning-31-320.jpg)


![データ生成は意思決定のくりかえし [Bachman+, ‘15]
“Data Generation as Sequential Decision Making”
モデル中の中間変数を
その分布パラメータを出力する action
分布パラメータ (action) をもとにサンプリングを行う環境
とみなすと、マルコフ決定過程における報酬最大化問題になる
この場合、学習したいのは action を予測する方策 (policy)
Helmholtz Machine のように変分ベイズにもとづく手法は、policy に対して
「データを知っている」推論モデルの予測に policy を近づける
– これは、強化学習における Guided Policy Search と等価
35](https://image.slidesharecdn.com/learning-generator-v2-160225050717/85/Deep-Learning-35-320.jpg)












![[DL輪読会]ICLR2020の分布外検知速報](https://cdn.slidesharecdn.com/ss_thumbnails/iclr2020ood-190927011524-thumbnail.jpg?width=640&height=640&fit=bounds)


![SSII2022 [TS1] Transformerの最前線〜 畳込みニューラルネットワークの先へ 〜](https://cdn.slidesharecdn.com/ss_thumbnails/ts120220608ssiitransformerr2-220607054025-3adacf07-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]Grokking: Generalization Beyond Overfitting on Small Algorithmic Datasets](https://cdn.slidesharecdn.com/ss_thumbnails/20220325okimura-220405024717-thumbnail.jpg?width=640&height=640&fit=bounds)





![[DL輪読会]Control as Inferenceと発展](https://cdn.slidesharecdn.com/ss_thumbnails/20191004-191204055019-thumbnail.jpg?width=640&height=640&fit=bounds)















![[DL輪読会]Xception: Deep Learning with Depthwise Separable Convolutions](https://cdn.slidesharecdn.com/ss_thumbnails/2017-06-22-170623004409-thumbnail.jpg?width=640&height=640&fit=bounds)


















![[DL輪読会]Temporal DifferenceVariationalAuto-Encoder](https://cdn.slidesharecdn.com/ss_thumbnails/20181130new-190205051636-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DL輪読会]GQNと関連研究,世界モデルとの関係について](https://cdn.slidesharecdn.com/ss_thumbnails/20180817-180827085537-thumbnail.jpg?width=640&height=640&fit=bounds)





![[DL輪読会]Flow-based Deep Generative Models](https://cdn.slidesharecdn.com/ss_thumbnails/20190307-190328024744-thumbnail.jpg?width=640&height=640&fit=bounds)





















