Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
Submit search
EN
Uploaded by
Deep Learning JP
PPTX, PDF
2,652 views
[DL輪読会]Dream to Control: Learning Behaviors by Latent Imagination
2020/03/13 Deep Learning JP: http://deeplearning.jp/seminar-2/
Technology
◦
Related topics:
Deep Learning
•
Read more
3
Save
Share
Embed
Embed presentation
Download
Downloaded 29 times
1
/ 20
2
/ 20
3
/ 20
4
/ 20
5
/ 20
6
/ 20
7
/ 20
8
/ 20
Most read
9
/ 20
Most read
10
/ 20
11
/ 20
Most read
12
/ 20
13
/ 20
14
/ 20
15
/ 20
16
/ 20
17
/ 20
18
/ 20
19
/ 20
20
/ 20
More Related Content
PPTX
[DL輪読会]Learning Latent Dynamics for Planning from Pixels
by
Deep Learning JP
PDF
【DL輪読会】A Path Towards Autonomous Machine Intelligence
by
Deep Learning JP
PPTX
【DL輪読会】DayDreamer: World Models for Physical Robot Learning
by
Deep Learning JP
PPTX
[DL輪読会]“SimPLe”,“Improved Dynamics Model”,“PlaNet” 近年のVAEベース系列モデルの進展とそのモデルベース...
by
Deep Learning JP
PPTX
[DL輪読会]World Models
by
Deep Learning JP
PDF
[DL輪読会]Control as Inferenceと発展
by
Deep Learning JP
PDF
「世界モデル」と関連研究について
by
Masahiro Suzuki
PDF
深層強化学習の分散化・RNN利用の動向〜R2D2の紹介をもとに〜
by
Jun Okumura
[DL輪読会]Learning Latent Dynamics for Planning from Pixels
by
Deep Learning JP
【DL輪読会】A Path Towards Autonomous Machine Intelligence
by
Deep Learning JP
【DL輪読会】DayDreamer: World Models for Physical Robot Learning
by
Deep Learning JP
[DL輪読会]“SimPLe”,“Improved Dynamics Model”,“PlaNet” 近年のVAEベース系列モデルの進展とそのモデルベース...
by
Deep Learning JP
[DL輪読会]World Models
by
Deep Learning JP
[DL輪読会]Control as Inferenceと発展
by
Deep Learning JP
「世界モデル」と関連研究について
by
Masahiro Suzuki
深層強化学習の分散化・RNN利用の動向〜R2D2の紹介をもとに〜
by
Jun Okumura
What's hot
PPTX
[DL輪読会]相互情報量最大化による表現学習
by
Deep Learning JP
PDF
[DL輪読会]Decision Transformer: Reinforcement Learning via Sequence Modeling
by
Deep Learning JP
PPTX
【DL輪読会】Efficiently Modeling Long Sequences with Structured State Spaces
by
Deep Learning JP
PPTX
【DL輪読会】High-Resolution Image Synthesis with Latent Diffusion Models
by
Deep Learning JP
PDF
Control as Inference (強化学習とベイズ統計)
by
Shohei Taniguchi
PPTX
強化学習 DQNからPPOまで
by
harmonylab
PDF
【DL輪読会】How Much Can CLIP Benefit Vision-and-Language Tasks?
by
Deep Learning JP
PPTX
【DL輪読会】Transformers are Sample Efficient World Models
by
Deep Learning JP
PPTX
[DL輪読会]Life-Long Disentangled Representation Learning with Cross-Domain Laten...
by
Deep Learning JP
PDF
【DL輪読会】Diffusion Policy: Visuomotor Policy Learning via Action Diffusion
by
Deep Learning JP
PDF
強化学習その3
by
nishio
PDF
強化学習と逆強化学習を組み合わせた模倣学習
by
Eiji Uchibe
PDF
深層生成モデルと世界モデル
by
Masahiro Suzuki
PDF
PRML学習者から入る深層生成モデル入門
by
tmtm otm
PPTX
【DL輪読会】Scaling Laws for Neural Language Models
by
Deep Learning JP
PPTX
Curriculum Learning (関東CV勉強会)
by
Yoshitaka Ushiku
PDF
【DL輪読会】Mastering Diverse Domains through World Models
by
Deep Learning JP
PDF
最近のディープラーニングのトレンド紹介_20200925
by
小川 雄太郎
PDF
【DL輪読会】GPT-4Technical Report
by
Deep Learning JP
PPTX
猫でも分かるVariational AutoEncoder
by
Sho Tatsuno
[DL輪読会]相互情報量最大化による表現学習
by
Deep Learning JP
[DL輪読会]Decision Transformer: Reinforcement Learning via Sequence Modeling
by
Deep Learning JP
【DL輪読会】Efficiently Modeling Long Sequences with Structured State Spaces
by
Deep Learning JP
【DL輪読会】High-Resolution Image Synthesis with Latent Diffusion Models
by
Deep Learning JP
Control as Inference (強化学習とベイズ統計)
by
Shohei Taniguchi
強化学習 DQNからPPOまで
by
harmonylab
【DL輪読会】How Much Can CLIP Benefit Vision-and-Language Tasks?
by
Deep Learning JP
【DL輪読会】Transformers are Sample Efficient World Models
by
Deep Learning JP
[DL輪読会]Life-Long Disentangled Representation Learning with Cross-Domain Laten...
by
Deep Learning JP
【DL輪読会】Diffusion Policy: Visuomotor Policy Learning via Action Diffusion
by
Deep Learning JP
強化学習その3
by
nishio
強化学習と逆強化学習を組み合わせた模倣学習
by
Eiji Uchibe
深層生成モデルと世界モデル
by
Masahiro Suzuki
PRML学習者から入る深層生成モデル入門
by
tmtm otm
【DL輪読会】Scaling Laws for Neural Language Models
by
Deep Learning JP
Curriculum Learning (関東CV勉強会)
by
Yoshitaka Ushiku
【DL輪読会】Mastering Diverse Domains through World Models
by
Deep Learning JP
最近のディープラーニングのトレンド紹介_20200925
by
小川 雄太郎
【DL輪読会】GPT-4Technical Report
by
Deep Learning JP
猫でも分かるVariational AutoEncoder
by
Sho Tatsuno
Similar to [DL輪読会]Dream to Control: Learning Behaviors by Latent Imagination
PPTX
【DL輪読会】Data-Efficient Reinforcement Learning with Self-Predictive Representat...
by
Deep Learning JP
PPTX
[DL輪読会]Temporal DifferenceVariationalAuto-Encoder
by
Deep Learning JP
PDF
生成モデルの Deep Learning
by
Seiya Tokui
PDF
[DL輪読会]Imagination-Augmented Agents for Deep Reinforcement Learning / Learnin...
by
Deep Learning JP
PPTX
強化学習エージェントの内発的動機付けによる探索とその応用(第4回 統計・機械学習若手シンポジウム 招待公演)
by
Shota Imai
PDF
[DL輪読会]Shaping Belief States with Generative Environment Models for RL
by
Deep Learning JP
PDF
[DL輪読会]Learning Task Informed Abstractions
by
Deep Learning JP
PDF
Decision Transformer: Reinforcement Learning via Sequence Modeling
by
Yasunori Ozaki
PDF
RLアーキテクチャ勉強会 MERLIN
by
YumaKajihara
PDF
20180115_東大医学部機能生物学セミナー_深層学習の最前線とこれから_岡野原大輔
by
Preferred Networks
PDF
ICML2017 参加報告会 山本康生
by
Yahoo!デベロッパーネットワーク
PDF
[DL輪読会]Learning to Act by Predicting the Future
by
Deep Learning JP
PDF
【参考文献追加】20180115_東大医学部機能生物学セミナー_深層学習の最前線とこれから_岡野原大輔
by
Preferred Networks
PPTX
「機械学習とは?」から始める Deep learning実践入門
by
Hideto Masuoka
PDF
NIPS KANSAI Reading Group #7: Temporal Difference Models: Model-Free Deep RL ...
by
Eiji Uchibe
PDF
Learning to Navigate in Complex Environments 輪読
by
Tatsuya Matsushima
PPTX
[DL輪読会]Learning to Adapt: Meta-Learning for Model-Based Control
by
Deep Learning JP
PPTX
"Universal Planning Networks" and "Composable Planning with Attributes"
by
Yusuke Iwasawa
PDF
Ibis2016okanohara
by
Preferred Networks
PDF
Generative deeplearning #02
by
逸人 米田
【DL輪読会】Data-Efficient Reinforcement Learning with Self-Predictive Representat...
by
Deep Learning JP
[DL輪読会]Temporal DifferenceVariationalAuto-Encoder
by
Deep Learning JP
生成モデルの Deep Learning
by
Seiya Tokui
[DL輪読会]Imagination-Augmented Agents for Deep Reinforcement Learning / Learnin...
by
Deep Learning JP
強化学習エージェントの内発的動機付けによる探索とその応用(第4回 統計・機械学習若手シンポジウム 招待公演)
by
Shota Imai
[DL輪読会]Shaping Belief States with Generative Environment Models for RL
by
Deep Learning JP
[DL輪読会]Learning Task Informed Abstractions
by
Deep Learning JP
Decision Transformer: Reinforcement Learning via Sequence Modeling
by
Yasunori Ozaki
RLアーキテクチャ勉強会 MERLIN
by
YumaKajihara
20180115_東大医学部機能生物学セミナー_深層学習の最前線とこれから_岡野原大輔
by
Preferred Networks
ICML2017 参加報告会 山本康生
by
Yahoo!デベロッパーネットワーク
[DL輪読会]Learning to Act by Predicting the Future
by
Deep Learning JP
【参考文献追加】20180115_東大医学部機能生物学セミナー_深層学習の最前線とこれから_岡野原大輔
by
Preferred Networks
「機械学習とは?」から始める Deep learning実践入門
by
Hideto Masuoka
NIPS KANSAI Reading Group #7: Temporal Difference Models: Model-Free Deep RL ...
by
Eiji Uchibe
Learning to Navigate in Complex Environments 輪読
by
Tatsuya Matsushima
[DL輪読会]Learning to Adapt: Meta-Learning for Model-Based Control
by
Deep Learning JP
"Universal Planning Networks" and "Composable Planning with Attributes"
by
Yusuke Iwasawa
Ibis2016okanohara
by
Preferred Networks
Generative deeplearning #02
by
逸人 米田
More from Deep Learning JP
PPTX
【DL輪読会】Hopfield network 関連研究について
by
Deep Learning JP
PDF
【DL輪読会】"Learning Fine-Grained Bimanual Manipulation with Low-Cost Hardware"
by
Deep Learning JP
PPTX
【DL輪読会】Towards Understanding Ensemble, Knowledge Distillation and Self-Distil...
by
Deep Learning JP
PPTX
【DL輪読会】AdaptDiffuser: Diffusion Models as Adaptive Self-evolving Planners
by
Deep Learning JP
PDF
【DL輪読会】"Secrets of RLHF in Large Language Models Part I: PPO"
by
Deep Learning JP
PDF
【DL輪読会】Self-Supervised Learning from Images with a Joint-Embedding Predictive...
by
Deep Learning JP
PDF
【DL輪読会】Can Neural Network Memorization Be Localized?
by
Deep Learning JP
PPTX
【DL輪読会】 "Learning to render novel views from wide-baseline stereo pairs." CVP...
by
Deep Learning JP
PPTX
【DL輪読会】Llama 2: Open Foundation and Fine-Tuned Chat Models
by
Deep Learning JP
PDF
【DL輪読会】Drag Your GAN: Interactive Point-based Manipulation on the Generative ...
by
Deep Learning JP
PDF
【DL輪読会】RLCD: Reinforcement Learning from Contrast Distillation for Language M...
by
Deep Learning JP
PPTX
【DL輪読会】事前学習用データセットについて
by
Deep Learning JP
PPTX
【DL輪読会】"Language Instructed Reinforcement Learning for Human-AI Coordination "
by
Deep Learning JP
PPTX
【DL輪読会】Parameter is Not All You Need:Starting from Non-Parametric Networks fo...
by
Deep Learning JP
PPTX
【DL輪読会】AnyLoc: Towards Universal Visual Place Recognition
by
Deep Learning JP
PPTX
【DL輪読会】SimPer: Simple self-supervised learning of periodic targets( ICLR 2023 )
by
Deep Learning JP
PPTX
【DL輪読会】BloombergGPT: A Large Language Model for Finance arxiv
by
Deep Learning JP
PDF
【 DL輪読会】ToolLLM: Facilitating Large Language Models to Master 16000+ Real-wo...
by
Deep Learning JP
PPTX
【DL輪読会】マルチモーダル LLM
by
Deep Learning JP
PPTX
【DL輪読会】Zero-Shot Dual-Lens Super-Resolution
by
Deep Learning JP
【DL輪読会】Hopfield network 関連研究について
by
Deep Learning JP
【DL輪読会】"Learning Fine-Grained Bimanual Manipulation with Low-Cost Hardware"
by
Deep Learning JP
【DL輪読会】Towards Understanding Ensemble, Knowledge Distillation and Self-Distil...
by
Deep Learning JP
【DL輪読会】AdaptDiffuser: Diffusion Models as Adaptive Self-evolving Planners
by
Deep Learning JP
【DL輪読会】"Secrets of RLHF in Large Language Models Part I: PPO"
by
Deep Learning JP
【DL輪読会】Self-Supervised Learning from Images with a Joint-Embedding Predictive...
by
Deep Learning JP
【DL輪読会】Can Neural Network Memorization Be Localized?
by
Deep Learning JP
【DL輪読会】 "Learning to render novel views from wide-baseline stereo pairs." CVP...
by
Deep Learning JP
【DL輪読会】Llama 2: Open Foundation and Fine-Tuned Chat Models
by
Deep Learning JP
【DL輪読会】Drag Your GAN: Interactive Point-based Manipulation on the Generative ...
by
Deep Learning JP
【DL輪読会】RLCD: Reinforcement Learning from Contrast Distillation for Language M...
by
Deep Learning JP
【DL輪読会】事前学習用データセットについて
by
Deep Learning JP
【DL輪読会】"Language Instructed Reinforcement Learning for Human-AI Coordination "
by
Deep Learning JP
【DL輪読会】Parameter is Not All You Need:Starting from Non-Parametric Networks fo...
by
Deep Learning JP
【DL輪読会】AnyLoc: Towards Universal Visual Place Recognition
by
Deep Learning JP
【DL輪読会】SimPer: Simple self-supervised learning of periodic targets( ICLR 2023 )
by
Deep Learning JP
【DL輪読会】BloombergGPT: A Large Language Model for Finance arxiv
by
Deep Learning JP
【 DL輪読会】ToolLLM: Facilitating Large Language Models to Master 16000+ Real-wo...
by
Deep Learning JP
【DL輪読会】マルチモーダル LLM
by
Deep Learning JP
【DL輪読会】Zero-Shot Dual-Lens Super-Resolution
by
Deep Learning JP
Recently uploaded
PDF
エンジニアが選ぶべきAIエディタ & Antigravity 活用例@ウェビナー「触ってみてどうだった?Google Antigravity 既存IDEと...
by
NorihiroSunada
PDF
流行りに乗っかるClaris FileMaker 〜AI関連機能の紹介〜 by 合同会社イボルブ
by
Evolve LLC.
PPTX
楽々ナレッジベース「楽ナレ」3種比較 - Dify / AWS S3 Vector / Google File Search Tool
by
Kiyohide Yamaguchi
PDF
20251210_MultiDevinForEnterprise on Devin 1st Anniv Meetup
by
Masaki Yamakawa
PDF
Machine Tests Benchmark Suite. Explain github.com/alexziskind1/machine_tests #2
by
Tasuku Takahashi
PDF
Machine Tests Benchmark Suite. Explain github.com/alexziskind1/machine_tests #1
by
Tasuku Takahashi
エンジニアが選ぶべきAIエディタ & Antigravity 活用例@ウェビナー「触ってみてどうだった?Google Antigravity 既存IDEと...
by
NorihiroSunada
流行りに乗っかるClaris FileMaker 〜AI関連機能の紹介〜 by 合同会社イボルブ
by
Evolve LLC.
楽々ナレッジベース「楽ナレ」3種比較 - Dify / AWS S3 Vector / Google File Search Tool
by
Kiyohide Yamaguchi
20251210_MultiDevinForEnterprise on Devin 1st Anniv Meetup
by
Masaki Yamakawa
Machine Tests Benchmark Suite. Explain github.com/alexziskind1/machine_tests #2
by
Tasuku Takahashi
Machine Tests Benchmark Suite. Explain github.com/alexziskind1/machine_tests #1
by
Tasuku Takahashi
[DL輪読会]Dream to Control: Learning Behaviors by Latent Imagination
1.
DEEP LEARNING JP [DL
Papers] Dream to Control: Learning Behaviors by Latent Imagination Hiroki Furuta http://deeplearning.jp/
2.
書誌情報 • タイトル: Dream
to Control: Learning Behaviors by Latent Imagination • 著者: Danijar Hafner12, Timothy Lillicrap3, Jimmy Ba1, Mohammad Norouzi2 • 所属: 1University of Toronto, 2Google Brain, 3DeepMind • 会議: ICLR2020, Spotlight • URL: https://openreview.net/forum?id=S1lOTC4tDS, https://arxiv.org/abs/1912.01603 • 概要: 画像入力でlong-horizonなタスクを潜在空間における想像(latent imagination)のみによって解く, モデルベース強化学習のアルゴリズム, Dreamerを 提案 2
3.
研究背景 • 深層学習によって, 画像入力から将来の予測が可能な潜在空間のダイナミクス モデルを学習することが可能になった •
ダイナミクスモデルから制御方策を獲得する方法はいくつか存在 予測される報酬を最大化するようにパラメタ化した方策を学習 • Dyna[Sutton 1991], World models[Ha and Schmidhuber 2018], SOLAR[Zhang et al. 2018]など Online planning • PETS[Chua et al. 2018], PlaNet[Hafner et al. 2018]など • Neural Networkによるダイナミクスモデルでは勾配が計算できることを利用して long-horizonなタスクを解きたい 固定長のimagination horizon(ダイナミクズモデルから生成される軌道)における報酬の最大 化を図ると近視眼的な方策に陥りがちなため 3
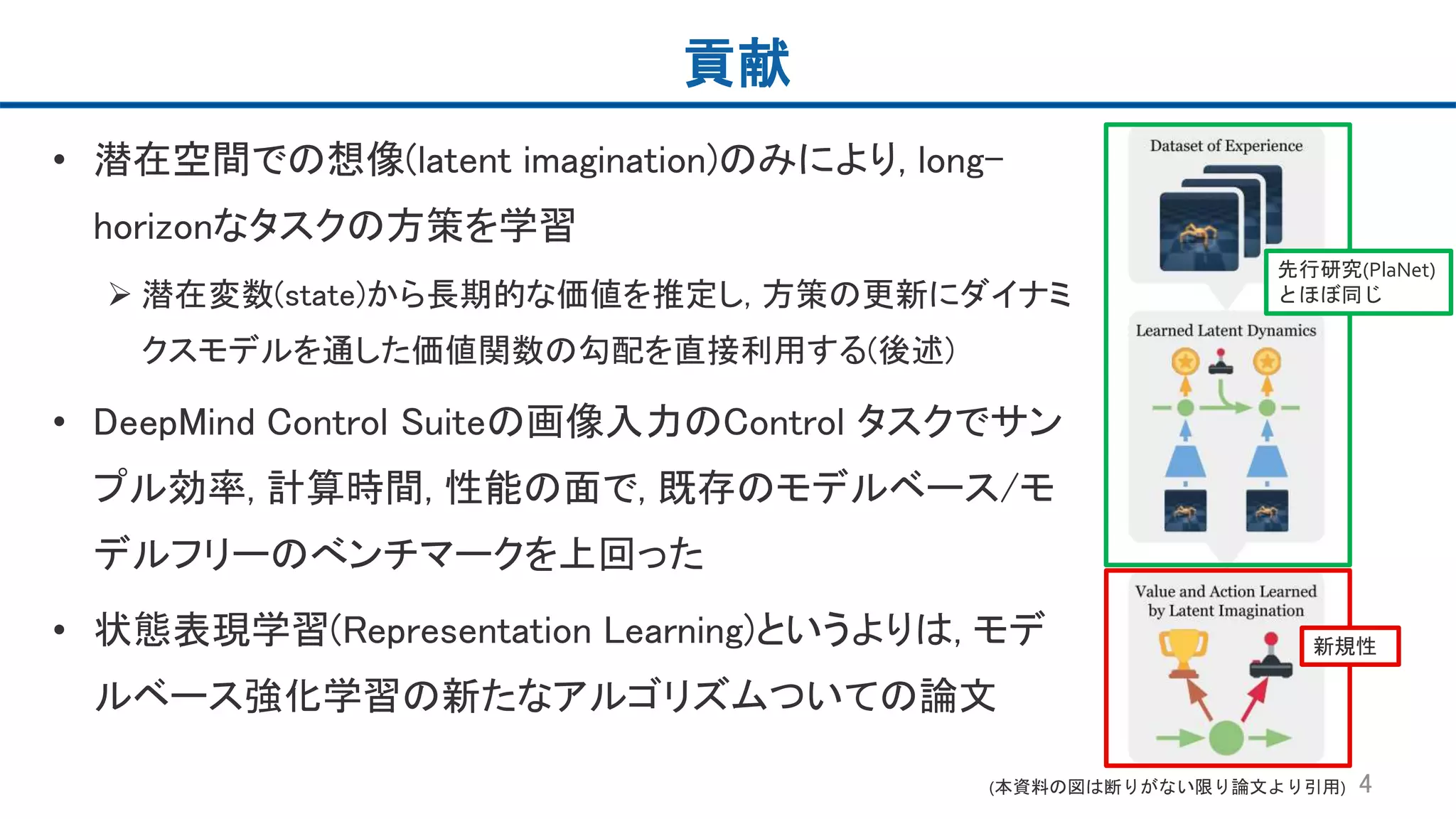
4.
貢献 • 潜在空間での想像(latent imagination)のみにより,
long- horizonなタスクの方策を学習 潜在変数(state)から長期的な価値を推定し, 方策の更新にダイナミ クスモデルを通した価値関数の勾配を直接利用する(後述) • DeepMind Control Suiteの画像入力のControl タスクでサン プル効率, 計算時間, 性能の面で, 既存のモデルベース/モ デルフリーのべンチマークを上回った • 状態表現学習(Representation Learning)というよりは, モデ ルベース強化学習の新たなアルゴリズムついての論文 4(本資料の図は断りがない限り論文より引用) 先行研究(PlaNet) とほぼ同じ 新規性
5.
準備: 問題設定 • 画像入力なので部分観測Markov
Decision Process(POMDP)を仮定 離散 time step 𝑡 ∈ 1; 𝑇 エージェントの出力する連続値action(ベクトル) 𝑎 𝑡 ~ 𝑝 𝑎 𝑡 𝑜≤𝑡, 𝑎<𝑡 観測(今回は画像)と報酬(スカラー) 𝑜𝑡, 𝑟𝑡 ~ 𝑝 𝑜𝑡, 𝑟𝑡 𝑜<𝑡, 𝑎<𝑡) • 今回は環境は未知 目標は期待報酬の和を最大化する方策を学習すること Ε 𝑝(∑ 𝑡=1 𝑇 𝑟𝑡) 5 DeepMindControl Suitから20 タスクを実験に使用(図はそのう ちの5つの例)
6.
準備: エージェント • モデルベース強化学習でimaginationから学習するエージェントは以下の3 つの要素を繰り返すことで学習する[Sutton,
1991] ダイナミクスモデルの学習 • 今回はlatent dynamics 方策の学習 • 今回は方策の更新にダイナミクスモデルを通した価値関数の勾配を直接利用 環境との相互作用 • ダイナミクスモデルのデータセットを拡張するため 6
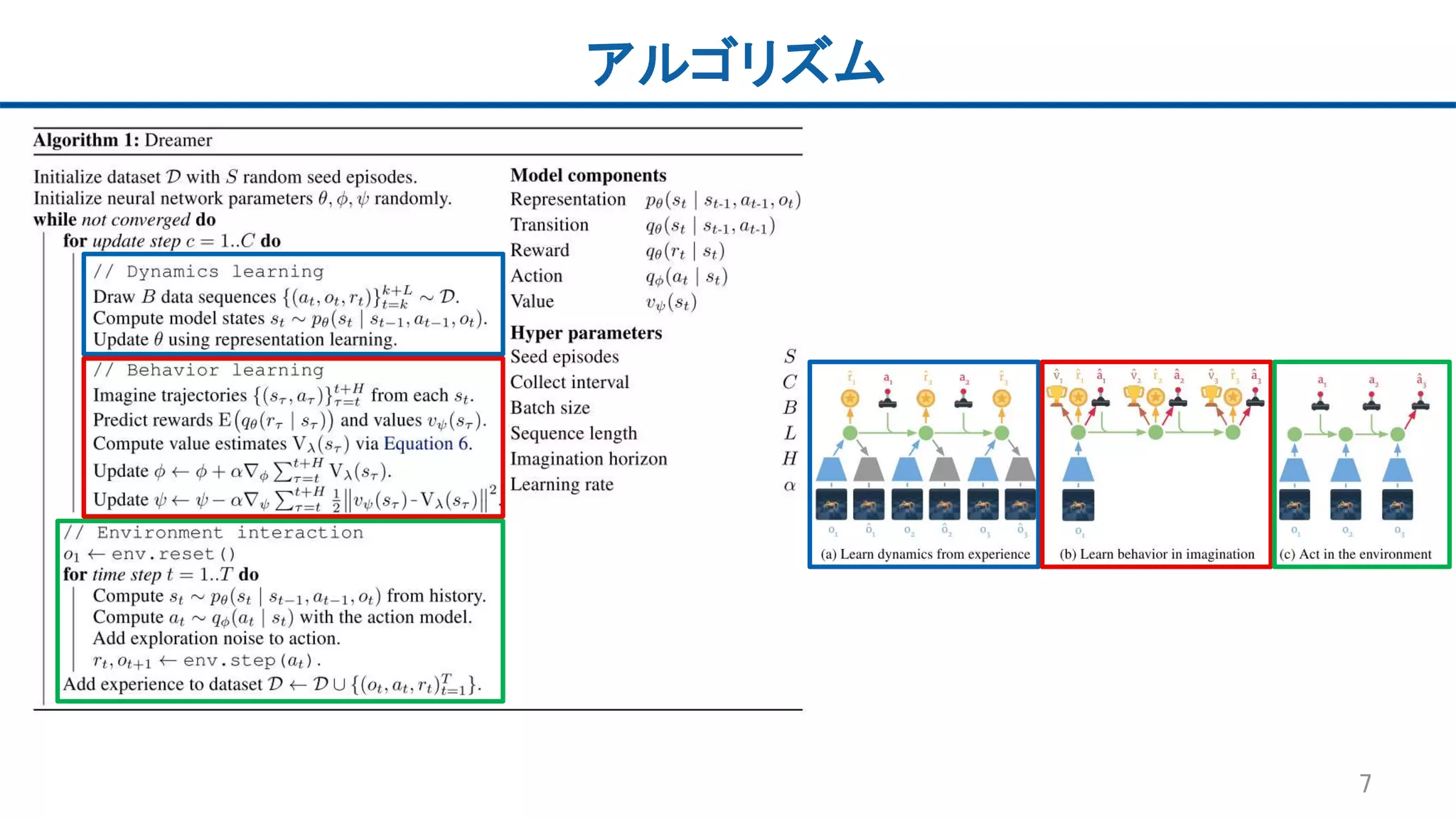
7.
アルゴリズム 7
8.
ダイナミクスモデルの学習: Latent dynamics Dreamerで用いるLatent
dynamicsは3つのモデルからなる • Representation model 𝑝(𝑠𝑡|𝑠𝑡−1, 𝑎 𝑡−1, 𝑜𝑡) 観測𝑜𝑡とaction 𝑎 𝑡−1からマルコフ性を仮定した連続値ベクトルのstate(潜在変数) 𝑠𝑡 をエンコード • Transition model 𝑞(𝑠𝑡|𝑠𝑡−1, 𝑎 𝑡−1) 観測𝑜𝑡によらない潜在空間上の遷移のモデル (latent imaginationに使用) • Reward model 𝑞(𝑟𝑡|𝑠𝑡) state 𝑠𝑡における報酬𝑟𝑡の予測モデル (latent imaginationに使用) 8
9.
ダイナミクスモデルの学習: Reward Prediction ダイナミクスモデルの学習には代表的な3つのアプローチがある •
Reward Prediction 前ページで説明したRepresentation model, Transition model, Reward modelを, 行動 と過去の観測で条件づけられた将来の報酬の予測から学習する方法 大量で多様なデータがあればControl taskを解くのに十分なモデルが学習できる(ら しい) • Reconstruction • Contrastive estimation 9
10.
ダイナミクスモデルの学習: Reconstruction Reconstruction • PlaNet[Hafner
et al. 2018]同様, 観測の画像の再構成によって学習 Observation modelは学習時のみ使用 Transition modelとRepresentation modelはRecurrent State Space Model(RSSM)で 実装 10 ※PlaNetについて詳しくは谷口さんの過去の輪読資料を参照してください https://www.slideshare.net/DeepLearningJP2016/dllearning-latent-dynamics- for-planning-from-pixels
11.
ダイナミクスモデルの学習: Latent dynamics Contrastive
estimation • 画像の再構成以外の方法としてNoise Contrastive Estimation(NCE)による 学習がある ReconstructionのObservation modelをState modelに置き換える 実験では3つの性能を比較 11 Constructive Estimation Reconstruction
12.
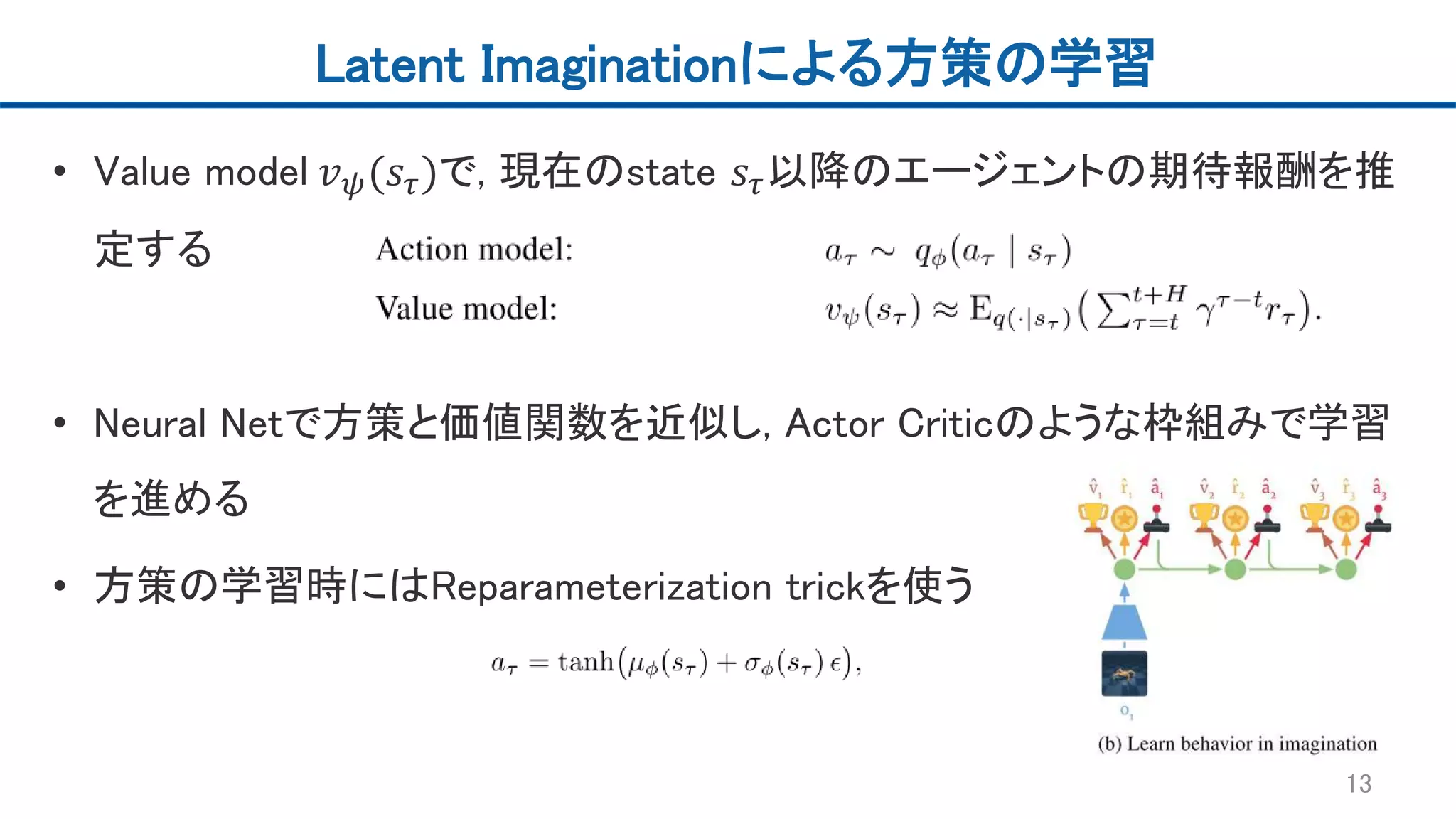
Latent Imaginationによる方策の学習 • State
𝑠𝑡(潜在空間)にはMDPを仮定 • 過去の経験の観測𝑜𝑡からエンコードされた𝑠𝑡をスタートとして, Transition model 𝑠𝜏 ~ 𝑞(𝑠𝜏|𝑠𝜏, 𝑎 𝜏), Reward model 𝑟𝜏 ~ 𝑞(𝑟𝜏|𝑠𝜏), 方策 𝑎 𝜏 ~ 𝑞 𝑎 𝜏 𝑠𝜏 を 順番に予測することで有限のhorizon 𝐻のimagined trajectoryを出力 12
13.
Latent Imaginationによる方策の学習 • Value
model 𝑣 𝜓(𝑠𝜏)で, 現在のstate 𝑠𝜏以降のエージェントの期待報酬を推 定する • Neural Netで方策と価値関数を近似し, Actor Criticのような枠組みで学習 を進める • 方策の学習時にはReparameterization trickを使う 13
14.
Long Horizonな価値の推定 • Value
model 𝑣 𝜓(𝑠𝜏)を用いて, k-step先まで考慮した価値関数𝑉𝑁 𝑘 と,異なる 長さ𝑘について指数的に重み付けして平均された価値関数𝑉𝜆の値の推定を 行う(本論文の要点1) 𝑉𝑅はValue modelを持たない価値関数(実験で𝑉𝜆の効果を比較) (今回の実験では𝐻 = 15ぐらいでいいらしい) 14
15.
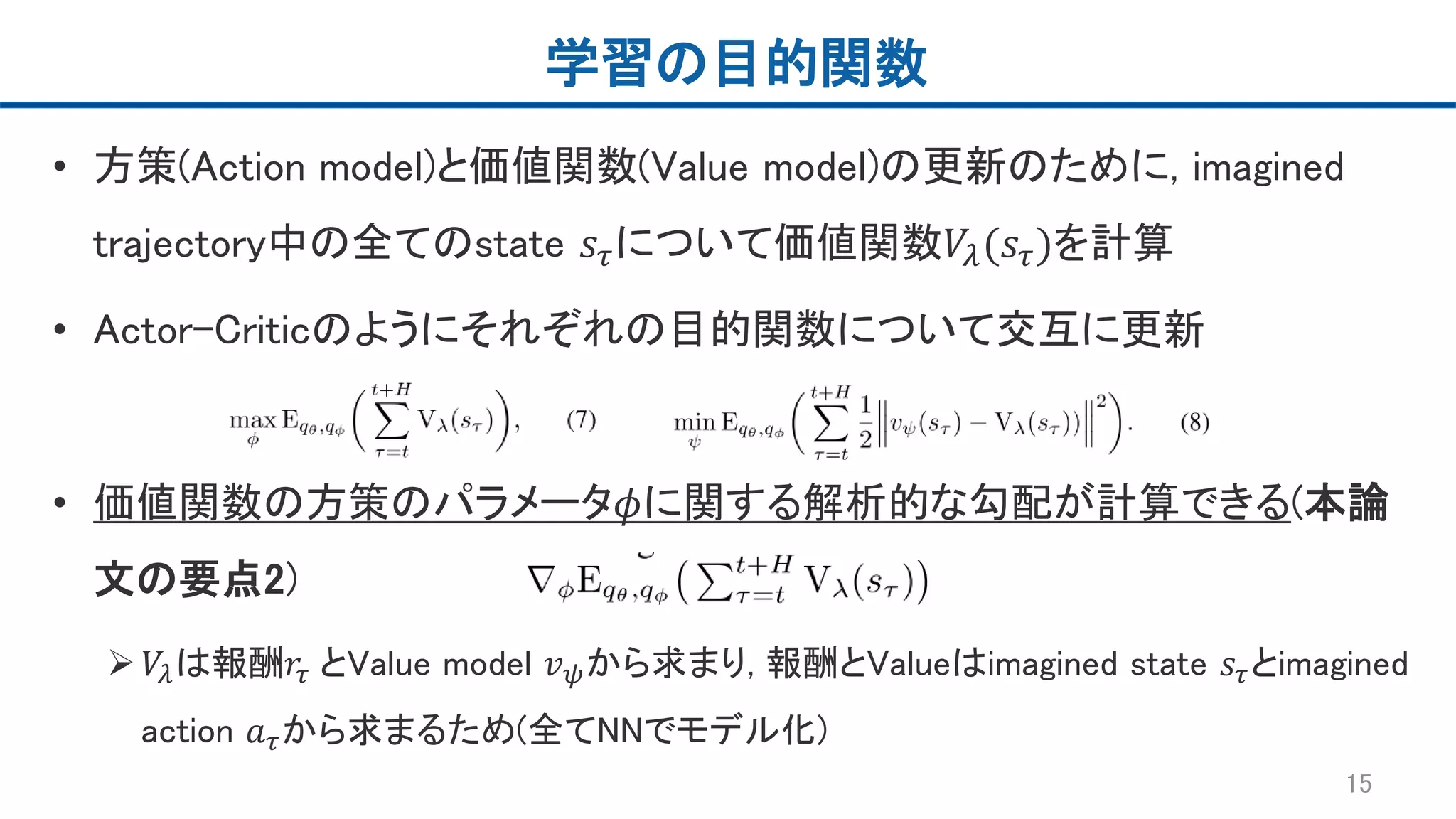
学習の目的関数 • 方策(Action model)と価値関数(Value
model)の更新のために, imagined trajectory中の全てのstate 𝑠𝜏について価値関数𝑉𝜆(𝑠𝜏)を計算 • Actor-Criticのようにそれぞれの目的関数について交互に更新 • 価値関数の方策のパラメータ𝜙に関する解析的な勾配が計算できる(本論 文の要点2) 𝑉𝜆は報酬𝑟𝜏 とValue model 𝑣 𝜓から求まり, 報酬とValueはimagined state 𝑠𝜏とimagined action 𝑎 𝜏から求まるため(全てNNでモデル化) 15
16.
既存研究との差分 • DDPG, SAC:
方策の目的関数にQ-valueを用いている点で異なる • A3C, PPO: これらは方策勾配のvarianceを下げるためにベースラインとして 価値関数を用いるが, Dreamerは直接価値関数を微分する • MVE[Feinberg et al. 2018] , STEVE[Buckman et al. 2018] : 複数ステップ先を考慮したQ- learningをダイナミクスモデルを用いて行うが, ダイミクスモデルを通した微 分を行わない点と, Dreamerは価値関数𝑉のみで学習する点で異なる 16
17.
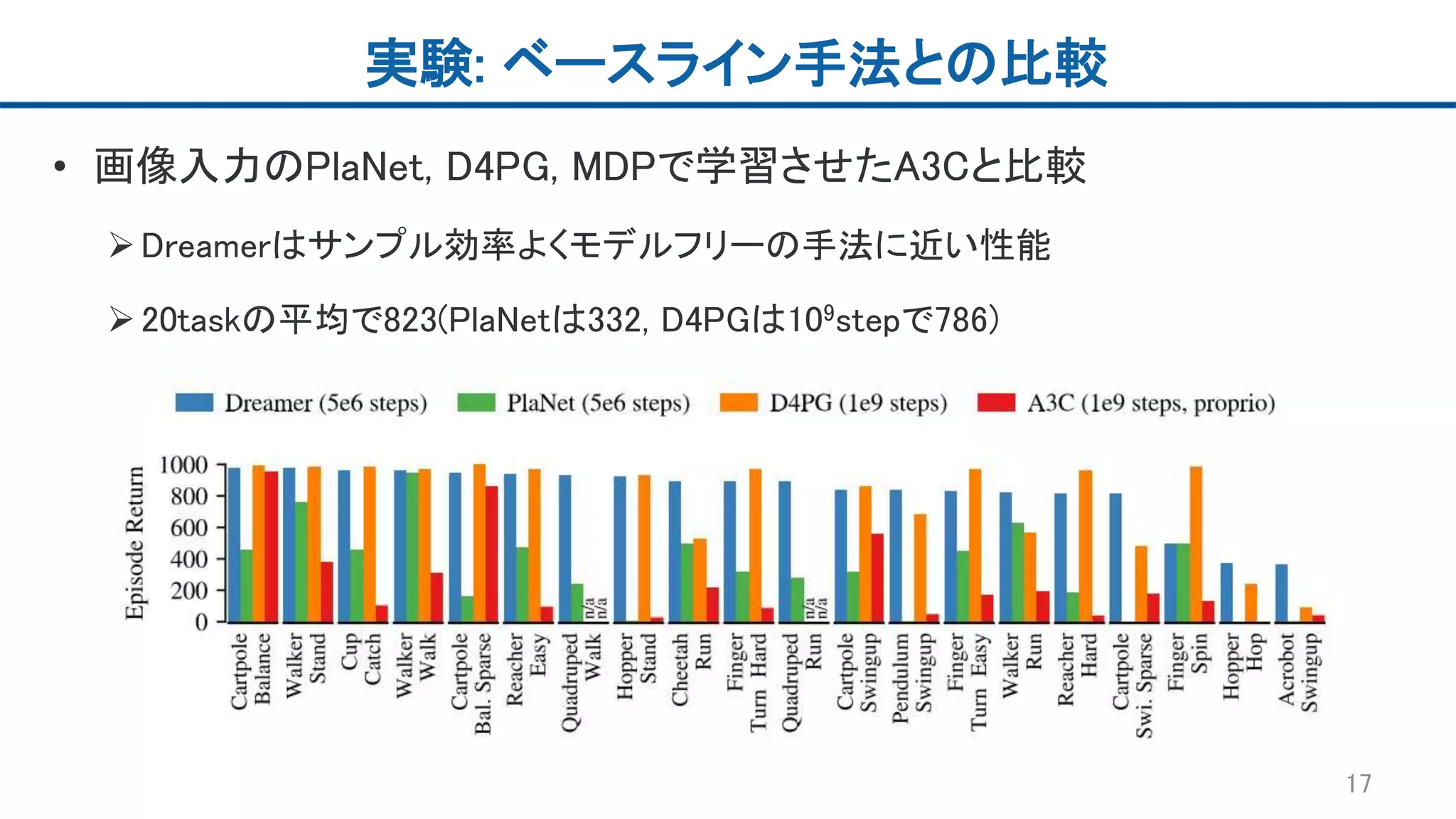
実験: ベースライン手法との比較 • 画像入力のPlaNet,
D4PG, MDPで学習させたA3Cと比較 Dreamerはサンプル効率よくモデルフリーの手法に近い性能 20taskの平均で823(PlaNetは332, D4PGは109stepで786) 17
18.
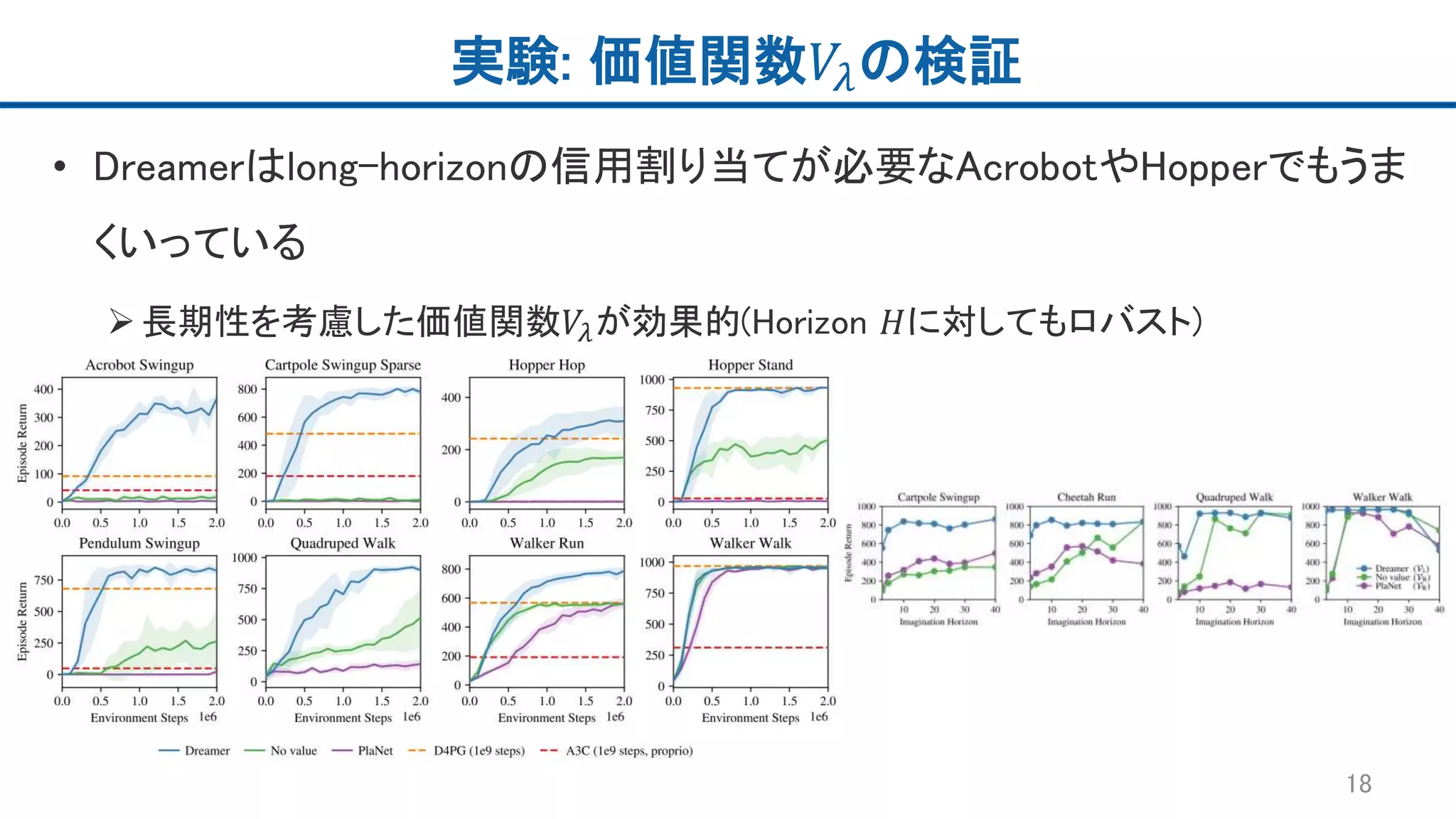
実験: 価値関数𝑉𝜆の検証 • Dreamerはlong-horizonの信用割り当てが必要なAcrobotやHopperでもうま くいっている 長期性を考慮した価値関数𝑉𝜆が効果的(Horizon
𝐻に対してもロバスト) 18
19.
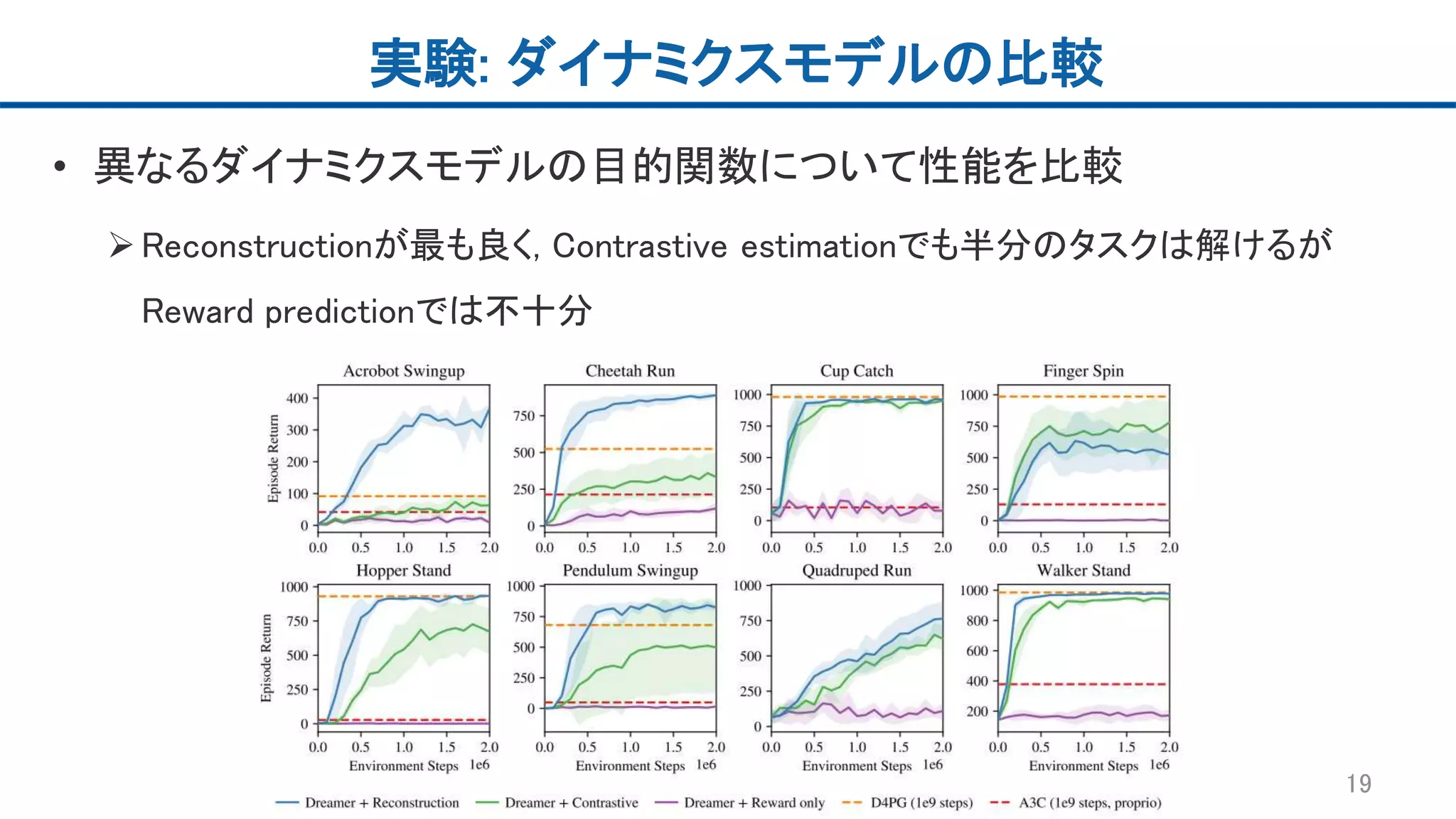
実験: ダイナミクスモデルの比較 • 異なるダイナミクスモデルの目的関数について性能を比較 Reconstructionが最も良く,
Contrastive estimationでも半分のタスクは解けるが Reward predictionでは不十分 19
20.
まとめ • 潜在空間での想像(latent imagination)のみにより,
long-horizonなタスクの 方策を学習する手法 Dreamerを提案 • ダイナミクスモデルとimagined trajectory全体を通して, 方策の価値関数に 関する勾配を直接計算 感想 ダイナミクスモデルや学習方法についての拡張性が高い 画像入力のロボットアームのタスクでも解けるのか気になる 20
Download
![DEEP LEARNING JP
[DL Papers]
Dream to Control: Learning Behaviors by Latent
Imagination
Hiroki Furuta
http://deeplearning.jp/](https://image.slidesharecdn.com/20200313furutav2-200313025657/75/DL-Dream-to-Control-Learning-Behaviors-by-Latent-Imagination-1-2048.jpg)

![研究背景
• 深層学習によって, 画像入力から将来の予測が可能な潜在空間のダイナミクス
モデルを学習することが可能になった
• ダイナミクスモデルから制御方策を獲得する方法はいくつか存在
予測される報酬を最大化するようにパラメタ化した方策を学習
• Dyna[Sutton 1991], World models[Ha and Schmidhuber 2018], SOLAR[Zhang et al. 2018]など
Online planning
• PETS[Chua et al. 2018], PlaNet[Hafner et al. 2018]など
• Neural Networkによるダイナミクスモデルでは勾配が計算できることを利用して
long-horizonなタスクを解きたい
固定長のimagination horizon(ダイナミクズモデルから生成される軌道)における報酬の最大
化を図ると近視眼的な方策に陥りがちなため
3](https://image.slidesharecdn.com/20200313furutav2-200313025657/75/DL-Dream-to-Control-Learning-Behaviors-by-Latent-Imagination-3-2048.jpg)

![準備: エージェント
• モデルベース強化学習でimaginationから学習するエージェントは以下の3
つの要素を繰り返すことで学習する[Sutton, 1991]
ダイナミクスモデルの学習
• 今回はlatent dynamics
方策の学習
• 今回は方策の更新にダイナミクスモデルを通した価値関数の勾配を直接利用
環境との相互作用
• ダイナミクスモデルのデータセットを拡張するため
6](https://image.slidesharecdn.com/20200313furutav2-200313025657/75/DL-Dream-to-Control-Learning-Behaviors-by-Latent-Imagination-6-2048.jpg)


![ダイナミクスモデルの学習: Reconstruction
Reconstruction
• PlaNet[Hafner et al. 2018]同様, 観測の画像の再構成によって学習
Observation modelは学習時のみ使用
Transition modelとRepresentation modelはRecurrent State Space Model(RSSM)で
実装
10
※PlaNetについて詳しくは谷口さんの過去の輪読資料を参照してください
https://www.slideshare.net/DeepLearningJP2016/dllearning-latent-dynamics-
for-planning-from-pixels](https://image.slidesharecdn.com/20200313furutav2-200313025657/75/DL-Dream-to-Control-Learning-Behaviors-by-Latent-Imagination-10-2048.jpg)



![既存研究との差分
• DDPG, SAC: 方策の目的関数にQ-valueを用いている点で異なる
• A3C, PPO: これらは方策勾配のvarianceを下げるためにベースラインとして
価値関数を用いるが, Dreamerは直接価値関数を微分する
• MVE[Feinberg et al. 2018] , STEVE[Buckman et al. 2018] : 複数ステップ先を考慮したQ-
learningをダイナミクスモデルを用いて行うが, ダイミクスモデルを通した微
分を行わない点と, Dreamerは価値関数𝑉のみで学習する点で異なる
16](https://image.slidesharecdn.com/20200313furutav2-200313025657/75/DL-Dream-to-Control-Learning-Behaviors-by-Latent-Imagination-16-2048.jpg)


![[DL輪読会]Learning Latent Dynamics for Planning from Pixels](https://cdn.slidesharecdn.com/ss_thumbnails/taniguchi20181221-190104064850-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DL輪読会]“SimPLe”,“Improved Dynamics Model”,“PlaNet” 近年のVAEベース系列モデルの進展とそのモデルベース...](https://cdn.slidesharecdn.com/ss_thumbnails/20190426akuzawa-190426020057-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]World Models](https://cdn.slidesharecdn.com/ss_thumbnails/20180427-180427003856-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]Control as Inferenceと発展](https://cdn.slidesharecdn.com/ss_thumbnails/20191004-191204055019-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DL輪読会]相互情報量最大化による表現学習](https://cdn.slidesharecdn.com/ss_thumbnails/20190913iwasawa-190913002312-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]Decision Transformer: Reinforcement Learning via Sequence Modeling](https://cdn.slidesharecdn.com/ss_thumbnails/decisiontransformer20210709zhangxin-210709021501-thumbnail.jpg?width=640&height=640&fit=bounds)






![[DL輪読会]Life-Long Disentangled Representation Learning with Cross-Domain Laten...](https://cdn.slidesharecdn.com/ss_thumbnails/20180914iwasawa-180919025635-thumbnail.jpg?width=640&height=640&fit=bounds)












![[DL輪読会]Temporal DifferenceVariationalAuto-Encoder](https://cdn.slidesharecdn.com/ss_thumbnails/20181130new-190205051636-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]Imagination-Augmented Agents for Deep Reinforcement Learning / Learnin...](https://cdn.slidesharecdn.com/ss_thumbnails/dlhacksshioya201707281-170728054152-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]Shaping Belief States with Generative Environment Models for RL](https://cdn.slidesharecdn.com/ss_thumbnails/20190705suzuki-191204061058-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]Learning Task Informed Abstractions](https://cdn.slidesharecdn.com/ss_thumbnails/20210709akuzawa-210709021836-thumbnail.jpg?width=640&height=640&fit=bounds)




![[DL輪読会]Learning to Act by Predicting the Future](https://cdn.slidesharecdn.com/ss_thumbnails/20171113dl-171114045641-thumbnail.jpg?width=640&height=640&fit=bounds)




![[DL輪読会]Learning to Adapt: Meta-Learning for Model-Based Control](https://cdn.slidesharecdn.com/ss_thumbnails/20180511dl-180511004107-thumbnail.jpg?width=640&height=640&fit=bounds)




























