Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
EN
MN
Uploaded by
Masato Nakai
PDF, PPTX
6,948 views
Word2vecの理論背景
This explains about theoretical background of word2vec by the paper of PMI embeddings Analysis.
Data & Analytics
◦
Read more
21
Save
Share
Embed
Embed presentation
Download
Download as PDF, PPTX
1
/ 20
2
/ 20
3
/ 20
4
/ 20
5
/ 20
6
/ 20
7
/ 20
8
/ 20
9
/ 20
10
/ 20
11
/ 20
12
/ 20
13
/ 20
14
/ 20
15
/ 20
16
/ 20
17
/ 20
18
/ 20
19
/ 20
20
/ 20
More Related Content
PPTX
Transformerを雰囲気で理解する
by
AtsukiYamaguchi1
PDF
数式からみるWord2Vec
by
Okamoto Laboratory, The University of Electro-Communications
PDF
【論文調査】XAI技術の効能を ユーザ実験で評価する研究
by
Satoshi Hara
PPTX
【解説】 一般逆行列
by
Kenjiro Sugimoto
PDF
グラフニューラルネットワーク入門
by
ryosuke-kojima
PDF
ブラックボックス最適化とその応用
by
gree_tech
PDF
Optimizer入門&最新動向
by
Motokawa Tetsuya
PDF
Attentionの基礎からTransformerの入門まで
by
AGIRobots
Transformerを雰囲気で理解する
by
AtsukiYamaguchi1
数式からみるWord2Vec
by
Okamoto Laboratory, The University of Electro-Communications
【論文調査】XAI技術の効能を ユーザ実験で評価する研究
by
Satoshi Hara
【解説】 一般逆行列
by
Kenjiro Sugimoto
グラフニューラルネットワーク入門
by
ryosuke-kojima
ブラックボックス最適化とその応用
by
gree_tech
Optimizer入門&最新動向
by
Motokawa Tetsuya
Attentionの基礎からTransformerの入門まで
by
AGIRobots
What's hot
PDF
計算論的学習理論入門 -PAC学習とかVC次元とか-
by
sleepy_yoshi
PDF
Bayesian Neural Networks : Survey
by
tmtm otm
PPTX
【DL輪読会】Efficiently Modeling Long Sequences with Structured State Spaces
by
Deep Learning JP
PDF
cvpaper.challenge 研究効率化 Tips
by
cvpaper. challenge
PDF
MICの解説
by
logics-of-blue
PDF
Transformerを多層にする際の勾配消失問題と解決法について
by
Sho Takase
PDF
機械学習モデルのハイパパラメータ最適化
by
gree_tech
PPTX
Triplet Loss 徹底解説
by
tancoro
PDF
最適輸送の解き方
by
joisino
PDF
BERT入門
by
Ken'ichi Matsui
PPTX
【DL輪読会】Flow Matching for Generative Modeling
by
Deep Learning JP
PDF
クラシックな機械学習入門:付録:よく使う線形代数の公式
by
Hiroshi Nakagawa
PDF
サポートベクターマシン(SVM)の数学をみんなに説明したいだけの会
by
Kenyu Uehara
PDF
3分でわかる多項分布とディリクレ分布
by
Junya Saito
PDF
深層学習の不確実性 - Uncertainty in Deep Neural Networks -
by
tmtm otm
PDF
組合せ最適化入門:線形計画から整数計画まで
by
Shunji Umetani
PPTX
猫でも分かるVariational AutoEncoder
by
Sho Tatsuno
PDF
ELBO型VAEのダメなところ
by
KCS Keio Computer Society
PPTX
[DL輪読会]Set Transformer: A Framework for Attention-based Permutation-Invariant...
by
Deep Learning JP
PDF
プログラミングコンテストでのデータ構造 2 ~動的木編~
by
Takuya Akiba
計算論的学習理論入門 -PAC学習とかVC次元とか-
by
sleepy_yoshi
Bayesian Neural Networks : Survey
by
tmtm otm
【DL輪読会】Efficiently Modeling Long Sequences with Structured State Spaces
by
Deep Learning JP
cvpaper.challenge 研究効率化 Tips
by
cvpaper. challenge
MICの解説
by
logics-of-blue
Transformerを多層にする際の勾配消失問題と解決法について
by
Sho Takase
機械学習モデルのハイパパラメータ最適化
by
gree_tech
Triplet Loss 徹底解説
by
tancoro
最適輸送の解き方
by
joisino
BERT入門
by
Ken'ichi Matsui
【DL輪読会】Flow Matching for Generative Modeling
by
Deep Learning JP
クラシックな機械学習入門:付録:よく使う線形代数の公式
by
Hiroshi Nakagawa
サポートベクターマシン(SVM)の数学をみんなに説明したいだけの会
by
Kenyu Uehara
3分でわかる多項分布とディリクレ分布
by
Junya Saito
深層学習の不確実性 - Uncertainty in Deep Neural Networks -
by
tmtm otm
組合せ最適化入門:線形計画から整数計画まで
by
Shunji Umetani
猫でも分かるVariational AutoEncoder
by
Sho Tatsuno
ELBO型VAEのダメなところ
by
KCS Keio Computer Society
[DL輪読会]Set Transformer: A Framework for Attention-based Permutation-Invariant...
by
Deep Learning JP
プログラミングコンテストでのデータ構造 2 ~動的木編~
by
Takuya Akiba
Similar to Word2vecの理論背景
PPTX
自然言語処理 Word2vec
by
naoto moriyama
PDF
【2016年度】勉強会資料_word2vec
by
Ryosuke Tanno
PPTX
【論文紹介】Distributed Representations of Sentences and Documents
by
Tomofumi Yoshida
PPTX
Enriching Word Vectors with Subword Information
by
harmonylab
PPTX
Enriching Word Vectors with Subword Information
by
harmonylab
PPTX
Interop2017
by
tak9029
PDF
100816 nlpml sec2
by
shirakia
PDF
Word2vecの並列実行時の学習速度の改善
by
Naoaki Okazaki
PPTX
fastTextの実装を見てみた
by
Yoshihiko Shiraki
PDF
2016word embbed
by
Shin Asakawa
PDF
Word2vec alpha
by
KCS Keio Computer Society
PDF
[DL輪読会]data2vec: A General Framework for Self-supervised Learning in Speech,...
by
Deep Learning JP
PPTX
Variational Template Machine for Data-to-Text Generation
by
harmonylab
PDF
TensorFlow math ja 05 word2vec
by
Shin Asakawa
自然言語処理 Word2vec
by
naoto moriyama
【2016年度】勉強会資料_word2vec
by
Ryosuke Tanno
【論文紹介】Distributed Representations of Sentences and Documents
by
Tomofumi Yoshida
Enriching Word Vectors with Subword Information
by
harmonylab
Enriching Word Vectors with Subword Information
by
harmonylab
Interop2017
by
tak9029
100816 nlpml sec2
by
shirakia
Word2vecの並列実行時の学習速度の改善
by
Naoaki Okazaki
fastTextの実装を見てみた
by
Yoshihiko Shiraki
2016word embbed
by
Shin Asakawa
Word2vec alpha
by
KCS Keio Computer Society
[DL輪読会]data2vec: A General Framework for Self-supervised Learning in Speech,...
by
Deep Learning JP
Variational Template Machine for Data-to-Text Generation
by
harmonylab
TensorFlow math ja 05 word2vec
by
Shin Asakawa
More from Masato Nakai
PDF
Padoc_presen4R.pdf
by
Masato Nakai
PDF
Factor analysis for ml by padoc 6 r
by
Masato Nakai
PDF
報酬が殆ど得られない場合の強化学習
by
Masato Nakai
PDF
Padocview anonimous2
by
Masato Nakai
PDF
presentation for padoc
by
Masato Nakai
PDF
Ai neuro science_pdf
by
Masato Nakai
PDF
Deep IRL by C language
by
Masato Nakai
PDF
Open pose時系列解析7
by
Masato Nakai
PDF
Team ai 3
by
Masato Nakai
PDF
Semi vae memo (2)
by
Masato Nakai
PDF
Open posedoc
by
Masato Nakai
PPT
Dr.raios papers
by
Masato Nakai
PDF
Deep genenergyprobdoc
by
Masato Nakai
PDF
Irs gan doc
by
Masato Nakai
PDF
Semi vae memo (1)
by
Masato Nakai
PDF
Ai論文サイト
by
Masato Nakai
PDF
Vae gan nlp
by
Masato Nakai
PDF
機械学習の全般について 4
by
Masato Nakai
PDF
粒子フィルターによる自動運転
by
Masato Nakai
PDF
Icpによる原画像推定
by
Masato Nakai
Padoc_presen4R.pdf
by
Masato Nakai
Factor analysis for ml by padoc 6 r
by
Masato Nakai
報酬が殆ど得られない場合の強化学習
by
Masato Nakai
Padocview anonimous2
by
Masato Nakai
presentation for padoc
by
Masato Nakai
Ai neuro science_pdf
by
Masato Nakai
Deep IRL by C language
by
Masato Nakai
Open pose時系列解析7
by
Masato Nakai
Team ai 3
by
Masato Nakai
Semi vae memo (2)
by
Masato Nakai
Open posedoc
by
Masato Nakai
Dr.raios papers
by
Masato Nakai
Deep genenergyprobdoc
by
Masato Nakai
Irs gan doc
by
Masato Nakai
Semi vae memo (1)
by
Masato Nakai
Ai論文サイト
by
Masato Nakai
Vae gan nlp
by
Masato Nakai
機械学習の全般について 4
by
Masato Nakai
粒子フィルターによる自動運転
by
Masato Nakai
Icpによる原画像推定
by
Masato Nakai
Word2vecの理論背景
1.
word2vecの理論背景 mabonki0725 2016/12/17
2.
自己紹介 • データ分析と統計モデル構築15年 – 学習データ以外の運用データでも予測が当たることに驚く •
統計数理研究所の機械学習ゼミに6年間在籍 – 殆どの統計モデルを構築 判別木 SVM ベイジアンネット DeepLearning等 • ロボット技術習得のため産業技術大学院に入学 – 知覚・機械学習・制御理論の統合が必要で発展途上の技術 • 経験的には米国の機械学習の論文を読み、できれば 実装するのが一番近道と思っている – NIPS ICML論文読会したい(隔週開催) • 教師あり学習のXGBOOSTの性能に驚いている
3.
word2vecとは • 大量の文書をよんで文字をvectorで表現にする – vectorなので加減算で推論・推薦ができる •
連想 vec(日本) - vec(東京) + vec(パリ) → vec(フランス) • 推奨 映画のBacktoFutureにviolenceを強くした映画は? vec(バックツウザフューチャ) + 2×vec(暴力) → vec(ターミネータ) + =2×violence
4.
word2vecの背景理論 ①なぜword2vecはvectorを使うのか ②なぜword2vecは学習できるのか ③なぜword2vecは加減算で推論できるのか word2vecの理論背景には以下の論文と解説がある ①A Latent Variable
Model Approach to PMI-basedWord Embeddings Sanjeev Arora+ (TACL 2016) ②統数研 持橋大地先生の解説資料 (最先端NLP8) http://chasen.org/~daiti-m/paper/SNLP8-latent.pdf
5.
①word2vecはvectorを使うのか • word2vecのvectorの推定方法(skip-gram) – 最適なvector算出するためvectorの内積を使う –
発生確率を教師データとするsoftmaxの回帰モデル 単語Wiとその前後の単語Woの発生確率 教師データ softmax関数
6.
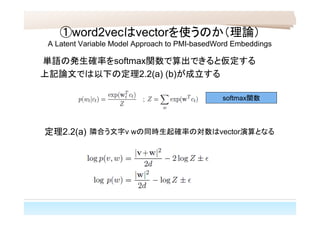
①word2vecはvectorを使うのか(理論) A Latent Variable
Model Approach to PMI-basedWord Embeddings 単語の発生確率をsoftmax関数で算出できると仮定する 上記論文では以下の定理2.2(a) (b)が成立する 定理2.2(a) 隣合う文字v wの同時生起確率の対数はvector演算となる softmax関数
7.
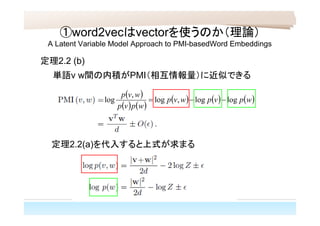
①word2vecはvectorを使うのか(理論) A Latent Variable
Model Approach to PMI-basedWord Embeddings 定理2.2 (b) 単語v w間の内積がPMI(相互情報量)に近似できる 定理2.2(a)を代入すると上式が求まる wpvpwvp wpvp wvp loglog,log , log
8.
PMI情報量 • (he has)
(are the) 等のよく出てくる結びつきは意味がない。 (beer wine) (oil economy)の結びつきは意味がある • 頻繁に出てこない単語でよく見るペアに意味がある • PMI情報量は頻繁に出ないが、よく見るペアを表す word2vecはPMI情報量(単語の内積)で回帰してvectorを求めている。 教師データ softmax関数
9.
①word2vecはvectorを使うのか(証明) A Latent Variable
Model Approach to PMI-basedWord Embeddings <前提> 時刻t において, ランダムウォークする文脈ベクトルct があり 単語vecotor wt の発生確率はsoftmax関数に従がうと仮定 この前提で観測するとZはCtに拘らず1
10.
• 定理2.2 (a)の証明 ①word2vecはvectorを使うのか(証明) A
Latent Variable Model Approach to PMI-basedWord Embeddings 定理2.2(a)
11.
• 定理2.2の証明 ①word2vecはvectorを使うのか(証明) A Latent
Variable Model Approach to PMI-basedWord Embeddings ※
12.
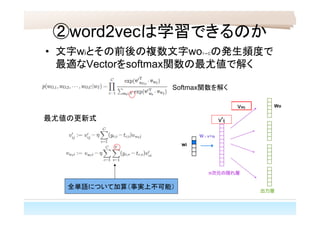
②word2vecは学習できるのか • 文字wiとその前後の複数文字wo1~Cの発生頻度で 最適なVectorをsoftmax関数の最尤値で解く 最尤値の更新式 Softmax関数を解く Wovwji v'ij 全単語について加算(事実上不可能) wi
13.
②word2vecは学習できるのか • word2vecの最尤値解の簡便化? 分母側を全単語ではなく、ランダム抽出とする NegativeSampling法 計算量の削減 V(全語)→VNeg(ランダム抽出) σ:シグモイド関数 Wovwji v'ij wi
14.
②word2vecは学習できるのか(理論) • 対数尤度Lを最大となるVector v
w を学習できればよい Xvwは生起回数 これから
15.
②word2vecの学習できるのか(証明) よって
16.
②word2vecは学習できるのか(証明) ※ 生起回数Xvwを教師データとしてwは最小二乗解で算出できる
17.
③word2vecの加法推論 • vec(king) -
vec(man) + vec(woman) → vec(queen) vec(king) - vec(qeen) = vec(man) - vec(woman) )|( )|( log )|( )|( log ),( )( )( ),( log ),( )( )( ),( log ),( )()( )()( ),( log ),( )()( )()( ),( log )()( ),( log )()( ),( log )()( ),( log )()( ),( log )()( ),( log )(2.2 womanxp manxp queenxp kingxp womanxp womanp manp manxp queenxp queenp kingp kingxp womanxp womanpxp manpxp manxp queenxp queenpxp kingpxp kingxp manpxp womanxp manpxp manxp queenpxp queenxp kingpxp kingxp d kingx kingpxp kingxp b womanxmanxqueenxkingx x womanmanqueenking womanqueenmanking t tttt これを用いると より定理 を掛けて任意 加法則はこれを示す 証明
18.
③word2vecの加法推論 定理2.2(a)より Vの意味空間の存在 <x,y>は内積を示す
19.
③word2vecの加法推論 > <x,y>は内積を示す
20.
まとめ • 偶然発見されたword2vecの加法則は今回の 論文で限定的だが明らかにされた • 今迄の自然言語解析は意味解析が殆ど無った –
東大ロボは意味解析で失敗した (情報研 宮尾先生) • 自然言語の意味理解には分散表現が加わった – 記号表現(構文解析) – 隠れ因子分析(LDAモデル) – 分散表現(vector演算) この融合が研究が期待される <参考> 「自然言語の意味に対する2つのアプローチ」情報研 宮尾
Download












































![[DL輪読会]Set Transformer: A Framework for Attention-based Permutation-Invariant...](https://cdn.slidesharecdn.com/ss_thumbnails/20200221settransformer-200221020423-thumbnail.jpg?width=640&height=640&fit=bounds)












![[DL輪読会]data2vec: A General Framework for Self-supervised Learning in Speech,...](https://cdn.slidesharecdn.com/ss_thumbnails/220204nonakadl1-220204025334-thumbnail.jpg?width=640&height=640&fit=bounds)





















