[DL輪読会]A Bayesian Perspective on Generalization and Stochastic Gradient Descent
1.
1
DEEP LEARNING JP
[DLPapers]
http://deeplearning.jp/
A Bayesian Perspective on
Generalization and Stochastic Gradient Descent
Masahiro Suzuki, Matsuo Lab
2.
本輪読発表について
• A BayesianPerspective on Generalization and Stochastic
Gradient Descent
– Samuel L. Smith, Quoc V. Le
• arXiv:1710.06451(11/6現在ICLR投稿中)
• ちなみにSmith氏はICLRにこれともう1本出している模様
– Don't Decay the Learning Rate, Increase the Batch Size
– 元のタイトルはUnderstanding Generalization and Stochastic Gradient
Descent(redditでディスられてたから変えた?)
• 深層学習における汎化の疑問に,ベイジアンの観点から考える.
• 合わせて,深層学習と汎化に関する話題について簡単にまとめました.
– もっと知りたい方がいる場合は完全版作ります
2
ベイズ的観点からの汎化とSGD
• A BayesianPerspective on Generalization and Stochastic
Gradient Decent[Smith+ 17]
– この論文では,汎化とSGDについて次の2つの問題に取り組んでいる.
• 訓練で獲得した局所解が汎化するかどうか.
• なぜSGDは汎化性能の高い局所解を獲得するのか.
– ベイズ的な視点で検証するといろいろわかってくる.
18
19.
ベイズの定理と事後分布
• モデルをM,パラメータをω とすると,パラメータの事後分布は,
–尤度をone-hotのクロスエントロピーとすると,
,
– 事前分布は,ガウス分布 .
• したがって事後分布は,
• は正則化パラメータ
• これはL2正則化クロスエントロピーコスト関数となる
{ }i 1
P(!|{y}, {x}; M) =
P({y}|!, {x}; M)P(!; M)
P({y}|{x}; M)
P({y}|!, {x}; M) =
Q
i P(yi|!, xi; M) = e−H(!;M)
( )
P
( ( | ))
{ } )
Q
i (y | )
H(!; M) = −
P
i ln (P(yi|!, xi; M)).
p 2
P(!; M) =
p
λ/2⇡e−λ!2
/2
P(!|{y}, {x}; M) /
p
λ/2⇡e−C(!;M)
, where C(!; M) = H(!; M) + λ!2
/2
/ P({y}|!, {x}; M)P(!; M).
λ
19
20.
予測分布
• 予測分布は,パラメータを周辺化して
– ここで,パラメータの積分のほとんどがの領域で, が滑らかだと
すると,コスト関数Cを最小化してパラメータ を求めて,予測分布を
と近似できる.
P(yt|xt, {x}, {y}; M) =
Z
d! P(yt|!, xt; M)P(!|{y}, {x}; M)
=
R
d! P(yt|!, xt; M)e−C(!;M)
R
d! e−C(!;M)
.
P(yt|!, xt; M)
( )
!0,
!0,
y g
P(yt|xt; M) ⇡ P(yt|!0, xt; M)
20
ランダムラベルとの比較
• この研究では,ラベルが完全にランダムで,各クラスに等しい確率を
割り当てるモデルとしてnullモデルを考えて,比較する.
– nはモデルクラス数,Nはラベル数
•エビデンスの比は,
ただし
– この比が0より小さければ,予測モデルが信頼できないことになる.
• [Dinh+ 17]と違い,モデルのパラメータ化に依存しない.
– [Dinh+ 17]では,ヘッセ行列の固有値 を変更してパラメータ化を変えていた
が,正則化パラメータ も変える必要があった.
– 一方,本手法では となっているので,オッカム係数は変わらない.
P({y}|{x}; NULL) = (1/n)N
= e−N ln (n)
h b f i i l b l h h id
P({y}|{x}; M)
P({y}|{x}; NULL)
= e−E(!0)
,
E(!0) = C(!0)+(1/2)
P
i ln(λi/λ)−N ln(n) i
λ
λi
ln(λi/λ)
22
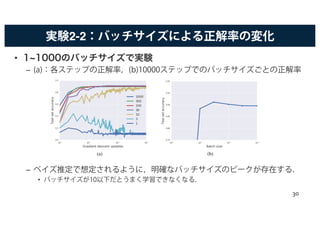
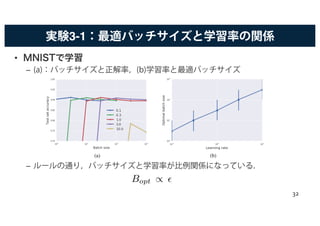
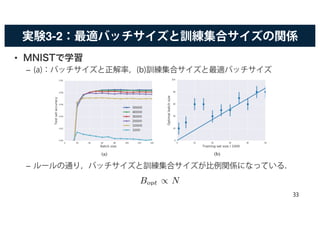
バッチサイズと各パラメータの関係
• 最適なバッチサイズが,学習率ε,訓練集合サイズN ,そしてモーメ
ンタムの係数ωにどのように影響するかを調べる.
•SGDは
– は真の勾配, はバッチの期待勾配
• 上の式を,確率的微分方程式の離散更新とみなす.
• すると,最終的に というルールが得られる.
– 式展開の詳細は,論文参照.
– バッチサイズと,学習率,訓練集合サイズ ,モーメンタムの係数の関係を示
している.
∆! =
✏
N
dC
d!
+
d ˆC
d!
−
dC
d!
!!
dC
d! =
PN
i=1
dCi
d!
h d
d ˆC
d! = N
B
PB
i=1
dCi
d!
d!
dt
=
dC
d!
+ ⌘(t)
g = ✏(N
B − 1) ⇡ ✏N/B.
fl i i
31
感想
• 汎化ギャップを考えるには,モデルや損失関数だけではなく,アルゴ
リズムやデータ集合についても考える必要がある(定義の通り).
– SGDはflatminimaの獲得に貢献している?
– データによる正則化(data augmentationとか)による違いは?
• この分野は,今くらいが楽しい時期かも.
• 今回,発表時間的に断念した論文(おすすめ)
– [Kawaguchi+ 17] Generalization in Deep Learning
• 最初の定式化が素晴らしい(参考にしました).まとめ方が博論っぽくてすごい.
– [Neyshabur+ 17] Exploring Generalization in Deep Learning
• この辺りの研究をずっとされているNeyshabur氏の論文.
– [Wu+ 17] Towards Understanding Generalization of Deep Learning:
Perspective of Loss Landscapes
• Flat minimaに落ちる理由に納得感がある説明. 37
38.
参考資料(論文)
• [Dinh+ 17]Sharp Minima can Generalize for Deep Nets
• [Hardt+ 16] Train faster, generalize better: Stability of stochastic gradient
descent
• [Hoffer+ 17] Train longer, generalize better: closing the generalization gap in large
batch training of neural networks
• [Kawaguchi+ 17] Generalization in Deep Learning
• [Keskar+ 16] On large-batch training for deep learning: Generalization gap and sharp
minima
• [Krueger+ 17] Deep Nets Don't Learn via Memorization
• [Mandt+ 17] Stochastic Gradient Descent as Approximate Bayesian Inference
• [Smith+ 17] A Bayesian Perspective on Generalization and Stochastic Gradient
Decent
• [Neyshabur+ 17] Geometry of Optimization and Implicit Regularization in Deep
Learning
• [Neyshabur+ 17] Exploring Generalization in Deep Learning
• [Wu+ 17] Towards Understanding Generalization of Deep Learning: Perspective of
Loss Landscapes
• [Zhang+ 16] Understanding deep learning requires rethinking generalization
38
39.
参考資料(スライドや本等)
• [Bousquet,17] WhyDeep Learning works?(http://www.ds3-datascience-
polytechnique.fr/wp-content/uploads/2017/08/2017_08_31_1630-
1730_Olivier_Bousquet_Understanding_Deep_Learning.pdf)
• [Deng+ 14] Rademacher Complexity
(http://web.eecs.umich.edu/~cscott/past_courses/eecs598w14/notes/10_rade
macher.pdf)
• [Goodfellow+ 16] Deep Learning
• [岡野原, 17] Deep Learning Practice and Theory
(https://www.slideshare.net/pfi/deep-learning-practice-and-theory)
• [金森,15] 統計的学習理論 (機械学習プロフェッショナルシリーズ)
39
![1
DEEP LEARNING JP
[DL Papers]
http://deeplearning.jp/
A Bayesian Perspective on
Generalization and Stochastic Gradient Descent
Masahiro Suzuki, Matsuo Lab](https://image.slidesharecdn.com/20171106dl2-171108033614/85/DL-A-Bayesian-Perspective-on-Generalization-and-Stochastic-Gradient-Descent-1-320.jpg)



![機械学習と汎化
• 機械学習で重要なのは汎化能力!
– 汎化:訓練集合で学習した後に,未知のデータ(テスト集合)について予測
できる能力のこと
– 「最適化」と機械「学習」の違いはここにある.
• 問題設定(教師あり学習):
– データ分布:
– 仮説(識別関数,モデル): ,
– 損失関数:
• やりたいこと:
– 期待損失(テスト誤差) を最小化すること
– しかしデータ分布は未知なので,直接期待損失を求めることができない!!
(x, y) ⇠ D
l(ˆy, y)
f : x ! y f 2 F
R[f] = ED[l(f(x), y)]
5](https://image.slidesharecdn.com/20171106dl2-171108033614/85/DL-A-Bayesian-Perspective-on-Generalization-and-Stochastic-Gradient-Descent-5-320.jpg)
![汎化ギャップ
• 直接データ分布を求められないので,代わりにデータ分布からのサン
プルを利用する.
– データ集合(訓練集合):
– 経験損失(訓練誤差):
– データ集合 からアルゴリズム によって得た仮説を とする.
• 予測損失の代わりに,経験損失を最小化することにする.
– このとき,以下の汎化ギャップを抑えるようにしたい.
– 式のとおり,このギャップは,仮説集合,データ集合,アルゴリズム,損失関
数に依存する.
– 統計的学習理論はこれを色々考える分野.
Dn = (x1, y1), ..., (xn, yn)
ˆRn[f] =
1
n
nX
i=1
l(f(xi), y1)
fA(Dn)
Rn[fA(Dn)] − ˆR[fA(Dn)]
Dn A
6](https://image.slidesharecdn.com/20171106dl2-171108033614/85/DL-A-Bayesian-Perspective-on-Generalization-and-Stochastic-Gradient-Descent-6-320.jpg)
![汎化ギャップと仮説集合の大きさ
• 汎化ギャップは,仮説集合の大きさに依存する.
– 仮説集合(モデル容量)が大きいと,ギャップは大きくなる.
• 損失は,バイアス(近似誤差)とバリアンス(推定誤差)に分解する
ことができる.
– 仮説集合が大きくなると,バイアスが小さくなりバリアンスが大きくなる
– 仮説集合が小さくなると,バイアスが大きくなりバリアンスが小さくなる
[Goodfellow+ 16]より
7](https://image.slidesharecdn.com/20171106dl2-171108033614/85/DL-A-Bayesian-Perspective-on-Generalization-and-Stochastic-Gradient-Descent-7-320.jpg)
![汎化ギャップの評価
• 汎化ギャップは直接求められないが,なんらかの形で評価したい.
• 統計的学習理論では,以下のようなアプローチがある.
– 複雑度
– 一様安定性(話さない)
– ロバスト性(話さない)
• 基本的には,汎化ギャップの上界を求める.
Rn[fA(Dn)] − ˆR[fA(Dn)]
8](https://image.slidesharecdn.com/20171106dl2-171108033614/85/DL-A-Bayesian-Perspective-on-Generalization-and-Stochastic-Gradient-Descent-8-320.jpg)
![仮説集合の複雑度
• PAC学習では,仮説集合の複雑度を考えることで,確率的な上界を
求めることができる.
– 複雑度の指標としては,VC次元とラデマッハ複雑度がある.
• 経験ラデマッハ複雑度:
ただし, は+1と-1を等確率にとる独立な確率変数.
– ランダムなラベル付けに対する,関数集合Fの適合度を表す.
• 任意の に対して, 以上の確率で次式が成り立つ.
– ラデマッハ複雑度によって,汎化ギャップの上界が求められるようになった!
ˆR(F) = Eσ[sup
f2F
(
1
n
nX
i=1
σif(xi))]
σ1, ..., σn
1 − δ
sup
f2F
Rn[f] − ˆR[f] 2 ˆR(F) + 3
s
log 2
δ
2n
δ 2 (0, 1)
9](https://image.slidesharecdn.com/20171106dl2-171108033614/85/DL-A-Bayesian-Perspective-on-Generalization-and-Stochastic-Gradient-Descent-9-320.jpg)

![深層学習と仮説集合の大きさ
• 深層学習はパラメータが膨大になる.
– つまり仮説集合の大きさはかなり大きい->汎化ギャップも大きいはず
– パラメータが増えるほど,汎化ギャップはさらに大きくなるはず
• しかし実験的には,パラメータが増えるほど汎化性能が良くなること
が知られている[Neyshabur+ 17].
– しかも,経験損失が下がりきっても,予測損失は下がっている.
4 8 16 32 64 128 256 512 1K 2K 4K
0
0.01
0.02
0.03
0.04
0.05
0.06
0.07
0.08
0.09
0.1
H
Error
Training
Test (at convergence)
Test (early stopping)
4 8 16 32 64 128 256 512 1K 2K 4K
0
0.1
0.2
0.3
0.4
0.5
0.6
H
Error
Training
Test (at convergence)
Test (early stopping)
MNIST CIFAR-10
仮説集合の大きさ
11](https://image.slidesharecdn.com/20171106dl2-171108033614/85/DL-A-Bayesian-Perspective-on-Generalization-and-Stochastic-Gradient-Descent-11-320.jpg)
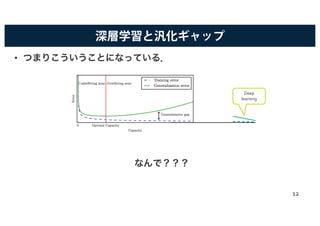
![既存の学習理論では説明できない現象
• 従来の統計的学習理論で汎化について説明することはできないか?
– モデルの複雑度(ラデマッハ複雑度)を計測すればよい.
• Zhangらによる実験[Zhang+ 17]:
– ランダムなラベル付けをした訓練集合で学習
• 深層モデルは,これを完全に学習した.
• ラデマッハ複雑度は1(max)となり,汎汎化化ギギャャッッププのの上上界界がが緩緩くくななるるここととをを意意味味すするる.
– モデルに様々な正則化を行って学習
• あまり大きな違いはなかった.
• 正則化は仮説集合の大きさを小さくする効果がある.
• つまり,仮説集合の大きさを抑える->汎化性能の向上,ととはは限限ららなないい.
• 従来の学習理論では説明できないことが,DNNでは起こってい
る??
sup
f2F
Rn[f] − ˆR[f] 2 ˆR(F) + 3
s
log 2
δ
2n
13](https://image.slidesharecdn.com/20171106dl2-171108033614/85/DL-A-Bayesian-Perspective-on-Generalization-and-Stochastic-Gradient-Descent-13-320.jpg)
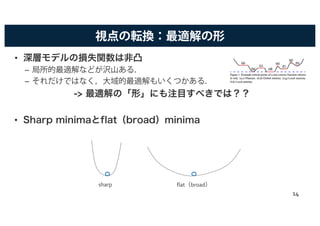
![Flat minimaと汎化性能
• Flat minimaが良い汎化となることが,経験的に指摘されていた
[Hochreiter & Schmidhuber+ 97].
– Chaudhariらは,この仮説を元にEntropy-SGDを提案している[Chaudhari+ 17].
• Sharp minimaに行かないような,局所エントロピーに基づく手法.
• また,ランダムなラベルで訓練すると,ヘッセ行列の最大固有値が大
きくなる(=sharp minima)ことが確認された[Krueger+ 17]
– その他にも,ランダムラベルを学習するためには,モデル容量が大きい必要が
あることを確認.
• しかし,汎化性能を変えずに,sharp minimaを持つ損失関数に再
パラメータ化できることも示された[Dinh+ 17].
->良い汎化ななららばばflat minima,ではない!
15](https://image.slidesharecdn.com/20171106dl2-171108033614/85/DL-A-Bayesian-Perspective-on-Generalization-and-Stochastic-Gradient-Descent-15-320.jpg)
![バッチサイズとflat minima
• Keskarは,大規模なバッチサイズがsharp minimaに落ちることを
実験的に示した[Keskar+ 16].
– 小規模なバッチサイズだとflat minimaに落ちることも確認.
• 一方,Hofferは,大規模なバッチサイズがsharp minimaに落ちる
のは,反復回数が足りないだけと主張[Hoffer+ 17].
– Flat minimaに行くには時間がかかる.
– 異なるバッチサイズで反復回数を同じになるように学習率を調節すると,汎化
ギャップがなくなっていることを確認.
– (ただし,一様安定性の観点からは,反復回数を増やさないほうがSGDは安定
する[Hardt+ 16])
16](https://image.slidesharecdn.com/20171106dl2-171108033614/85/DL-A-Bayesian-Perspective-on-Generalization-and-Stochastic-Gradient-Descent-16-320.jpg)

![ベイズ的観点からの汎化とSGD
• A Bayesian Perspective on Generalization and Stochastic
Gradient Decent[Smith+ 17]
– この論文では,汎化とSGDについて次の2つの問題に取り組んでいる.
• 訓練で獲得した局所解が汎化するかどうか.
• なぜSGDは汎化性能の高い局所解を獲得するのか.
– ベイズ的な視点で検証するといろいろわかってくる.
18](https://image.slidesharecdn.com/20171106dl2-171108033614/85/DL-A-Bayesian-Perspective-on-Generalization-and-Stochastic-Gradient-Descent-18-320.jpg)



![ランダムラベルとの比較
• この研究では,ラベルが完全にランダムで,各クラスに等しい確率を
割り当てるモデルとしてnullモデルを考えて,比較する.
– nはモデルクラス数,Nはラベル数
• エビデンスの比は,
ただし
– この比が0より小さければ,予測モデルが信頼できないことになる.
• [Dinh+ 17]と違い,モデルのパラメータ化に依存しない.
– [Dinh+ 17]では,ヘッセ行列の固有値 を変更してパラメータ化を変えていた
が,正則化パラメータ も変える必要があった.
– 一方,本手法では となっているので,オッカム係数は変わらない.
P({y}|{x}; NULL) = (1/n)N
= e−N ln (n)
h b f i i l b l h h id
P({y}|{x}; M)
P({y}|{x}; NULL)
= e−E(!0)
,
E(!0) = C(!0)+(1/2)
P
i ln(λi/λ)−N ln(n) i
λ
λi
ln(λi/λ)
22](https://image.slidesharecdn.com/20171106dl2-171108033614/85/DL-A-Bayesian-Perspective-on-Generalization-and-Stochastic-Gradient-Descent-22-320.jpg)

![単純なラベルでのランダムラベル問題
• [Zhang+ 17]では,DNNのように仮説集合の大きい場合に,ランダ
ムラベルを完全に記憶してしまう問題があった.
-> 本研究では,はるかに単純なモデル,ロジスティック回帰で試す.
• データセット:各要素をガウス分布からサンプリングした200次元ベ
クトルの入力
– 2つのタスクで実験:
• ランダムに0,1を割り当て(ランダムラベルの場合)
• 要素の和が1より大きいなら1,そうでなければ0(ラベルを正しく割り当てた場合)
x
24](https://image.slidesharecdn.com/20171106dl2-171108033614/85/DL-A-Bayesian-Perspective-on-Generalization-and-Stochastic-Gradient-Descent-24-320.jpg)
![実験1-1:簡単なモデルで問題が生じるか確認
– (a):ランダムラベルの場合,(b)ラベルを正しく割り当てた場合
– ロジスティック回帰でも,ランダムラベルを完全に記憶してしまうことがわか
る.
• 正則化を高めても,モデルの性能は改善していない.
• [Zhang+ 17]の指摘を簡単なモデル,データセットでも再現できた!
(a) (b)
25](https://image.slidesharecdn.com/20171106dl2-171108033614/85/DL-A-Bayesian-Perspective-on-Generalization-and-Stochastic-Gradient-Descent-25-320.jpg)
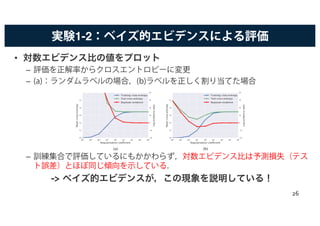
![SGDとベイズ推定と汎化
• 前述の結果から,深層ネットワークを訓練する場合は,損失関数では
なく,エビデンスを最大にするように極小値をみつけるべきである.
– ベイジアンは,ノイズを入れることでベイズ推定等を行っている.
• SGDは,パラメータの近似ベイズ推定を行っているとみなせる
[Mandt+ 17]
– 一定の学習率を持つSGDは,定常分布を持つマルコフ連鎖をシミュレートして
いる.
• よって,SGDの「ノイズ」を調節することで,良い汎化とすること
ができる.
– 小規模なバッチは,より大きなノイズを与える.
– ノイズによって,sharp minimaから遠ざかるようになる([Keskar+ 16]の話と
一致).
– つまり,勾配->深い最適値,ノイズ(ミニバッチ)->flat minima 27](https://image.slidesharecdn.com/20171106dl2-171108033614/85/DL-A-Bayesian-Perspective-on-Generalization-and-Stochastic-Gradient-Descent-27-320.jpg)

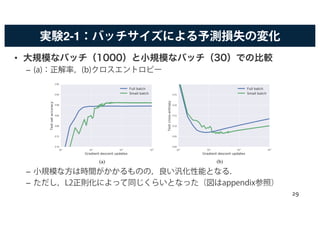

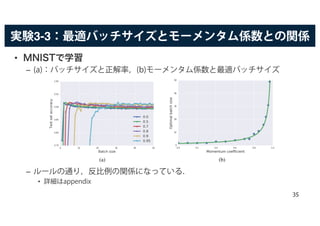
![スケーリングルールの効果
• 求めたルールによって,次の影響がある.
– バッチサイズを大幅に増やすことができる.
• 精度を落としたり,計算コストを上げなくても,学習率を調節することで,大幅に向上さ
せられる.
– 大きなサイズの商用データセットを利用できる.
• [Hoffer+ 17]では という方法が提案されている.
• しかし今回の実験では,[Hoffer+ 17]の方法では学習率が大きすぎて,逆に精度が下がる結
果となった.
✏ /
p
Bopt.
h
34](https://image.slidesharecdn.com/20171106dl2-171108033614/85/DL-A-Bayesian-Perspective-on-Generalization-and-Stochastic-Gradient-Descent-34-320.jpg)

![感想
• 汎化ギャップを考えるには,モデルや損失関数だけではなく,アルゴ
リズムやデータ集合についても考える必要がある(定義の通り).
– SGDはflat minimaの獲得に貢献している?
– データによる正則化(data augmentationとか)による違いは?
• この分野は,今くらいが楽しい時期かも.
• 今回,発表時間的に断念した論文(おすすめ)
– [Kawaguchi+ 17] Generalization in Deep Learning
• 最初の定式化が素晴らしい(参考にしました).まとめ方が博論っぽくてすごい.
– [Neyshabur+ 17] Exploring Generalization in Deep Learning
• この辺りの研究をずっとされているNeyshabur氏の論文.
– [Wu+ 17] Towards Understanding Generalization of Deep Learning:
Perspective of Loss Landscapes
• Flat minimaに落ちる理由に納得感がある説明. 37](https://image.slidesharecdn.com/20171106dl2-171108033614/85/DL-A-Bayesian-Perspective-on-Generalization-and-Stochastic-Gradient-Descent-37-320.jpg)
![参考資料(論文)
• [Dinh+ 17] Sharp Minima can Generalize for Deep Nets
• [Hardt+ 16] Train faster, generalize better: Stability of stochastic gradient
descent
• [Hoffer+ 17] Train longer, generalize better: closing the generalization gap in large
batch training of neural networks
• [Kawaguchi+ 17] Generalization in Deep Learning
• [Keskar+ 16] On large-batch training for deep learning: Generalization gap and sharp
minima
• [Krueger+ 17] Deep Nets Don't Learn via Memorization
• [Mandt+ 17] Stochastic Gradient Descent as Approximate Bayesian Inference
• [Smith+ 17] A Bayesian Perspective on Generalization and Stochastic Gradient
Decent
• [Neyshabur+ 17] Geometry of Optimization and Implicit Regularization in Deep
Learning
• [Neyshabur+ 17] Exploring Generalization in Deep Learning
• [Wu+ 17] Towards Understanding Generalization of Deep Learning: Perspective of
Loss Landscapes
• [Zhang+ 16] Understanding deep learning requires rethinking generalization
38](https://image.slidesharecdn.com/20171106dl2-171108033614/85/DL-A-Bayesian-Perspective-on-Generalization-and-Stochastic-Gradient-Descent-38-320.jpg)
![参考資料(スライドや本等)
• [Bousquet,17] Why Deep Learning works?(http://www.ds3-datascience-
polytechnique.fr/wp-content/uploads/2017/08/2017_08_31_1630-
1730_Olivier_Bousquet_Understanding_Deep_Learning.pdf)
• [Deng+ 14] Rademacher Complexity
(http://web.eecs.umich.edu/~cscott/past_courses/eecs598w14/notes/10_rade
macher.pdf)
• [Goodfellow+ 16] Deep Learning
• [岡野原, 17] Deep Learning Practice and Theory
(https://www.slideshare.net/pfi/deep-learning-practice-and-theory)
• [金森,15] 統計的学習理論 (機械学習プロフェッショナルシリーズ)
39](https://image.slidesharecdn.com/20171106dl2-171108033614/85/DL-A-Bayesian-Perspective-on-Generalization-and-Stochastic-Gradient-Descent-39-320.jpg)


![[DL輪読会]Pay Attention to MLPs (gMLP)](https://cdn.slidesharecdn.com/ss_thumbnails/kobayashi-210528032327-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DL輪読会]Deep Learning 第15章 表現学習](https://cdn.slidesharecdn.com/ss_thumbnails/deeplearning15-180601023904-thumbnail.jpg?width=640&height=640&fit=bounds)





![SSII2022 [TS1] Transformerの最前線〜 畳込みニューラルネットワークの先へ 〜](https://cdn.slidesharecdn.com/ss_thumbnails/ts120220608ssiitransformerr2-220607054025-3adacf07-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DL輪読会]Relational inductive biases, deep learning, and graph networks](https://cdn.slidesharecdn.com/ss_thumbnails/180629dlseminarrelationalinductivebias-180706003755-thumbnail.jpg?width=640&height=640&fit=bounds)
![SSII2021 [OS2-01] 転移学習の基礎:異なるタスクの知識を利用するための機械学習の方法](https://cdn.slidesharecdn.com/ss_thumbnails/os2-02final-210610091211-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DL輪読会]data2vec: A General Framework for Self-supervised Learning in Speech,...](https://cdn.slidesharecdn.com/ss_thumbnails/220204nonakadl1-220204025334-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]相互情報量最大化による表現学習](https://cdn.slidesharecdn.com/ss_thumbnails/20190913iwasawa-190913002312-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会] Spectral Norm Regularization for Improving the Generalizability of De...](https://cdn.slidesharecdn.com/ss_thumbnails/dlhackspectralnorm1-170907072536-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DL輪読会]Swin Transformer: Hierarchical Vision Transformer using Shifted Windows](https://cdn.slidesharecdn.com/ss_thumbnails/swintransformer-210514020542-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Dl輪読会]dl hacks輪読](https://cdn.slidesharecdn.com/ss_thumbnails/dldlhacks-161125051944-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]Understanding Black-box Predictions via Influence Functions](https://cdn.slidesharecdn.com/ss_thumbnails/dlhacksinffunc-170822055634-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]Opening the Black Box of Deep Neural Networks via Information](https://cdn.slidesharecdn.com/ss_thumbnails/dlhacks10161-171027055615-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]Imagination-Augmented Agents for Deep Reinforcement Learning / Learnin...](https://cdn.slidesharecdn.com/ss_thumbnails/dlhacksshioya201707281-170728054152-thumbnail.jpg?width=640&height=640&fit=bounds)






![[DL輪読会]Learning to Act by Predicting the Future](https://cdn.slidesharecdn.com/ss_thumbnails/20171113dl-171114045641-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DLHacks] DLHacks説明資料](https://cdn.slidesharecdn.com/ss_thumbnails/dlhacks-170919004557-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DL輪読会]QUASI-RECURRENT NEURAL NETWORKS](https://cdn.slidesharecdn.com/ss_thumbnails/quasi-recurrentneuralnetworks-170512014332-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]One Model To Learn Them All](https://cdn.slidesharecdn.com/ss_thumbnails/dljp20170714ono-170714005853-thumbnail.jpg?width=640&height=640&fit=bounds)







![[DL輪読会]Scalable Training of Inference Networks for Gaussian-Process Models](https://cdn.slidesharecdn.com/ss_thumbnails/mainslideshare1-190927025239-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]Deep Learning 第5章 機械学習の基礎](https://cdn.slidesharecdn.com/ss_thumbnails/deeplearning5-180601021956-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DL輪読会]Train longer, generalize better: closing the generalization gap in lar...](https://cdn.slidesharecdn.com/ss_thumbnails/dlhacks20170721-170721035045-thumbnail.jpg?width=640&height=640&fit=bounds)

![[論文解説]A Bayesian Perspective on Generalization and Stochastic Gradient Descent](https://cdn.slidesharecdn.com/ss_thumbnails/0123bayes-180123100528-thumbnail.jpg?width=640&height=640&fit=bounds)


























